




目录
1、FlinkSQL客户端的功能
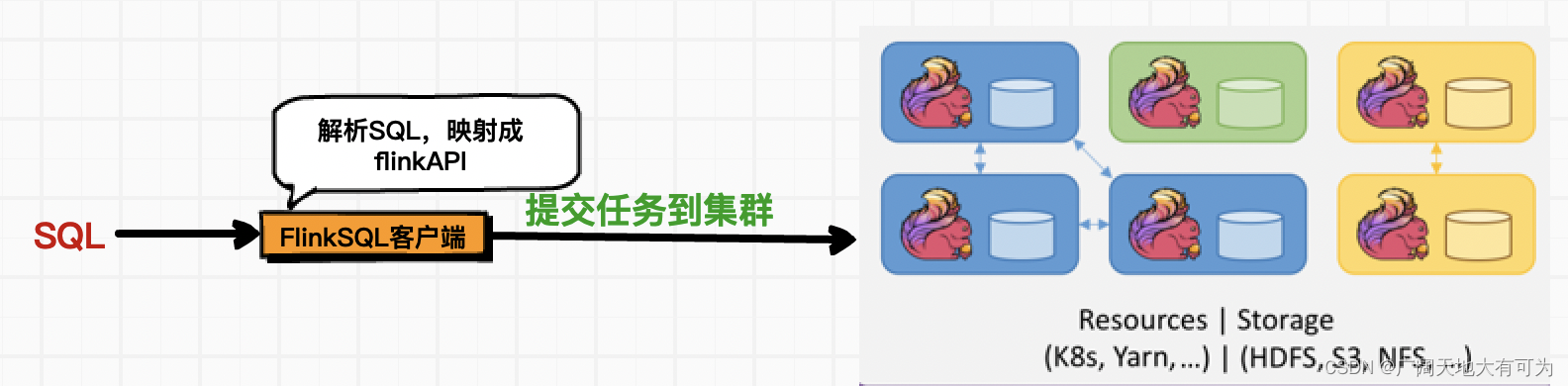
提供一个客户端,不需要写一行java或scala代码,只需通过写SQL的方式就能向Flink集群提交流式计算任务。
2、FlinkSQL客户端启动参数配置
2.1 基本语法
./sql-client [MODE] [OPTIONS]2.2 相关参数([MODE]):
MODE = embedded
默认选项 表示从本地机器提交Flink作业
MODE = gateway
表示通过SQL网关进行提交2.3 相关参数(embedded [OPTIONS]):
-f,--file <script file>
运行指定的SQL脚本,注意:在此模式下,客户端无法打开交互终端
-hist,--history <History file path>
指定保存历史命令(交互终端)的文件,不指定时,将生成在默认位置 /home/.flink-sql-history
-i,--init <initialization file>
指定初始化客户端的SQL脚本,如果SQL报错客户端将退出
注意:这个文件里不允许添加查询或插入语句
-j,--jar <JAR file>
指定依赖的jar包
-s,--session <session identifier>3、启动Flink的sql-client
3.1 启动时使用初始化脚本
bin/sql-client 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









