







大家好,我是微学AI,今天给大家介绍一下卷积神经网络,卷积神经网络(Convolutional Neural Network)是一种深度学习模型,也是最近几年受到最多关注的模型之一。它的核心是深度学习的卷积层,可以帮助用户抽取有效的特征,从而进行分类或者识别。这些特征可以是图像,文本,音频或者视频中的相关特征,可以构建许多实用的应用。
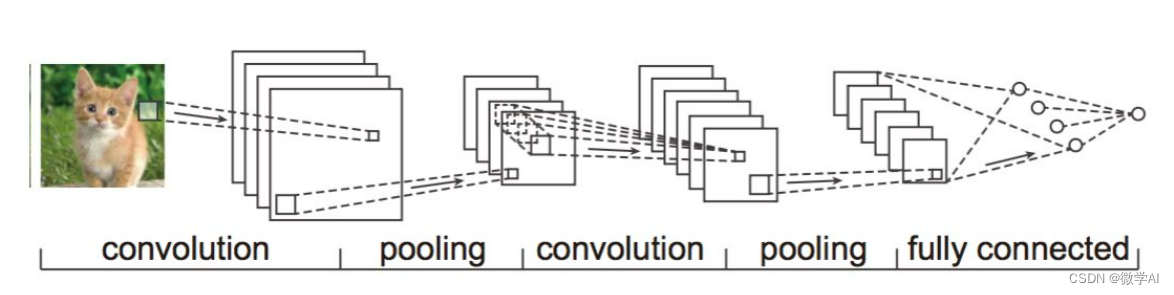
一、卷积神经网络的发展
CNN最早的模型框架就是由LeNet给出的, 即卷积+池化+FC层的基本结构.
2012年另一个具有划时代意义的模型AlexNet横空出世. AlexNet在2012年ImageNet竞赛中以超过第二名10.9个百分点的绝对优势, 一举夺冠, 引起了相当大的轰动. 此前深度学习沉寂了很久, 但自AlexNet诞生后, 所有的ImageNet冠军都是用CNN来做的.
随后,CNN 又经历了几次发展,例如 VGG、GoogLeNet 等。这些模型在不同的计算机视觉任务中取得了很好的成绩,并在深度学习领域引起了巨大的关注。
近年来,CNN 又有了新的发展,例如 ResNet、DenseNet 等。这些模型在不同的计算机视觉任务中也取得了很好的成绩。
总的来说,CNN 经历了几十年的发展,在计算机视觉领域取得了巨大的成就。它的出现极大地提高了计算机对图像的理解能力,为人工智能的发展做出了重要贡献。
二、卷积神经网络介绍
卷积神经网络由一系列可学习的卷积层和全连接层组成,每一层都有一组可学习的参数,卷积层的参数定义为卷积核,全连接层的参数叫做权重矩阵。卷积神经网络可以通过反向传播算法不断的调整参数值,使得输入的数据可以被准确的识别或者分类。
卷积神经网络的优势主要在于它可以抽取更多的特征,抽取特征的过程是由卷积层完成的,卷积层是基于局部连接和权重共享的。另外,卷积神经网络可以更好的处理结构化的输入数据,比如图片、声音、文本等。它也具有更少的参数,更高的泛化能力,这使得卷积神经网络更容易收敛,可以更快的训练模型,更好的处理大规模的数据,以及解决更复杂的问题。
三、卷积神经网络的原理
卷积神经网络(Convolutional Neural Network,CNN) 具有许多层,包括卷积层、池化层和全连接层。
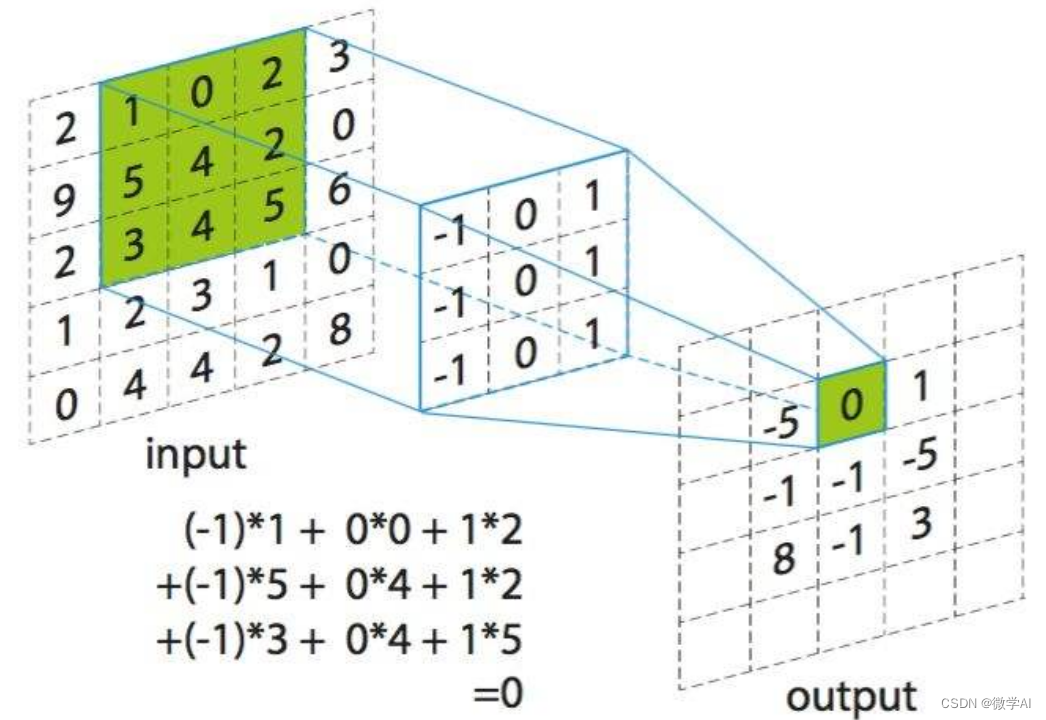
卷积层的作用是提取图像的特征。它通过使用卷积核(也称为滤波器)对图像进行卷积来实现这一点。卷积核是一个小的矩阵,它在图像上滑动,并与图像的每个部分做卷积运算。对于图像的每一个位置,卷积核都会与它所覆盖的图像像素做内积,然后将所有内积的结果相加,得到一个新的值。这个新值就是卷积核在该位置的输出。卷积核在图像上滑动的过程就是卷积运算。
池化层的作用是降低图像的维度,同时保留有用的特征。常用的池化操作有最大池化和平均池化。最大池化会保留池化窗口内的最大值,而平均池化则会保留池化窗口内的平均值。池化的效果是降低图像的维度,同时有效地抑制噪声和缩小模型的大小。
全连接层是普通的神经网络层,它将之前的输出进一步处理并得到最终的输出结果。全连接层中的每个单元都会与前一层中的所有单元相连。
在训练过程中,CNN 会自动学习卷积核的权值,以便于提取图像中有用的特征。这就是 CNN 的强大之处,因为它能够自动学习图像的特征,而不用人工去设计特征提取方法。
四、卷积运算的数学表达
在物理学中,卷积运算可以用来描述两个时变信号之间的关系。例如,假设你有一个声音发生器和一个麦克风。当声音发生器发出声音时,麦克风就会捕捉到声音波。这个过程可以看作是声音发生器的输出信号与麦克风的输入信号之间的卷积运算。
在数学上,卷积运算可以表示为:
其中 和
是两个函数,
表示卷积运算。
在上面的例子中, 函数就是声音发生器的输出信号,
函数就是麦克风的输入信号,
就是麦克风捕捉到的声音信号。
在 CNN 中,卷积运算通常是在二维图像上进行的。在二维图像中,卷积运算可以表示为:
其中 是输入图像,
是卷积核,
是卷积核在图像上的位置。
在 CNN 中,卷积运算通常用于图像处理。例如,在图像分类任务中,我们可以使用卷积运算来提取图像中的特征。卷积核就是一个小的矩阵,它在图像上滑动,并与图像的每个部分做卷积运算。卷积核在图像上滑动的过程就是卷积运算。
五、卷积神经网络pytorch案例
import torchvision.transforms as transforms
from torch.nn import functional as F
# 定义模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 加载数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
testset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
net =CNN()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
if __name__ == '__main__':
torch.multiprocessing.freeze_support()
# 训练模型
for epoch in range(5): # 遍历数据集五次
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 获取输入和标签
inputs, labels = data
# 梯度清零
optimizer.zero_grad()
# 前向传播+反向传播+优化
outputs= net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 打印统计信息
running_loss += loss.item()
if i % 2000 == 1999: # 每 2000 个 mini-batches 打印一次
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
#模型测试
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))在未来,CNN 还将会有新的发展,并在更多领域得到应用。希望未来的发展能够帮助人工智能更好地服务于人类社会。
















 6790
6790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











