






大家好,我是微学AI,今天给大家介绍一下大模型在推理过程中top-k和top-p同时设置的时候该怎么采样,详细介绍这个过程。在推理过程中,当同时设置Top-k和Top-p进行采样时,采样过程通常遵循一定的顺序和规则,以确保生成文本的多样性和准确性。以下是对这一过程的详细阐述:
文章目录
一、概念阐述
Top-k采样
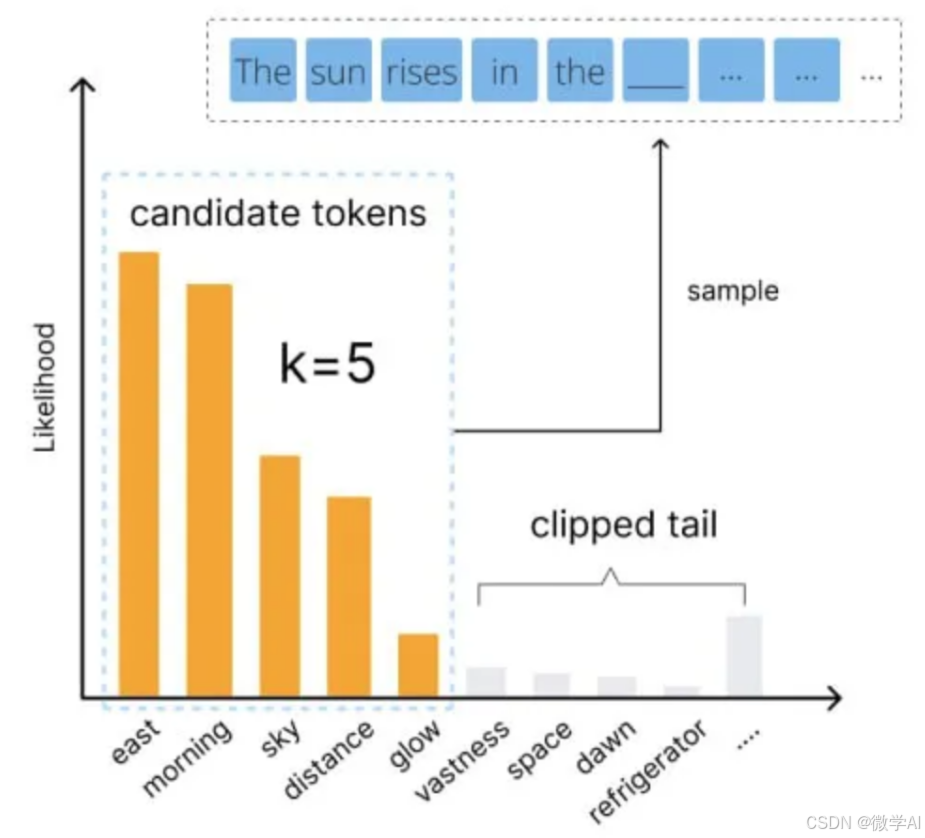
在预测下一个单词时,Top-k采样策略只考虑概率最高的k个词。这k个词是固定数量的,无论它们的累计概率是多少。
通过限制候选词的数量,Top-k采样可以在一定程度上避免选择概率过低的词,从而增加生成内容的连贯性。
示例:假设一个语言模型预测下一个词的概率分布如下(按概率降序排列):
词A:0.5
词B:0.3
词C:0.1
词D:0.05
词E:0.05 如果设置Top-k=3,那么筛选出的词为词A、词B和词C。
Top-p采样
Top-p采样,也称为核采样(Nucleus Sampling),选择一个概率阈值p。
然后从模型的预测分布中选择一个最小的词的集合,这个集合中的单词的概率总和至少为p。与Top-k不同的是,Top-p选择的词数量是不固定的,它根据每个生成步骤中词的概率分布动态选择候选词。
示例:继续使用上述概率分布,如果设置Top-p=0.8,那么需要选择累计概率至少为0.8的词集合。词A和词B的累计概率为0.8(0.5+0.3),因此最终的候选词集合为{词A,词B}。
二、同时设置时的采样顺序
在一般情况下,当Top-k和Top-p同时设置时,采样过程会先按照Top-k的规则筛选出k个概率最高的词,然后再在这k个词中按照Top-p的规则进一步筛选出累计概率至少为p的词集合。也就是说,Top-p在Top-k之后起作用。这种顺序可以确保在保持一定多样性的同时,也考虑到了生成内容的连贯性和准确性。
为什么先进行Top-k再进行Top-p?
1. 减少计算复杂度
Top-k采样:通过选择概率最高的k个词,显著减少了候选词的数量。假设词汇表中有N个词,直接进行Top-p采样需要遍历所有N个词并计算累计概率。而先进行Top-k采样后,只需要对k个词进行操作,计算复杂度从O(N)降低到O(k),其中k << N。
效率提升:在大规模词汇表中,Top-k采样可以极大地减少计算量,提高推理速度。这对于实时应用和大规模数据处理尤为重要。
2. 平衡多样性和连贯性
Top-k采样:确保候选词具有较高的概率。通过选择概率最高的k个词,可以保留那些最有可能的词,从而保持生成文本的连贯性。
Top-p采样:在Top-k候选词的基础上,进一步筛选出累计概率达到p的词集合。这种方法称为核采样(Nucleus Sampling),能够平衡多样性和连贯性。具体来说:
通过设定p值,可以控制候选词的数量。较小的p值会保留更多的词,增加多样性;较大的p值会保留较少的词,减少多样性。 由于Top-k候选词已经具有较高的概率,Top-p采样进一步确保这些词的累计概率达到一定的阈值,从而保持生成文本的连贯性。
3. 结合两种方法的优势
Top-k采样:通过减少候选词的数量,降低了计算复杂度。
Top-p采样:在减少的候选词基础上,进一步筛选出概率累计达到阈值的词,确保生成文本的多样性和连贯性。
综合效果:结合这两种方法,可以在保证生成文本质量的同时,提高推理效率。
三、采样过程代码示例
假设一个语言模型预测下一个词的概率分布如下(按概率降序排列):
词A:0.5
词B:0.3
词C:0.1
词D:0.05
词E:0.05
如果设置Top-k=3且Top-p=0.9,那么采样过程如下:
Top-k采样
首先筛选出概率最高的3个词,即词A、词B和词C。
Top-p采样
然后在这3个词中筛选出累计概率至少为0.9的词集合。由于词A和词B的累计概率已经达到0.8(0.5+0.3),再加上词C的概率0.1后累计概率为0.9,满足Top-p的条件。因此,最终的候选词集合为{词A,词B,词C}。
随机采样
最后从这个候选词集合中随机选择一个词作为采样结果。
import numpy as np
# 假设一个语言模型预测下一个词的概率分布如下(按概率降序排列)
probabilities = np.array([0.5, 0.3, 0.1, 0.05, 0.05])
words = ['词A', '词B', '词C', '词D', '词E']
# 设置Top-k和Top-p参数
top_k = 3
top_p = 0.9
# Top-k采样
top_k_indices = np.argsort(probabilities)[-top_k:][::-1]
top_k_words = [words[i] for i in top_k_indices]
top_k_probabilities = probabilities[top_k_indices]
# Top-p采样
cumulative_probabilities = np.cumsum(top_k_probabilities)
top_p_indices = np.where(cumulative_probabilities <= top_p)[0]
if len(top_p_indices) == len(cumulative_probabilities) or cumulative_probabilities[top_p_indices[-1]] < top_p:
top_p_indices = np.append(top_p_indices, len(cumulative_probabilities) - 1)
top_p_words = [top_k_words[i] for i in top_p_indices]
top_p_probabilities = top_k_probabilities[top_p_indices]
# 随机采样
selected_word = np.random.choice(top_p_words, p=top_p_probabilities / top_p_probabilities.sum())
print(f"Top-k候选词: {top_k_words},概率: {top_k_probabilities}")
print(f"Top-p候选词: {top_p_words},概率: {top_p_probabilities}")
print(f"最终采样结果: {selected_word}")
代码说明:
概率分布和词汇定义:定义了一个词汇列表words及其对应的概率分布probabilities。
Top-k采样:通过np.argsort获取概率最高的top_k个词的索引,并筛选出对应的词汇和概率。
Top-p采样:计算筛选出的top_k个词的累计概率,并找出累计概率小于等于top_p的词的索引,最终确定Top-p候选词。
随机采样:从Top-p候选词中根据概率分布随机选择一个词作为最终结果。
你可以根据实际需求调整top_k和top_p的值,以适应不同的应用场景。
四、结合实际情况说明
在不同应用场景下,Top-k和Top-p的取值可能会有所不同,进而影响同时设置时的采样结果。例如:
创意写作:
在创意写作等需要高度多样性的场景下,可能会设置较高的Top-p值(如0.95或更高),以允许模型从更大的词汇空间中进行采样,生成更具创意和多样性的文本。
示例:假设一个创意写作任务,设置Top-k=5且Top-p=0.95,模型可以生成多种不同的句子,增强文本的创新性。
代码生成:
在代码生成等需要较高准确性的场景下,可能会设置较低的Top-p值(如0.7或0.8),以确保生成的代码更加符合语法和逻辑要求。
示例:假设一个代码生成任务,设置Top-k=3且Top-p=0.7,模型可以生成更符合编程规范的代码片段。
五、潜在问题讨论
虽然同时设置Top-k和Top-p可以有效平衡生成文本的多样性和准确性,但也存在一些潜在问题:
过度限制候选词集:如果Top-k和Top-p设置得过于严格,可能会导致生成内容的单调性,缺乏多样性。
计算复杂度:尽管先进行Top-k可以减少计算复杂度,但在某些情况下,Top-p的计算仍然可能较为复杂,尤其是在大规模模型中。
六、总结
通过同时设置Top-k和Top-p进行采样,可以在不同场景下平衡生成文本的多样性和准确性。具体步骤包括先进行Top-k采样,筛选出概率最高的k个词,然后再在这k个词中进行Top-p采样,确保生成内容的连贯性和多样性。在实际应用中,可以根据具体需求灵活调整这两个参数的值,以生成高质量的文本。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











