







一、运算符
逻辑运算符优先级:
not and or
// 用于向下取接近除数的整数。
二、函数-收集参数
`def greetPerson(*name):
print(‘Hello’, name)
greetPerson(‘Runoob’, ‘Google’)`
Hello (‘Runoob’, ‘Google’)
加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数
递归函数用于调用函数的本身。
三、标识符-变量名字
变量不能以数字开头;标识符的最大长度是79
系统将函数调用的参数和局部变量存放在内存的哪一部分? 堆(stack)
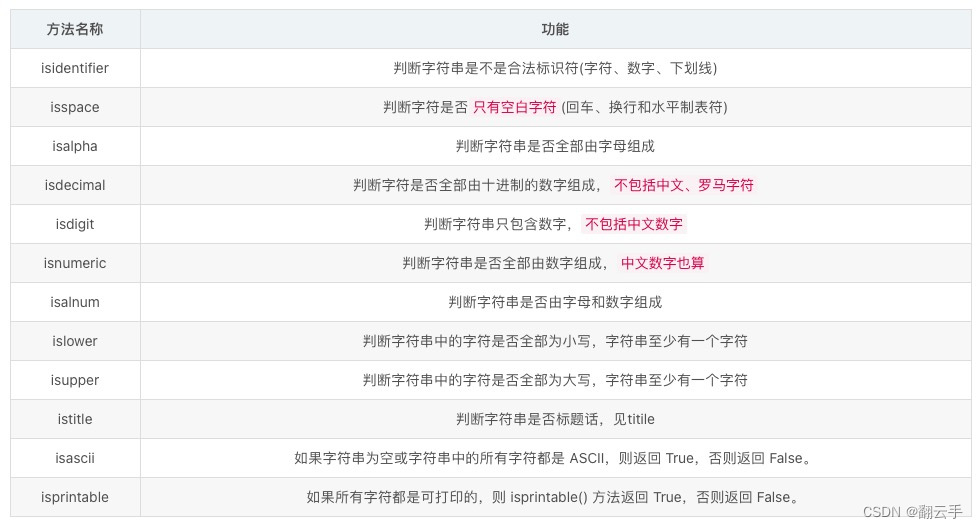
s 为字符串
s.isalnum() 所有字符都是数字或者字母,为真返回 True,否则返回 False。
s.isalpha() 所有字符都是字母,为真返回 True,否则返回 False。
s.isdigit() 所有字符都是数字,为真返回 True,否则返回 False。
s.islower() 所有字符都是小写,为真返回 True,否则返回 False。
s.isupper() 所有字符都是大写,为真返回 True,否则返回 False。
s.istitle() 所有单词都是首字母大写,为真返回 True,否则返回 False。
s.isspace() 所有字符都是空白字符,为真返回 True,否则返回 False。
四、 数据容器
不可哈希-可变数据结构
1.列表[]
列表:一个大仓库,你可以随时往里边添加和删除任何东西。
2.字典{“A”:“B”}
3.集合
可哈希-不可变数据结构
1.元组(,)
元组:封闭的列表,一旦定义,就不可改变(不能添加、删除或修改)。
x, y, z = 1, 2, 3 请问x, y, z是元组吗?
所有的多对象的、逗号分隔的、没有明确用符号定义的这些集合默认的类型都是元组,
2.字符串
3.数字
五、文件读取
1.新建文件夹时注意
创建多级目录:makedirs(name, mode, exist_ok=False) #exist_ok=True时所创建的文件即使存在也不会报错 。如makedirs(‘a/b/c/’)
创建单个目录:mkdir(name, mode,dir_fd)没有exist_o这个关键字参数
2.文件读取read、readline和readlines
read()读取整个文件内容,作为字符串输出,注意每行后会有一个换行,可以用rstrip()去除
readline()只读取一行
readlines()读取所有内容,每一行作为列表的一个元素
os模块与pathlib模块
from pathlib import Path
#注意,当有‘\t’、‘\r’ 分别表示“横向制表符(TAB)”和“回车符”等有特殊含义的文件路径出现时要在路径前加r;只需要使用原始字符串操作符(R或r)
file1 = open(r’C:\windows\temp\readme.txt’, ‘r’)
3.with open() as f:与f=open()f.wrtie,f.close()
with open(‘xx.txt’,‘w’) as f:
f.write()
###类和对象
1,多态概念:
面向对象的三大特征:封装,继承,多态
封装:根据职责将属性和方法封装到一个抽象的类中
继承:实现代码的重用,相同的代码不需要重复的编写
多态:(以封装和继承为前提)不同的子类调用相同的方法,产生不同的结果
x= [[13, -1, 4], [5, 0, 6], [1, 9, -3]]
Z = [[0 for i in range(len(X))] for j in range(len(X))] #一行创建一个与x相同的m行,n列的矩阵
sorted和lambda妙用答案参考–692. 前K个高频单词
首先利用 hash = collections.Counter(words) 记录每个单词出现的次数
然后进行双关键词排序
res = sorted(hash, key=lambda word:(-hash[word], word))
sorted 方法默认正序排列
第一个参数 -hash[word] 即单词出现次数的相反数
当我们对其进行正序排列时,相当于词频的倒序排列
当词频相同时,用第二个参数 word 进行排序,即字母正序排列
关于 sorted 排序的多种情况
词频正序, 字母正序
sorted(hash, key=lambda word:(hash[word], word))
词频倒序, 字母倒序 (reverse=True 即将sorted方法修改为倒序排列)
sorted(hash, key=lambda word:(hash[word], word), reverse=True)
词频倒序, 字母正序(本题要求)
sorted(hash, key=lambda word:(-hash[word], word))
词频正序, 字母倒序
sorted(hash, key=lambda word:(-hash[word], word), reverse=True)
深拷贝浅拷贝赋值的总结:
赋值=》赋值就是对原变量的引用
赋值的本质就是将一个对象的内存空间地址赋值给一个变量,让变量指向该内存空间地址。
浅拷贝=》父对象是拷贝,子对象是引用
浅拷贝是拷贝了源对象的引用,并创建了一个新的内存空间地址。但是引用的对象的子对象的地址仍然是源对象的,所以当源对象的子对象发生改变时,拷贝对象内的子对象同时也跟着改变。
深拷贝=》完完全全的拷贝,跟原来的变量没有引用关系
深拷贝就是彻底的拷贝,完全的拷贝了父对象及子对象,同时指向一个新的内存空间地址。源对象与拷贝对象之间的修改互不影响。














 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









