







目录
1. key和value
这⾥的key并不是索引的意思,下⾯根据情况具体说明:
Aggregate数据模型:key为聚合的键,value为聚合的值
Uniq数据模型:key为聚合的键,value为聚合的值
Duplicate数据模型:key为建表时指定的duplicate key(sorted column,只是⽤来排序),其余字段为value
rollup
->作⽤于Aggregate和Uniq数据模型:key为聚合的键,value为聚合的值
->作⽤于Duplicate数据模型:key为rollup命令添加的字段,且添加的字段都是key
2. 数据模型
2.1 Aggregate数据模型
建表语句如下:
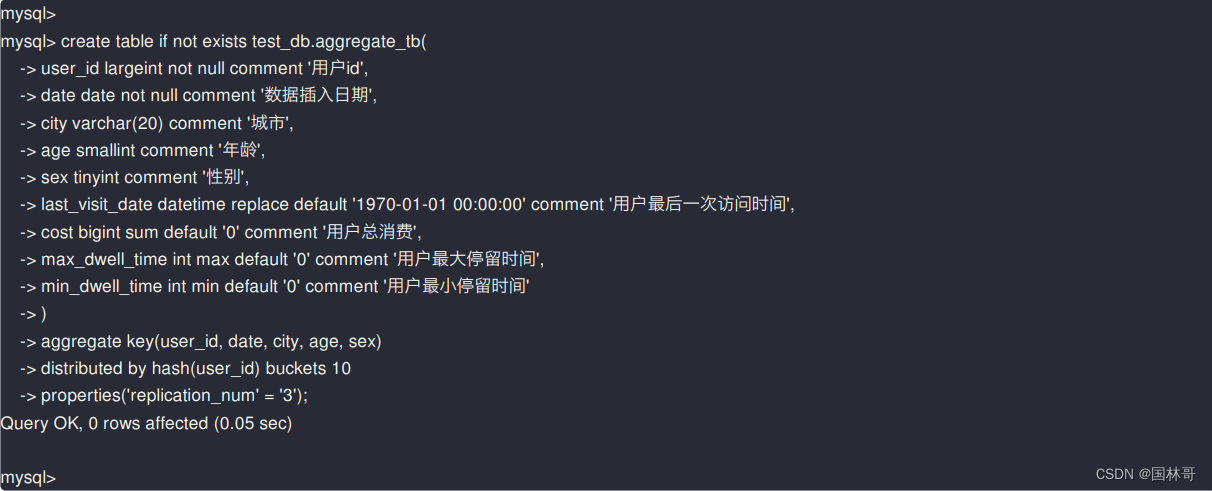
根据user_id, date, city, age, sex这5个key进⾏数据的聚合
replace表⽰取最后⼀个insert的数据;但在同⼀个insert中如果包含多条数据,会随机取⼀条
数据聚合分为3个阶段
1. 数据insert时,会对同⼀个insert批次的数据进⾏聚合
2. BE进⾏Compaction时,会对不同insert批次的数据进⾏聚合
3. ⽤户进⾏查询时,在BE后端可能不同insert批次的数据未进⾏聚合,此时会对符合查询条件的数据进⾏内部聚合(不⽤⽤户调 ⽤group by,会扫描所有列的数据)后,再返回给客户端
所有的key列必须在value列之前.
2.2 uniq数据模型
建表语句如下:

uniq数据模型其实是Aggregate数据模型的⼀种特列
根据user_id, username这2个key进⾏数据的聚合,其余字段按replace⽅式进⾏聚合
2.3 Duplicate数据模型
建表语句如下:

数据不会发⽣内部聚合,插⼊多少条数据,查询就会返回多少条数据
duplicate key只是指定了timestamp和type两个sorted column, ⽤于数据排序,并不能作为数据唯⼀的标识















 2238
2238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











