







深度学习教程 | 经典CNN网络实例详解
本系列为吴恩达老师《深度学习专项课程(Deep Learning Specialization)》学习与总结整理所得,对应的课程视频可以在这里查看。
引言
在ShowMeAI前一篇文章 卷积神经网络解读 中我们对以下内容进行了介绍:
- 卷积计算、填充
- 卷积神经网络单层结构
- 池化层结构
- 卷积神经网络典型结构
- CNN特点与优势
本篇内容ShowMeAI展开介绍和总结几个有名的典型CNN案例。这些CNN是最典型和有效的结构,吴恩达老师希望通过对具体CNN模型案例的分析讲解,帮助我们理解CNN并训练实际的模型。

本篇涉及到的经典CNN模型包括:
- LeNet-5
- AlexNet
- VGG
- ResNet(Residual Network,残差网络)
- Inception Neural Network
1.经典卷积网络

1.1 LeNet-5
手写字体识别模型LeNet5由Yann LeCun教授于90年代提出来,是最早的卷积神经网络之一。它是第一个成功应用于数字识别问题的卷积神经网络。在MNIST数据中,它的准确率达到大约99.2%。
LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络也是最近大量神经网络架构的起点。
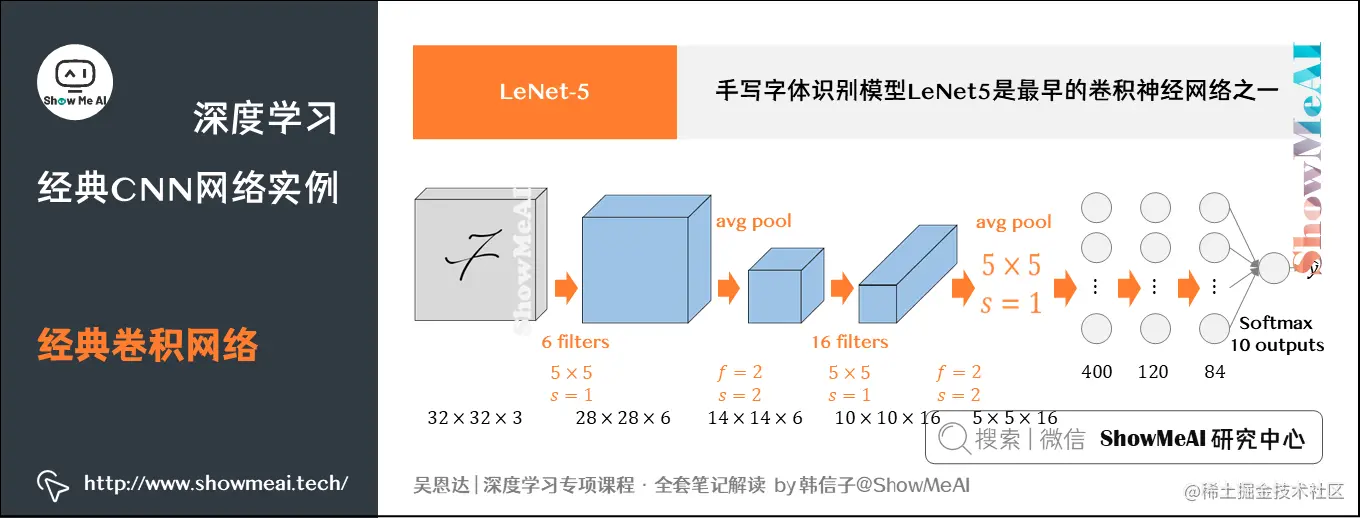
- LeNet-5针对灰度图像而训练,因此输入图片维度为(32,32,1)(32,32,1)(32,32,1)(注意其中通道数为1)。
- 该模型总共包含了约6万个参数,远少于标准神经网络所需。
- 典型的LeNet-5结构包含卷积层(CONV layer),池化层(POOL layer)和全连接层(FC layer),排列顺序一般为CONV layer ⟹\Longrightarrow⟹ POOL layer ⟹\Longrightarrow⟹ CONV layer ⟹\Longrightarrow⟹ POOL layer ⟹\Longrightarrow⟹ FC layer ⟹\Longrightarrow ⟹ FC layer ⟹\Longrightarrow⟹ OUTPUT layer。一个或多个卷积层后面跟着一个池化层的模式至今仍十分常用。
- 当LeNet-5模型被提出时,其池化层使用的是平均池化,而且各层激活函数一般选用Sigmoid和tanh。现在我们更多的会使用最大池化并选用ReLU作为激活函数。
相关论文:LeCun et.al., 1998. Gradient-based learning applied to document recognition。吴恩达老师建议精读第二段,泛读第三段。
1.2 AlexNet
AlexNet由Alex Krizhevsky于2012年提出,夺得2012年ILSVRC比赛的冠军,top5预测的错误率为16.4%,远超第一名。
AlexNet采用8层的神经网络,5个卷积层和3个全连接层(3个卷积层后面加了最大池化层),包含6亿3000万个链接,6000万个参数和65万个神经元。具体的网络结构如下图:


模型结构解析:
- 卷积层 ⟹\Longrightarrow⟹ (最大)池化层 ⟹\Longrightarrow⟹ 全连接层的结构。
- AlexNet模型与LeNet-5模型类似,但是更复杂,包含约6000万个参数。另外,AlexNet模型使用了ReLU函数。
- 当用于训练图像和数据集时,AlexNet能够处理非常相似的基本构造模块,这些模块往往包含大量的隐藏单元或数据。
相关论文:Krizhevsky et al.,2012. ImageNet classification with deep convolutional neural networks。这是一篇易于理解并且影响巨大的论文,计算机视觉群体自此开始重视深度学习。
1.3 VGG
VGG是Oxford的Visual Geometry Group的组提出的CNN神经网络。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。在提出后的几年内,大家广泛应用其作为典型CNN结构。
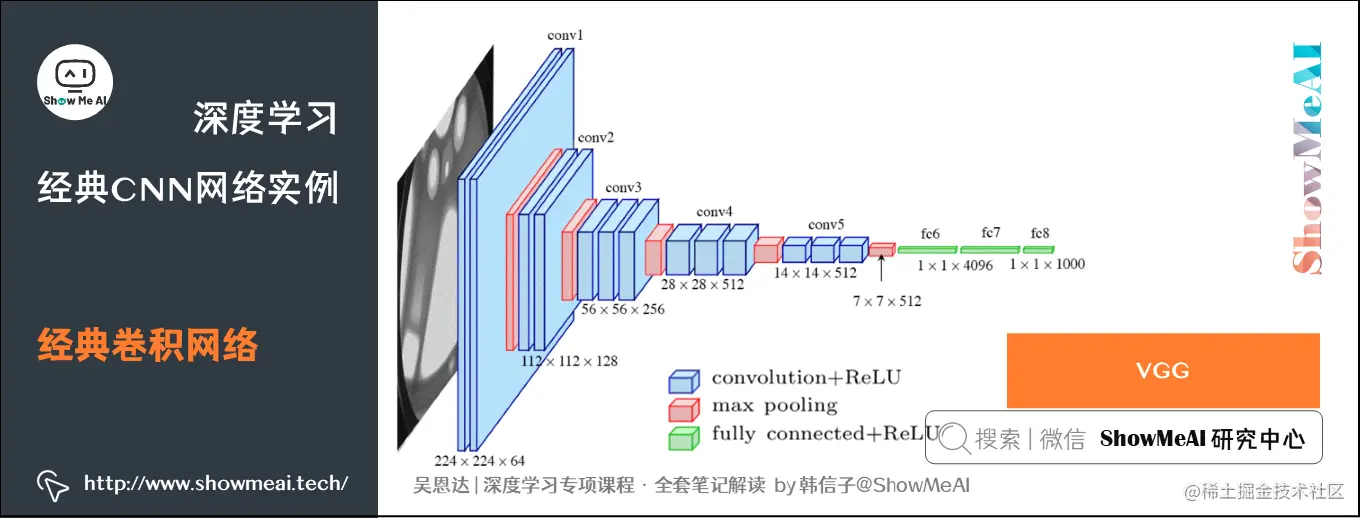

- VGG又称VGG-16网络,「16」指网络中包含16个卷积层和全连接
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









