






 阿里提出Multi-ScenarioRankingwithAdaptiveFeatureLearning(MARIA),针对多模态查询和差异化场景的点击率预估问题,通过场景感知的特征自适应学习改善排序性能。方法包括特征尺度调整、特征细化选择和跨特征关联模型,有效解决数据稀疏性和场景同步优化问题。
阿里提出Multi-ScenarioRankingwithAdaptiveFeatureLearning(MARIA),针对多模态查询和差异化场景的点击率预估问题,通过场景感知的特征自适应学习改善排序性能。方法包括特征尺度调整、特征细化选择和跨特征关联模型,有效解决数据稀疏性和场景同步优化问题。
阿里:Multi-Scenario Ranking with Adaptive Feature Learning(MARIA) 2023 SIGIR
背景与问题
由于能促进不同场景的迁移学习、减轻数据稀疏性和减少消耗,多场景学习广泛地应用在推荐系统中。
场景:在多种的搜索场景下,有拍照搜索(Visual Search)、相似搜索(Similar Search)和外部媒体商品引导和触发的兴趣搜索(Interest),拍照搜索以照片作为Query,相似商品搜索和兴趣搜索以搜索的商品信息作为Query。不同搜索场景和Query模态下用户的搜索意图和行为习惯具有明显的差异。针对上述异构模态Query和差异化显著场景下的点击率CTR预估问题进行研究
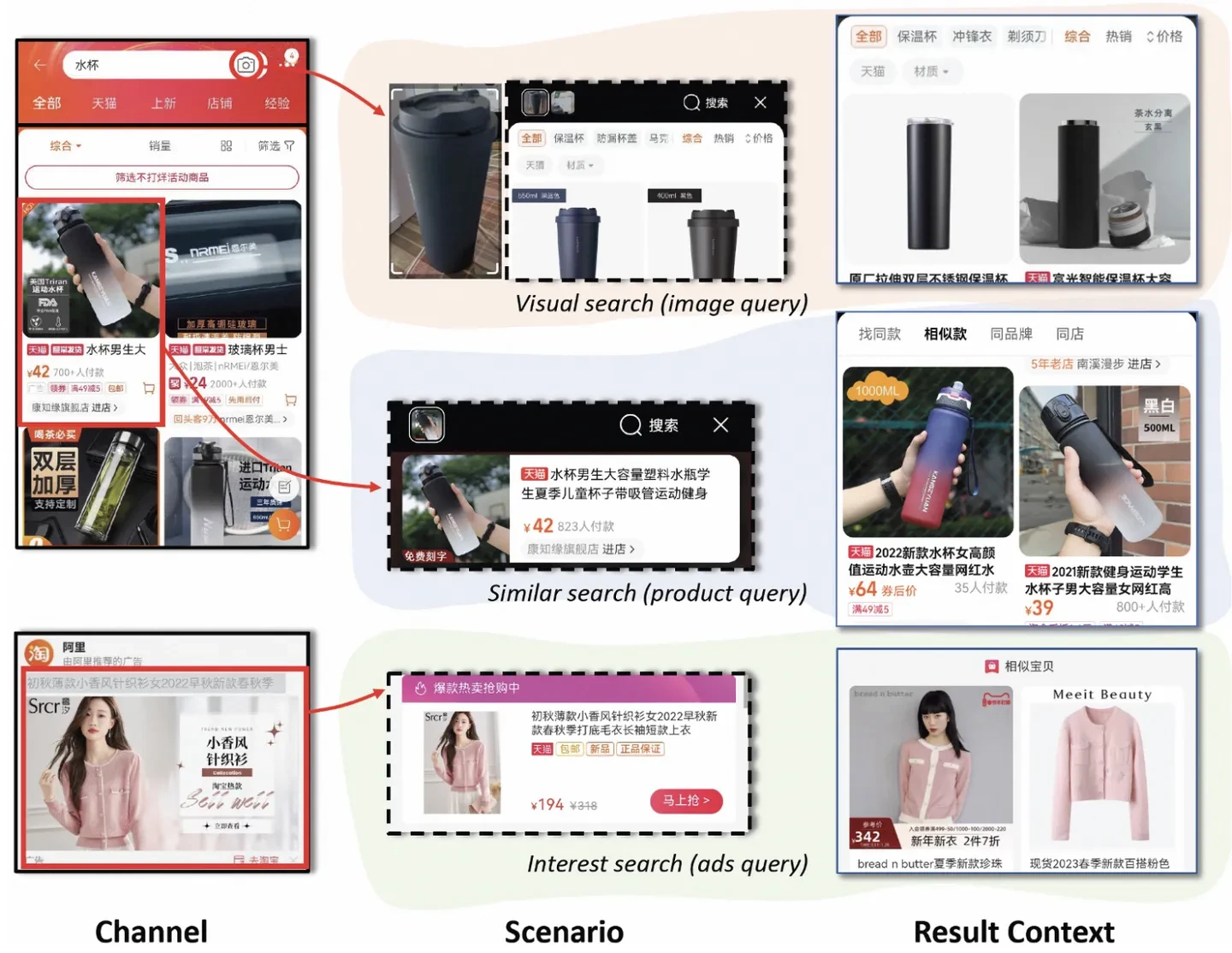
多场景任务下,传统的对场景单独建模会遇到数据稀疏性和难以维护同步优化的问题。最近的方法大多数是关注与对场景的共性与差异性建模,多场景学习通常分为:Auxiliary Network, Expert Network, Multi-Tower Network
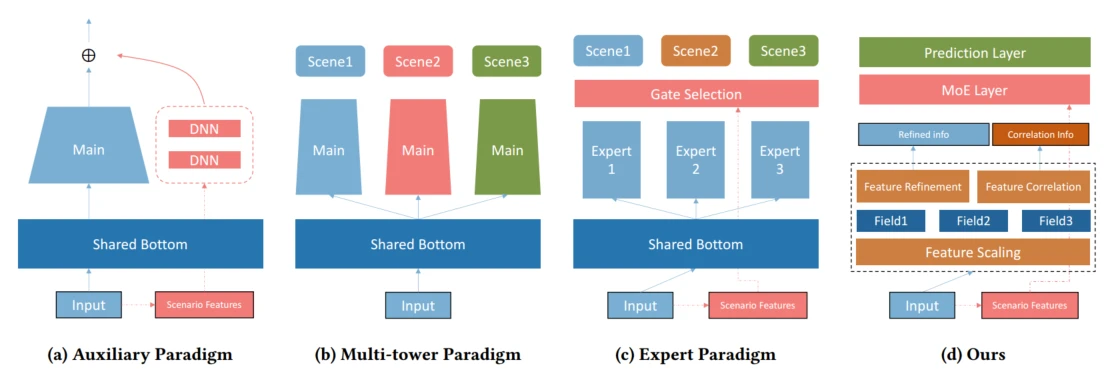
这些方法尽管都取得了进步,但是他们公平地认为底层生成的表征对不同的场景是相同的,使用简单的Shared Bottom策略进行embedding特征共享,所以对底层的特征自适应学习是值得探索的。
直觉地认为,不同场景可以根据他们特定的特征不同地激活用户的意图。
意思就是,不同的特征在不同的场景下有不同的重要性。相比最优网格搜索方法,以场景感知的方法来改进更多的判别性特征,可以轻松获得更好的排序性能,但是这种方法在现实生活中很少应用。
因此,本文提出自适应特征学习多场景排序方法Multi-Scenario Ranking with Adaptive Feature Learning(MARIA)。设计Maria将场景语义注入到网络底部,以获得更具判别性的特征表示
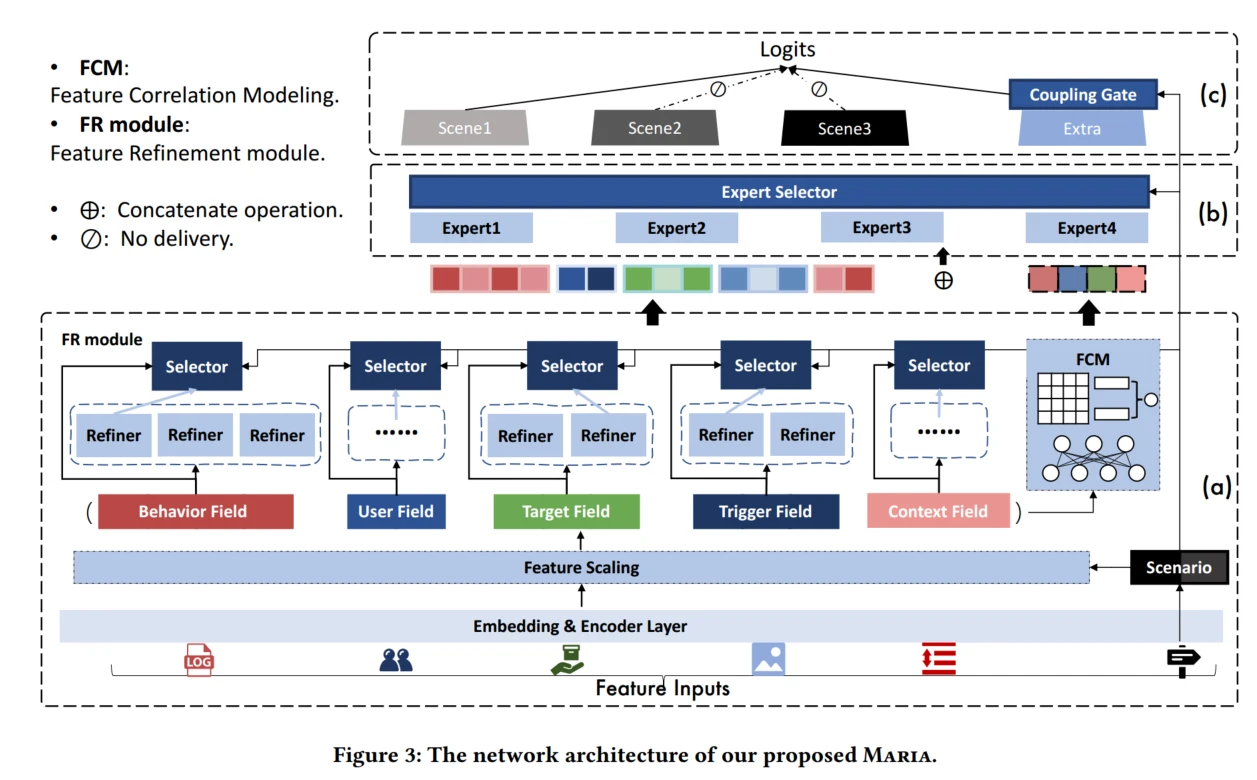
MARIA三个组成
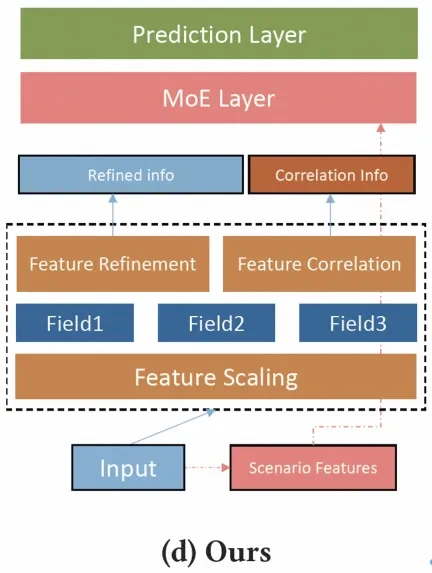
feature scaling:通过挤压或放大特征值来识别每个特征的重要性,强调场景相关的特征域并抑制不相关的特征域
feature refinement:对每个特征域使用一个自动精细化选择子网络,场景对应的高层次的语义可以被最优的refiner网络提取。目的是选择最优的refiner网络来在实例级别产生更多的区别性语义。
feature correlation modeling:进一步捕获跨特征域的语义关联模式,推导出各场景间的相关性,作为互补信号。
最后将这些结果拼接起来输入到MOE中,上述步骤侧重于提取场景特定的特征,因此,为了利用共享知识,建立一个额外的共享塔来进行最终预测。
Methods
Formulation
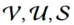 分别代表所有的Product(item),所有的用户和所有的场景
分别代表所有的Product(item),所有的用户和所有的场景
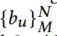 是用户的行为序列,其中
是用户的行为序列,其中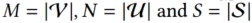
对于每个用户u,对应的行为序列由下列时间序列组成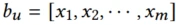 ,其中
,其中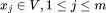 ,m是预定义的最大容量
,m是预定义的最大容量
Product域包括P个属性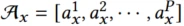
User域包括L个属性
这些属性会有连续特征,将其转化为类别特征
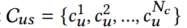 代表用户u在场景s下的上下文特征,这些上下文特征通常描述用户端的页面和物理环境
代表用户u在场景s下的上下文特征,这些上下文特征通常描述用户端的页面和物理环境
user域特征、products域特征和上下文特征的总数可以被描述为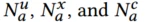
论文的任务是精确的识别出用户感兴趣的target product x i x_i xi
目的是为了设计一个统一的排名框架,适用于产品搜索和顺序推荐
对于产品搜索,有一个额外的从user产生的输入query。由于这些场景S涵盖了不同的服务,所以query的形式有图像、文本、产品、广告。使用 trigger 来代表这些queries,就是将输入搜索的内容放进特征
假设每个trigger t 包括 O个属性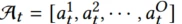 ,
,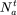 是trigger的特征总数。
是trigger的特征总数。
总的公式
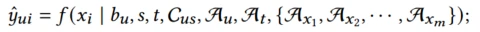
代表的是对于trigger t,用户u与product x i x_i xi交互的可能性
Encoder Layer
Embedding Layer

使用7个embedding表来表示:用户、产品、用户属性、产品属性、queries、query属性、上下文、场景
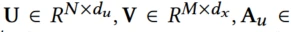
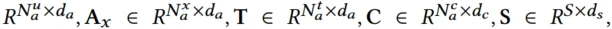
d是embedding长度
将产品和产品属性的embedding拼接起来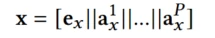 来充分表示产品的语义属性
来充分表示产品的语义属性
因此,可以形成行为序列bu的特征矩阵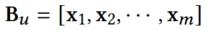
同产品embedding,用户、queries、上下文的embedding可以如下表示
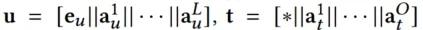
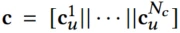
*代表trigger是基本的产品query还是图像query,使用线性变化来使这两种query维度相同
Sequence Encoder序列编码
对用户连续不断的行为建模,选择使用解码器来从序列bu来提取用户的喜好
自注意力机制可以进一步利用不同场景的语义信息联系
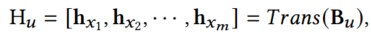
从场景内部的角度来看,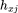 是产品
是产品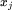 的顺序表示,意思是在场景内交互的产品的顺序
的顺序表示,意思是在场景内交互的产品的顺序
之后,一个使用trigger感知注意力模块来聚集trigger t的相关信息
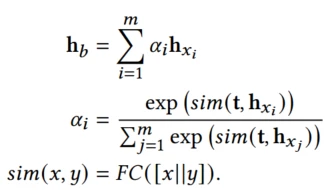
sim是全连接层,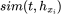 的意思是把单个trigger(搜索)下发生的每个顺序行为
的意思是把单个trigger(搜索)下发生的每个顺序行为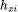 分别输入到全连接层。
分别输入到全连接层。
然后做softmax处理得到trigger对每个行为的权重再加权求和聚集得到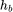 是用户历史行为的trigger感知表征
是用户历史行为的trigger感知表征
在推荐场景下,trigger t换成target表征
x
i
x_i
xi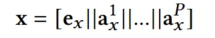
最后将不同特征域的表征拼接到一起Q
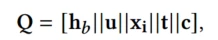
Q包括:历史行为的trigger感知表征、用户及其属性表征、target product及其属性表征,trigger表征和上下文表征
Feature Scaling

不同的特征在不同的场景有不同程度的作用,如在拍照搜索场景图像query起到的作用比在产品搜索场景大。同时考虑用户兴趣和目标产品的相互作用
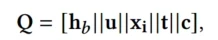
因此FS的作用就是根据场景Indicator来对Q的每个特征进行压缩或放大的作用
对于Q的每个特征表征,计算缩放系数
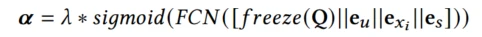
输入Q、用户表征、target product表征、场景表征计算得到权重
freeze是梯度截断,目的是为了避免过拟合和梯度冲突, x i x_i xi是场景indicator embedding
和标准自注意力机制相比,缩放因子 λ \lambda λ可以大于1,由此可以放大一些重要的特征
特征经过FS层后的输出,对Q的每个特征实现加权
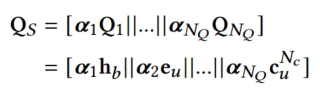
α \alpha α是考虑了Q的5个特征字段来计算出来的,对特征之间的联系进行了隐式建模
Feature Refinement
为了在实例级别调节特定于场景的特性,设计一个feature refinement模块,使用自动化refiner选择网络来支持高层及的语义解码。
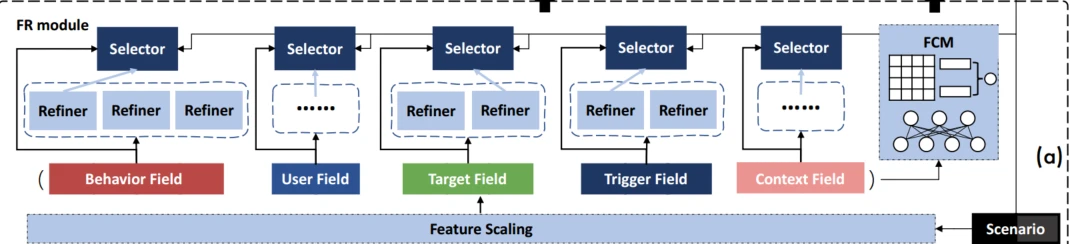
对每个特征域设计一系列的feature refiner,refiner网络由FC构成,激活函数是relu,每个域对应一个selector网络。
如图所示,refiner selection的实现是以场景感知的方式实现的,将FeatureScaling模块的输出划分为不同的Field,即意义相近的一组特征。
selector接收每个field的特征输入以及场景embedding es输入,计算出field对应的多个Refiner的权重
β
\beta
β,以用户行为field  为例
为例
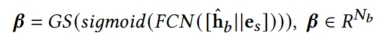
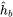 与
x
i
x_i
xi通过FC网络然后通过sigmoid,再通过Softmax,
N
b
N_b
Nb代表field的refiner的数量,
β
\beta
β有Nb个
与
x
i
x_i
xi通过FC网络然后通过sigmoid,再通过Softmax,
N
b
N_b
Nb代表field的refiner的数量,
β
\beta
β有Nb个
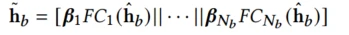
FC代表refiner网络,将多个refiner网络的输出与对应的
β
\beta
β相乘,并拼接起来,得到高级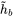 表征向量。
表征向量。
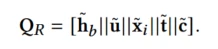
对其他特征域做同样的操作,得到所有特征域的高级表征
Feature Correlation Modeling
对不同的特征域之间的语义联系进行显式建模
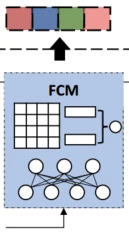
首先对所有特征域表征向量通过全连接层映射成相同的维度大小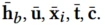
再对特征域之间两两点积交互,计算相关性,再拼接起来
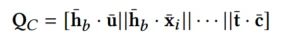
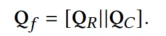
Network Layer
经过了上述一系列自适应特征学习的任务后,使用标准MOE作为主网络
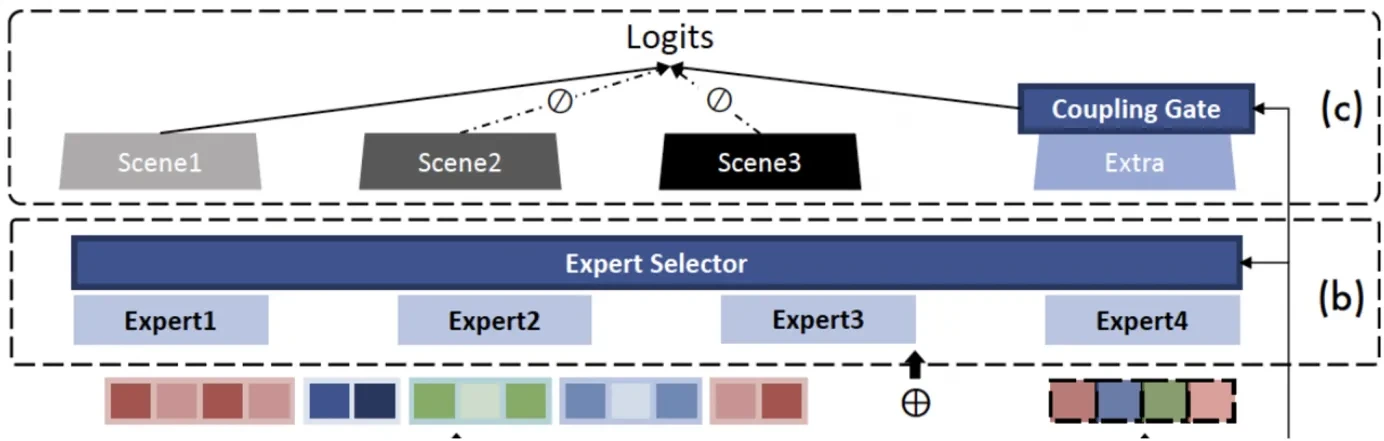
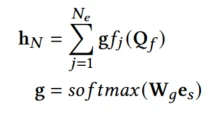
Prediction and Model Optimization
在预测层借鉴多塔的结构,搭建场景特定塔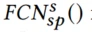 和共享塔Extra Tower
和共享塔Extra Tower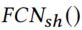 ,来增加场景间的信息共享,如用户在场景1的兴趣可以被场景2捕捉,最终预测如下
,来增加场景间的信息共享,如用户在场景1的兴趣可以被场景2捕捉,最终预测如下
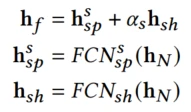
α s \alpha_s αs是一个耦合系数,用来控制共享信息的影响力,当目标场景和其他场景的相关性较少时,会希望这个系数更小一点
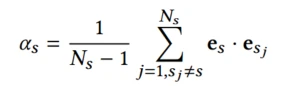
即当前场景与其他场景的点积求和平均,相关性小的时候,系数会小。
最后,用户u和product x i x_i xi交互的可能性输出结果如下
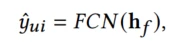
Loss:
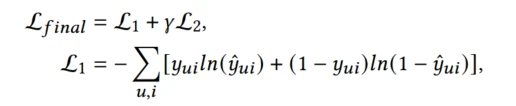
L2是所有模型参数的L2正则化, γ \gamma γ是超参数
总结与其他细节
由于Refiner本身可以起到一个降维的作用,同时在FCM层将特征维度统一,减少了网络层和预测层的参数量
Feature Scaling类似于EPNet、SEnet
Feature Refinement类似于对多个特征field使用MOE,在gate处加入了场景指示
Feature Correlation Modeling是PNN
实验分析
数据集,公开数据集与业务数据集,都是三个场景
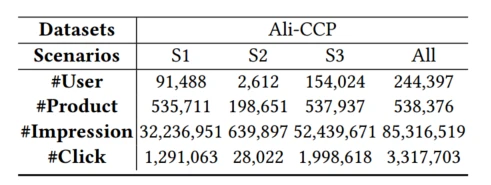
对比实验:在两个数据集上表现良好,AUC提升,缓解场景跷跷板的问题

**消融实验:**各个模块都是正向效果
Refiner权重可视化:
随机采样Alimama数据集中1000个样本中User Field和User behavior Field中的第一个Refiner的权重,分别画出三个场景的分布图
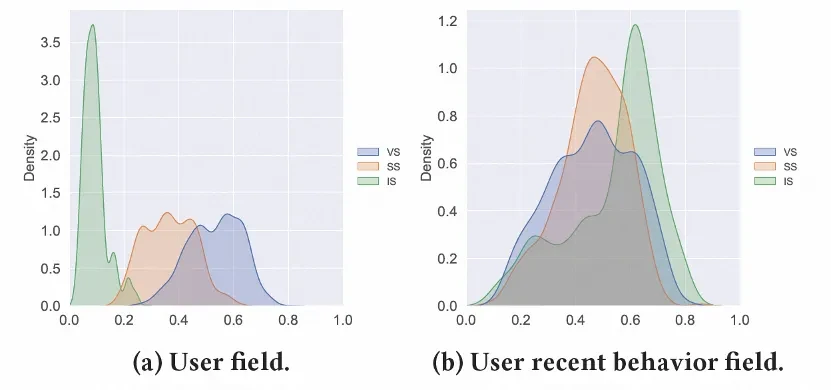
三个场景的分布有明显的差异,体现了用户侧表征在三个场景中的空间位置存在明显不同。
具体来看,SS和IS场景具有一定的相似性,但VS场景和另外两个场景存在明显差异,几乎没有交集。针对Alimama三个场景的描述,由于VS场景的搜索Query和其他场景不同,因此用户的意图和偏好与另外两个场景差异更为明显。而通过FR结构,我们可以较好的达到端到端微调的作用,实现特征层面的场景间解耦合。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









