






美团:HiNet: Novel Multi-Scenario & Multi-Task Learning with Hierarchical Information Extraction 2023ICDE
背景和问题:
问题:
多场景多任务学习在工业应用推荐系统中,基于MoE架构的多场景学习是一种有效的方法。但是MoE-based的方法旨在在相同的特征空间中处理所有信息,这样子不能处理不同的场景和任务中内部复杂的关系。
如在美团app中,用户可能会在多个场景上有多个行为交互
随着场景的增加,为每个场景单独建模会有以下问题:
1、仅根据场景本身的数据不能利用到跨场景的知识,同时考虑到在多个场景中会有重叠的用户和items
2、长尾场景没有足够的数据来训练单独的模型
3、单独建模耗费人工和资源,降低效率
但是同时,简单的合并数据建模一个共享的模型也不能每个场景的独特信息。
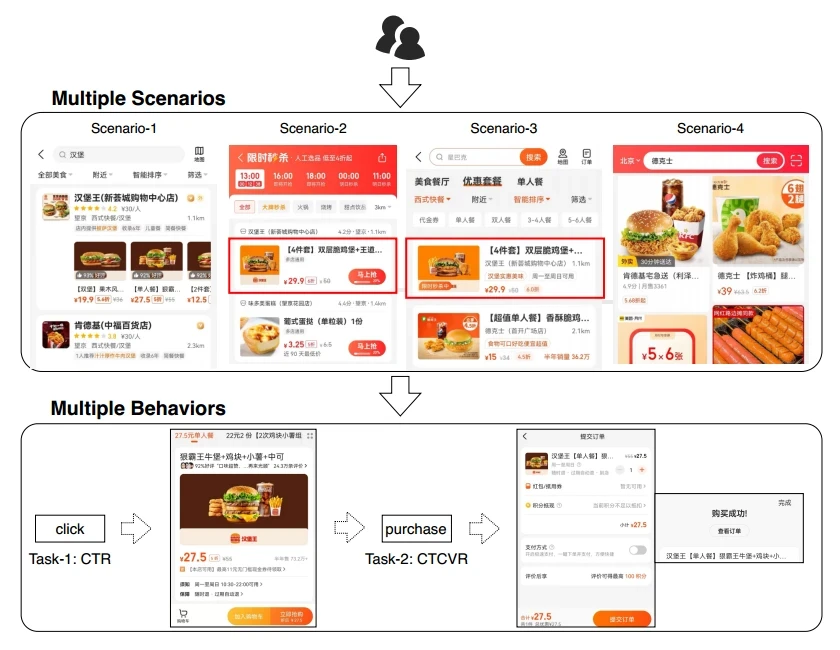
除了多场景推荐的问题,用户在每个场景的满意度和参与度通常都有不同的指标需要同时优化,比如CTR、CTCVR。
因此建模一个有效且统一的框架来在多种场景下优化各种复杂的指标是非常重要的,即多场景多任务优化问题。
在最近的一些研究中,相关方法往往是将多场景推荐做为一个多任务学习(MTL)问题进行建模,此类方法大多是使用MMOE来将多场景推荐问题建模成一个多任务学习问题。
但是使用MTL模型在相同的特征空间中处理多个场景的数据,这很难充分捕捉到具有多个任务的众多场景之间的复杂关系,因此也无法进一步提升多场景多任务学习模型的性能
在论文中,基于直觉认为场景相关和任务相关的信息是处于不同粒度的级别的,因此需要分层次处理,所以论文提出了一种层次化信息抽取网络,设计一个端到端的两层框架来联合建模跨场景和跨任务的信息共享和协作。
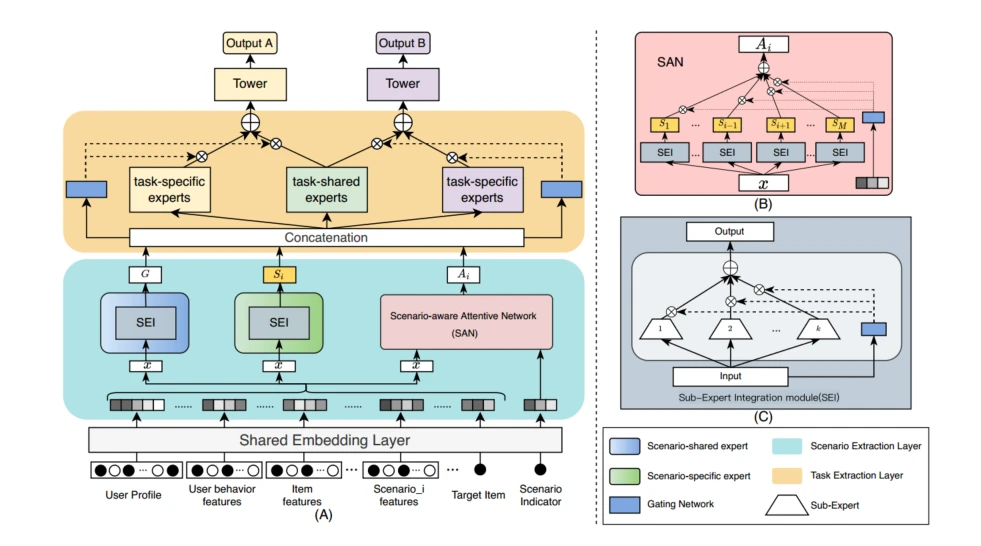
- 在场景提取层,通过场景共享experts和场景特定experts来提取场景共享和场景特定的信息。为了增强其他场景在当前场景的表征学习,设计一个场景感知注意力网络模块来显式建模场景间的相关性。
- 在任务提取层,使用具有任务共享experts和任务专用的experts的门网络,有效地缓解了多任务学习中共享知识和任务专用知识之间的参数干扰。
- 通过分开场景层和任务层,在不同场景中的多任务可以显式地划分到不同的特征空间进行优化,有利于模型性能的提高。
Methods
Formulation
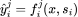
λ
i
\lambda_i
λi是第i个场景,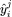 i个场景下第j个任务的预测,x是输入的稠密特征
i个场景下第j个任务的预测,x是输入的稠密特征
原始的输入特征包括:任务属性、任务行为、当前场景特定特征、item特征
数值特征首先转化为类别特征、类别特征再经过embedding层得到稠密向量
Hierarchical Information Extraction Network
一、Scenario Extraction Layer
场景信息提取层在场景间共享和迁移有价值的信息的同时还提取场景特定的特征。包括场景共享专家网络、场景专用网络和场景感知注意力模块
专家网络:
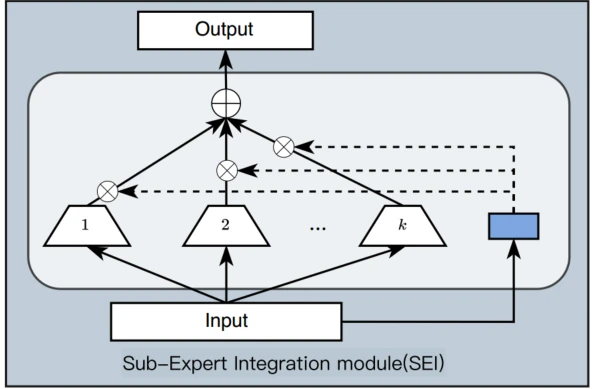
共享专家:
考虑到场景间用户交互和item的重叠,在多个场景中会存在共享信息,设计共享专家网络,共享专家由SEI(子专家集成模块)构成,如图,该网络是由多个专家与gate的输出相乘最后求和输出组成的一个模块
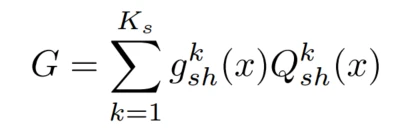
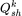 代表的是第k个由mlp和激活函数构成的子专家,
代表的是第k个由mlp和激活函数构成的子专家,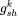 是第k个子专家的gate网络,由线性层和softmax构成,x是输入embedding
是第k个子专家的gate网络,由线性层和softmax构成,x是输入embedding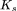 代表子专家的数量
代表子专家的数量
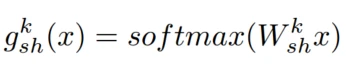
场景专用专家:
同时,对场景专用信息的提取网络同样也是通过SEI来构成
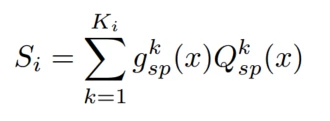
代表的是第i个场景下的子专家和gate
场景感知注意力:
在场景当中会存在相互的联系,其他场景的信息也可以对当前场景有所贡献,对当前场景形成补充。考虑到场景相互之间的贡献不一样,设计了一个场景感知注意力SAN模块来估计其他场景信息对当前场景的重要性。
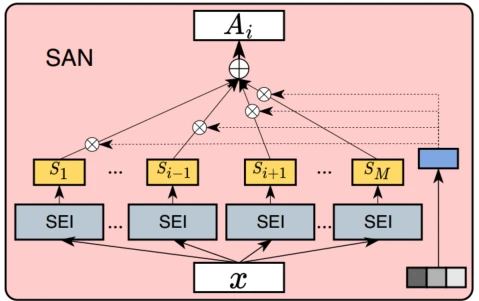
SAN的输入包括两部分:
1、场景指示
s
i
s_i
si的embedding 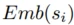 ,用来通过gate网络的softmax来计算其他场景的重要性权重
,用来通过gate网络的softmax来计算其他场景的重要性权重
2、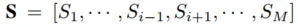 其他场景专家的输出表征
其他场景专家的输出表征
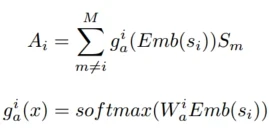
输出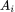 通过场景指示来计算每个场景专家输出表征的权重再与输出表征相乘求和
通过场景指示来计算每个场景专家输出表征的权重再与输出表征相乘求和
注意力模块可以根据复杂的场景相关性不同程度地在跨场景上传输信息
场景信息的总输出为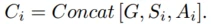
Task Extraction Layer:
为了解决多任务学习中的跷跷板问题,任务提取层主要是由CGC构成,使用任务共享专家网络和任务特有专家网络。前者主要负责学习当前场景中所有任务中的共享信息,后者用于提取当前场景中各个任务的特有信息。
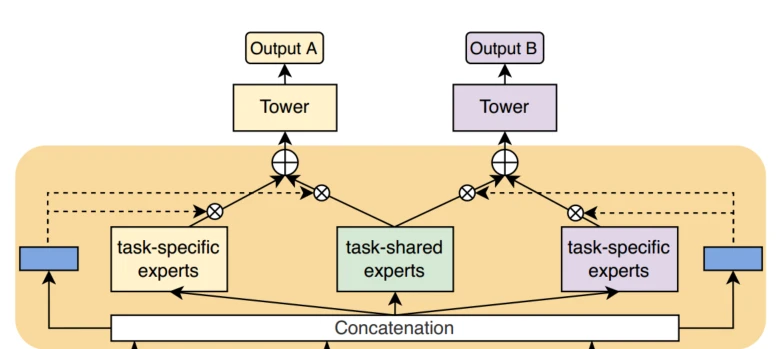
Tower的输入
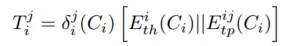
gate网络
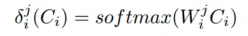
Tower的输出
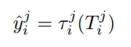
Loss
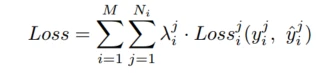
Loss为交叉熵, λ \lambda λ是根据经验设定的超参数,一般来说设为当前场景数据集的倒数
总结与细节:
在related works中提到,PLE解决了MMOE的跷跷板问题,但是场景特征都在同一特征空间下,STAR解决了PLE场景特征都在同一特征空间下的问题,但是忽略了别的场景也会对场景场景信息有贡献的问题。
实验细节:

多任务模型和多场景模型都有跷跷板现象:
多任务:场景a中PLE的CTCVR高于MMOE,但CTR低于MMOE,两项任务没有同时改善
多场景:STAR在CTCVR的表现在场景a、b上高于HMOE,但是在c、d、e、f低于HMOE,统一指标不能在多个场景同时改善
引入SAN和CGC模块就捕捉了任务和场景的相关性,解决了这些问题
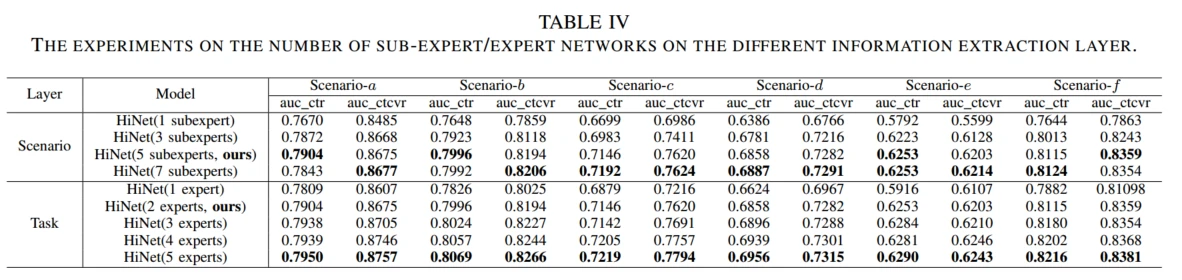
专家网络超参数实验中,看得出子专家越多或者任务专用专家越多,效果都越好















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









