






阿里:SAR-Net: A Scenario-Aware Ranking Network for Personalized Fair Recommendation in Hundreds of Travel Scenarios
背景和问题
一、多场景建模问题
(1)为每个场景单独训练建模,缺点是模型的数量会随场景的数量增加,同时场景的数据规模小难以训练出一个好的模型。
(2)用所有的场景统一训练一个ranking模型,缺点是不同场景的流量特征和语义特性都非常不一样,难以训练出一个合适的模型。
(3)使用multi-task框架输出多个预测用于不同的场景,现有的多场景建模通常使用early-sharing的策略,然后再进入不同的任务子网络,但是这样就忽略了用户的跨场景迁移,也忽略了不同场景的输入信息的重要性。
解决方案:
(1)使用多任务框架同时输出多个预测结果用于不同场景。现有多任务模型采取early-sharing早分享策略,然后再进入不同具体任务子网络,这样做就忽略了用户跨场景的兴趣迁移,而且不同场景对输出的重要性也不相同,这在之前的模型中也没有显式考虑这一点。
(2)论文设计两个注意力模块,来分别根据场景特征和物品特征来提取用户的跨场景兴趣信息
(3)设计一个场景线性变换来加强每个场景的重要性信息,同时几乎不会增加模型的总体参数,进一步适应对应场景的特征。
二、数据公平性问题(Data Fairness Issue)
论文研究的是人为干预偏差,即推荐系统往往会经过Matching-Ranking-Reranking的过程,而Reranking会被许多人为规则干预,如为了确保双十一期间某些商家或物品的流量,这就自然导致得到的日志有偏差,如果据此训练模型,那就会导致模型在Ranking阶段即产生有偏结果,比如会过度曝光某些商家。
现在处理干预偏差的方法就是对人为干预而造成过度曝光的目标进行降采样,但是这样子会消耗大量人力,尤其是会在推广阶段中频繁地修改干预规则。除此之外,过度的降采样会浪费数据集中的数据
解决方案:
(1)构造了一个公平系数(fairness coefficient)表示不同物品的干预程度,来降低人工干预的某些item的权重。
(2)基于公平系数,分别设计了一个去偏差专家网络和去偏差损失函数。设计两个debias expert network去偏差专家网络:scenario-specific experts场景特定专家和scenario-shared experts场景共享专家,二者分别独立输出,最后再进一步通过multi-scenario gating module多场景门控模块来融合这些特征最终结果。
Method
Formulation:
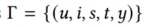
u为用户、i为用户交互的item、s是场景、t是推荐时间、y是标签
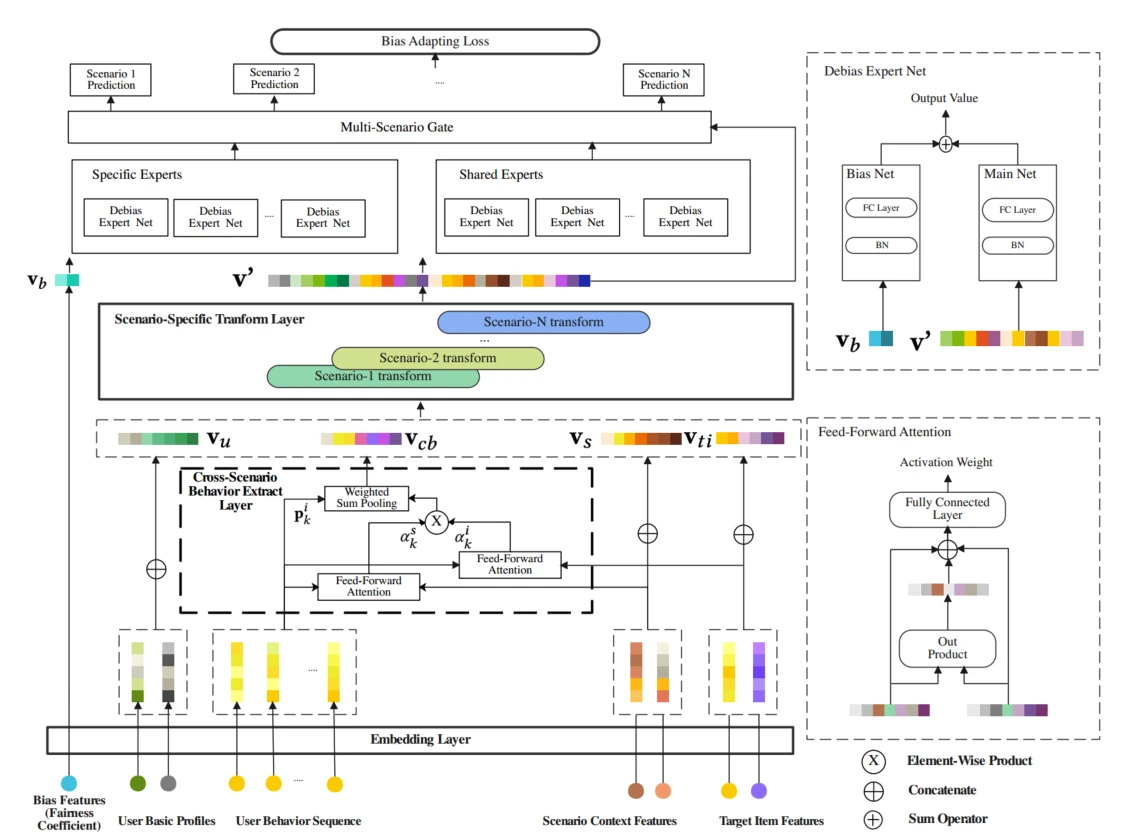
Embedding层
共有5个部分的输入特征:
用户信息:userid,country
用户跨场景行为:behavior type click,list of user interaction in all scenario
场景上下文特征:time,current scenario id,current scenario type
目标物品特征:item id,category id
干预偏差特征:公平系数
其中有几个点值得一提:
(1)用户的交互序列是从全场景采样的,而不只是某一场景。目的是做跨场景的交互。
(2)对于序列中的某一item,会把该item的所有特征向量拼接[itemId || category || …]。
(3)公平系数是一个sample-wise的常数,当有一天的线上数据之后再计算,其用途一是作为偏差专家网络的输入特征,二是作为loss里的样本权重。
Fairness Coefficient 公平系数
干预偏差会使数据分布偏向于加权的items,模型训练的时候会不可避免地倾向于学习这些items,提出公平系数来衡量个体样本的重要性,代表着不同items的干预程度。
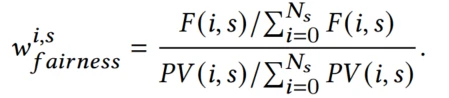
**PV(i,s)**代表场景s下曝光的item i的数量。
**F(i,s)**代表在场景s下曝光的所有item i 的pctr总和。
Ns代表场景s内的所有item数量。
直观的说,当某item的pctr并不高,但由于人为干预导致其曝光过高的时候,公平系数就会变小,从而给给当前prediction重新加权。
Cross-Scenario Behavior Extract Layer跨场景行为提取层
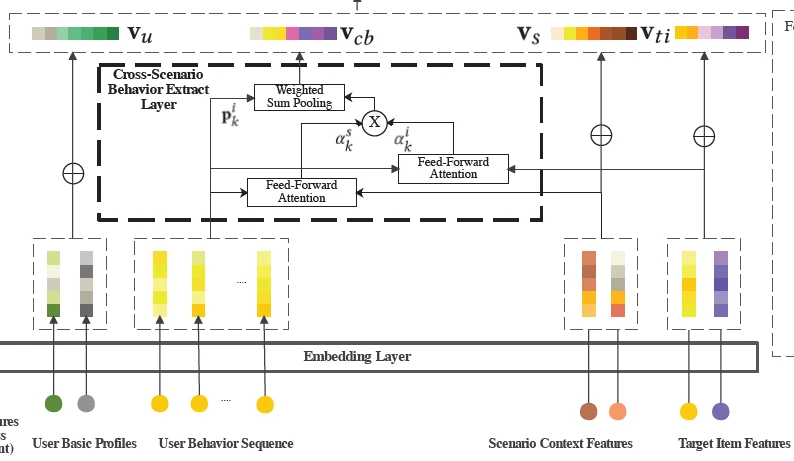
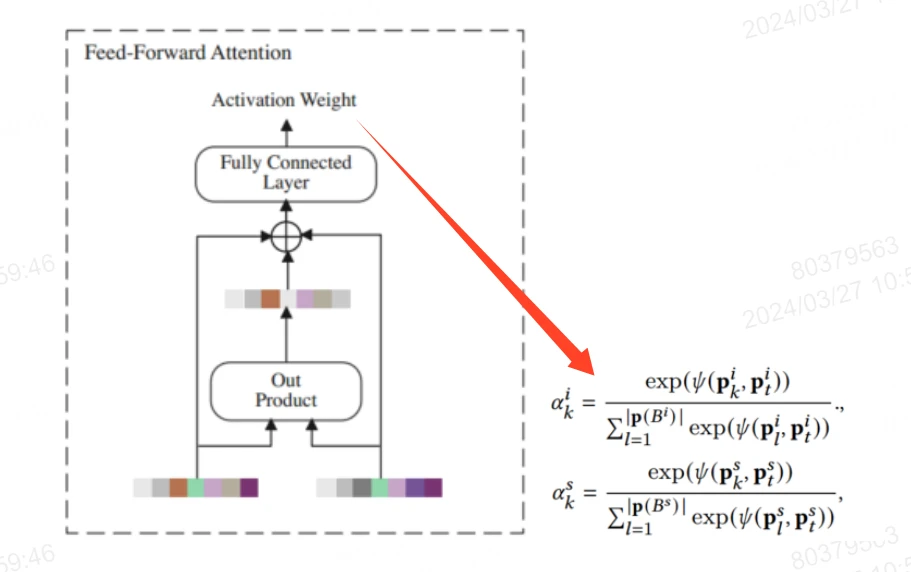
该模块提取用户的跨场景兴趣迁移,主要有3部分输入:用户的交互序列,场景的上下文特征,目标Item特征。将用户的跨场景行为聚合为统一的表示为 ,其中xi表示一次交互行为,ai是这个行为的权重,这里的重点问题是如何计算ai?在拿到用户的全场景交互序列的时候,我们不难想到使用注意力机制来做特征提取。
,其中xi表示一次交互行为,ai是这个行为的权重,这里的重点问题是如何计算ai?在拿到用户的全场景交互序列的时候,我们不难想到使用注意力机制来做特征提取。
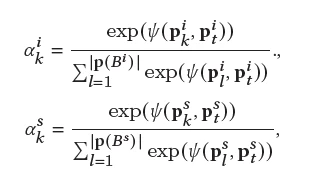
上述给出的ak_i和ak_s,分别代表用户的第k次行为与目标item和目标scenario的相关性,item行为序列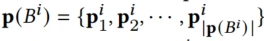 ,每个是交互item的特征,包括id,类别,目的地
,每个是交互item的特征,包括id,类别,目的地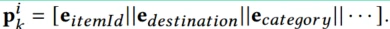 。
。
场景上下文序列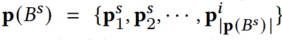 ,每个是行为发生的场景的上下文特征,包括id、场景类型、时间
,每个是行为发生的场景的上下文特征,包括id、场景类型、时间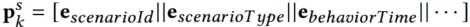 。
。
而相关性的计算采用的是feed-forward attention,具体来说就是对target item 和交互item做外积再和原来的拼接再传入FC输出一个权重,最后两个权重乘在行为序列上。
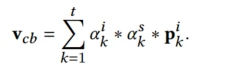
Scenatio-Specific Transform场景专用线性变换
该模块可以单纯理解为对特征向量v做了一次线性变换,以聚集用户行为序列vcb、用户属性序列vu,target item序列vti,场景上下文序列vs四部分做输入,线性变化的结果是生成了1-N个场景的特征向量。
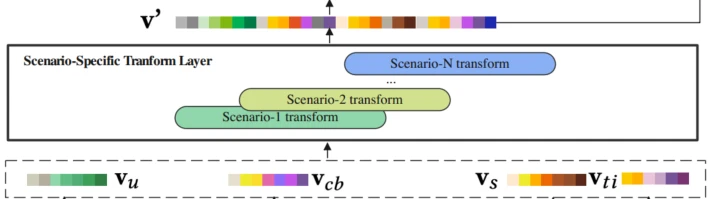
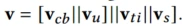
对于第i个场景,对序列v做线性变换
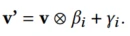
两个参数都是场景感知参数,与v有相同的维度并做一次element-wise的操作(论文中没有提到为什么这样做,猜测是对不同场景做分化)。从图中来看对于每个场景,都会有各自的特征向量v’。
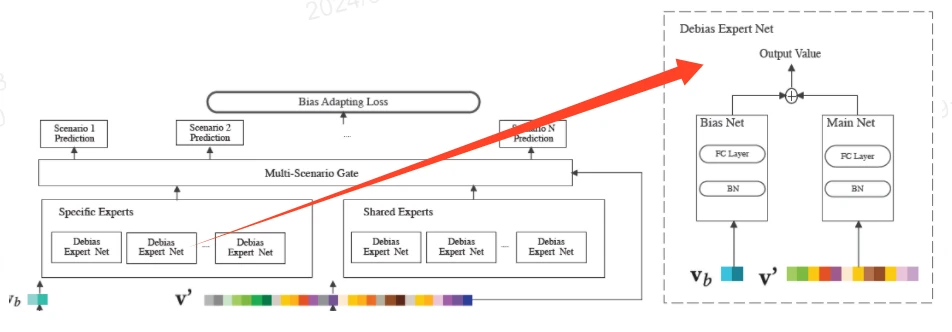
Mixture of Debias Experts偏差专家网络
使用专家网络来解决负迁移问题,对于跷跷板问题,每个场景都有私人专家,所有场景都有共享专家。
而私有专家和共享专家的子模块是一个Debias Expert,它由偏置网络和主网络构成。
主网络接收上一层的输出v’,偏差网络接受偏差特征(公平系数),根据场景识别与item识别的原则来预测对人为干预偏差的权重,与主网络的预测分数求和得到这个expert的输出。
最终共享专家和特有专家的输出会通过gate的方式融合,gate网络是激活函数为softmax的fc层,gate接收的输入是场景线性变换层的输出v’,它会作为一个选择器来计算选择的预测分数的加权权重,将该场景下所有的specific experts和shared experts加权求和在一起。
Bias Adapting Loss
由于提出了公平系数的概念,公平系数高的样本其受到的人为干预越少,因此希望从这些样本中学到更多信息,就参考了类似focal loss的方式,对交叉熵损失加权。
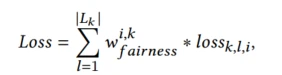
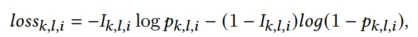
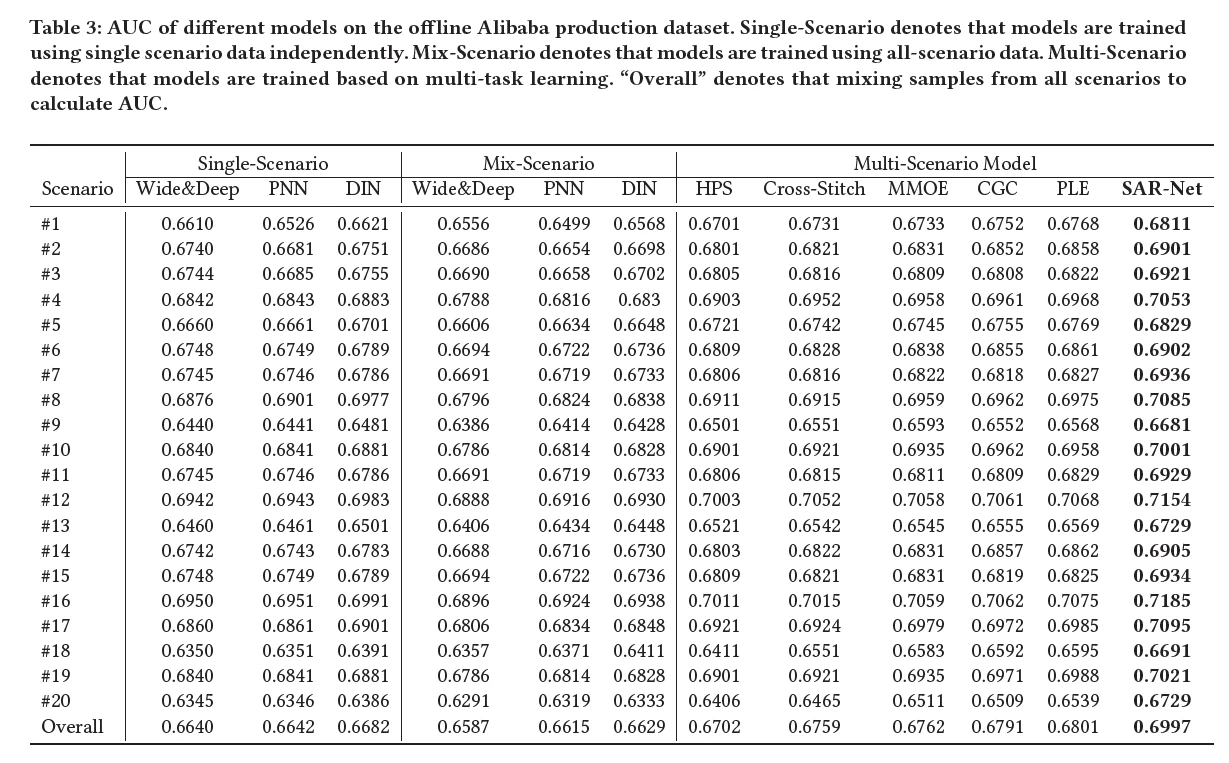
实验对比
【对比其他模型】
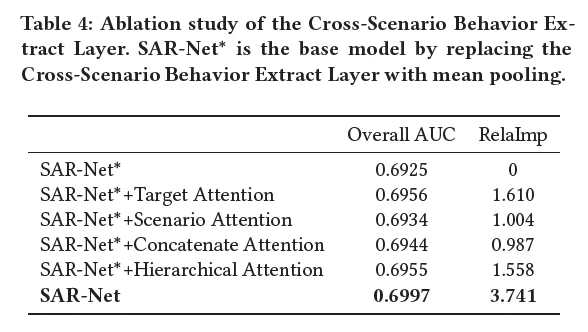
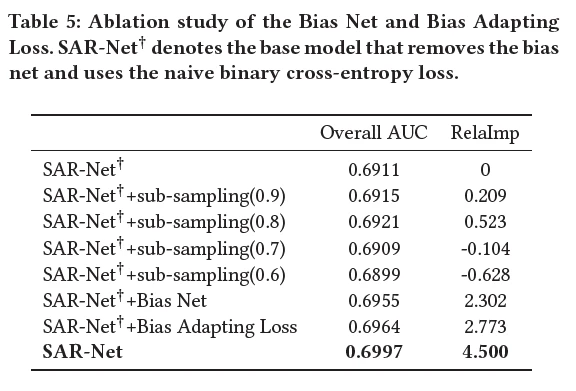
【消融实验】
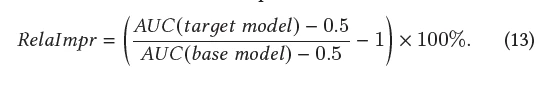
总结与细节
1、文章的重点是通过偏差网络和偏差loss来缓解人为干预的偏差问题,算是大多数相关工作容易忽略的。但实际应用中有几个问题,一是公平系数的计算需要有一天真实数据的收集,二是debias模块只在训练中使用,线上部署时并没有用到。个人猜测是为了保证模型的鲁棒性。
2、另一个亮点是论文的数据处理和对attention的利用,使用全场景的交互序列更加适配attention结构,并且从消融实验来看,attention对基础模型的auc提升比较明显。而且SAR-Net是将item和场景attention分开计算的,其效果要比单独计算其中一个更好。
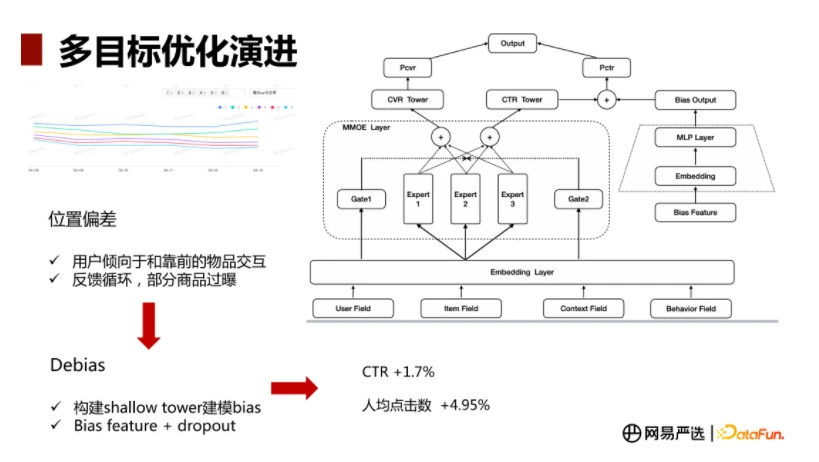
3、最近看到一个博客也有对偏差问题的处理。网易严选跨域多目标算法演进,不同的是他描述的是位置偏差,即用户更倾向于点击曝光位置靠前的物品。其Debias的方式为Bias特征+消偏模块,bias特征包括商品的曝光位置,设备型号,用户身份等可能影响到展示位置的特征,经过浅层网络得到bias的表征,然后把这个结果与主网络学出来的CTR直接相加,再经过一次激活函数得到最后的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









