







一、工具
VirtualBox V7.1.6
Ubuntu V24.04.1 desktop版
测试视频是随便从B站下载的 致富经:外来物种袭扰,村民变废为宝
B站视频下载网页工具:https://greenvideo.cc/bilibili
声明:以上内容仅作学习用途使用
二、处理过程:
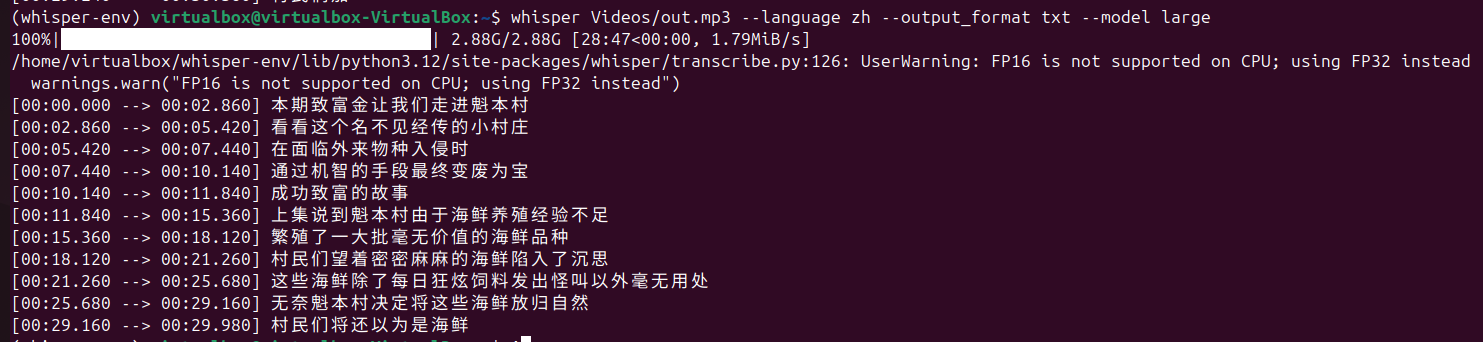
先使用ffmpeg工具从视频中提取30秒音频,然后再用whisper处理这个30秒的音频文件,就能得到一个.txt的文本结果。
三、结果
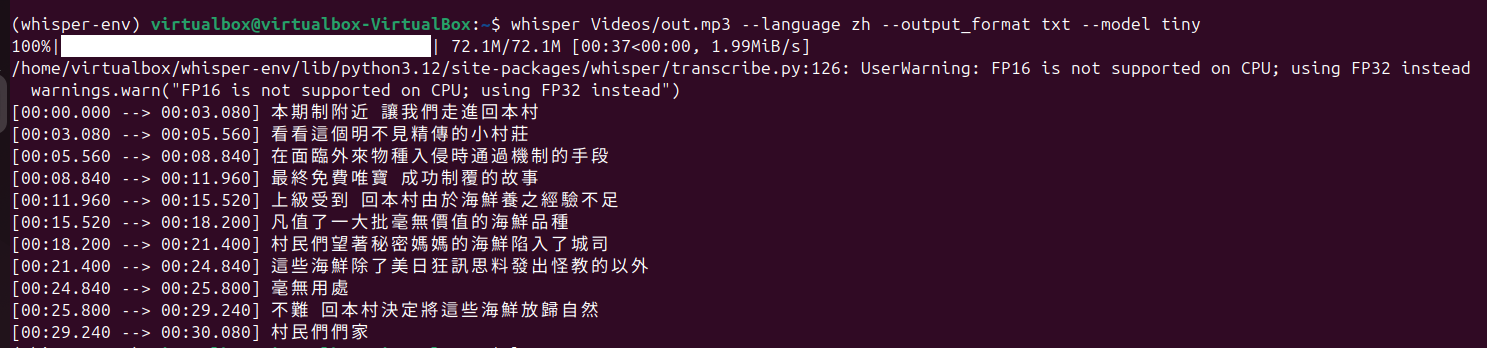
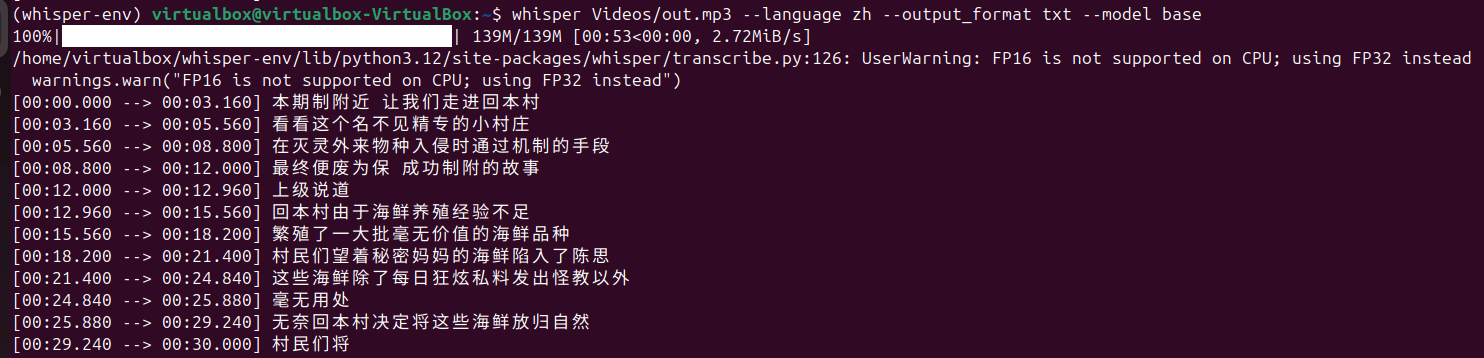
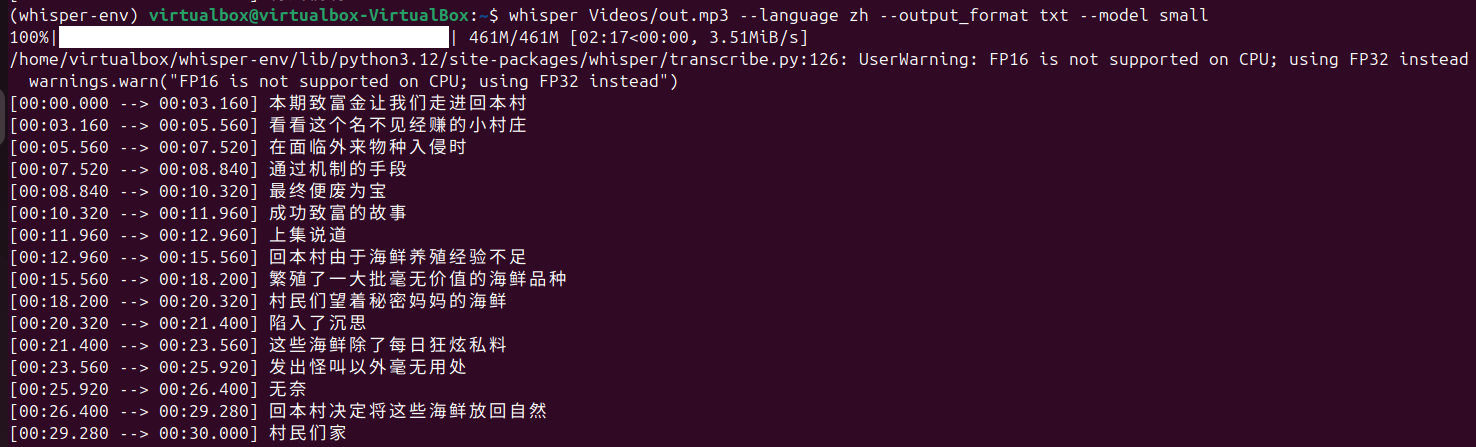
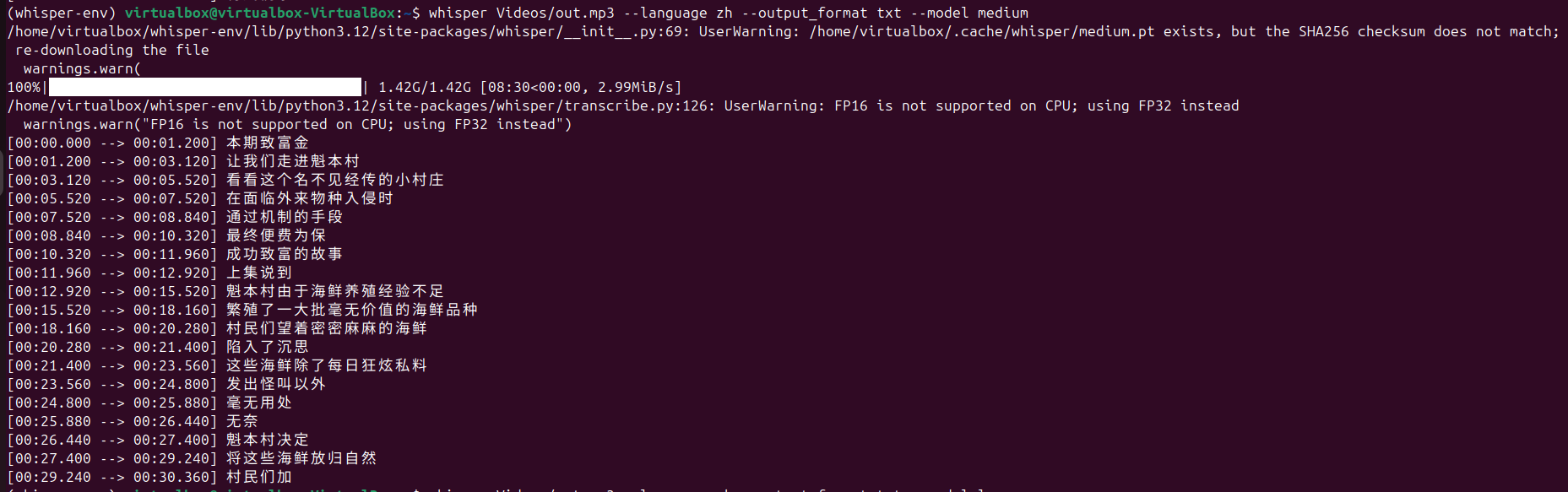
以下是不同模型规模的处理结果,tiny、base、small、middum、large,随着模型变大,语音识别的准确度显著提高,但相应地,处理时间也被拉长了好多。
tiny:
base:
small:
medium:
large:

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









