







通过优化Kettle的配置、调整转换步骤、优化SQL查询等,可以显著减少数据处理的时间,尤其是在处理大规模数据集时,性能提升的效果更加明显。还可以在现有的硬件资源下处理更多的数据,减少对额外硬件设备的需求,从而降低硬件成本。
一、 JVM参数调优
| 任务规模 | JVM参数配置示例 | 适用场景 |
|---|---|---|
| 小型任务 | -Xms1g -Xmx2g -Xmn512m | 数据量<100万行,单表操作 |
| 中型任务 | -Xms4g -Xmx8g -Xmn3g -XX:+UseG1GC | 100万~5000万行,多步骤复杂转换 |
| 大型任务 | -Xms16g -Xmx32g -Xmn12g -XX:+UseG1GC -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=1g | 5000万行以上,集群分布式执行 |
1. 堆内存分配
| 参数 | 作用 | 推荐比例 | 计算示例(Xmx=8G) |
|---|---|---|---|
| -Xmx | 最大堆内存(必须设置) | 物理内存的50%~70% | 可用物理内存16G → 8G |
| -Xms | 初始堆内存(建议与-Xmx相等) | =Xmx /2 | -Xms4g |
| -Xmn | 年轻代大小(Eden+Survivor) | 总堆的1/3 ~ 1/2 | -Xmn3g(年轻代3G,老年代5G) |
2. 元空间配置
| 参数 | 作用 | 推荐配置 |
|---|---|---|
| -XX:MetaspaceSize | 元空间配置 | 如果你的应用程序需要加载大量类或依赖项,可以增加,否制不变 |
| -XX:MaxMetaspaceSize | 最大元空间配置,最大1GB(大型任务可增至2GB) | 1g |
3. 垃圾回收器选择
| 回收器 | 适用场景 | 优势 |
|---|---|---|
| -XX:+UseG1GC | 大多数ETL任务(JDK8+) | 平衡吞吐量和延迟,可预测停顿 |
| -XX:+UseZGC | 超大堆(>32GB)且要求低延迟(JDK17+) | 亚毫秒级停顿,适合实时数据处理 |
4. 线程堆栈优化
-Xss512k # 默认1MB,降低可创建更多线程
最大线程数 ≈ (Xmx - Xmn) / Xss
示例:堆8G(年轻代3G),Xss512k → (8-3)*1024/0.5 ≈ 10240线程
5.实战
5.1调整前配置
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS="-Xms1024m" "-Xmx2048m"
5.2调整后配置
if "%PENTAHO_DI_JAVA_OPTIONS%"=="" set PENTAHO_DI_JAVA_OPTIONS=^
"-Xms4g" ^
"-Xmx8g" ^
"-Xmn3g" ^
"-XX:+UseG1GC" ^
"-XX:MaxGCPauseMillis=200" ^
"-XX:MetaspaceSize=64m" ^
"-XX:MaxMetaspaceSize=256m" ^
"-XX:InitiatingHeapOccupancyPercent=35" ^
"-XX:G1ReservePercent=15 " ^
"-XX:+UseCompressedOops"
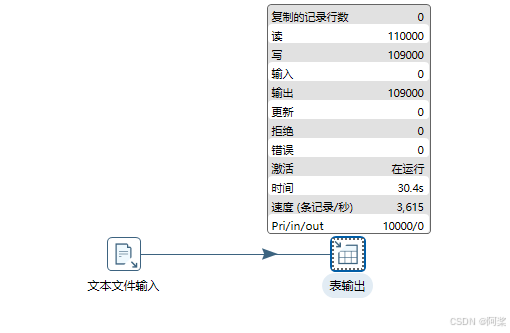
5.3抽取速率为3615条记录/秒
二、Kettle配置优化
1.修改提交批次大小
提交记录数量从1000提升至5000
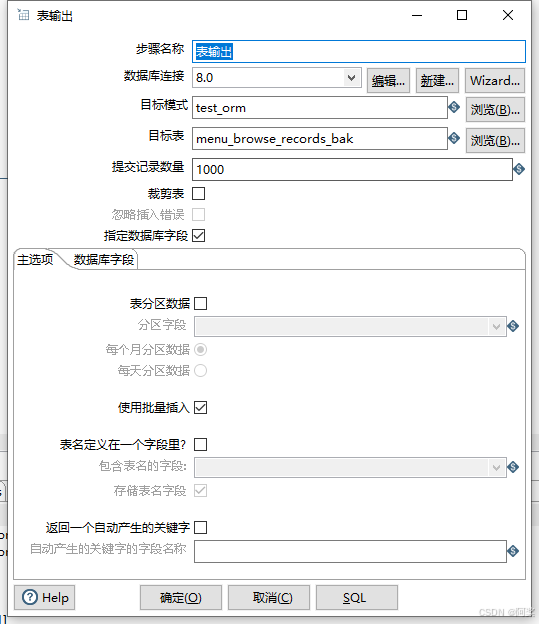
抽取速率提升至6992条记录/秒
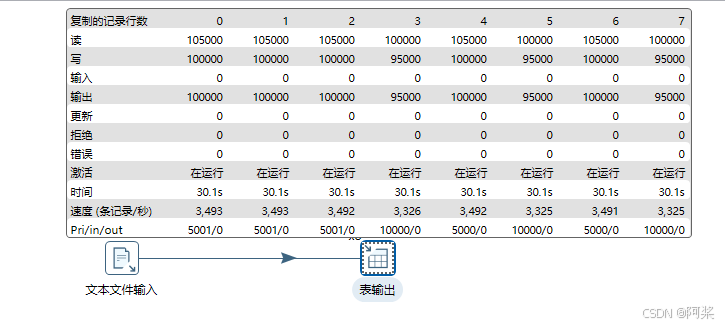
2.复制表输出数量
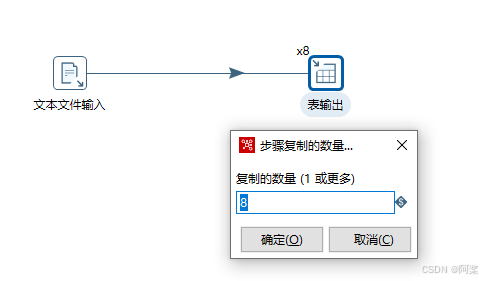
抽取速率提升至25591条记录/秒
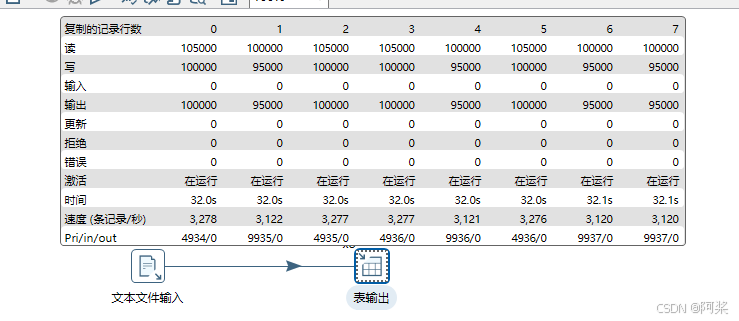
三、JDBC参数优化
| 参数名称 | 参数作用 | 推荐值 | 推荐理由 |
|---|---|---|---|
| useServerPrepStmts | 启用服务器端预处理语句,提升批量操作性能 | true | 减少客户端预处理开销,提升批量操作效率(需结合rewriteBatchedStatements使用) |
| useCompression | 启用客户端与MySQL服务器通信压缩,减少网络带宽占用 | false | 压缩会增加CPU负载,仅在网络带宽受限时启用(如远程数据库) |
| rewriteBatchedStatements | 重写批量SQL语句(如合并INSERT语句),提升批量写入性能 | true | 显著提升批量插入/更新性能(如ETL场景) |
| defaultFetchSize | 设置结果集每次从数据库获取的行数,平衡内存与网络开销 | 500-1000 | 减少内存占用,避免一次性加载大结果集(需结合useCursorFetch=true生效) |
| useCursorFetch | 启用游标逐块获取结果集,减少内存占用 | true(大数据量) | 处理大结果集时避免OOM,但可能略微增加延迟 |
| characterEncoding | 指定连接字符编码(如UTF-8) | UTF-8 | 避免中文乱码,兼容多语言字符 |
| maxReconnects | 定义连接断开后最大重试次数 | 3 | 防止无限重试导致线程阻塞,兼顾容错性 |
| autoReconnect | 连接断开后自动重连 | false | 自动重连可能导致事务状态不一致,建议由连接池管理重试 |
| nullCatalogMeansCurrent | 将null目录视为当前数据库 | true | 兼容旧版本JDBC驱动行为,避免跨库操作问题 |
| useSSL | 启用SSL加密通信 | true(生产环境) | 保障数据传输安全,但需配置证书(测试环境可设为false) |
| serverTimezone | 指定数据库服务器时区(如Asia/Shanghai) | 与数据库一致 | 避免时间字段转换错误(如Java应用与MySQL时区不一致) |
| useUnicode | 强制使用Unicode编码 | true | 确保非ASCII字符(如中文)正确存储和读取 |
| failOverReadOnly | 故障转移时是否仅允许只读操作 | true | 避免主从切换时写入数据导致不一致 |
| connectTimeout | 建立连接超时时间(毫秒) | 3000 | 防止网络故障时线程长时间阻塞 |
| socketTimeout | 网络读写超时时间(毫秒) | 60000 | 避免慢查询或网络问题导致线程挂起 |
| allowPublicKeyRetrieval | 允许从服务器获取公钥(解决SSL连接问题) | false | 存在安全风险,仅在MySQL 8.0+且SSL配置错误时临时启用 |
| maxAllowedPacket | 设置客户端允许的最大数据包大小(单位:字节) | 16777216 | 避免大数据插入/查询时报Packet too large错误 |
useServerPrepStmts=true + rewriteBatchedStatements=true + useCursorFetch=true + defaultFetchSize=1000 可显著提升批量操作和大数据查询效率。
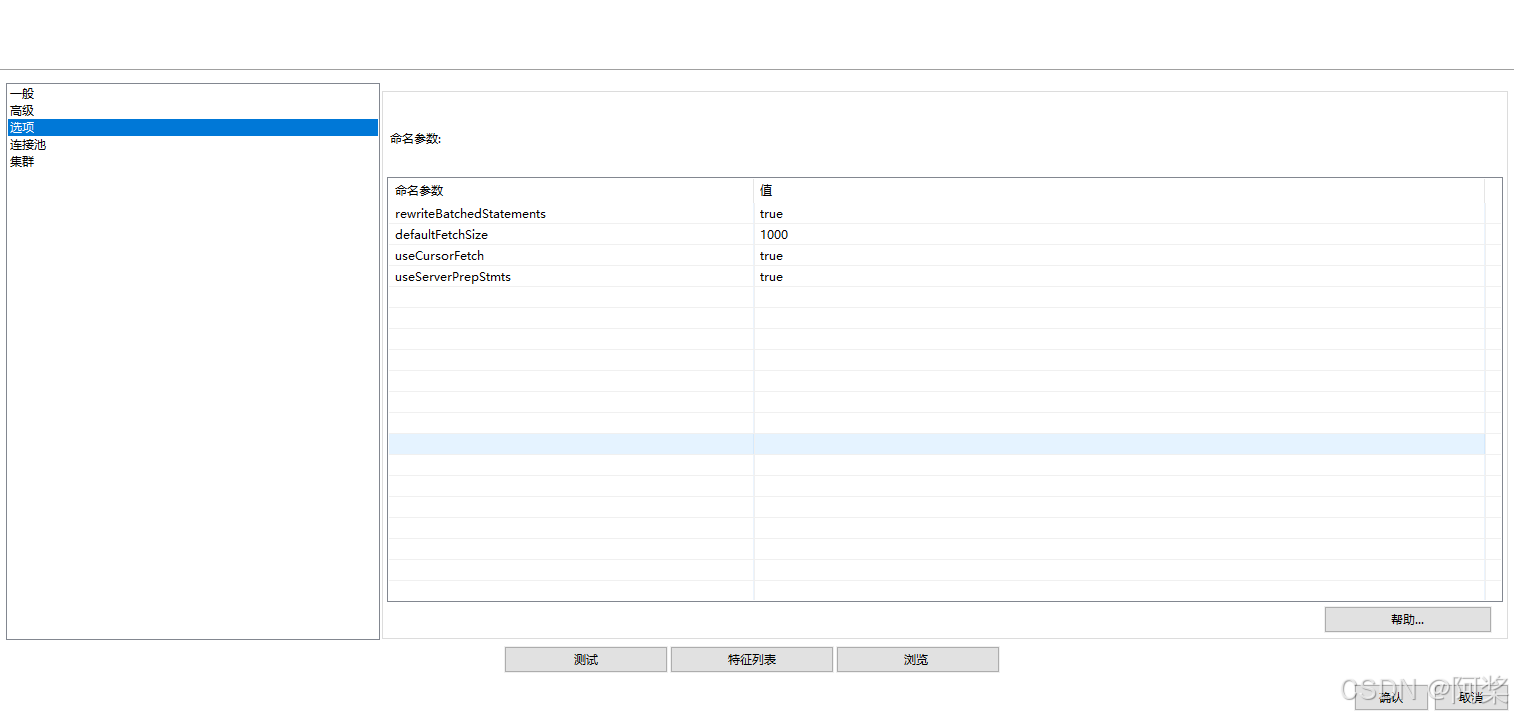
抽取速率提升至31297条记录/秒
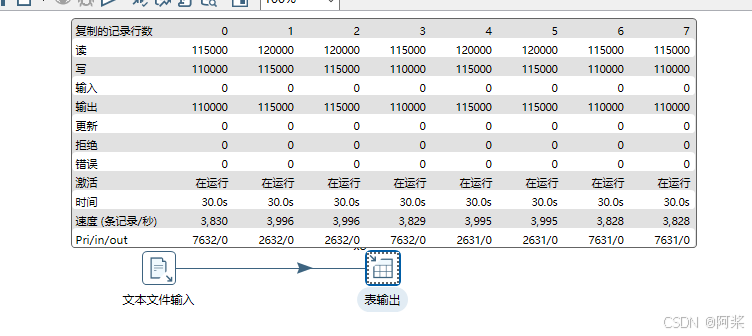
四、使用连接池(不配置JDBC参数)
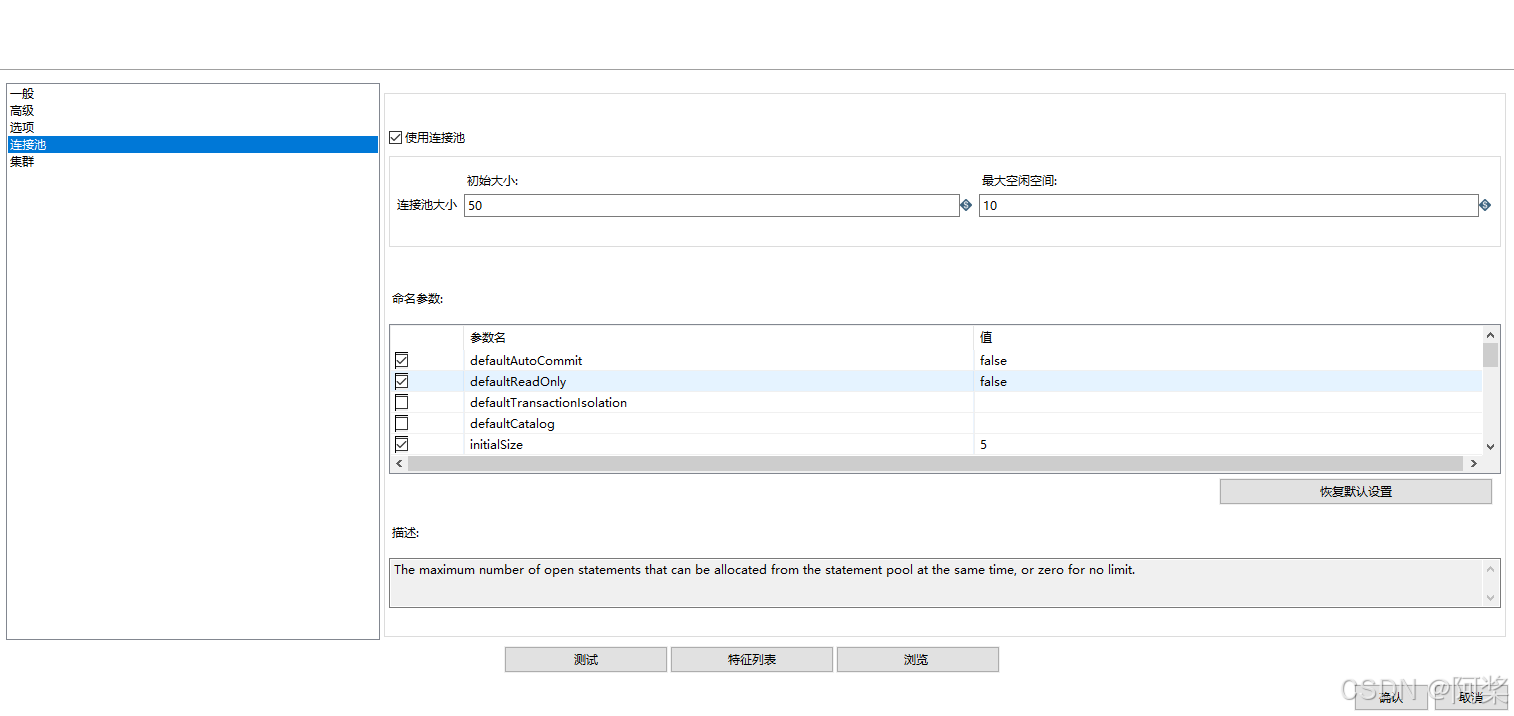
| 参数名称 | 设置值 | 理由 |
|---|---|---|
| 连接池大小 | 50 | 根据CPU核心数(4-8核)和并发需求,50个连接可以满足大多数场景 |
| 最大空闲空间 | 10 | 保持10个空闲连接可以快速响应突发请求,同时不会占用过多资源 |
| defaultAutoCommit | false | 建议关闭自动提交,以便更好地控制事务边界,避免意外提交 |
| defaultReadOnly | false | 默认允许读写操作,除非明确知道只需要读操作 |
| defaultTransactionIsolation | READ_COMMITTED | 在性能和一致性之间取得平衡,避免脏读同时保持较好性能 |
| defaultCatalog | (空) | 由具体业务数据库决定,通常不需要设置 |
| initialSize | 5 | 启动时创建5个连接,可以快速响应初始请求 |
| maxActive | 50 | 最大活跃连接数设置为50,可以应对高峰期的并发需求 |
| maxIdle | 20 | 最大空闲连接数设置为20,在空闲时保持一定连接数以快速响应 |
| minIdle | 5 | 最小空闲连接数保持5个,确保随时有可用连接 |
| maxWait | 30000 | 最大等待时间设置为30秒,避免长时间阻塞 |
| validationQuery | SELECT 1 | 使用简单的SELECT 1语句验证连接是否有效 |
| testOnBorrow | true | 在获取连接时验证,确保获取的连接是有效的 |
| testOnReturn | false | 归还时不需要验证,减少性能开销 |
| testWhileIdle | true | 空闲时定期验证连接,及时清理无效连接 |
| timeBetweenEvictionRunsMillis | 60000 | 每60秒运行一次空闲连接清理 |
| poolPreparedStatements | true | 启用准备语句池,提高SQL执行效率 |
| maxOpenPreparedStatements | 100 | 最大准备语句数设置为100,满足大多数场景 |
| accessToUnderlyingConnectionAllowed | false | 禁止访问底层连接,确保连接池管理可控 |
| removeAbandoned | true | 启用遗弃连接移除,防止连接泄漏 |
| removeAbandonedTimeout | 300 | 300秒后移除被遗弃的连接 |
| logAbandoned | true | 记录被遗弃的连接日志,便于排查问题 |
抽取速率提升至27437条记录/秒
五、其他优化方式
1.使用集群
- 对查询、运算、排序等计算密集型操作启用集群模式,利用分布式计算能力分担负载。
2.替换低效组件
- 避免使用JavaScript步骤,改用Java类、插件或数据库函数实现复杂逻辑。
3.控制日志级别
- 禁止使用Rowlevel日志(性能仅为Basic的1/10),生产环境建议设为Basic或Minimal。
4.规避死锁
- 数据库死锁:避免并发读写同一张表,或通过事务隔离级别优化。
- 转换死锁:检查步骤依赖关系,避免环形数据流。
5.启用数据库连接池
- 配置连接池(如DBCP、HikariCP),减少连接创建开销。通过日志验证是否生效。
6.合理利用缓存
- 对排序、流查询等步骤增大缓存(如调整排序行步骤的缓存大小)。
- 对重复查询使用缓存查询步骤。
7.优化数据库交互
- 索引策略:为高频查询字段添加索引,插入数据前删除索引,完成后重建。
- 批量操作:使用表输出的批量提交模式,单次提交1k~10k条数据。
- 原生工具:用数据库原生工具(如MySQL的LOAD DATA、Oracle的SQL*Loader)导入文本。
8.优先使用SQL
- 将Group By、Merge Join、Split Fields等操作转化为SQL语句,利用数据库优化器提升效率。
9.高效数据删除
- 用TRUNCATE替代DELETE ALL。
- 分区表直接DROP PARTITION而非逐行删除。
10.增量处理与数据过滤
- 增量更新时仅处理新增/变化数据,减少数据集规模。
- 在输入阶段通过WHERE条件过滤无效数据。
11.避免低效操作
- 禁用Update步骤,转为Delete + Insert组合。
- 禁用Calculate步骤,复杂计算通过SQL或存储过程实现。
12.远程数据传输优化
- 跨网络传输时使用压缩文件(如ZIP)+FTP/SFTP,减少传输时间。
13.资源管理与并行化
- 用Carte服务部署作业,降低内存消耗。
- 对无依赖的步骤启用并行执行(如设置Start步骤的并发数)。
14.性能瓶颈分析
- 通过Metrics或Performance Logging定位慢步骤,针对性优化(如调整数据库连接、拆分复杂转换)。


















 1172
1172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









