







DMBP: Diffusion Model-Based Predictor for Robust Offline Reinforcement Learning Against State Observation Perturbations
摘要
Offline RL是通过在离线数据集上进行训练并不与环境进行交互。而其在真实世界应用的挑战来源于对状态观测干扰的鲁棒性,如传感器错误或对抗性攻击。与Online RL方法不同,Agent不能在Offline setting下进行对抗训练。
在本文中,提出了Diffusion-Based预测器,使用条件扩散模型用于恢复真实状态,用于基于状态的RL任务。为了缓解误差累积问题,本文提出了一个非马尔可夫训练目标用于最小化去噪后状态的熵。DMBP可有效增强现有Offline RL算法在不同噪音和对抗攻击下的鲁棒性,同时其也能够有效解决不完整的状态观测任务。
介绍
Online方法需要进行频繁的试错学习,可能会很昂贵或者危险。当前一种普遍采用的解决方法是构建一个模拟器用于策略训练,但其可能是昂贵的并且可能会由于模拟器和真实世界的区别导致失败。因此Offline RL方法被予以注意。
当前Offline方法的一个挑战在于在状态观测中对干扰的鲁棒性。在Online setting下,多种对抗训练方法已经被提出来解决观测和真实状态的误关联。但这些方法难以直接用于Offline setting。
用于解决状态观测干扰问题的一种经典的方法是在最坏情况下训练一个鲁棒的策略,但是这可能会导致策略过度保守。在之前的工作中,有研究者提出一种替代性方法,即使用保守平滑方法来平滑Q值并且采用正则化项限制策略,从而防止Agent在对抗攻击下采取灾难性的动作。但是这种方法可能会随着噪音尺度的增大而发生性能的迅速降低,特别是在拥有高维动作和状态空间下的复杂环境。
本文提出了一个框架DMBP,用于在观测被干扰的情况下预测真实状态。之前的工作已有提出将Diffusion Model作为去噪工具而非生成模型进行使用,能够增强已有Offline方法的鲁棒性。
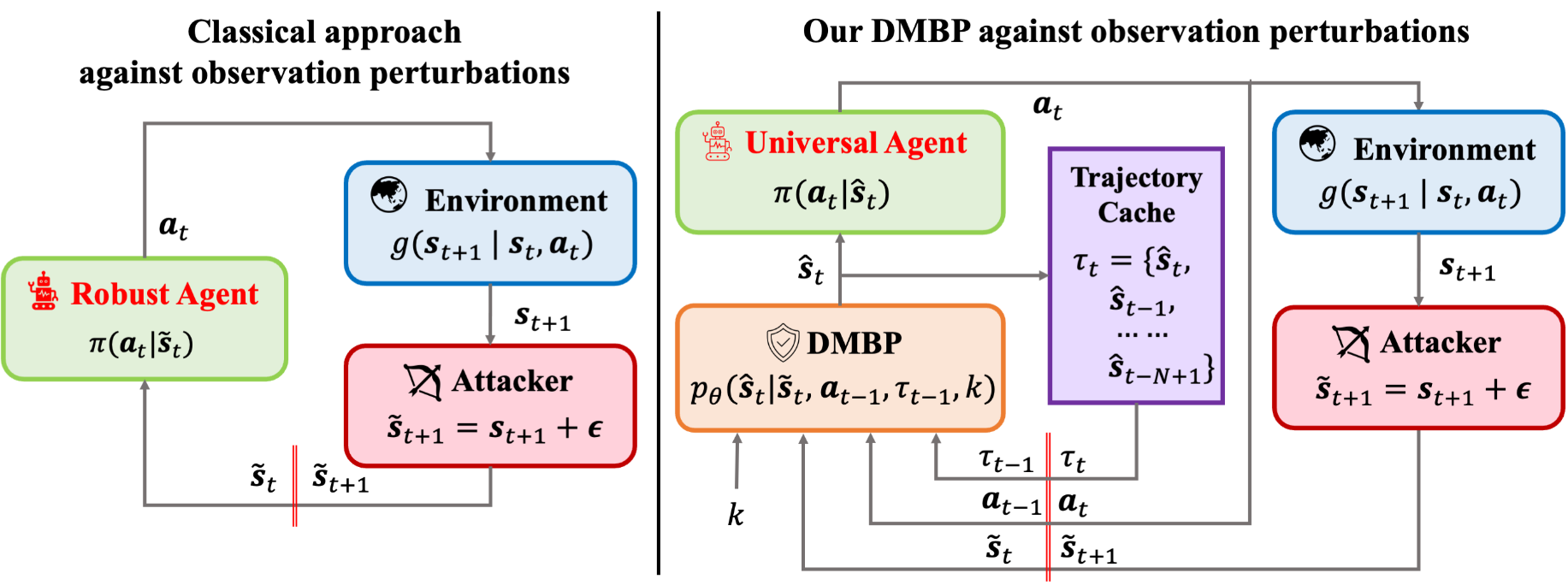
本文贡献:
- 该框架在给定已估计状态轨迹、最后一步Agent生成的动作以及当前来自环境的噪音状态,使用一个条件扩散模型通过去噪来估计当前的状态。
- 为了缓解在状态估计过程中的误差累积,本文提出了一个非马尔科夫链loss函数用于最小化去噪后状态的熵。
- 为了捕获噪音状态和去噪轨迹间的关系,本文提出了Unet-MLP网络,用于预测噪声信息。DMBP的输出是对当前状态的估计。
方法优点:
- 该方法能够通过对噪声状态进行去噪,直接用于增强现有Offline方法的鲁棒性。并且其不会导致策略过于保守。
- 利用Diffusion对缺失区域的填充能力,DMBP可以在不完整的状态观测下进行决策。
Diffusion-Based预测器
本文将状态 s s s的干扰结果写作 s ~ \tilde{s} s~,其中 B d ( s , ϵ ) : = s ~ : d ( s , s ~ ) ≤ ϵ \mathbb{B}_d(s,\epsilon):={\tilde{s}:d(s,\tilde{s})\le\epsilon} Bd(s,ϵ):=s~:d(s,s~)≤ϵ是扰动集合, d ( ⋅ , ⋅ ) d(\cdot,\cdot) d(⋅,⋅)是 l p l_p lp正则化。 s ~ ∗ = arg max s ~ ∈ B d ( s , ϵ ) D ( π ϕ ( ⋅ ∣ s ) ∥ π ϕ ( ⋅ ∣ s ~ ) ) \tilde{s}^*=\arg\max_{\tilde{s}\in\mathbb{B}_d(s,\epsilon)}D(\pi_\phi(\cdot|s)\parallel\pi_\phi(\cdot|\tilde{s})) s~∗=argmaxs~∈Bd(s,ϵ)D(πϕ(⋅∣s)∥πϕ(⋅∣s~))是状态 s s s的对抗攻击样本,其中 D ( ⋅ ∥ ⋅ ) D(\cdot\parallel\cdot) D(⋅∥⋅)是两个分布的散度。
这两个任务的目标都是最小化策略的平滑正则化器 R s π = E s ∈ D max s ~ ∈ B d ( s , ϵ ) D ( π ϕ ( ⋅ ∣ s ) ∥ π ϕ ( ⋅ ∣ s ~ ) ) \mathcal{R}^\pi_s=\mathbb{E}_{s\in\mathcal{D}}\max_{\tilde{s}\in\mathbb{B}_d(s,\epsilon)}D(\pi_\phi(\cdot|s)\parallel\pi_\phi(\cdot|\tilde{s})) Rsπ=Es∈Dmaxs~∈Bd(s,ϵ)D(πϕ(⋅∣s)∥πϕ(⋅∣s~)),最小化值函数的平滑正则化器 R s V = E s ∈ D , a ∼ π max s ~ ∈ B d ( s , ϵ ) ( Q ( s , a ) − Q ( s ~ , a ) ) \mathcal{R}^V_s=\mathbb{E}_{s\in\mathcal{D},a\sim\pi}\max_{\tilde{s}\in\mathbb{B}_d(s,\epsilon)}(Q(s,a)-Q(\tilde{s},a)) RsV=Es∈D,a∼πmaxs~∈Bd(s,ϵ)(Q(s,a)−Q(s~,a))。
用于预测真实状态的条件扩散模型
在该任务中有两类时间步,使用 i , k ∈ { 1 , … , K } i,k\in\{1,\dots,K\} i,k∈{1,…,K}表示扩散时间步, t ∈ { 1 , … , T } t\in\{1,\dots,T\} t∈{1,…,T}表示RL任务的轨迹时间步。
由于该方法是在较小或中等噪声上对数据进行处理,而非从纯噪音中生成数据,故重新设计了方差:
β
i
=
1
−
α
i
=
e
−
b
i
+
a
+
c
α
ˉ
k
=
∏
i
=
1
k
α
i
β
~
i
=
1
−
α
ˉ
i
−
1
1
−
α
ˉ
i
β
i
\beta_i=1-\alpha_i=e^{-\frac{b}{i+a}+c}\\ \bar{\alpha}_k=\prod\limits_{i=1}^k\alpha_i\\ \tilde{\beta}_i=\frac{1-\bar{\alpha}_{i-1}}{1-\bar{\alpha}_i}\beta_i
βi=1−αi=e−i+ab+cαˉk=i=1∏kαiβ~i=1−αˉi1−αˉi−1βi
其中
a
,
b
,
c
a,b,c
a,b,c是超参。重新设计的方差将扩散过程中的噪声限制在了较小的尺度,而在DDPM中方差是固定的,因为可学习的方差会导致训练不稳定。
重新对方差进行设计以后,既可通过最后一步动作
a
t
−
1
a_{t-1}
at−1和之前的去噪序列
τ
t
−
1
s
^
:
=
s
^
1
,
s
^
2
,
⋯
,
s
^
t
−
1
\tau^{\hat{s}}_{t-1}:={\hat{s}_1,\hat{s}_2,\cdots,\hat{s}_{t-1}}
τt−1s^:=s^1,s^2,⋯,s^t−1从噪声状态
s
~
t
\tilde{s}_t
s~t中获得去噪状态
s
^
t
\hat{s}_t
s^t。该过程能够被形式化的写成:
KaTeX parse error: Got function '\hat' with no arguments as superscript at position 62: …-1},\tau_{t-1}^\̲h̲a̲t̲{s})=f_k(\tilde…
其中
f
k
(
s
~
t
)
=
a
ˉ
k
s
~
t
f_k(\tilde{s}_t)=\sqrt{\bar{a}_k}\tilde{s}_t
fk(s~t)=aˉks~t。
p
θ
(
s
~
t
i
−
1
∣
s
~
t
i
,
a
t
−
1
,
τ
t
−
1
s
^
)
p_\theta(\tilde{s}^{i-1}_t|\tilde{s}^i_t,a_{t-1},\tau_{t-1}^{\hat{s}})
pθ(s~ti−1∣s~ti,at−1,τt−1s^)能够使用高斯分布
N
(
s
~
t
i
−
1
;
μ
θ
(
s
~
t
i
,
a
t
−
1
,
τ
t
−
1
s
^
,
i
)
,
∑
θ
(
s
~
t
i
,
a
t
−
1
,
τ
t
−
1
s
^
,
i
)
)
\mathcal{N}(\tilde{s}_t^{i-1};\mu_\theta(\tilde{s}^i_t,a_{t-1},\tau_{t-1}^{\hat{s}},i),\sum_\theta(\tilde{s}^i_t,a_{t-1},\tau_{t-1}^{\hat{s}},i))
N(s~ti−1;μθ(s~ti,at−1,τt−1s^,i),∑θ(s~ti,at−1,τt−1s^,i)),该分布中的均值和方差表示为:
μ
θ
(
s
~
t
i
,
a
t
−
1
,
τ
t
−
1
s
^
,
i
)
=
α
i
(
1
−
α
ˉ
i
−
1
)
1
−
α
ˉ
i
s
~
t
i
+
α
i
(
1
−
α
ˉ
i
−
1
)
β
i
1
−
α
ˉ
i
s
~
t
0
(
i
)
∑
θ
(
s
~
t
i
,
a
t
−
1
,
τ
t
−
1
s
^
,
i
)
=
β
~
i
I
\mu_\theta(\tilde{s}^i_t,a_{t-1},\tau_{t-1}^{\hat{s}},i)=\frac{\sqrt{\alpha_i}(1-\bar{\alpha}_{i-1})}{1-\bar{\alpha}_i}\tilde{s}^i_t+\frac{\sqrt{\alpha_i}(1-\bar{\alpha}_{i-1})\beta_i}{1-\bar{\alpha}_i}\tilde{s}_t^{0(i)}\\ \sum_\theta(\tilde{s}^i_t,a_{t-1},\tau_{t-1}^{\hat{s}},i)=\tilde{\beta}_i\mathbf{I}
μθ(s~ti,at−1,τt−1s^,i)=1−αˉiαi(1−αˉi−1)s~ti+1−αˉiαi(1−αˉi−1)βis~t0(i)θ∑(s~ti,at−1,τt−1s^,i)=β~iI
则状态
s
~
t
0
(
i
)
\tilde{s}^{0(i)}_t
s~t0(i)能够被还原出来:
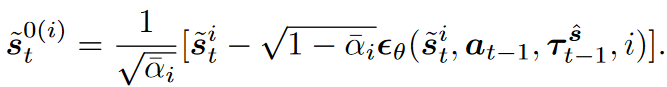
反向扩散能够形式化的表示为:
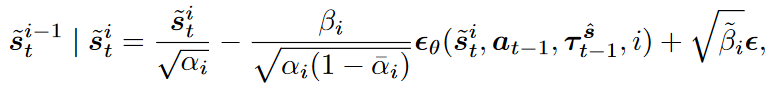
其中的噪声 ϵ ∼ N ( 0 , I ) \epsilon\sim\mathcal{N}(0,I) ϵ∼N(0,I)在最后一个去噪步被设置为0。最后一个去噪步得到的 s ~ t 0 \tilde{s}_t^0 s~t0被视为 s ^ t \hat{s}_t s^t,用于进行决策获得动作 a t = π ϕ ( ⋅ ∣ s ^ t ) a_t=\pi_\phi(\cdot|\hat{s}_t) at=πϕ(⋅∣s^t)。将 s ^ t \hat{s}_t s^t存储在轨迹存储 τ t s ^ \tau^{\hat{s}}_t τts^中,与 ( τ t s ^ , a t ) (\tau^{\hat{s}}_t,a_t) (τts^,at)共同用于下一步的去噪。由于去噪过程中的随机性,将并行地进行50次去噪,并取平均值。
由于将状态和动作直接输入到网络中,会导致不良的噪声估计。故本文先用U-net U ξ ( s ~ t i , τ t − 1 s ^ ) U_\xi(\tilde{s}^i_t,\tau^{\hat{s}}_{t-1}) Uξ(s~ti,τt−1s^)提取轨迹信息,再用MLP预测噪声 ϵ θ ( U ξ ( s ~ t i , τ t − 1 s ^ ) , s ~ t i , a t − 1 , s ^ t − 1 , i ) \epsilon_\theta(U_\xi(\tilde{s}^i_t,\tau^{\hat{s}}_{t-1}),\tilde{s}^i_t,a_{t-1},\hat{s}_{t-1},i) ϵθ(Uξ(s~ti,τt−1s^),s~ti,at−1,s^t−1,i)。
非马尔可夫损失函数
去噪结果 s ^ t \hat{s}_t s^t的准确性很大程度取决于条件 τ t − 1 s ^ \tau^{\hat{s}}_{t-1} τt−1s^的准确性。直接使用DDPM的损失函数可能造成严重的误差累积。为了缓解误差累积并增强鲁棒性,本文提出了一种非马尔可夫训练目标以最小化上的和,用于最小化真实分布与预测分布的交叉熵:
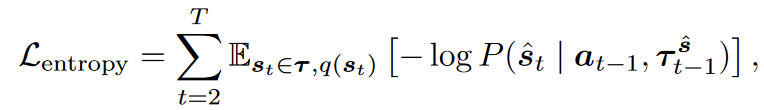
其中 P ( s ^ ∣ a t − 1 , τ t − 1 s ^ ) = p θ ( s ~ t 0 ∣ a t − 1 , τ t − 1 s ^ ) P(\hat{s}|a_{t-1},\tau^{\hat{s}}_{t-1})=p_\theta(\tilde{s}_t^0|a_{t-1},\tau_{t-1}^{\hat{s}}) P(s^∣at−1,τt−1s^)=pθ(s~t0∣at−1,τt−1s^)是时间步 t t t去噪结果的分布。通过变分下界,该目标可简化为:
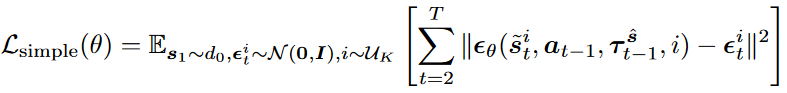
为了计算方便,通过采样离线数据集中的部分轨迹 ( s t − N , a t − N , s t − N + 1 , … , s t + M − 1 ) (s_{t-N},a_{t-N},s_{t-N+1},\dots,s_{t+M-1}) (st−N,at−N,st−N+1,…,st+M−1),有:
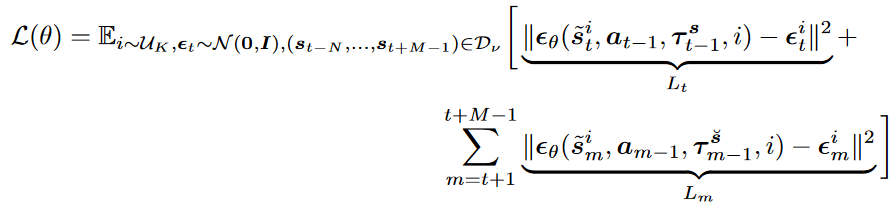
t − N t-N t−N到 t − 1 t-1 t−1部分是条件,没有噪音,因为推导时假设 t 0 t_0 t0时无噪音。
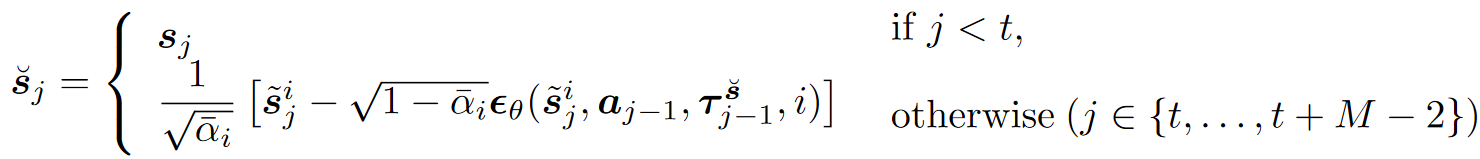
基于Diffusion的状态填充器
利用Diffusion在图像填充方面的应用,可使用DMBP对状态进行填充用于支持决策。

实验
本文对DMBP训练了300轮。
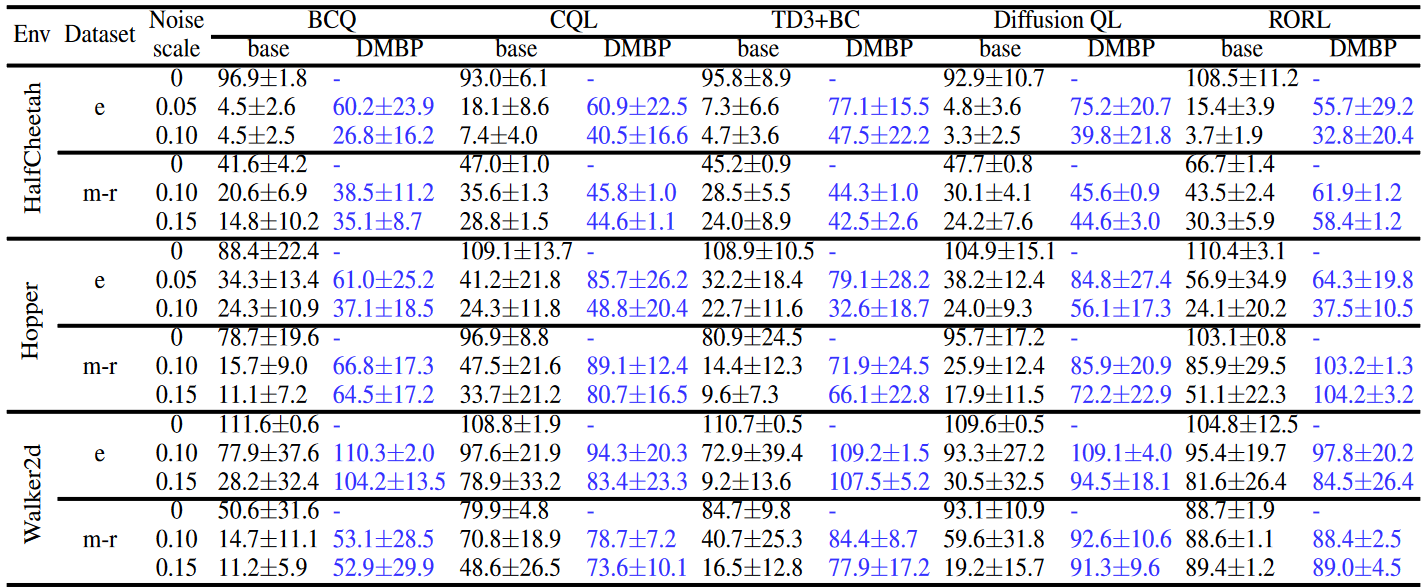
噪音状态观测下的鲁棒性实验
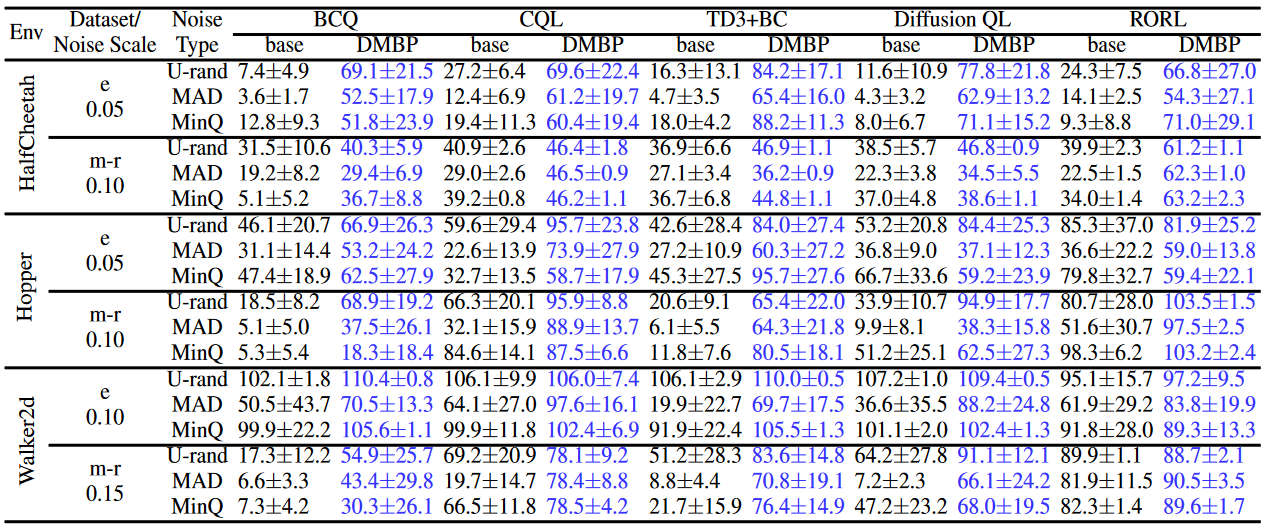
不同随机高斯噪声下的实验结果,其中RORL算法是保守策略算法:
不同攻击下的实验结果:
其中,最大动作攻击是让策略在两种状态下的输出分布最大化:
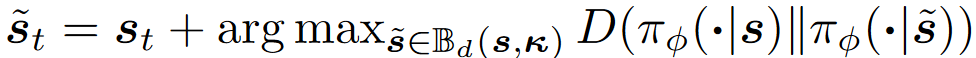
最小Q值攻击是让Q函数输出结果最小化:
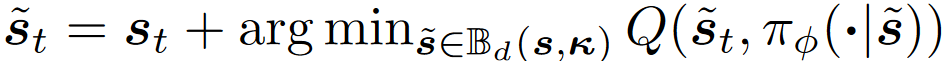
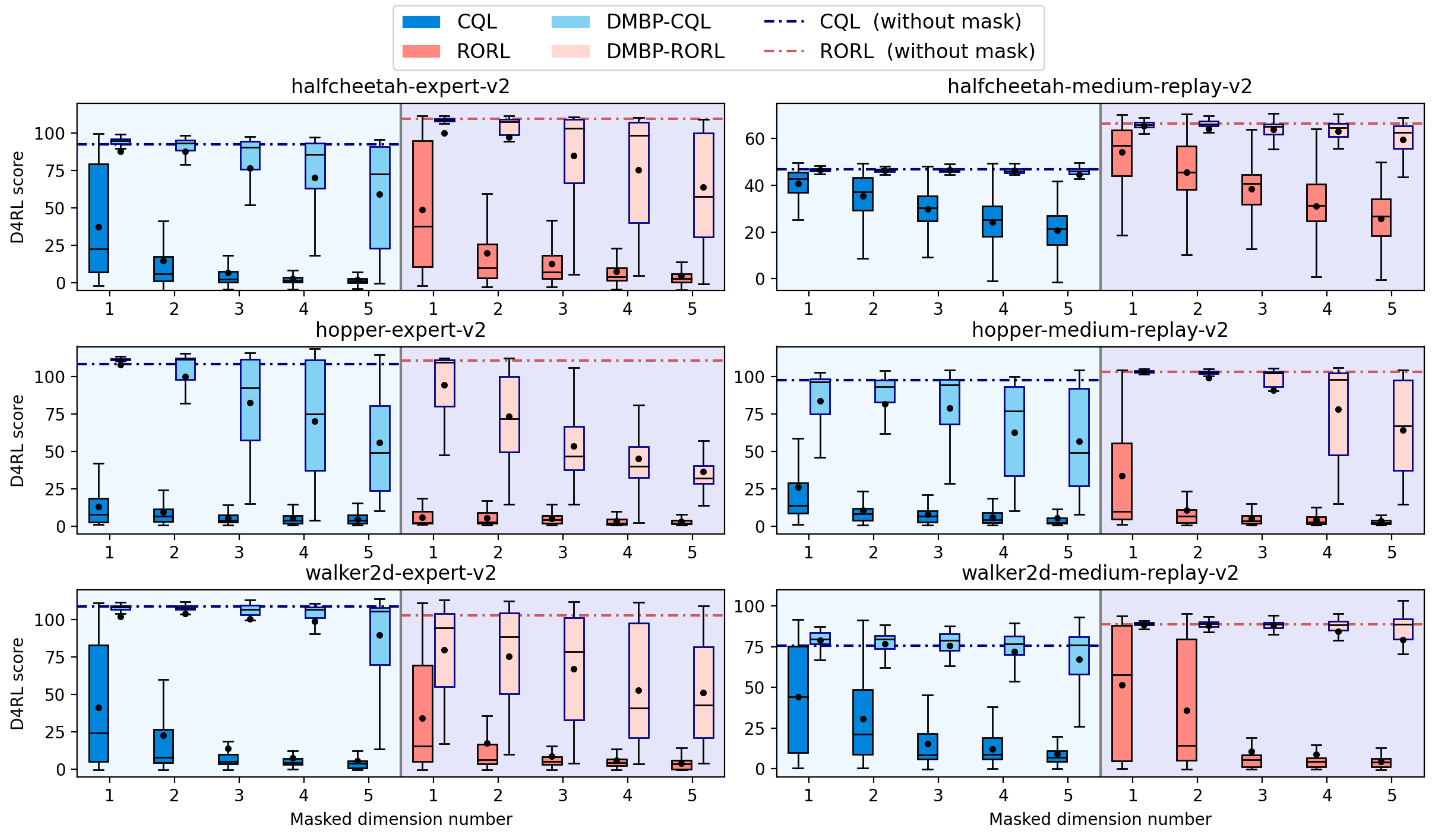
不完全观测下的鲁棒性实验
消融实验
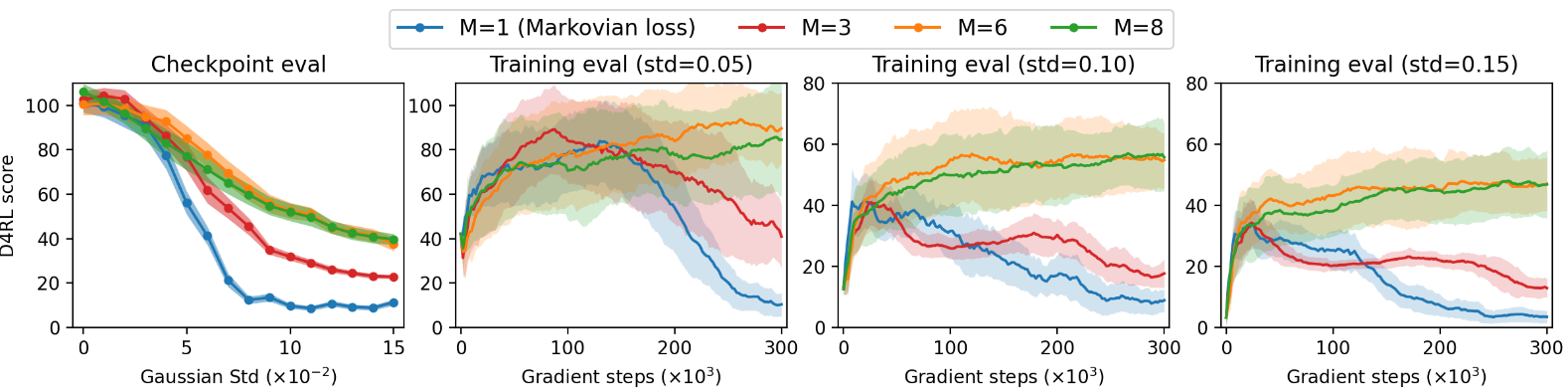
这个实验是对Loss函数的消融实验。该实验的区别在于给定无噪音观测的情况下,对未来求Loss的长度,在 M ≥ 2 M\ge2 M≥2时,有噪音部分通过前向过程公式,一步获得结果。















 2472
2472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









