







 文章介绍了BeyondMutualInformation方法,一种使用GAN进行医疗图像领域自适应的研究,通过信息瓶颈约束避免内容失真。研究者提出IB-GAN模型,结合Cycle-Consistency和信息理论,实验证明模型在不同数据集上的稳健性和效果,特别关注了数据量对模型性能的影响。
文章介绍了BeyondMutualInformation方法,一种使用GAN进行医疗图像领域自适应的研究,通过信息瓶颈约束避免内容失真。研究者提出IB-GAN模型,结合Cycle-Consistency和信息理论,实验证明模型在不同数据集上的稳健性和效果,特别关注了数据量对模型性能的影响。
Beyond Mutual Information: Generative Adversarial Network for Domain Adaptation Using Information Bottleneck Constraint,TMI2022
Beyond Mutual Information: Generative Adversarial Network for Domain Adaptation Using Information Bottleneck Constraint, TMI2022
这是一篇使用GAN进行医疗图像的领域自适应的工作。
医疗图像与领域自适应
AI模型的使用极大促进了电子辅助诊断(Computer Aided Diagnosis,CAD)领域的发展,然而,为某一领域使用的模型对于其它领域数据的泛化能力则很少被讨论,当输入域变化时,模型的表现将会出现显著下降。在实际使用过程中,不同设备造成的图像差异、不同采集机构造成的色调差异及不同模态的数据(如CT和MRI)都可能影响模型的使用。训练数据和测试数据之间的差别就是领域迁移问题(Domain Shift Problem)。
为了解决Domain Shift的问题,需要进行领域自适应(Domain Adaption),本文所关注的领域是采用GAN进行图像翻译实现领域自适应。具体来说,通过使用GAN强大的生成能力,将目标域的测试图像翻译回到模型训练的源域中(图像翻译问题)再输入模型,就可以避免模型效果受到影响。由于配对的不同域图像获取十分困难,因此实际使用过程中大多数方法采用了无监督非配对的方式,通过使用cycle-consistency loss来利用不配对图像完成训练(基于CycleGAN)。但是cycle-consistency loss训练的模型很容易出现内容失真,这在医疗图像中尤其不可接受,而如何在翻译过程中避免重要信息的丢失影响模型表现,就是本文提出的问题。
Cycle-Consistency及其缺陷
CycleGAN是一个经典的使用不成对数据进行图像翻译的模型,该模型可以利用非配对的数据,训练从一个域转换到另一个域的GAN网络。对于两个域
A
A
A和
B
B
B,CycleGAN的模型结构包含两个生成器
G
A
B
G_{AB}
GAB和
G
B
A
G_{BA}
GBA用于
A
→
B
A\rightarrow B
A→B和
B
→
A
B\rightarrow A
B→A的图像翻译,以及用于判断图像是否属于这两个领域的判别器
D
A
D_A
DA和
D
B
D_B
DB。整体结构参考下图(
A
A
A和
B
B
B变成了
X
X
X和
Y
Y
Y):
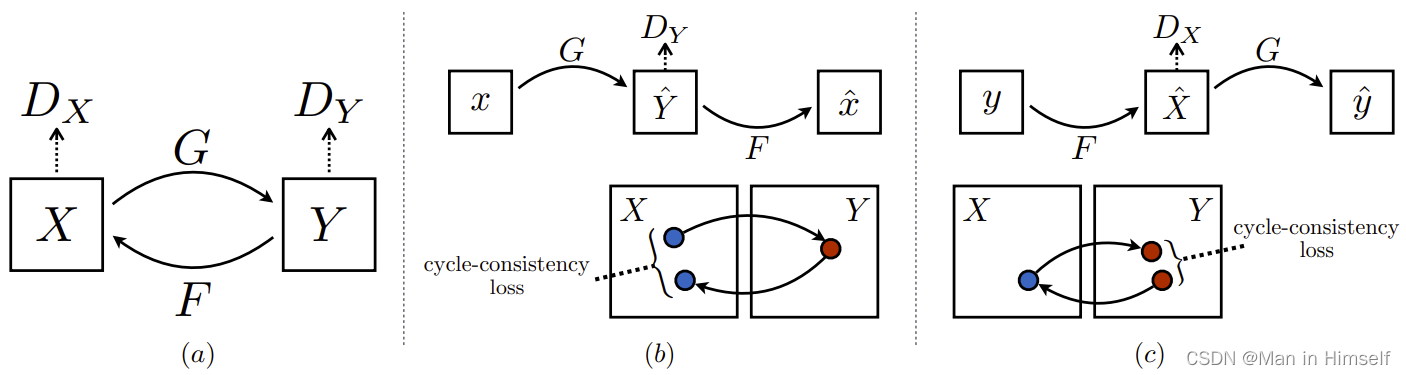
整个模型的损失函数也分为两部分,传统GAN的生成对抗损失
L
a
d
v
\mathcal{L}_{adv}
Ladv,和用于确保cycle-consistency的损失
L
c
y
c
\mathcal{L}_{cyc}
Lcyc。生成对抗损失在
B
→
A
B\rightarrow A
B→A翻译中如下(反之亦然):
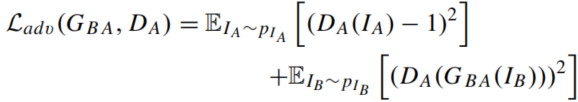
而cycle-consistency损失如下,表示一个图像可以被翻译回自身:
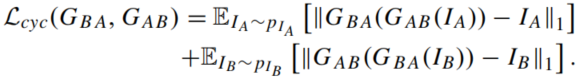
通过这一巧妙的设计,即使没有成对数据,也可以完成图像的翻译。然而CycleGAN结构有一个缺陷,无法保证样本几何性质的不变性,在生成过程中会内在地产生双射变换。具体来说,假如训练的GAN模型除了完成图像翻译
G
A
B
G_{AB}
GAB,还产生了几何变换
T
T
T,只需要在相反的生成器
G
B
A
G_{BA}
GBA中引入相反的变换
T
−
1
T^{-1}
T−1就可以仍然满足cycle-consistency,如下式所示:
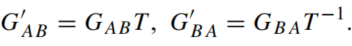
只要这种扭曲并不影响判别器判断(通常而言不会,因为一张图像经过一些轻微的几何变换如缩放平移旋转等仍然很容易被认为属于该域),那么就也不会生成对抗损失纠正,从而导致我们获得的模型对于图像做了扭曲,而该扭曲却可能会显著影响领域自适应场景下翻译后图像在下游任务的表现。
为了解决这个问题,传统的思路是通过一个辅助的分割任务,确保分割结果的不变性来作为生成器的正则化项,但是这需要训练额外的分割模型从而代价高昂。
信息瓶颈理论与IB-GAN
信息瓶颈理论在深度学习中被广泛用于分析学习过程和学习特征表示,其原理可以表述为,在尽可能保留关于
y
y
y的信息的情况下,尽量降低
x
x
x的码率得到特征表示
z
z
z。其公式可以表示为:
min
I
(
x
;
z
)
s
.
t
.
I
(
y
;
z
)
≥
D
\min\mathcal{I}(x;z) \quad s.t. \mathcal{I}(y;z)\ge D
minI(x;z)s.t.I(y;z)≥D
其中
I
\mathcal{I}
I表示互信息,所以通过拉格朗日法优化
I
(
x
;
z
)
−
β
I
(
y
;
z
)
\mathcal{I}(x;z)-\beta\mathcal{I}(y;z)
I(x;z)−βI(y;z)就是方法。但是在对特征的筛选过程中,我们注意到
z
z
z完全来自于
x
x
x的编码,换言之,我们不可能希望
y
y
y为z提供超过
x
x
x所能提供的信息,因此我们可以得出:
I
(
z
;
y
∣
x
)
=
0
\mathcal{I}(z;y|x)=0
I(z;y∣x)=0这样就可以推导出论文中的第一个公式:
I
(
x
;
z
)
=
I
(
x
;
z
∣
y
)
+
I
(
y
;
z
)
\mathcal{I}(x;z)=\mathcal{I}(x;z\vert y)+\mathcal{I}(y;z)
I(x;z)=I(x;z∣y)+I(y;z)
而这里的
I
(
x
;
z
∣
y
)
\mathcal{I}(x;z\vert y)
I(x;z∣y)就表示
z
z
z中对于预测
y
y
y没有贡献的冗余信息,(就等于等式左边(
x
x
x和
z
z
z的互信息)减去等式右边第二项(
y
y
y和
z
z
z的互信息))。所以优化目标也可以设置为该项。(这个公式来自Learning robust representations via multi-view information bottleneck,ICLR2020,文中没有做推导,我这里推测了它的推导过程,如有错误欢迎指正)
通过引入信息瓶颈理论,模型可以学习到对于预测而言最有意义的特征,从而提升模型的鲁棒性和泛化能力。这项技术已经开始被广泛运用,本文作者正是将其运用到图像翻译问题中,从而解决失真问题。作者提出的IB-GAN结构如下图:
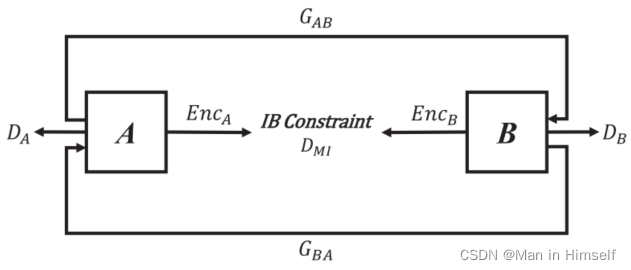
然而,经典的信息瓶颈理论需要使用到监督信号
y
y
y来识别冗余信息,在一些工作中,分割mask被使用作为标签,但是这显然不符合无监督的要求,因此作者选择让原始图像和翻译图像互为标签,所以直接推导的优化目标为(以
I
a
I_a
Ia作为标签为例):
I
(
I
a
b
;
z
a
b
)
−
β
I
(
I
a
;
z
a
b
)
(
1
)
\mathcal{I}(I_{ab};z_{ab})-\beta\mathcal{I}(I_a;z_{ab})\quad\quad\quad\quad (1)
I(Iab;zab)−βI(Ia;zab)(1)不过作者没有直接对此进行优化,因为在本问题中使用
I
a
I_a
Ia作为标签,所以有(按照之前的推导
I
(
z
;
y
∣
x
)
=
0
\mathcal{I}(z;y|x)=0
I(z;y∣x)=0):
I
(
z
a
b
;
I
a
∣
I
a
b
)
=
0
\mathcal{I}(z_{ab};I_a\vert I_{ab})=0
I(zab;Ia∣Iab)=0,这也是显而易见的,作为直接从
I
a
b
I_{ab}
Iab进行encode的结果,
z
a
b
z_{ab}
zab显然不可能从
I
a
I_a
Ia中获得额外的信息,这就使得我们的推导
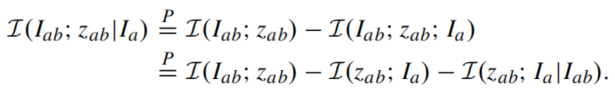
由于
z
a
b
z_{ab}
zab和
I
a
b
I_{ab}
Iab直接相关,因此最后一项为0,所以式子可以改写为:
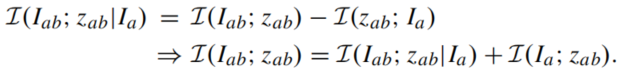
和公式(1)对比我们可以神奇地发现,对于
I
a
b
\mathcal{I}_{ab}
Iab的优化可以合并进行,由于我们仍然要最小化。按照信息瓶颈理论的推导,损失函数的上界表示为:
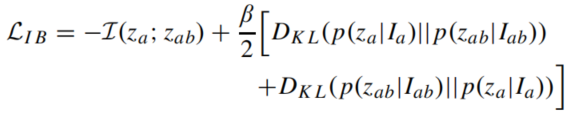
这里使用了两个上界:
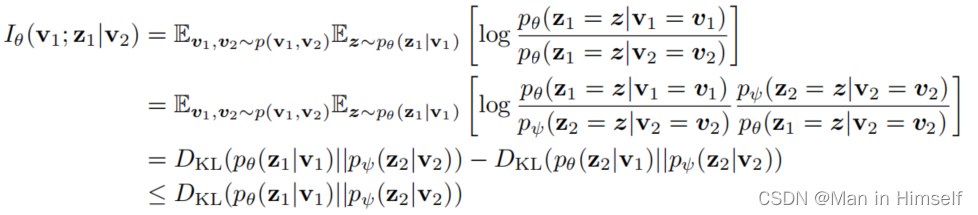
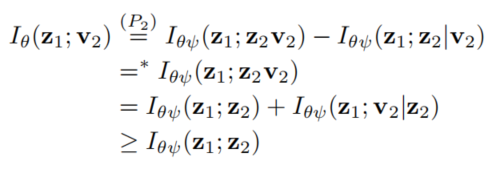
损失函数的第二项可以直接计算,第一项采用Donsker-Varadhan表示法计算。该方法利用了互信息和KL散度的关系:
I
(
X
;
Y
)
=
D
K
L
[
p
(
x
,
y
)
∥
(
p
(
x
)
p
(
y
)
)
]
I(X;Y)=D_{KL}[p(x,y)\Vert (p(x)p(y))]
I(X;Y)=DKL[p(x,y)∥(p(x)p(y))]
因此只需要对
z
a
z_a
za和
z
a
b
z_ab
zab的联合分布和边缘分布乘积的KL散度进行优化即可。为了优化KL散度作者选择了GAN网络来进行优化,其中联合分布用
z
a
z_a
za和
z
a
b
z_{ab}
zab的concat表示,边缘分布乘积用
z
a
z_a
za和随机sample的
z
b
z_{b}
zb(其实我觉得这里用
z
a
b
z_{ab}
zab更好,可能作者还想顺便优化以下
z
a
b
z_{ab}
zab和
z
b
z_{b}
zb的关系吧),整体结构如下,其中
J
\mathbb{J}
J表示的是联合分布,
M
\mathbb{M}
M表示边缘分布的乘积。

整体的损失函数就是前面提到的对抗损失、cycle-consistency损失和信息瓶颈损失的结合:
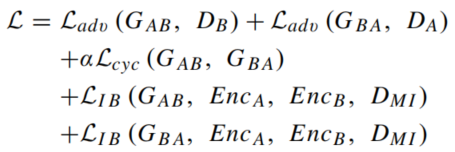
实验结果
模型效果
作者在结肠镜数据集(使用CVC和ETIS两个不同数据及作为不同域)、眼底图像数据集(REFUGE数据集的训练集和验证集采集自不同相机,作为两个域)和心脏数据集(MRI和CT作为两个域)的分割上做了实验,验证了模型再不同域到域转换情景下的表现:
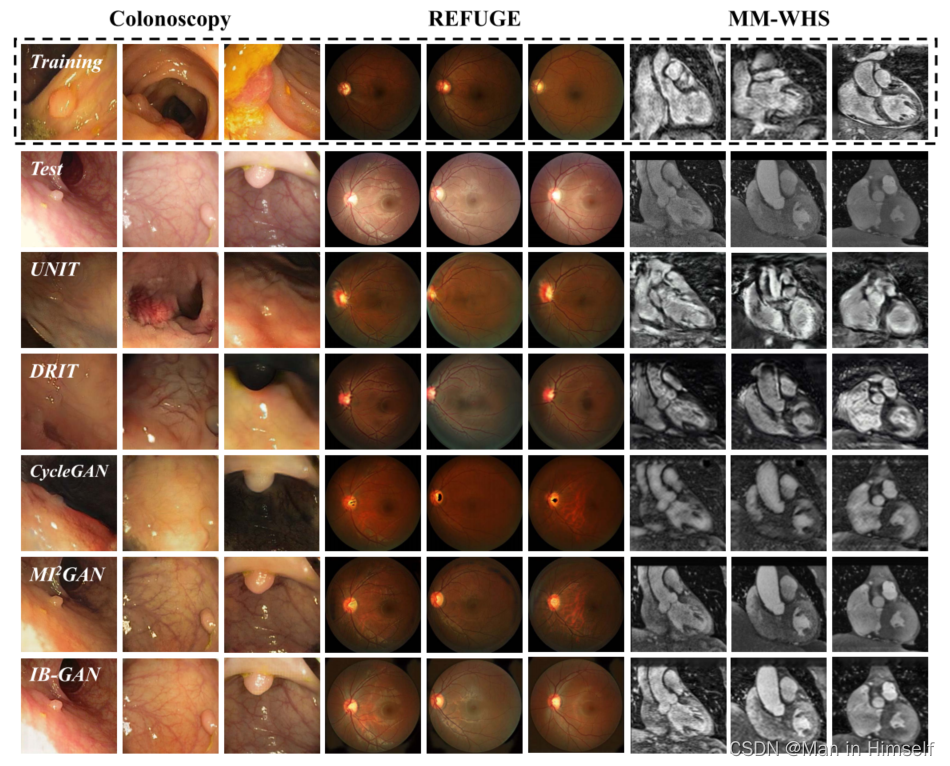
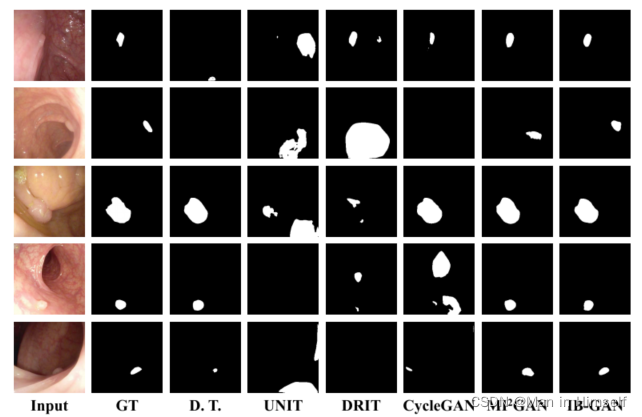
模型的转换对于分割模型的表现也有提升(GT为标签,D. T.为直接将另一个域的模型输入到模型中):
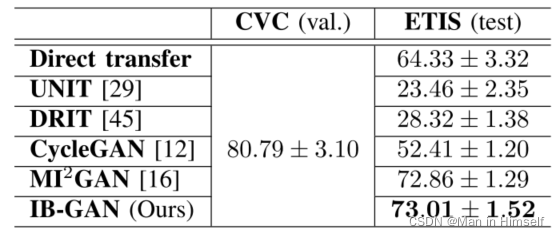
这里展示结肠镜数据集的结果指标如下:
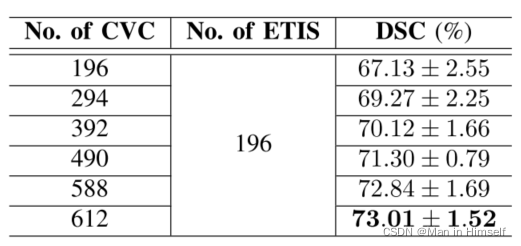
数据量的影响
先前的一些研究声称cycle-GAN模型会受到两个域数据集不平衡的影响,再结肠镜数据集中正好有这种情况,也出现了不同域到域转换后分割结果的不一致(见上图,被转换到数据量多的CVC后分割结果好于转换到ETIS的分割结果)。于是作者进行了实验,结果发现模型的性能并没有受到数据不平衡的影响,而只是收到了训练数据量的影响:
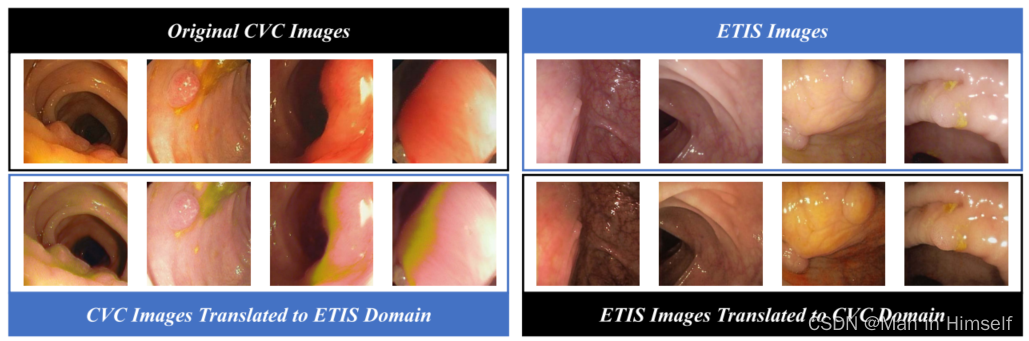
视觉效果上有也可以看出,翻译到数据较少模态时的伪影更加严重:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









