







持续学习+元学习+无监督学习文章调研(五)
继续进行相关文章的调研。这一主题的更新暂时告一段落了,下周开始进行一些医疗图像方面的相关学习。
文章
*CAVIA: Fast Context Adaptation via Meta-Learning,ICML2019
本文是针对经典方法MAML的一个改进,主要目的是解决MAML的meta-overfitting的问题(原因包括在meta-training的query set中的样本数量和代表性不足)。是对元学习的适应能力做的改进。
上下文参数(context parameters)和共享参数(shared parameters)
本文提出,将模型的参数分为两个部分,一个是context parameters,表示为 ϕ \phi ϕ该参数被作为额外的输入放入模型,并用于(inner loop)适应每一个任务;另外一部分是shared parameters,表示为 θ \theta θ被(outer loop)meta-train,在各个任务之间共享。 ϕ \phi ϕ可以被理解为task embedding,用于调控模型的行为。关于这两个参数的交互方式,并没有一定的规律, ϕ \phi ϕ可以直接和网络的中间输出做concat,也可以对特征做仿射变换。这样的划分有几个好处:
- 解耦了两种参数,避免了 θ \theta θ的过拟合,对 ϕ \phi ϕ的容量的选择也可以专注于依据任务间的关系而得到更合理的设置。(我的理解是,哪怕对于数据很相似的任务,任务间差别也可能是不同的,比如说一组五分类的任务,在CUB上和在ImageNet上任务间的区别就很大)
- 更好的并行性和节省计算。因为内外圈更新的参数不同了,所以不再需要权重的直接操作,并行性也更好。除此之外,由于外圈和内圈不再耦合,内圈可以采用更加灵活先进的更新方式。
- 更加简洁的结构。相比于其它的适应性算法,如CNPs和LEO,CAVIA没有引入额外的用于预测任务网络结构或针对任务定制不同的网络结构。
整体的步骤也不复杂,理解MAML的话很容易就能理解作者的思路。两组权重的更新公式如下:
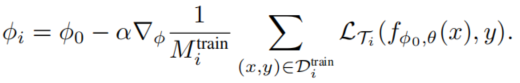
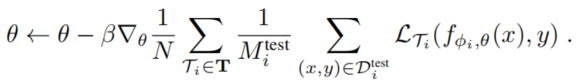
在meta-testing阶段,只有
ϕ
\phi
ϕ会被更新。
实验结果
这是在正弦曲线拟合中的结果,CAVIA不逊色于MAML,并且图b和c证明了固定的
ϕ
\phi
ϕ初始值足够(也就是不对
ϕ
0
\phi_0
ϕ0进行元学习,就是上面说的解耦内外圈),同时b和c还证明了不同的内圈学习率(仅限于meta training时)对于CAVIA来说都可以适应(因为外圈更新过程中会对和
ϕ
\phi
ϕ相关的参数做对应的缩放,从而缩放梯度从而平衡内圈学习率的影响)。

在元学习mini-ImageNet上的表现也相当不错(如下图),模型名称后面的括号里面是使用的CNN的filter数,证明了方法可以运用于大模型,这也来自于减少了更新的参数量(只更新
ϕ
\phi
ϕ)从而避免了内圈更新的过拟合(反例就是MAML)。

Defining Benchmarks for Continual Few-Shot Learning, arXiv 2004.11967
这篇文章为持续小样本学习(continual few-shot learning,CFSL)提出了benchmark。作者认为,作为智能系统有效学习的两种能力,持续学习和小样本学习在过去很少被关注的原因在于前者主要关注避免遗忘而后者关注快速学习新知,二者刚好相反,忽略了他们内在的共同点。作者将持续的数据流(持续学习的特点)引入了小样本学习。
任务定义&实验
和其他小样本学习任务类似,作者为每个问题设置了support set S \mathcal{S} S和target set(query set) T \mathcal{T} T,他们共享标签控件 C \mathcal{C} C。并设置了几个参数用于区分:
- number of classes, N C N_C NC或 N S N_S NS:支撑集的分类数(N-way)
- number of samples per class, K K K:每个分类的样本数(K-shot)
- number of support sets per task, NSS, N G N_G NG:一个CFSL任务有多少个support set
- class change interval, CCI:表示分类标签变更的间隔,也就是经过几个support set后,分类任务进行切换
- overwrite, O O O:不同support set是否共享标签
为了严格定义持续学习,所有的suppoer set都不会彼此重复,
这些参数的功能可以用下图来表示,New Class指的是在后续训练中引入了新的类,New Samples指的是在后续训练中为之前的类引入了更多样本。可以看出B和D是Class-Incremental的,A和C是Scenery-Incremental的:

作者在Omniglot和自己修改的SlimageNet上做了实验,测试了基线方法和一部分的元学习方法:
 作者给出了几个观察:
作者给出了几个观察:
- 相比于基于梯度的方法(MAML++L),基于Embedding的方法(如ProtoNet)善于在类空间独立的情况,而在输出空间共享的情况下则难以解耦不同任务的输出。(这也正常,毕竟要把不同的样本归于一类,但是在我看来这种Embedding的模型本身要记忆样本,已经打破了持续学习)
- 在SlimageNet中Embedding的方法缩小甚至超过了和梯度方法在共享输出空间情况下的差距,说明该数据集中记忆更加重要(因为数据集也更复杂多样了,可以理解),对于类内复杂度高的数据集(如共享输出空间的持续学习最后相当于将所有类分到了两个超类中),梯度方法的适应能力更加显著。
- 将梯度和Embedding结合的方法(SAC,MAML++H)能够取得最好的结果。
*Few-Shot and Continual Learning with Attentive Independent Mechanisms, arXiv 2107.14053
作者提出了一种方法,Attentive Independent Mechanisms(AIM),目的在于提高模型的泛化能力,解决模型遇到的灾难性遗忘(对应持续学习)和适应性问题(对应小样本学习)。作者还提到了关于神经结构搜索(NAS)相关的工作,认为从结构角度提高泛化能力是提高泛化能力的方向,但缺少在非均匀分布(non-iid distribution)的数据集上的检验,可见作者从这些工作也获得了启发。
Attentive Independent Mechanisms
作者提出AIM模块是为了在高层次对信息进行建模(所以背后的解耦特征提取和高层信息的思想和OML一样)。其之前的特征提取层表示为
z
=
f
ψ
(
x
)
\mathbf{z}=f_\psi(\mathbf{x})
z=fψ(x) 而
z
\mathbf{z}
z就是特征,AIM则被表示为
A
W
\mathcal{A}_\mathbf{W}
AW,其示意图如下:

该结构的目标是获得一组稀疏的机制,用于解耦提取到的高维特征,这一组机智的相互作用可以被理解为Mixture of Experts(MoE)系统,整体模型相当于一个静态的Recurrent Independent Mechanism (RIM),不过AIM的主要目的是学习到任务间通用的独立机制,从而避免遗忘和干扰。相对于RIM,AIM的一个改进是采用相加而非拼接的方式处理各个机制的结果,这样减少了输出维数,保证了模型的灵活扩展,并且是顺序无关的(减少了处理输出的负担)。除此之外,AIM继承了RIM的特点,包括模块间的彼此竞争,以及和无关输入的注意力对比来对top-K最关注输入的机制的稀疏选择,如下面几个式子所示,其中
z
^
=
[
z
T
,
∅
T
]
T
\hat{\mathbf{z}}=[\mathbf{z}^T,\emptyset^T]^T
z^=[zT,∅T]T:
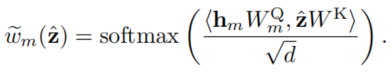

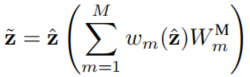
整体来说和RIM是非常像的,但是这里的
h
m
\mathbf{h}_m
hm让我有点不理解,在RIM中这是因为每一个机制都是LSTM模块所以有隐藏状态,但对于AIM来说这个设置感觉没有必要,如果为了区分不同模块,也不需要再乘以
W
m
Q
\mathbf{W^Q_m}
WmQ,至少不需要为每个模块m单独有一个
W
Q
\mathbf{W^Q}
WQ吧。
为了避免机制过拟合(总是激活某些机制),严格的top-K会被替换成了从前top K+l个机制中随机选择K个:
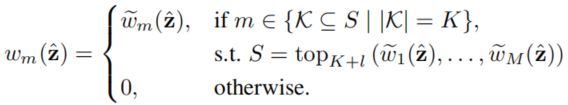
训练流程
作为一个模块,AIM适配不同的算法,如下图所示,特别注意的是,对于特征提取模块,本文采用再所有数据上进行预训练的方式,然后在AIM和其它部分的训练流程中保持不变(这挺重要的,因为根据我的经验,复杂数据集中想要单凭OML或者ANML训练好端到端网络十分困难)。

完整的训练流程如下,适用于持续学习和小样本学习的方法被分开表示(不同颜色)。

(元)验证/测试流程也是类似:

实验结果
从激活情况看,AIM的模块确实起到了选择作用

我比较关心持续学习的效果,在Omniglot,CIFAR-100和MiniImageNet的结果如下图:

个人感觉凭经验看,至少在MiniImageNet上的结果,ANML和OML的低了一些似乎,我怀疑这可能是由于作者选的backbone太小了,导致AIM这样多了很多参数的模型能够表现更好。
















 2107
2107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









