









 本文总结了医疗影像中模态缺失数据的处理策略,包括naive方法、imputation、synthesis和自适应方法。重点介绍了基于生成模型如CycleGAN的模态还原,以及HeMIS、U-Net等网络结构在融合和损失函数上的创新。此外,还讨论了无监督学习、模态dropout和特征标准化等技术在增强模型泛化能力上的应用。
本文总结了医疗影像中模态缺失数据的处理策略,包括naive方法、imputation、synthesis和自适应方法。重点介绍了基于生成模型如CycleGAN的模态还原,以及HeMIS、U-Net等网络结构在融合和损失函数上的创新。此外,还讨论了无监督学习、模态dropout和特征标准化等技术在增强模型泛化能力上的应用。
医疗影像与模态缺失数据
模态缺失的处理思路
最近在调研医疗图像领域关于模态缺失数据的处理。整理了一些文章的思路写了一篇博客。
方法思路
- naive方法,为每种情况专门训练模型(效率低,扩展性差)
- imputation(填充)方法,采用确实模态的平均值或其它统计特征替代缺失值
- synthesis方法,使用其它模态数据生成缺失模态的数据
- 其它领域自适应方法
方法汇总
- Y. Ganin and V. Lempitsky. Unsupervised domain adaptation by backpropagation. In International Conference on Machine Learning, pages 1180–1189, 2015.
基于特征相互生成的生成对抗损失 - J. Manders, E. Marchiori, and T. van Laarhoven. Simple domain adaptation with class prediction uncertainty alignment. arXiv preprint arXiv:1804.04448, 2018.
类预测约束下的生成对抗损失 - Y. Zhang and T. Funkhouser. Deep depth completion of a single RGB-D image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 175–185, 2018.
通道间相互生成的缺失通道补全 - M. Havaei, N. Guizard, N. Chapados, and Y. Bengio. HeMIS: Hetero-modal image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 469–477. Springer, 2016.
基于统计的模态融合
基于生成的方法
主要是使用CycleGAN代表的域到域转换算法。在数据层面或特征层面用已有数据还原缺失数据。
- 数据层面:Translating and Segmenting Multimodal Medical Volumes with Cycle- and Shape-Consistency Generative Adversarial Network(CVPR2018)
- 特征层面:Unsupervised domain adaptation in brain lesion segmentation with adversarial networks(IPMI2017)
HeMIS: Hetero-Modal Image Segmentation (MICCAI2016 Oral)
文章的主要思想:
- 使用统计特征(均值和方差)作为embedding进行解码,特征融合采用均值、方差的融合计算方式
模型结构
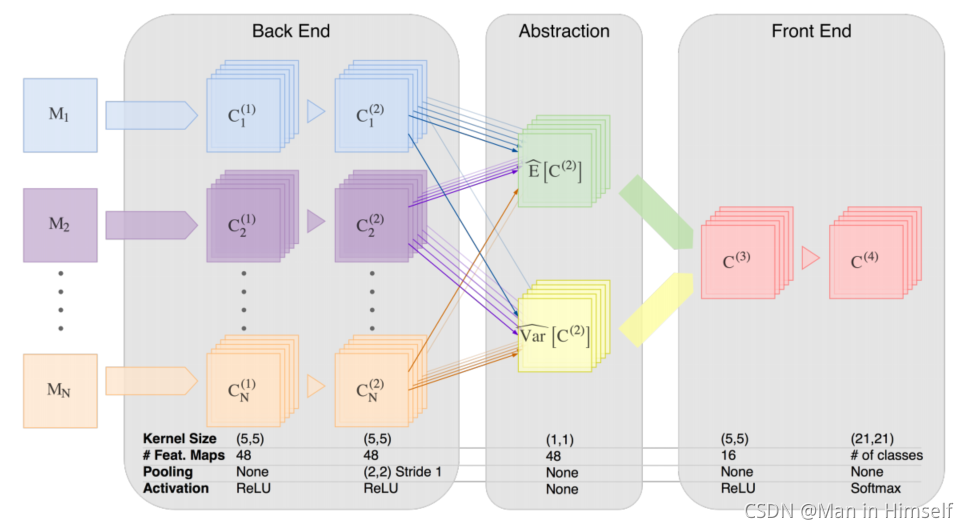
融合方式
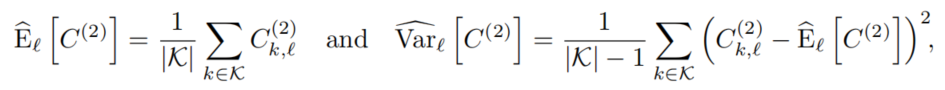
K表示模态数量,l表示feature-map的id(back-end部分最后的特征通道数),最后所有特征拼接起来进行解码。
Brain Tumor Segmentation on MRI with Missing Modalities(IPMI2019)
这篇文章主要提出了以下方法:
- 模态缺失自适应的网络(不需要额外训练)
- 新的领域自适应方法(使用生成对抗损失约束模型在缺失模态下和完整模态的feature-map一致)
- 模态间的解耦使得各个模态的贡献可定量
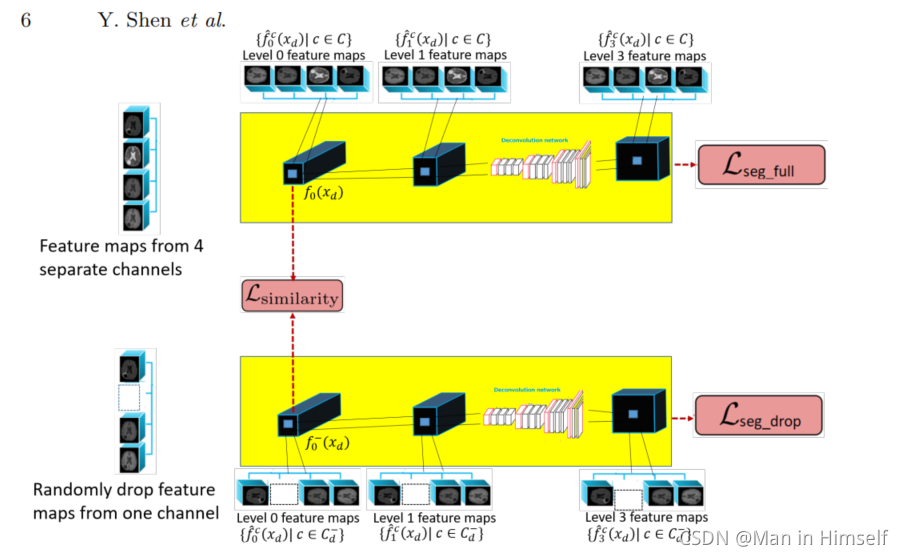
模型结构
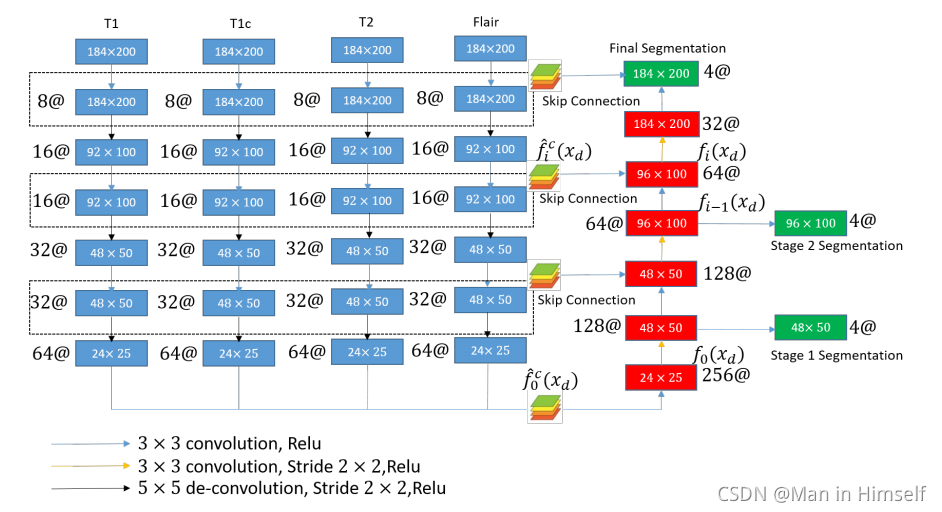
参考U-Net的结构,不同模态拥有独立的编码器,之间采用仅仅在decoder处使用相加方式fusion(decoder部分的skip-connection让深层信息分别和不同模态的skip信息融合,然后相加),不同层次设有辅助分割结果,用来迫使不同层次学习到不同的特征。
损失函数
生成对抗损失:一种用于让模型在模态缺失情况下生成相似特征的损失函数。主要目标是使得模态缺失情况下的底层feature map和全模态情况下相似。方法上使用的是类似GAN的损失函数,由于模态缺失造成的融合特征的期望值下降(采用加法,直接不加缺失的模态),采取缩放方式平衡。
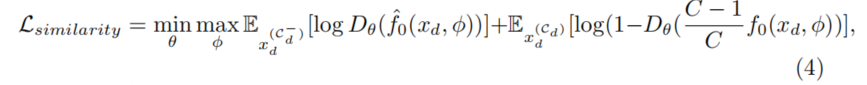
最终损失函数:
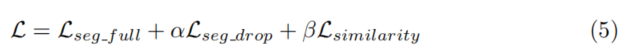
包括:
- 原始的分割损失
- 模态缺失的分割损失
- 上面两种情况下(最高层)特征相似度的生成对抗损失
整体架构图
Multimodal MR Synthesis via Modality-Invariant Latent Representation(TMI2017)
本文提出了一种用于核磁图像生成的网络结构,能够自动用现有的模态还原缺失的模态。网络也是基于自编码器的,无监督的。
模型结构
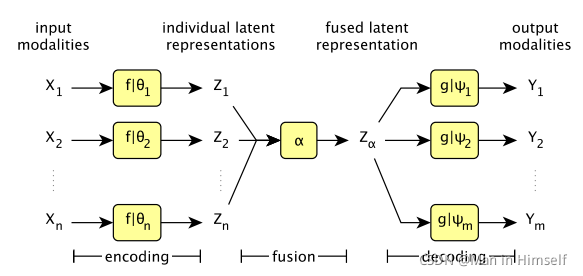
基于自编码器的结构,fusion方式原文采用的是max方式,在特征空间的各个位置选择max的值。作者认为这种方式训练的模型在缺失模态的情况下至少也会比只是用单一模态要好。也可以考虑结合均值fusion等。
损失函数
作者确保modality-invariant的方法主要是在损失函数上,文章认为要做到modality-invariant,模型的目标需要有:
-
每个模态encode后的特征需要能够尽可能精确还原出该模态的原始图像(MAE表示mean absolute error)。
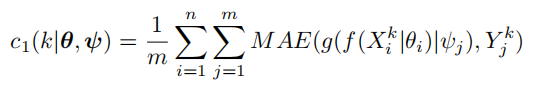
-
各个模态encode后的特征之间在欧氏距离上应该尽可能接近。
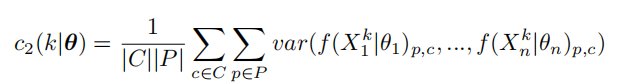
-
经过fuse后的特征应该能够尽可能还原出各个模态的原始图像。
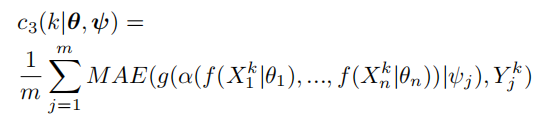
Learning Cross-Modality Representations from Multi-Modal Images(TMI 2019)
本文在多模态任务中提出和测试使用了多种无监督的跨模态特征学习方式,在医疗影像中获得了很好的结果。
基于迁移学习的无监督训练
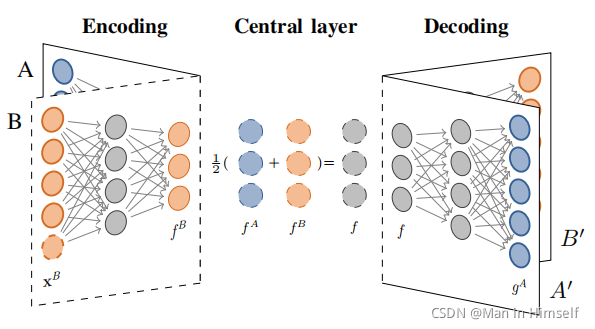
不同模态经过各自encoder后获得feature,在各个模态之间取平均值。该平均值又在各个模态的decoder中还原出原始输入。类似auto-encoder的无监督学习方式。
- 通过encoder获得各个模态的特征
- 将这些特征求平均得到x
- 用x还原各个模态
整体损失函数如下:
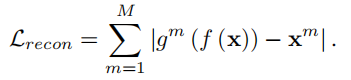
modality dropout
对各个模态求平均不足以使得模型学习到好的跨模态特征,因为模型可能会把不同模态的数据用于求解固定的特征,无法做到解耦。
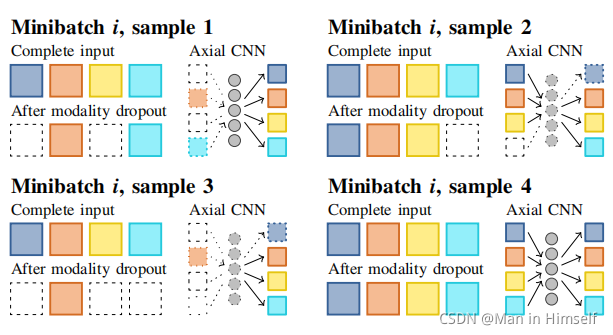
Similarity term in the learning objective
该方法通过为损失函数添加项,要求各个模态的feature靠近平均值。直接使用mse来进行距离度量。
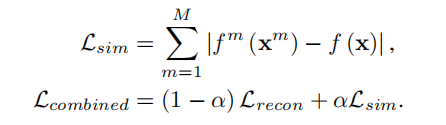
为了防止similarity损失通过减小特征的绝对值来完成,需要进行normalization。
Per-feature normalization
为了防止模型通过disable某一部分的特征来使得不同的特征出现较大差异,将每一个模态的特征进行normalization到均值0方差1。
实验效果
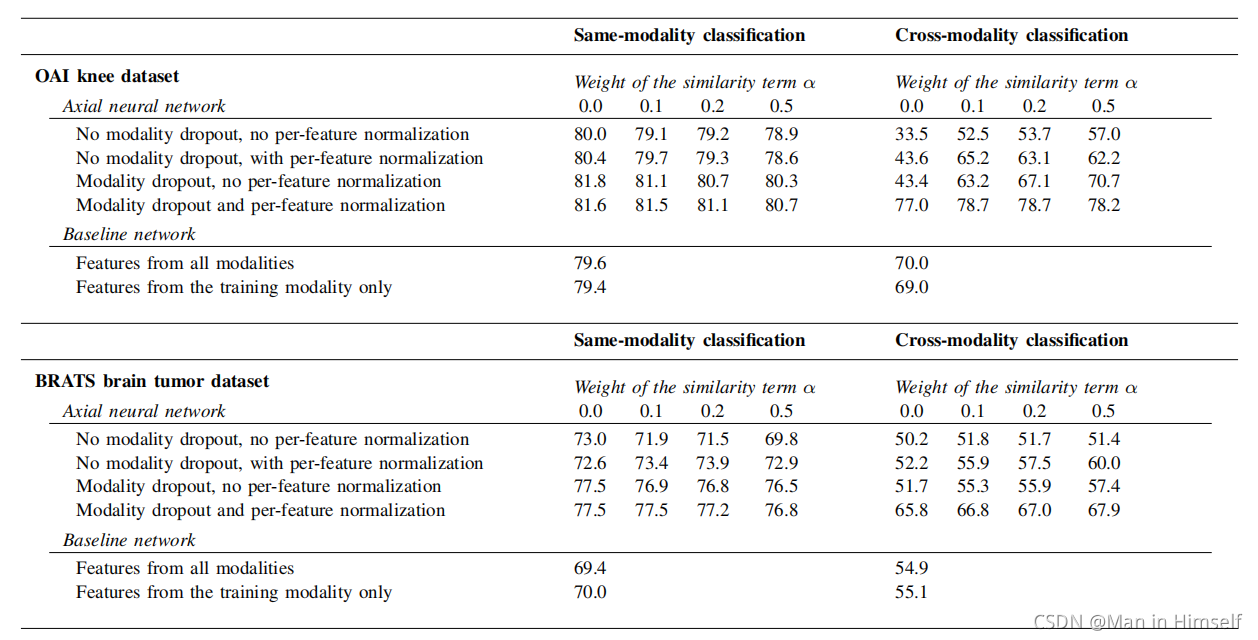
训练分类器进行拟合:
same-modality:学习和验证的特征来自于同一个模态。
cross-modality:学习和验证的特征来自于不同模态。
可以看到这些方法确实提高了效果。


















 606
606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









