







前言
博客得主要目的是记录自己的学习收获,排版、行文都会比较随意,内容也主要以自己能理解的方式描述,还希望各位看客见谅。
本文为中国人民大学发表在IJCAI2021上的预训练语言模型文本生成综述论文。我目前的想法是重点关注文章的结构,再具体补充其中的内容。
论文链接:https://arxiv.org/abs/2105.10311
目录
三、ENCODING INPUT REPRESENTATIONS
四、DESIGNING PLMS FOR TEXT GENERATION
4.1.4 Encoder-Decoder Language Models
五、 OPTIMIZING PLMS FOR TEXT GENERATION

引言
一、INTRODUCTION
p1:文本生成的简单介绍——文本生成的目标是生成通顺可读的自然语言。文本生成技巧可以广泛应用于对话系统、机器翻译和摘要生成任务中。
p2-p4:文本生成的研究历史
- p2:基于统计的方法——>面临 data sparsity的问题,需要smoothing
- p3:基于深度学习的方法——>从seq2seq到attention和copy机制——>面临数据不够多,容易过拟合的问题
- p4:基于PLM的方法——>好,所以我们关注
p5:本文与其他文本生成综述论文的区别——大部分综述是以任务的视角去描述文本综述的,如对话生成,摘要生成等。本文将更多从文本生成本身这个角度阐述。
p6:文章结构阐述
二、PRELIMINARY
2.1 文本生成
介绍了文本生成的定义。,通过输入x的不同对文本生成进行分类。
2.2 预训练模型
2.3 基于预训练的文本生成方法
本文认为,如果希望利用预训练语言模型实现文本生成,需要重点考虑三个问题,这三个问题分别从输入数据,模型结构和优化方法的角度进行阐述。这三个问题分别是:
- How to encode the input 𝑥 into a representation preserving the input semantics that can be fused into the PLM ?
- How to design an effective PLM M to serve as the generation function
and adapt to various text generation tasks?
- How to optimize the text generation function (i.e., PLMs)
?
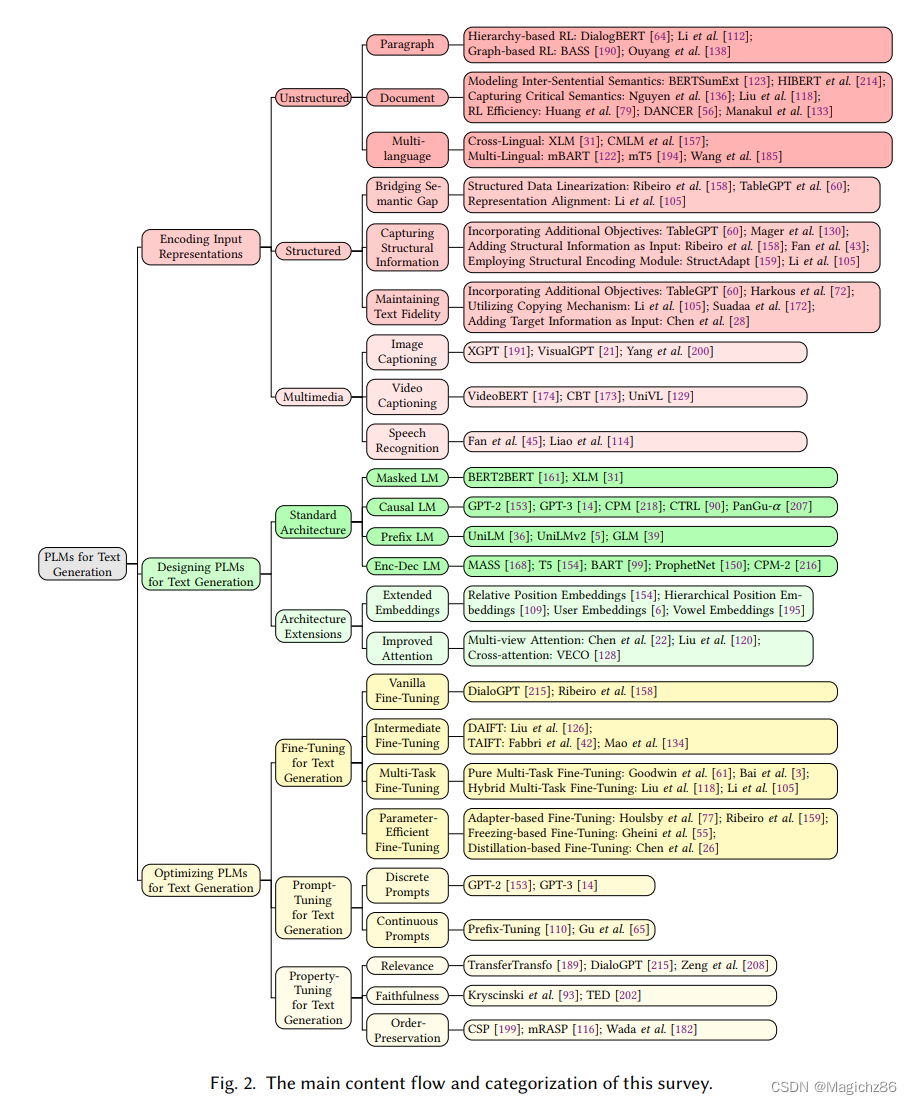
三、ENCODING INPUT REPRESENTATIONS
通过三种不同的输入:非结构化输入、结构化输入和多模态输入描述预训练模型输入数据的问题
3.1 非结构化输入
3.1.1 段落级表示学习
目的是同时学习到低级别的word meaning和高级别的topic sematics。主要通过hierarchy-based或者graph-based方法学习段落表示。
- hierarchy-based:对于一个包含多语句的段落输入,如多轮对话,直接的进行拼接难以捕捉语句之间的语义联系。因此,使用hierarchical编码器学习输入段落。
- graph-based:一个长段一般会包含一些冗余的、重复的信息。如果能把关键的语义信息提取出来,去除冗余信息可以很好地捕捉段落语义。相比于序列,图可以更好地表示这层关系。
3.1.2 文章级表示学习
输入是包含多个段的文章。
- 对句子间的关系进行建模。
- 保留重点语义信息,去冗余信息。
- 提高表示学习的效率
3.1.3 多语言表示学习
分为Cross-lingual(两种语言)和Multi-lingual(多语言)注:不知道为什么写这一段,不应该放在3.3吗。
3.2 结构化输入
结构化输入是我比较关注的。结构化输入目前面临以下三个挑战。注:这三个点基本跟TableGPT里总结的是一样的,在我看来主要就是两点:一是plm是序列输入训练的,所以有语义鸿沟;二是需要保留结构信息。
- There exists a semantic gap between structured data and PLMs, since PLMs are typically pre-trained on natural language texts;
- It is non-trivial to encode the structural information in the input data;
- It requires to maintain fidelity of the generated text with respect to the input.
之后文章根据各点都撰写了解决方式,有重复,我这里总结为以下几点:
- 把结构化输入转化为序列化输入:通过模板的方式或者直接添加结构信息。
- 对齐结构化输入和序列化输入的表示:例如最小化结构化输入gnn和plm encoder的语义距离。
- 增加结构化encoder模块
- 使用copy机制
3.3 多模态输入
本人的研究方向不涉及这个,不总结了...
四、DESIGNING PLMS FOR TEXT GENERATION
4.1 标准结构
现有的机构包含单独使用transformer的编码器或者解码器,或者使用基于transformer的编码器-解码器结构,文章将这种标准结构分为四个变体:masked LMs, causal LMs, prefix LMs和seperate encoder-decoder结构。
4.1.1 Masked Language Models
类似transformer的编码器,如BERT。然而,这类模型由于与训练任务和文本生成之间的差异性,一般不适用于文本生成任务。一般作为文本生成的编码器存在。
4.1.2 Causal Language Models
类似transformer的解码器,如GPT系列。这类模型的缺点在于忽视了输入端的双向信息,而且不适用于seq2seq式的生成任务。
4.1.3 Prefix Language Models
输入双向,自回归式输出的单个Transformer。UniLM是第一个PrefixLM模型。然而与encoder-decoder相比,还是encoder-decoder的效果好一些。
4.1.4 Encoder-Decoder Language Models
标准的transformer架构
4.2 结构改进方法
有些工作是通过改进transoformer的结构去提高文本生成效果的。这种改进主要可以分为两类:
4.2.1 扩展输入embedding
文章主要标注了两种方法,一种是对position embedding进行改进,比如从绝对位置编码到相对位置编码,甚至表示句子和句子间的位置编码。第二种是增加辅助embedding,例如在多模态下增加语音embedding等。
4.2.2 改进注意力机制
1、为了适应长文本输入和降低复杂度没引入sparse attention。2、由于使用多个编码器,对cross attention进行改进。
五、 OPTIMIZING PLMS FOR TEXT GENERATION
主要分为三种方式介绍优化方法:fine-tuning, prompt-tuning, 和 property-tuning
5.1 Fine-Tuning
5.1.1 Vanilla Fine-Tuning
最正常的微调方法。主要问题是在小数据集上容易过拟合。
5.1.2 Intermediate Fine-Tuning
采用一个足够大的中间数据集帮助微调。主要分为:
- 1、不同领域的相同任务数据集。
- 2、相同领域的不同任务数据集。
5.1.3 Multi-Task Fine-Tuning
这种多任务微调方式可以增强PLM的鲁棒性和对大量有标签数据的依赖。主要分为:
- Pure Multi-Task Fine-Tuning:采用与主文本生成任务相同,但是领域不同的方法(主要是数据集)。
- Hybrid Multi-Task Fine-Tuning:采用与主文本生成任务不同的方法
5.1.4 Parameter-Efficient Fine-Tuning
上述方法耗时,因此介绍这类微调方法
- Adapter-based:在每一层添加two feed-forward layers 和 a non-linear layer作为adapter,然后只微调adapter。
- Freezing-based:只微调PLM的部分参数
- Distillation-based:把PLM中的知识蒸馏到小模型中,然后训练小模型。
5.2 Prompt-Tuning
这部分介绍的就是最近比较火的提示学习在文本生成方向上的应用。简而言之,提示学习就是将文本生成下游任务形式化为和预训练任务相似的language model任务。
5.2.2 Discrete Prompts
5.2.3 Continuous Prompts
5.3 Property-Tuning
对于不同的文本生成任务,在微调PLM的时候我们需要考虑不同的属性(property)。这一小章主要针对三个在文本生成中的重要属性。
5.3.1 Relevance
输出文本中传达的主题语义应该与与输入文本高度相关。
5.3.2 Faithfulness
指生成的内容应符合输入文本的语义,生成的文本符合事实。
5.3.3 Order-Preservation
输入和输出文本中语义单元(单词、短语等)的顺序是一致的。对于摘要生成和机器翻译等任务很重要。
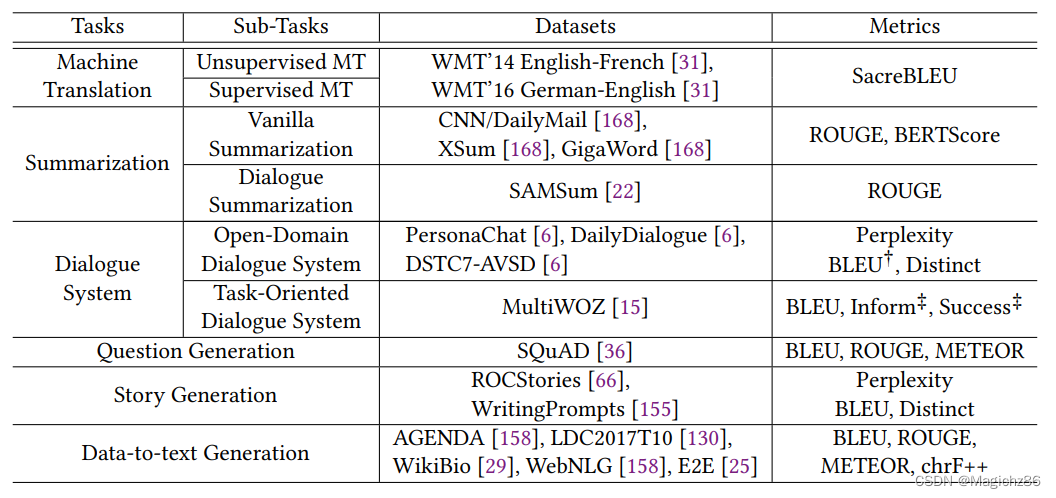
6 CHALLENGES AND SOLUTIONS
总结如下表所示:

7 EVALUATION AND RESOURCES
7.1 评估指标
7.1.1 N-Gram Overlap 指标
包含BLEU,ROUGE,METEOR,ChrF++(用于机器翻译)
7.1.2 多样性指标
包含Distinct
7.1.3 语义相似度指标
包含BERTScore
7.1.4 概率相关指标
包含PPL(感觉就是直接通过loss计算的)
7.2 Resources
Benchmark有GLUE
8 APPLICATION
这里就不详细写了,主要分为机器翻译,摘要生成,对话系统和其他。也可以看出对于文本生成来说,机器翻译和摘要生成是最火的应用方向。
9 CONCLUSION AND FUTURE DIRECTIONS
除了对上述内容的总结外,文章提到了一些他们发现的问题和方向。
- 1、可控的生成
- 2、探索更多的优化方法
- 3、其他语言的PLM
- 4、生成文本的伦理道德问题


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









