






浅浅的记录一次在实验中遇到的坑,这里主要记录一下prefixtunning在BART中是如何实现的。
先看看其他人是如何实现的,我目前在网上找到的代码包括openprompt版本[1]的代码和prefixtunning作者自己上传到github上的代码[2]。
这两个代码都存在一定的问题。作者这个源代码写的太乱了,加了很多if,我实在是看不清楚,而且作者也是修改了huggingface的源代码,但具体改了哪里也没说明(也可能我没注意到?)。openprompt这个代码就简洁明了很多了,但这个代码是by-case的,也就是没有实现针对BART的prefixtunning,实现的是针对T5和GPT2的prefixtunnig。
但是观察两个代码的共同点,这两个代码都用到了transformers库里的一个特定的参数:
past_key_values
我们首先看一下官方文档里对这个参数的解释,

简单翻译一下,也就是这个参数是用来通过添加自定义的key和value值加速解码过程的。实话实说,这个解释看完后我一头雾水,这跟prefixtunning有什么关系呢。prefixtunning的思想是加入一组可以微调的prompts,然后在训练的时候冻结预训练语言模型的参数只训练这组参数。
后来看到记录一次对past_key_values用法的理解 - 知乎这篇博客后,就恍然大明白了。重点在pre-computed这句话。prefixtunning原论文对他们加入的可训练参数是怎么具体实现的写的特别隐晦:
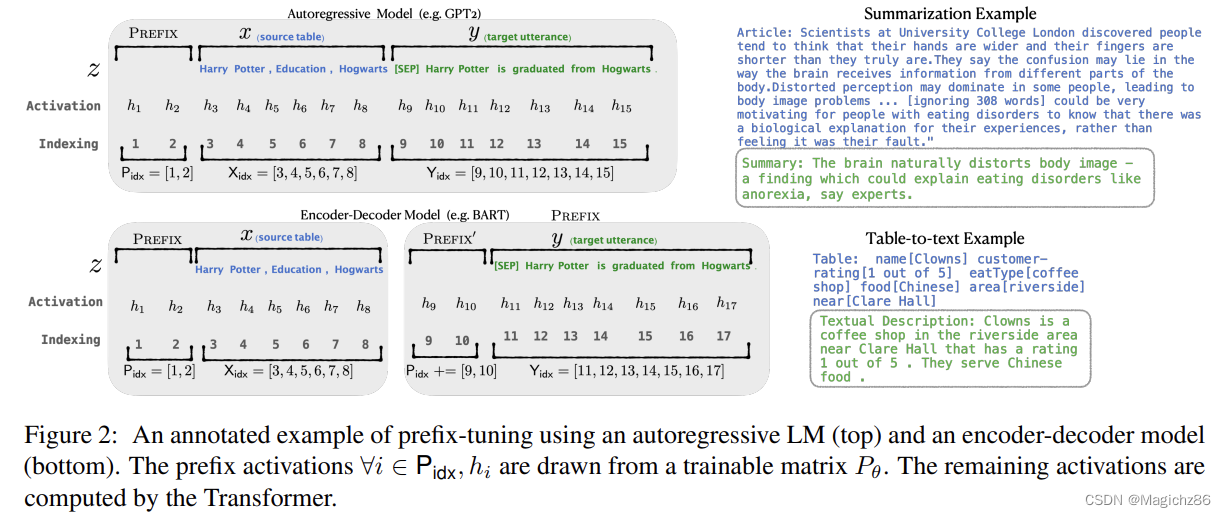
原论文用Acitivation一笔带过了,实际上就是通过自己生成一组key和value然后传入了模型中,具体实现如下:
class PrefixEncoder(torch.nn.Module):
def __init__(self):
super().__init__()
self.embedding = torch.nn.Embedding(seq_len, dim_ebd)
self.trans = torch.nn.Sequential(
torch.nn.Linear(dim_ebd, number),
torch.nn.Tanh(),
torch.nn.Linear(number, num_layer * n * dim_ebd)
).to(device)
def forward(self, prefix):
prefix_tokens = self.embedding(prefix)
past_key_values = self.trans(prefix_tokens)
return past_key_values这里seq_len就是prefix的长度,dim_ebd是模型的维度(bart-base是768)。number可以自己定义,越大参数量就越大(相对应的训练时间就会越长,但这跟提示学习的思想就相违背了),n取决于具体哪个模型,对于bart来说应该是4。
实际上到这步应该就结束了,但是问题就是past_key_values原本不是用来做prefixtunning的,是用来加速decoding的,这带来了第一个大坑:也就是模型训练的时候用不上这个参数(因为是teacher-forcing),但是在模型做自回归生成的时候tansformers自己会调用这个参数。你如果用model.generate()直接尝试解码是会报错的。这里有两种解决方法:
1、自己写decoding的代码,反正的decoding是一个很模块化的过程,就可以调用各种包。
2、参考openprompt的方法,对transformers源代码进行修修补补。但是我觉得这种做法挺难的。
另一个大坑是BART独有的,我们具体看一下past_key_value在bart里是怎么传递的。
首先从BartForConditionalGeneartion传到BartModel:(self.model)——
——>然后从BartModel传到BartDecoder:(self.decoder)——
——>从BartDecoder传到BartDecoderLayer:(decoder_layer)——>
然后就是关键了,这里开始对past_key_values里的值进行操作了:
首先模型会把past_key_values(一个长度为4的tuple)对半分开,分别给self attention和cross attention使用
![]()
![]()
这两个会分别送入两个BartAttetion模块中,

这一部分非常关键!其实看到这里也就明白了,由于在cross attention中,key_states和value_states的值是通过你传入的参数直接赋值的,而不是像self attention一样是拼接的,这会导致模型学习的时候学习不到编码器的表示,换言之,本来应该传递给解码器的编码器表示被忽略掉了。具体在val的时候,就会发现模型对任何不同的输入输出都是一样的。
解决办法也比较简单,直接把第一个if删掉就好了,然后传past_key_value的时候不要传后两个tuple了。
2022-7-23 更新
清华大学的opendelta项目上也实现了BART做prefixtunning的代码,google一下就能看到了。















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









