







 本文探讨了一种新的文本生成方法——PTG(PromptTransferforTextGeneration),它利用迁移学习和提示学习策略解决数据稀缺场景下的文本生成挑战。通过在源任务中学习源提示并将其转化为目标提示,PTG在14个数据集和3类任务上展现出与微调预训练语言模型相当的性能。实验表明,这种方法不仅效果良好,而且具有通用性和轻量级特性。
本文探讨了一种新的文本生成方法——PTG(PromptTransferforTextGeneration),它利用迁移学习和提示学习策略解决数据稀缺场景下的文本生成挑战。通过在源任务中学习源提示并将其转化为目标提示,PTG在14个数据集和3类任务上展现出与微调预训练语言模型相当的性能。实验表明,这种方法不仅效果良好,而且具有通用性和轻量级特性。
新鲜出炉的一篇NAACL的论文,通过迁移学习的方法集成提示学习的策略。
文章链接:https://arxiv.org/pdf/2205.01543
开源代码链接:GitHub - RUCAIBox/Transfer-Prompts-for-Text-Generation
一、摘要
近年来,文本生成任务在PLMs+微调的加持下取得了显著进展。然而,在数据稀缺场景下对PLM进行微调依然是具有挑战的。因此,基于PLM开发一个通用且轻巧的模型是十分有必要的。本文将介绍一种基于prompt的迁移学习方法(PTG)。PTG通过从sorce prompt中学习特征,并迁移为target prompt的方法实现目标文本生成。实验表示PTG能够产出和微调不相上下的结果。
二、概述
在NLP中,文本生成是一项重要的研究任务。其目的在于从源数据中自动生成人类可读的文本。近年来,PLM通过在大规模数据集上对巨量的参数进行学习的方法在文本生成中取得了实质性进展。通过在有标注数据集上进行微调的方法,PLM可以适应多种文本生成类任务。
然而,在真实场景中,我们需要对有限标注的数据集进行处理。在这种数据稀缺场景下进行微调往往是十分困难的。而即使不同的文本生成任务的输入输出源不同,他们都使用类似的生成策略。这为文本生成模型的迁移学习提供了可能性。因此,本文旨在提出一种通用且轻量的文本生成方法。
prompt-based learning(提示学习)提供了一种潜在解决方法。提示学习通过添加具体任务相关的提示生成文本。然而,在迁移提示依然面临两个主要挑战:
task-level:提示是高度任务相关的,难以为新任务利用构建好的提示。
instance-level:即使处理相同的任务,同一个提示也没办法覆盖所有的数据实例。
基于以上挑战,本文提出了PTG:Prompt Transfer for Text Generation,一种适用于文本生成,基于提示学习的迁移学习方法。具体来说,我们从一些具有代表性的源(source)生成任务中学习源提示(source prompts),然后将这些提示作为目标提示(target prompts)来执行目标生成任务。其核心思想是将学习到的源提示作为表示库(注意力机制中的value),对每一个具体任务和具体实例进行动态表示。
本文是第一个在文本生成任务中提出提示迁移学习的。本文在14个数据集,3类任务(compression,transduction和creation)中测试了PTG,结果均可以比肩或超过微调PLM的方法。不仅如此,本文公开了其源提示作为开源库供大家使用。
三、相关工作
3.1 基于提示学习的PLM
本文使用了软提示(连续提示)方法。
- 手工构造提示 ——> not flexible and cannot be applied to more kinds of new tasks,
- 离散提示 ——> hard to optimize and likely to be sub-optimal
- 连续提示 ——> more flexible to many kinds of tasks
3.2 NLP中的迁移学习
先前的研究已经表明,不同任务之间的迁移学习可以缓解数据稀疏的问题,增强复杂推理能力,学习更有效的表示。
注:Preliminary中的定义和概念已省略
四、方法
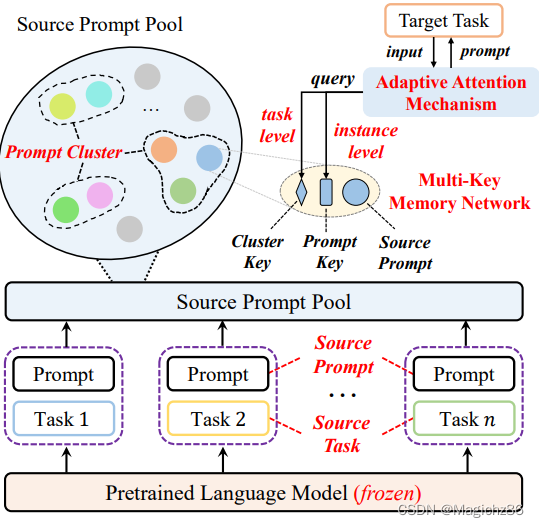
4.1 Learning Transferable Source Prompts
为了从源任务中学习任务相关的知识,本文学习一组源提示并将它们存储在源提示库中。引入源提示库的动机有二,一是本文期望识别源任务之间的相似性,二是库内存储的源提示可以为所有的目标任务所共享。
这个过程分为三部分:
- 在BART上加入一组额外参数进行提示学习,从14个3类数据集中学习到源提示库。
- 对学习到的源提示向量进行谱聚类,将提示表征到一个带权重的无向图中,并使用公式(1)计算两个点pi和pj之间的距离,k代表提示p的第k个向量。然后使用最大最小割算法将图分割为m个类(n是聚类中心的数量)。这种方法可以有效的将不同源提示进行区分。
- 通过一个multi-key 记忆网络进行存储,k是key(2)
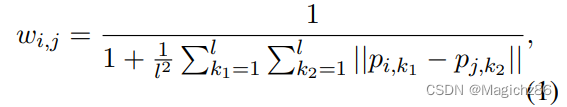
![]()
4.2 Transferring Instance Adaptive Prompts
之前的研究大部分都只考虑具体任务,而不考虑具体的输入。本文通过自适应注意力机制融合每一个文本的输入信息。
首先,取输入放进BERT后的最后一层平均向量作为instance-level query,可学习的向量作为task-level query
,计算一个分数
(4),通过公式
动态获取一个源提示。这种动态提示方法非常值得参考和借鉴。
![]()
最后,根据选择的提示+BART进行生成。
五、实验
5.1 实验设置
数据集:
- compression:用简洁的文字表达输入中的重要信息,包括摘要生成(CNN/Daily Mail,XSum,MSNews,Multi-News,NEWSROOM)和问题生成(SQuAD)
- transduction:在精确保留内容的同时转换文本形式,包括style transfer(Wiki Neutrality)和text paraphrase(Quora)
- creation:从原文本中生辰新内容,包括dialog(PersonaChat,PersonaChat, TopicalChat,DailyDialog,DSTC7-AVSD,MultiWOZ)和story generation (WritingPrompts)
对比组设置:
- GPT-2, BART,T5
- PREFIXTUNING
- SPOT
- MULTI-TASK MODELTUNING
评价指标:
BLEU,ROUGE,Distinct
5.2 实验结果
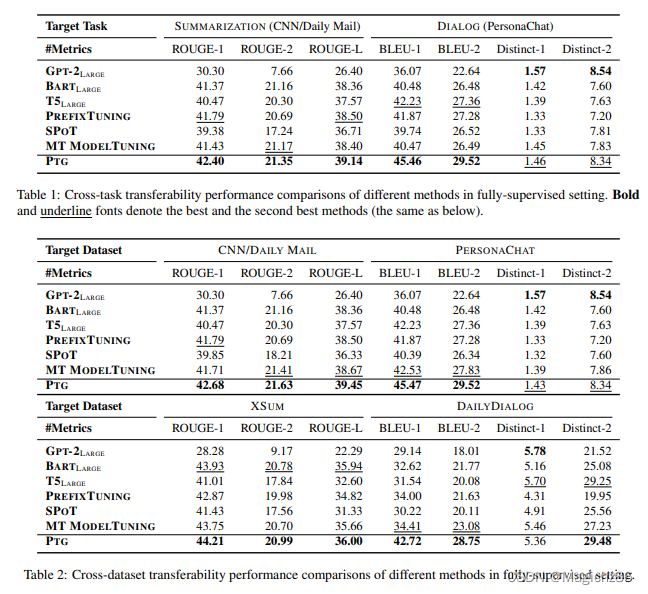
1、Full supervise settings
2、 Few shot

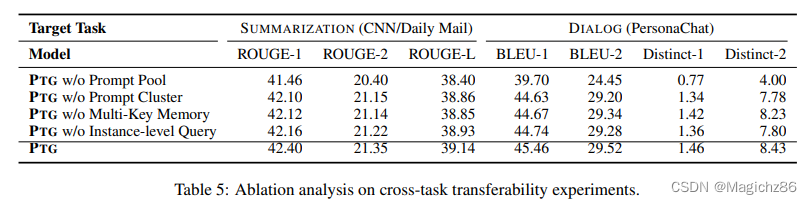
3、Ablation analysis
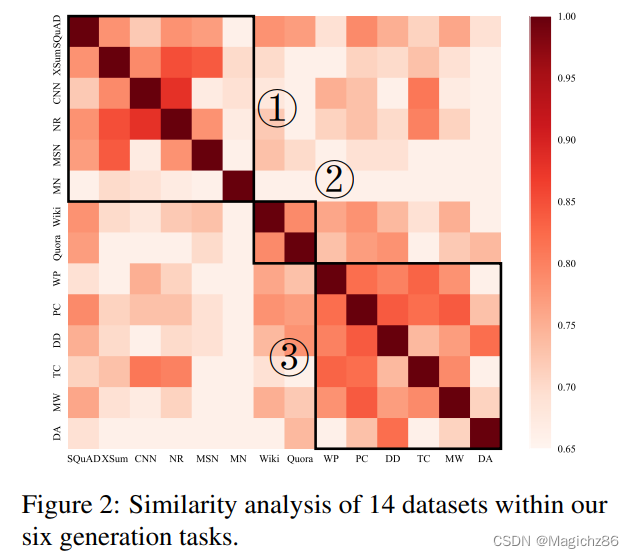
4、Task Similarity Analysis


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









