






1.概念:索引是帮助Mysql高效获取排好序的数据结构
2.索引数据结构
二叉树:左小右大,无限层级
红黑树:左小右大,平衡层级
Hash表:通过hash计算以存储hash值
很多时候比B+树更加高效,但仅仅能满足=,in,无法范围查询
存在hash冲突问题,hash值相同,循环比对也会消耗性能
B-Tree:数据从左向右递增,索引不重复,叶子节点和子节点有相同深度

B+Tree:变种B-Tree,只有叶子节点存储数据,节点间使用指针连接(在使用范围查询时更高效)
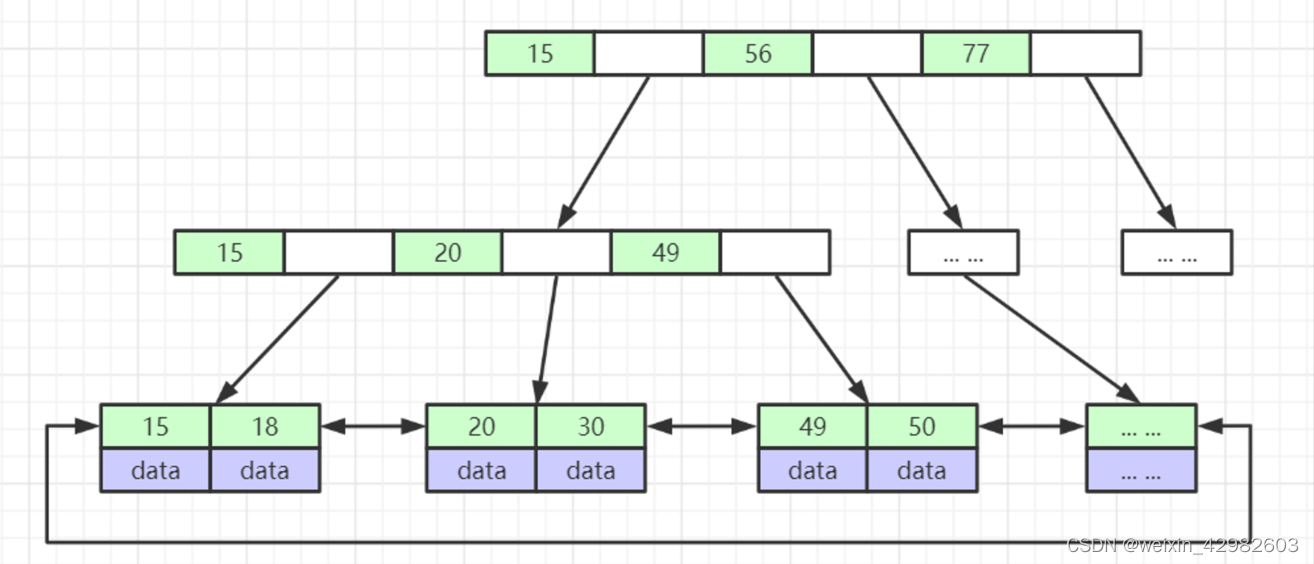
3.Mysql两种存储引擎比较
MyISAM:索引文件和数据文件分离(非聚集),叶子节点只存放数据文件的内存地址,不直接存放数据
InnoDB:索引和数据在一起(聚集),主键索引叶子节点就包含整行数据,普通索引叶子节点存放主键数据,根据主键回表查询数据。
4.常用索引(联合索引):左匹配原则

5.问题思考
为什么InnoDB为什么要建立主键,并且使用整形自增呢?
innoDB在构建B+树索引数据结构的时候,需要用用主键来组织树结构,如果没有,Mysql会建立隐藏列,但这个会消耗Mysql性能,所以要建立主键,在查找数据时,需要根据数据来定位,整形比大小并且占用空间小,使用自增会让树构建过程中更加快速,如果不是自增会让树结构变得复杂。
为什么Mysql索引使用B+树,不用B树?
1.B+树支持范围查找,因为根节点有双向指针。
2.B+树只有叶子节点存储数据,在查询时加载根节点效率更快。
为什么非主键索引叶子节点存储的是主键值?
如果普调索引也把一整行数据放在叶子节点,对存储空间占用有影响,在数据操作时候也需要同步更新主键索引。
联合索引为什么是左匹配原则
如图,如果查询条件为age=30,会走全表扫描,没法确定叶子节点后面有没有age=30的数据
如果查询name=Bill,只会在叶子节点的部分空间中查询。
















 64
64











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











