







Masked image modeling 是一种训练深度学习模型的技术,尤其是在视觉领域,类似于自然语言处理中的掩码语言建模(Masked Language Modeling)。它通过在输入图像中随机遮挡(或称为掩码)部分区域,然后训练模型来预测这些被遮挡部分的内容,从而提高模型的视觉理解能力。
Masked image modeling 主要用于视觉自监督学习(Visual Self-Supervised Learning)任务,帮助模型学习图像的内在结构和表示,而无需依赖大量的标注数据。
BEIT: BERT Pre-Training of Image Transformers
具体来说,在我们的预训练中,每个图像都有两个视图,即patch image(如16×16像素)和visual token(即离散标记)。我们首先将原始图像“tokenizer”为视觉标记。然后,我们随机mask some image patches,并将它们输入Transformer。预训练的目标是基于corrupted image 恢复原始视觉标记。在预训练BEIT之后,我们通过在预训练的编码器上附加任务层来直接微调下游任务的模型参数。
注:模型学习恢复原始图像的视觉标记,而不是掩码块的原始像素。
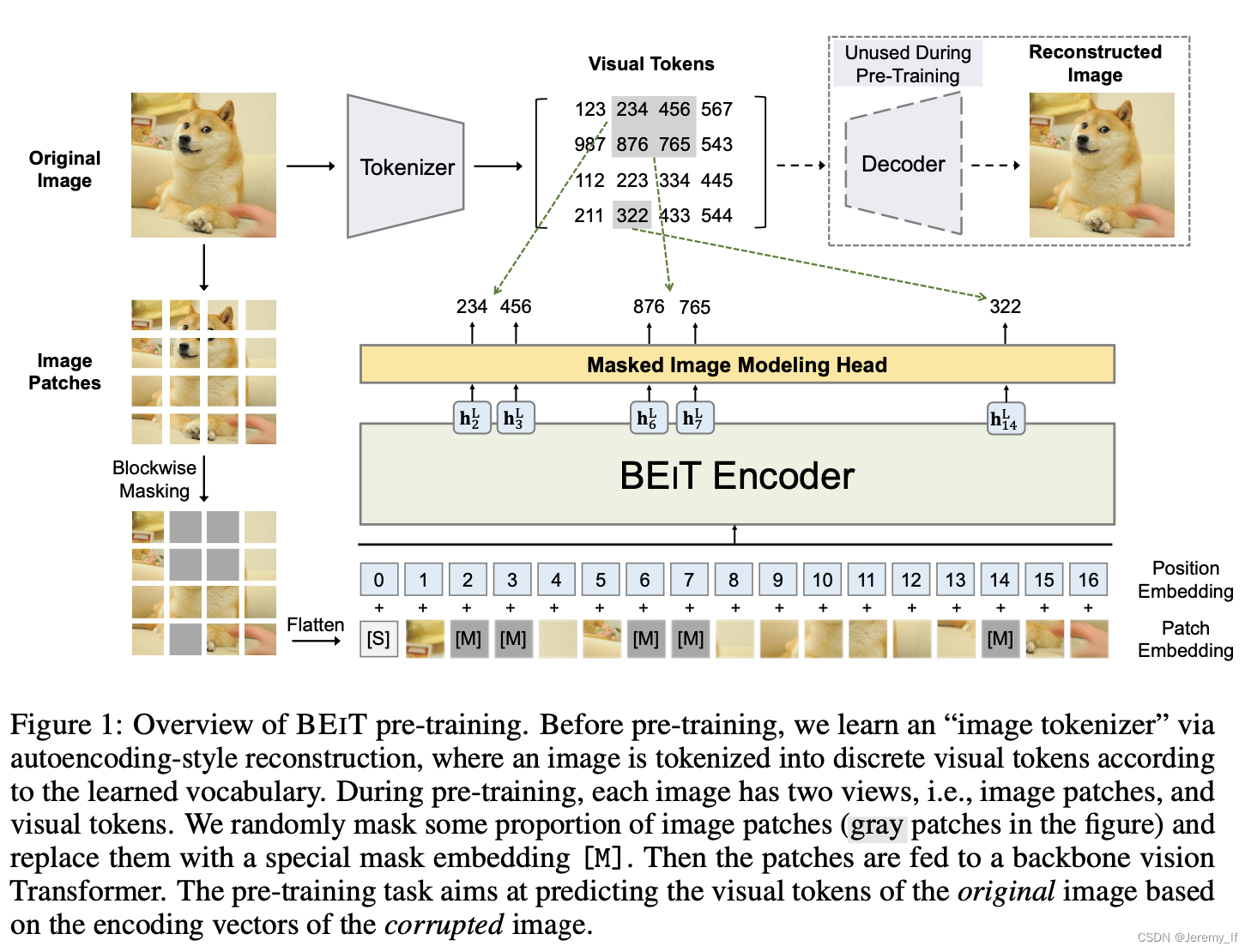
对于重建目标,BEiT 并没有使用原始的像素,而是通过一个 “image tokenizer” 进行离散化,遵循的是 dVAE 的思路,在 BEiT 预训练之前,先构建 “tokenizer” 和 “decoder” 进行 dVAE 的训练,并构建视觉词汇表,词表大小为8192。在 BEiT 中是直接采用 Zero-shot text-to-image generation 文章开源的代码进行训练。论文中掩码比例为40%,直接使用pixel-level auto-encoding像素级的自动编码(recovering the pixels of masked patches)进行视觉预训练,促使模型关注short-range dependencies和 high-frequency details。
实验
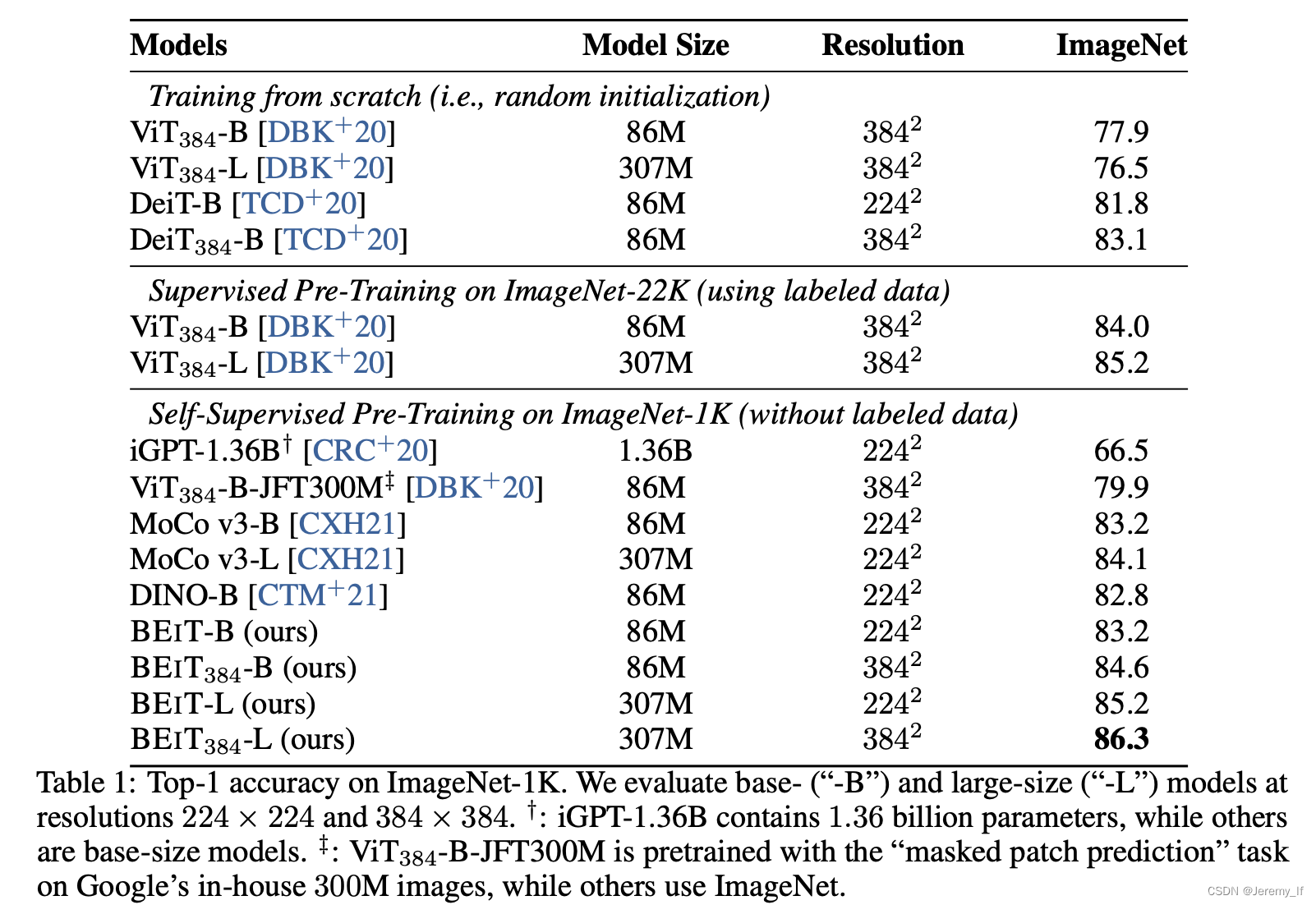
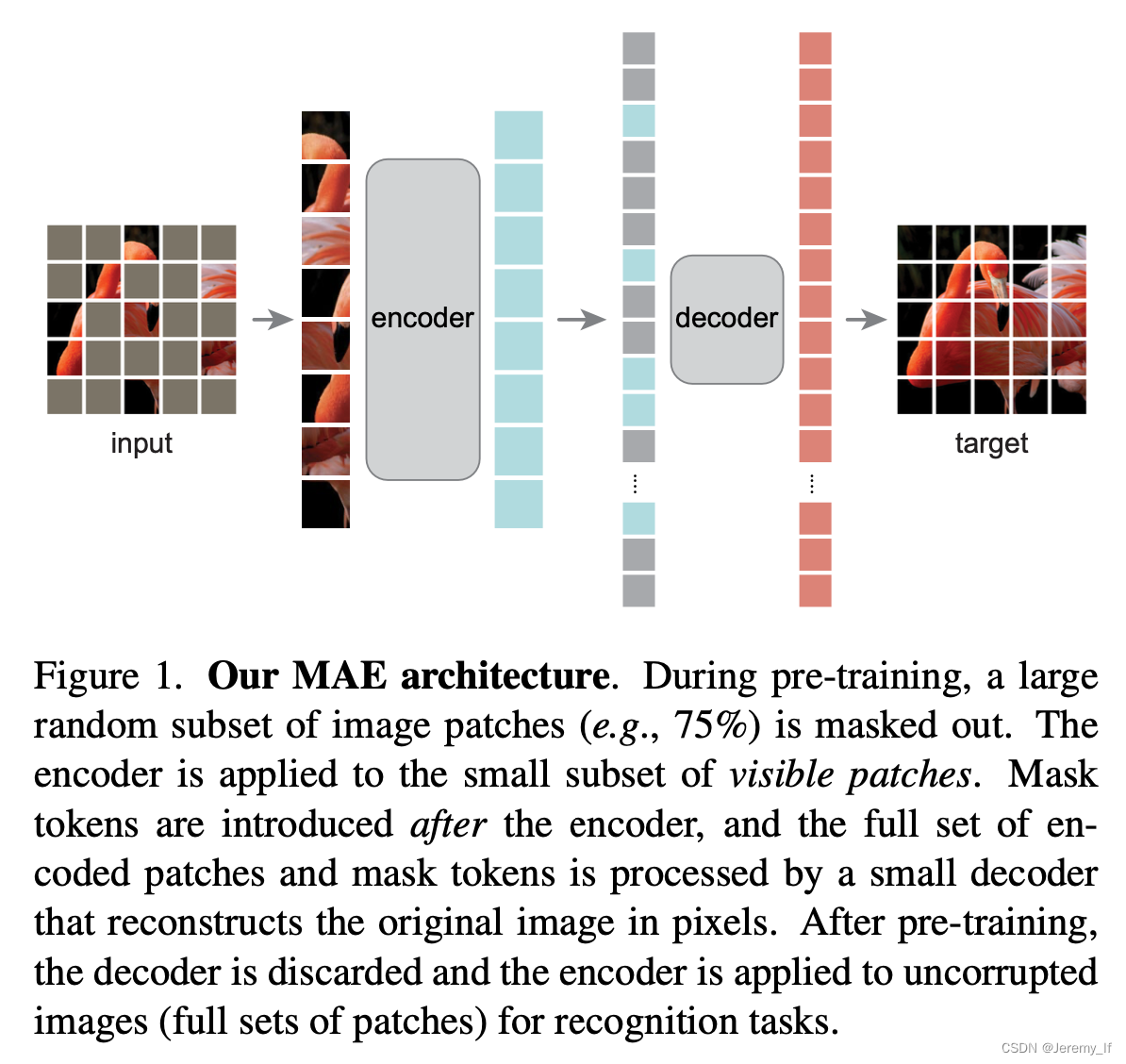
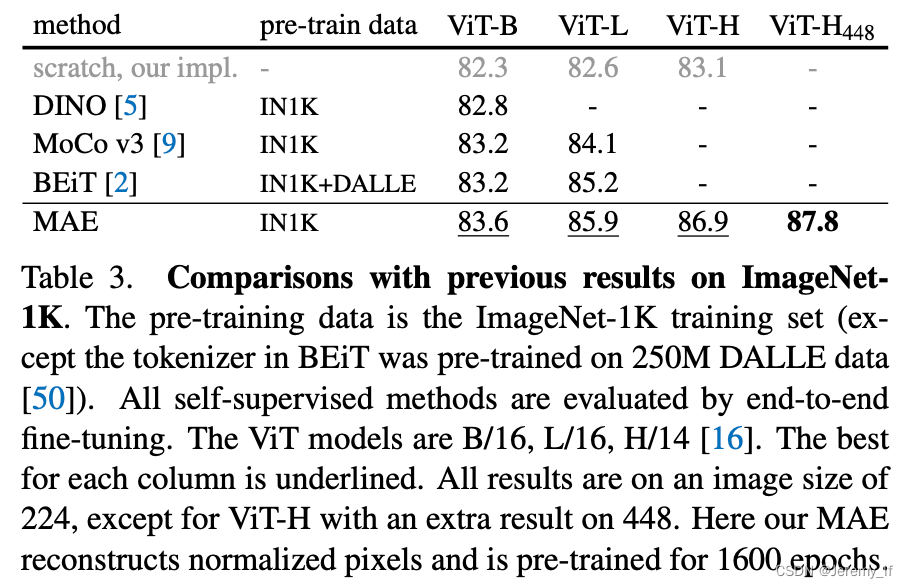
MAE:Masked Autoencoders Are Scalable Vision Learners
任务:对输入图像的随机mask image patch,并重建丢失的像素。
MAE 基于两大主要设计:一是采用了非对称结构的编码-解码器,其中编码器只计算非掩码图像块,同时采用了轻量化的解码器设计;二是mask大部分的图像块,如掩码概率为 75%,可以获得更加具有意义的自监督训练任务。
去噪自动编码器(DAE)[58]是一类破坏输入信号并学习重建原始未破坏信号的自动编码器。
Reconstruction target.
我们的MAE通过预测每个掩码补丁的像素值来重建输入。解码器输出中的每个元素都是表示补丁的像素值的矢量。解码器的最后一层是一个线性投影,其输出通道的数量等于补丁中像素值的数量。解码器的输出被重新整形以形成重建的图像。我们的损失函数计算像素空间中重构图像和原始图像之间的均方误差(MSE)。我们只计算mask patch的损失,类似于BERT[14]。
我们还研究了一种变体,其重建目标是每个masked patch的归一化像素值。具体来说,我们计算一个patch中所有像素的平均值和标准偏差,并使用它们来规范化这个patch。在我们的实验中,使用归一化像素作为重建目标提高了表示质量。
Simple Implementation.
image --> randomly shuffle the list of tokens remove the last portion of the list,based on the masking ratio.首先,我们为每个输入补丁生成一个令牌(通过添加位置嵌入的线性投影)。接下来,我们随机打乱令牌列表,并根据掩码比率删除列表的最后一部分。
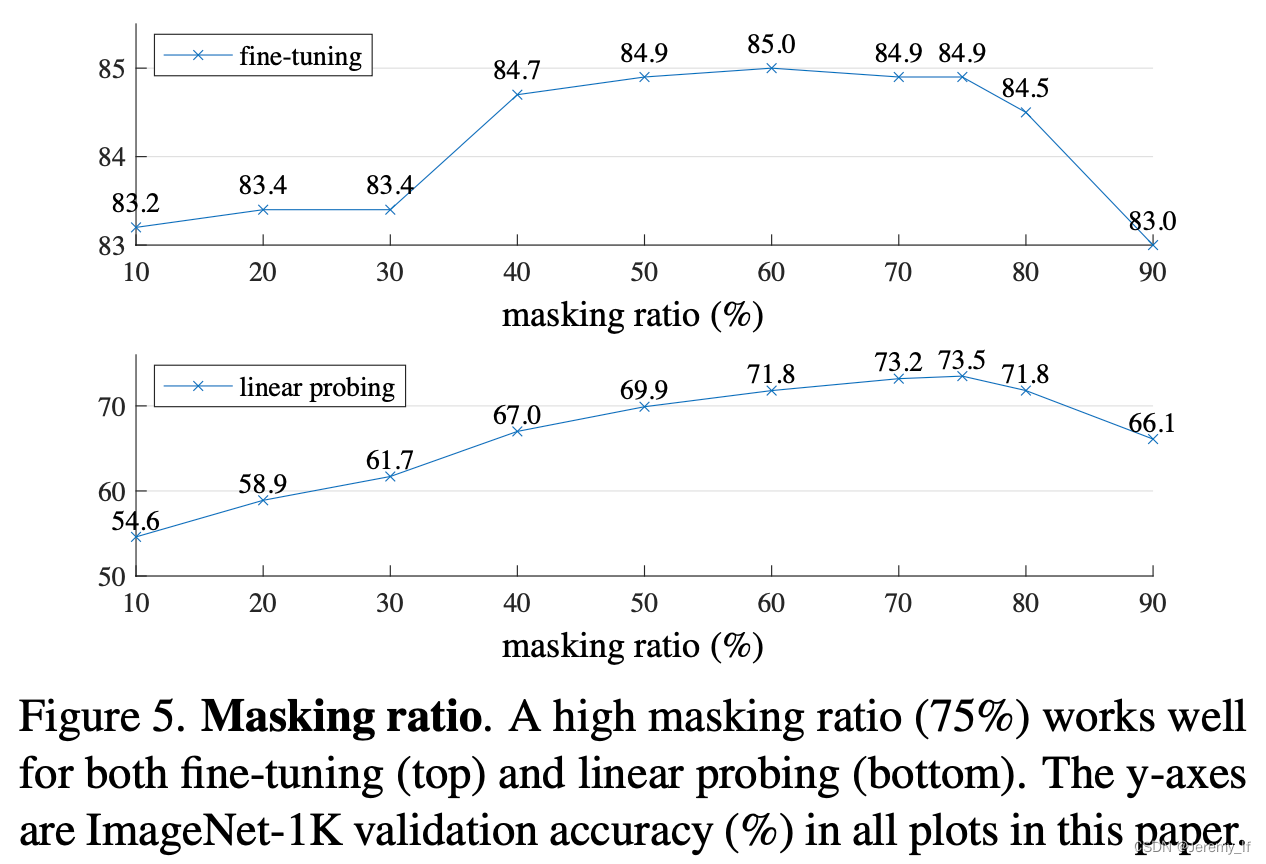
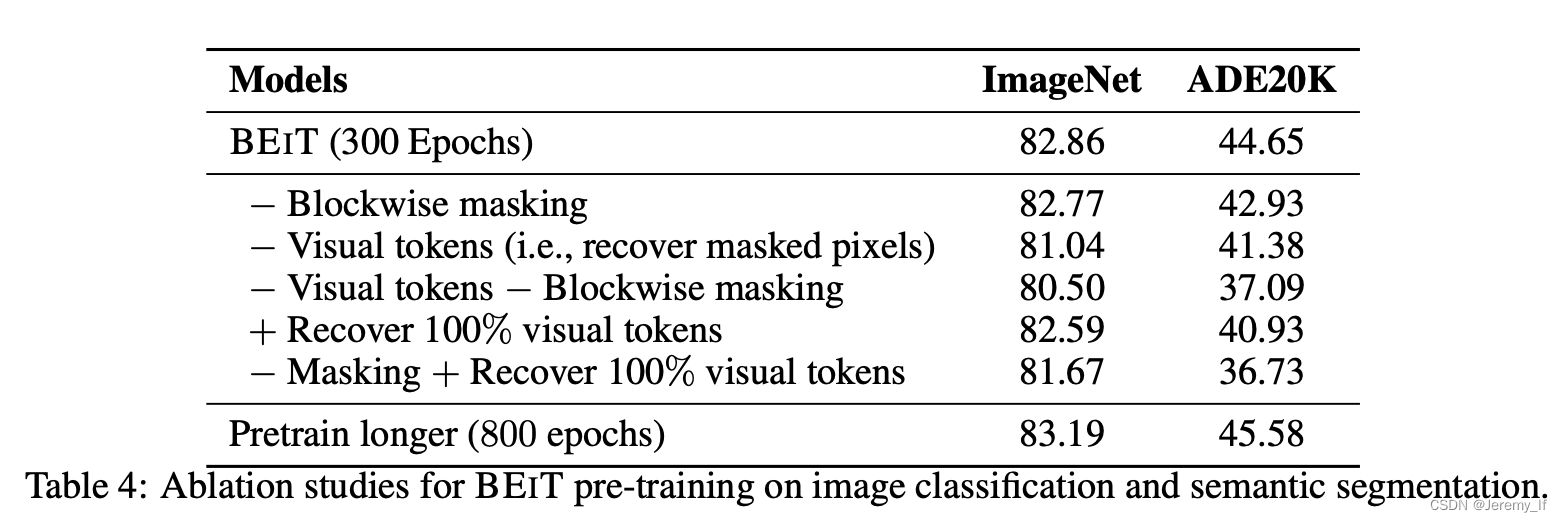
消融实验

Mask token.
我们的MAE的一个重要设计是跳过编码器中的掩码令牌[M],稍后将其应用于轻量级解码器。如果编码器使用掩码标记,其性能会更差:在linear probing中,其精度会下降14%。
Data augmentation.
我们的MAE使用only-crop增强效果良好,无论是固定大小还是随机大小(均具有随机水平翻转)。添加颜色抖动会降低结果,因此我们不会在其他实验中使用它。
没有证据表明对比学习可以在没有增强的情况下工作:图像的两个视图是相同的,并且可以很容易解决。

代码实现
MAE-Pytorch核心思想随机生成一个NXL的nosie,然后对齐进行排序选取其中百分之75%的patch个数,同时维护一个ids_restore用于在decoder重新排序patch。
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
# --------------------------------------------------------
# References:
# timm: https://github.com/rwightman/pytorch-image-models/tree/master/timm
# DeiT: https://github.com/facebookresearch/deit
# --------------------------------------------------------
from functools import partial
import torch
import torch.nn as nn
from timm.models.vision_transformer import PatchEmbed, Block
from util.pos_embed import get_2d_sincos_pos_embed
class MaskedAutoencoderViT(nn.Module):
""" Masked Autoencoder with VisionTransformer backbone
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3,
embed_dim=1024, depth=24, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4., norm_layer=nn.LayerNorm, norm_pix_loss=False):
super().__init__()
# --------------------------------------------------------------------------
# MAE encoder specifics
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim), requires_grad=False) # fixed sin-cos embedding
self.blocks = nn.ModuleList([
Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
# --------------------------------------------------------------------------
# ------------------------------------------------------- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1500
1500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









