









2018
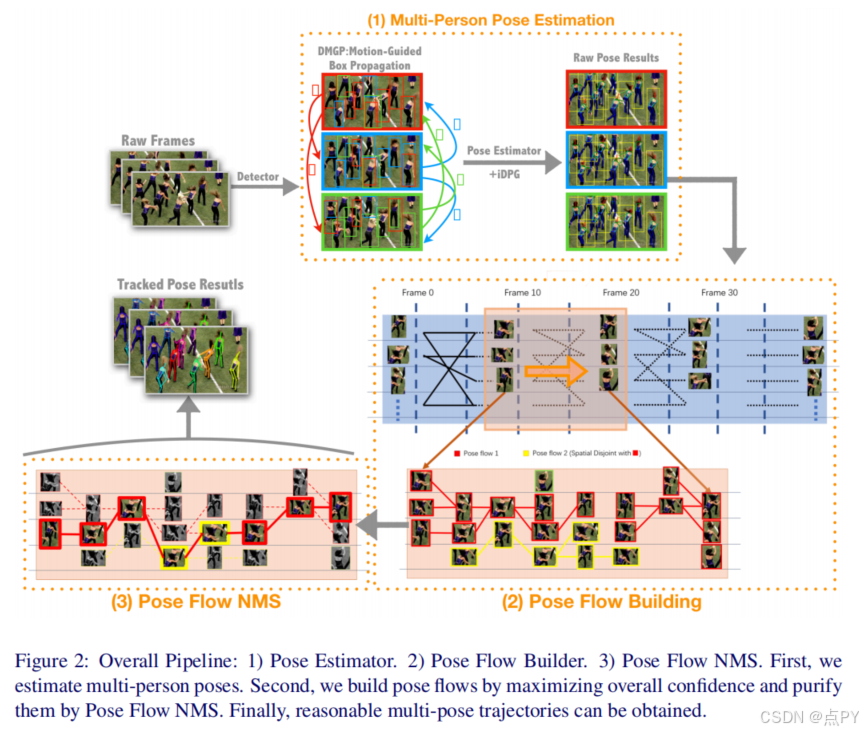
Pose Flow: Efficient Online Pose Tracking(BMVC)
code: https://paperswithcode.com/paper/pose-flow-efficient-online-pose-tracking
摘要: 在无约束视频中,多人关节姿态跟踪是一个重要而具有挑战性的问题。在本文中,我们沿着自上而下的方法,提出了一种基于姿态流的体面而高效的姿态跟踪器。首先,我们设计了一个在线优化框架来建立跨框架姿态和形式姿态流的关联(PF-Builder)。其次,设计了一种新的位姿流非最大抑制方法(PF-NMS),以稳健地减少冗余位姿流,并重新连接时间不相交的位姿流。大量的实验表明,我们的方法在两个标准姿态跟踪数据集([12]和[8])上分别显著优于13 mAP 25和6 mAP 3 MOTA的最佳报告结果。此外,在处理单个帧中检测到的姿态的情况下,姿态跟踪器的额外计算非常小,保证了10FPS的在线跟踪。
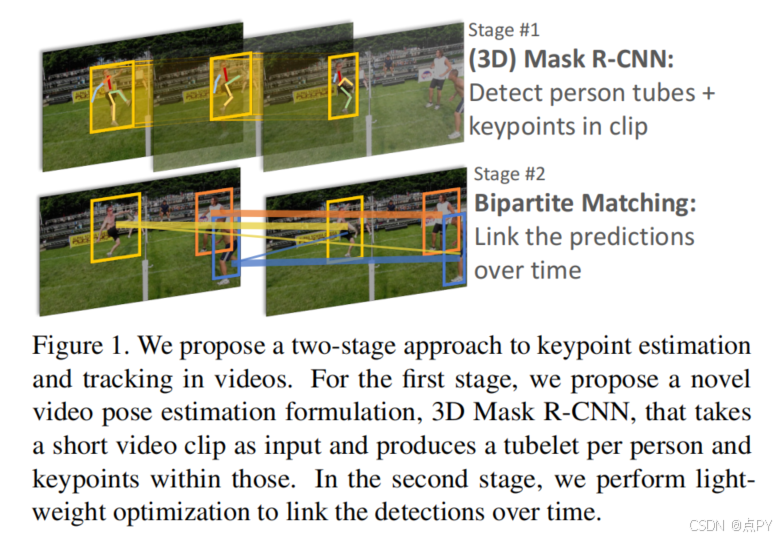
Detect-and-Track: Efficient Pose Estimation in Videos(CVPR)
code: https://github.com/facebookresearch/DetectAndTrack
摘要: 本文研究了复杂、多人视频中人体关键点的估计和跟踪问题。我们提出了一种非常轻量级但又非常高效的方法,它建立在人类检测[17]和视频理解[5]的最新进展之上。我们的方法分两个阶段:在帧或短片中进行关键点估计,然后轻量级跟踪生成整个视频的关键点预测。对于帧级姿态估计,我们使用Mask R-CNN进行了实验,以及我们自己提出的该模型的3D扩展,它利用小剪辑上的时间信息来生成更稳健的帧预测。我们在最新发布的多人视频姿态估计基准,PoseTrack上进行了广泛的烧蚀实验,以验证我们的模型的各种设计选择。我们的方法使用多目标跟踪精度(MOTA)度量,在验证上达到了55.2%的精度,在测试集上达到了51.8%的精度,并在ICCV 2017 PoseTrack关键点跟踪挑战上取得了最先进的性能。
Simple Baselines for Human Pose Estimation and Tracking(ECCV)
code: https://paperswithcode.com/paper/simple-baselines-for-human-pose-estimation
code2: https://github.com/simochen/flowtrack.pytorch
摘要: 近年来,在姿态估计方面取得了显著进展,对姿态跟踪的兴趣越来越大。同时,整体算法和系统复杂度也增加,使算法的分析和比较更加困难。这项工作提供了简单和有效的基线方法。它们有助于激励和评估该领域的新想法。在具有挑战性的基准上取得了最先进的结果。
2019
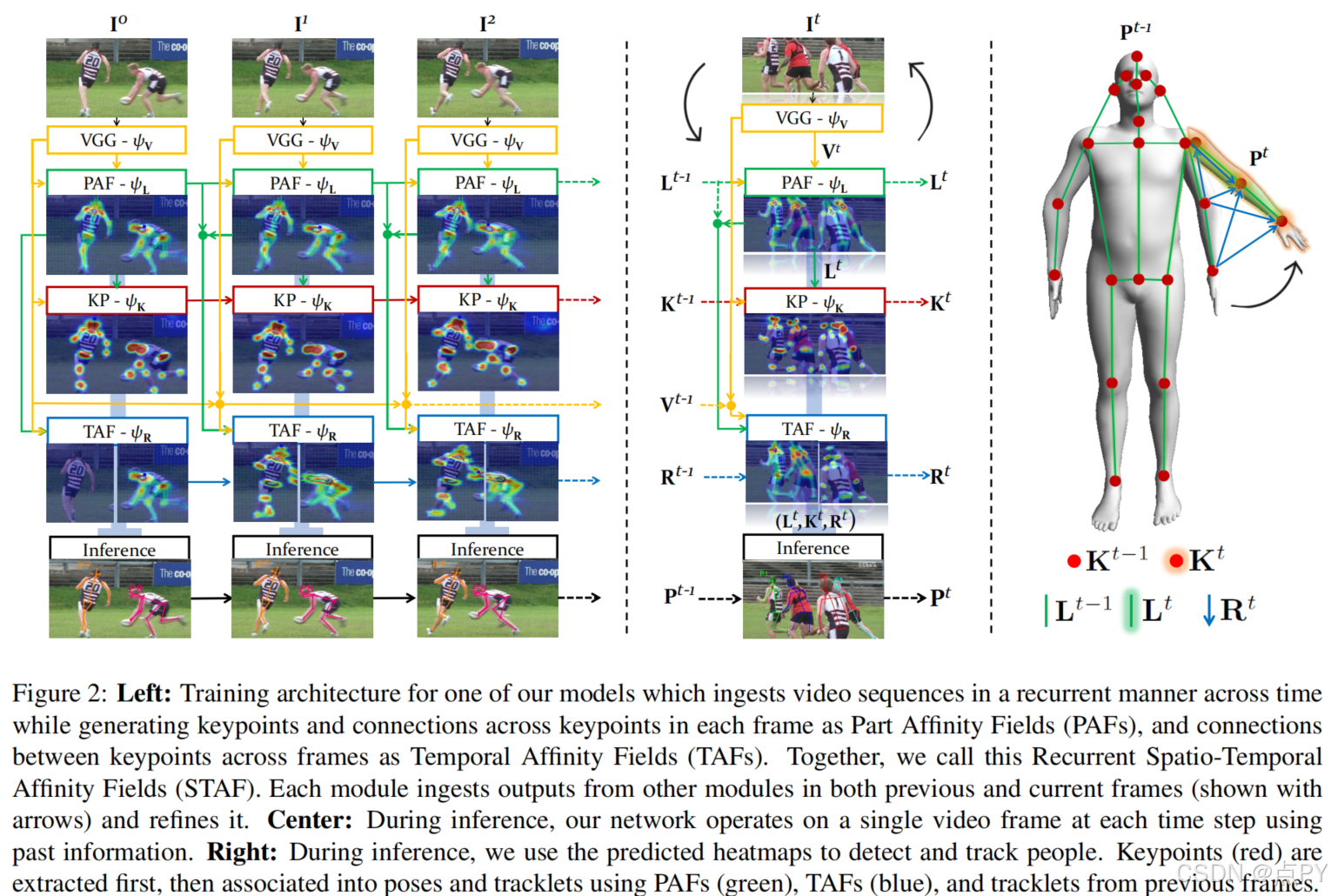
Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields (CVPR)
摘要:我们提出了一种在线方法,有效地同时检测和跟踪视频序列中多个人的二维姿态。我们建立了为静态图像设计的部分亲和场(PAF)表示,并提出了一种可以编码和预测时空亲和场(STAF)的架构。特别地,我们提出了一种新的时间拓扑交联跨四肢,它可以一致地处理大范围的身体运动。此外,我们使总体方法在本质上循环,其中网络从以前的帧摄取STAF热图,并估计当前帧。我们的方法只使用在线推理和跟踪,是目前最快和最准确的自下而向上的方法,运行时不变的人数,精度对相机输入帧率不变。
2020
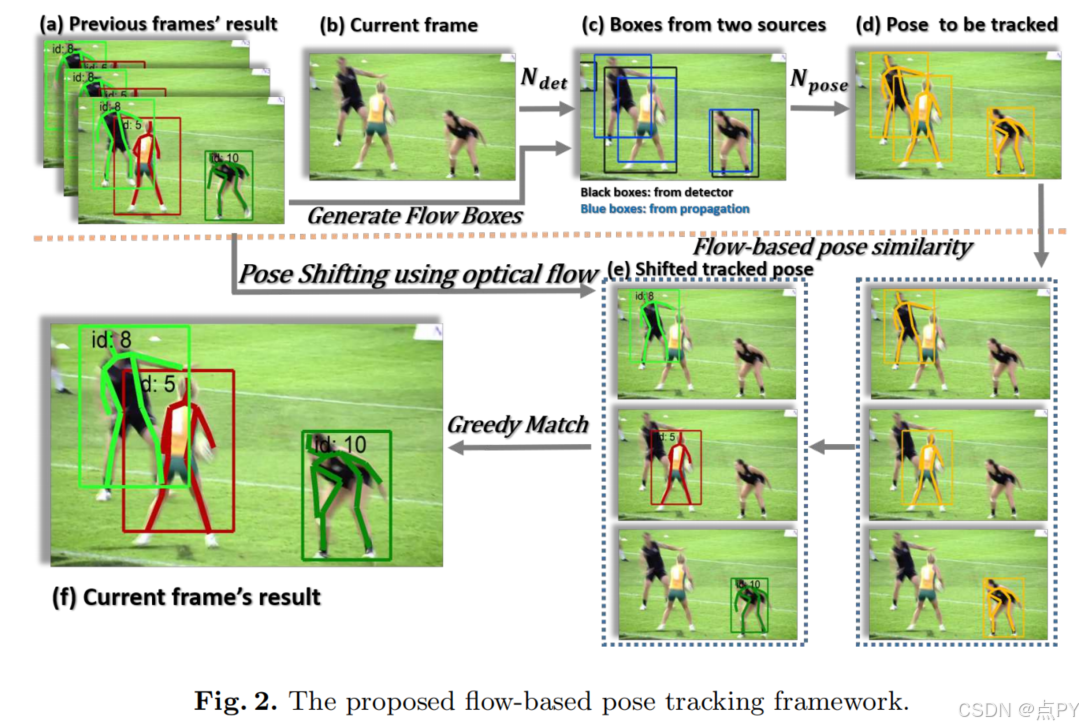
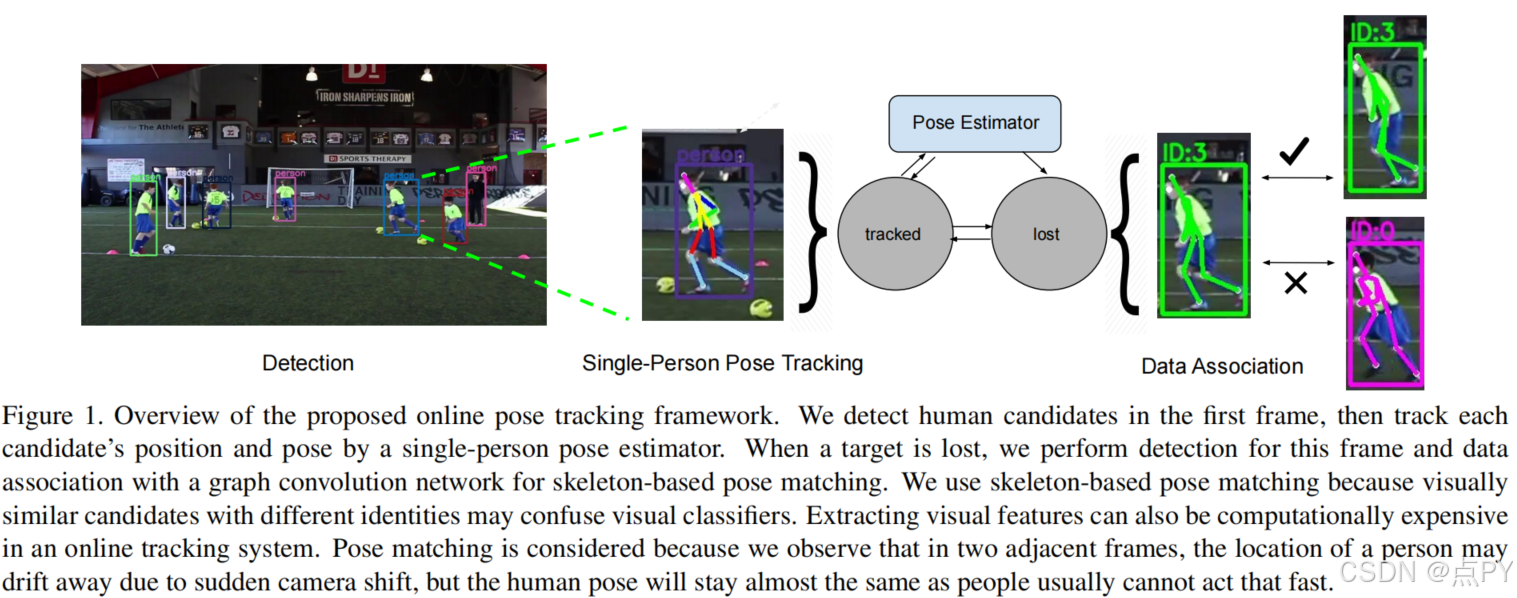
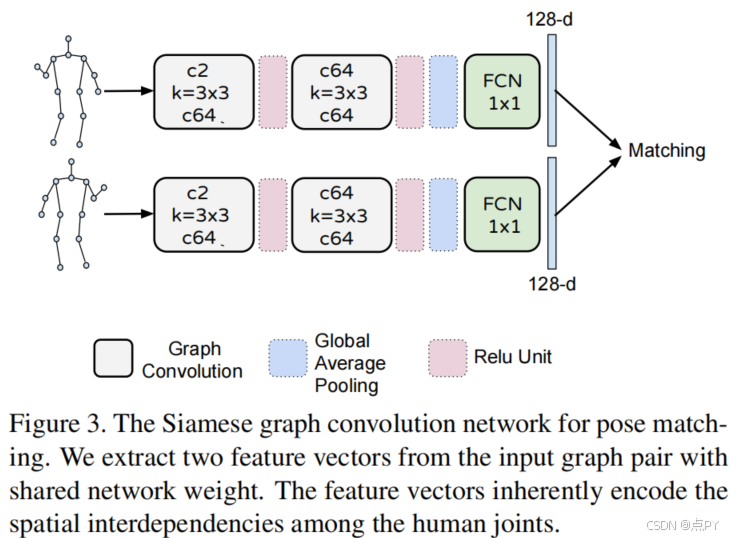
LightTrack: A Generic Framework for Online Top-Down Human Pose Tracking(CVPR)
code: https://paperswithcode.com/paper/lighttrack-a-generic-framework-for-online-top
摘要: 在本文中,我们提出了一个简单而有效的框架,称为光跟踪,用于在线人体姿态跟踪。现有的方法通常在顺序阶段进行人工检测、姿态估计和跟踪,其中姿态跟踪视为离线二部匹配问题。我们提出的框架被设计为通用的、高效的和真正的在线的方法。为了提高效率,单人姿态跟踪(SPT)和视觉对象跟踪(VOT)被合并为一个统一的在线功能实体,很容易由一个可替换的单人姿态估计器实现。为了降低离线优化成本,该框架还将SPT与在线身份关联联系起来,并首次阐明了多人关键点跟踪与多目标对象跟踪(MOT)的桥梁。具体地说,我们提出了一个用于人体姿态匹配的暹罗图卷积网络(SGCN)作为一个Re-ID模块。与其他Re-ID模块相反,我们使用人类关节的图形表示来进行匹配。基于骨架的表示法有效地捕获了人体姿态的相似性,而且计算成本低廉。它对引入人类漂移的相机突然变化是鲁棒的。所提出的框架足够通用,可以拟合其他姿态估计器和候选匹配机制。大量的实验表明,我们的方法优于其他在线方法,并且在保持更高的帧率的同时,与离线最先进的方法具有很高的竞争力。
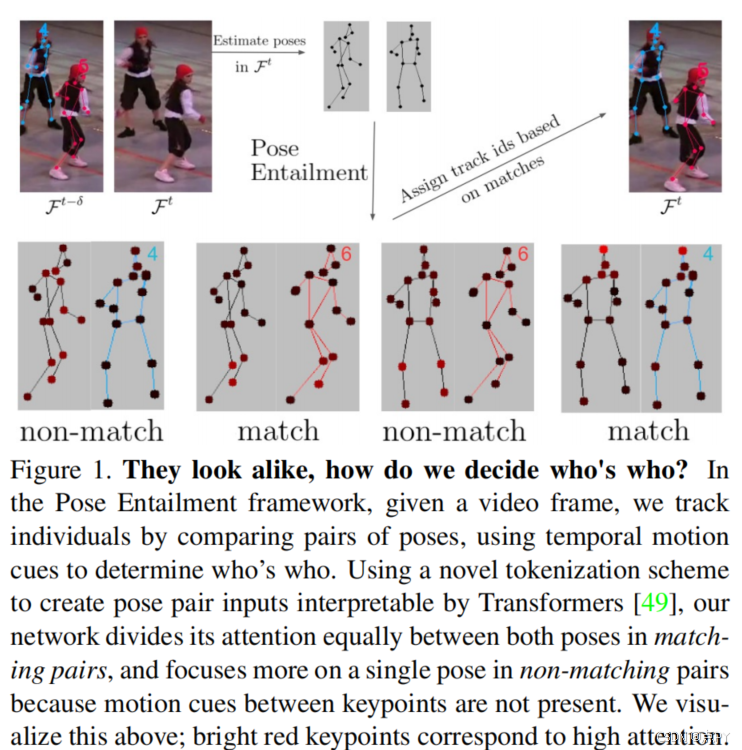
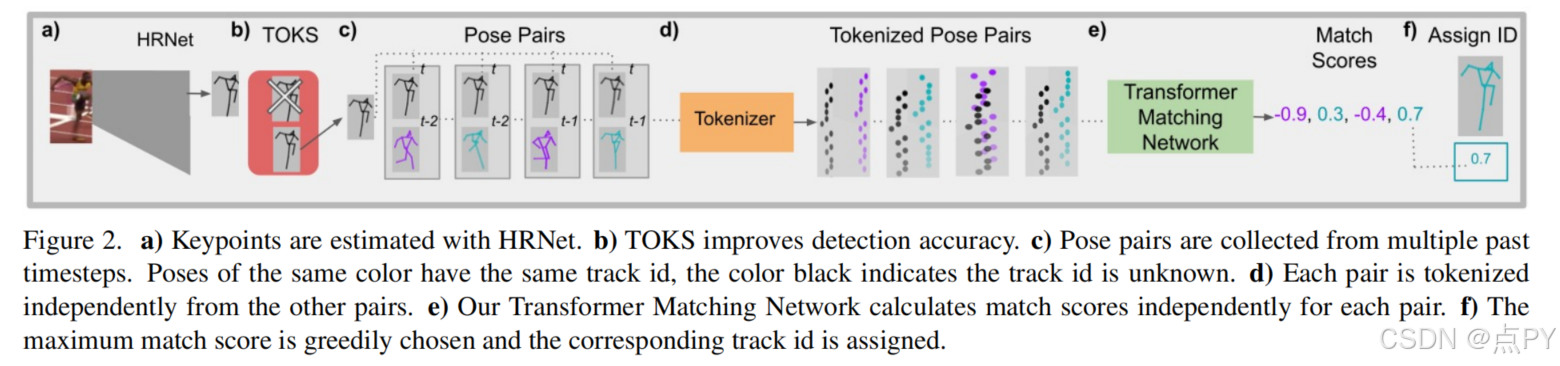
15 Keypoints Is All You Need (CVPR)
摘要: 姿态跟踪是一个重要的问题,它需要识别独特的人体姿态实例,并在视频的不同帧的时间上匹配它们。然而,现有的姿态跟踪方法无法准确地建模时间关系,需要大量的计算,通常是离线计算轨迹。我们提出了一种有效的多人姿态跟踪方法KeyTrack,它只依赖于关键点信息,而不使用任何RGB或光流信息来实时跟踪人体关键点。关键点跟踪使用我们的姿态隐含方法,其中,首先,从视频中的不同帧中采样一对姿态估计并进行标记化。然后,一个基于transformer的网络对一个姿态是否在时间上跟随另一个姿态进行二元分类。此外,我们用一种新的、无参数的关键点改进技术改进了我们的自上而下的姿态估计方法,它改进了在姿态细化步骤中使用的关键点估计。我们在PoseTrack‘17和PoseTrack’18基准测试上获得了最先进的结果,同时只使用了大多数其他方法计算跟踪信息所需的计算量的一小部分。
Combining detection and tracking for human pose estimation in videos(CVPR)
摘要: 我们提出了一种新的自上而下的方法来解决视频中的多人人体姿态估计和跟踪问题。与现有的自上而下的方法相比,我们的方法不受其人检测器性能的限制,并且可以预测非本地化的人实例的姿态。它通过在时间上向前和向后传播已知的人的位置,并在这些区域中搜索姿势来实现这种能力。我们的方法由三个部分组成: (i)一个剪辑跟踪网络,同时对小视频剪辑进行身体关节检测和跟踪;(ii)视频跟踪管道,将剪辑跟踪网络产生的固定长度轨道合并到任意长度的轨迹;以及(iii)一个基于空间和时间平滑项细化关节位置的时空合并程序。由于我们的剪辑跟踪网络和我们的合并程序的精度,我们的方法可以产生非常准确的联合预测,并可以解决常见的错误,比如严重纠缠的人。我们的方法在2017年PoseTrack2018和2018数据集上,以及所有自上向下和自底向下的方法,在联合检测和跟踪方面取得了最先进的结果。

2021
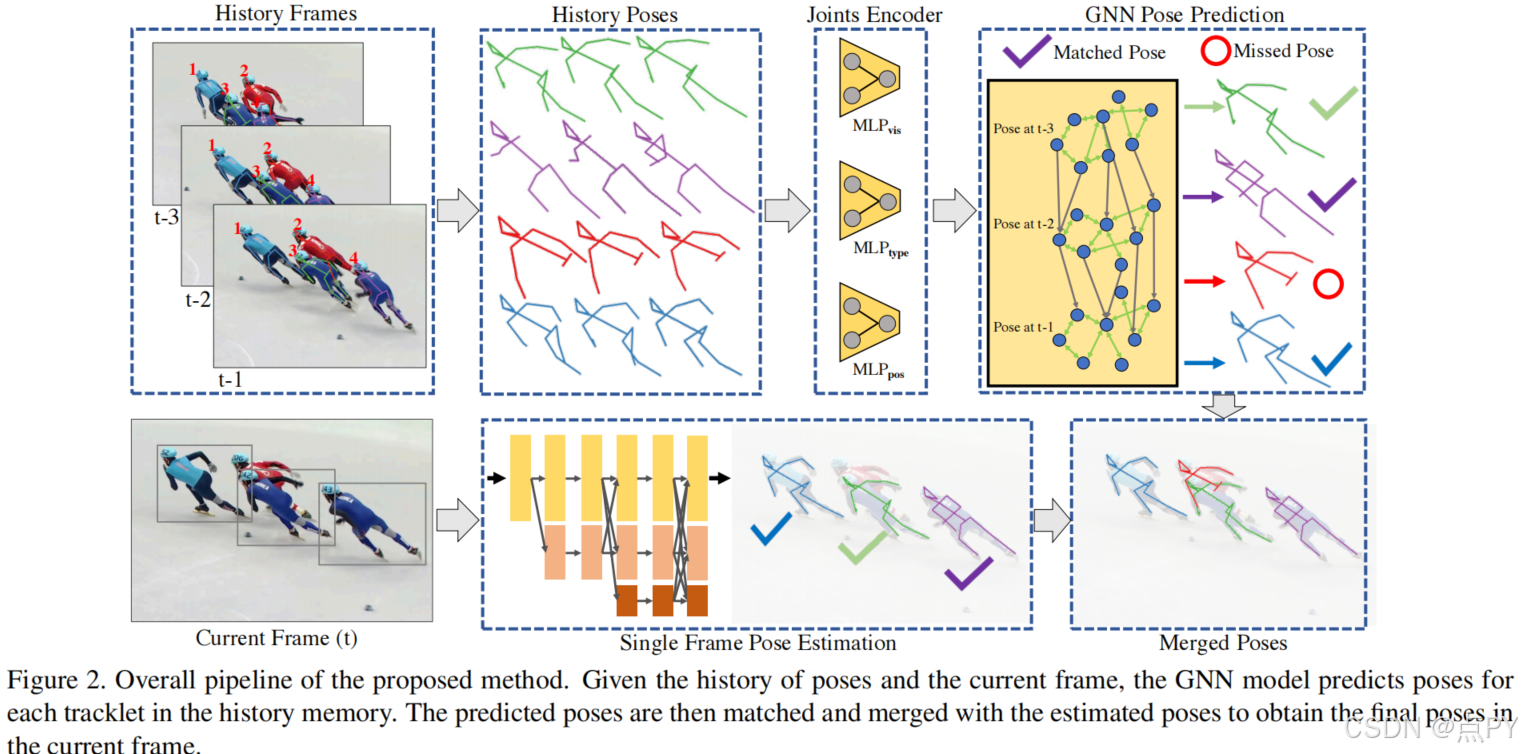
Learning Dynamics via Graph Neural Networks for Human Pose Estimation and Tracking(CVPR)
摘要: 多人姿态估计和跟踪是视频理解的关键步骤。大多数最先进的方法依赖于首先估计每一帧中的姿态,然后才实现数据关联和细化。尽管取得了很有希望的结果,但这种策略不可避免地容易错过检测,特别是在杂乱的场景中,因为这种检测跟踪范式本质上主要依赖于在遮挡情况下缺失的视觉证据。在本文中,我们提出了一种新的在线方法来学习姿态动态,它独立于当前的姿态检测,因此可以作为一个稳健的估计,即使在具有挑战性的场景,包括遮挡。具体来说,我们通过一个图神经网络(GNN)来得出这种动态预测,该网络明确地解释了时空和视觉信息。它将历史姿态轨迹作为输入,并直接预测每个轨迹在下一帧中相应的姿态。然后,预测的姿态将与检测到的姿态聚合,如果有的话,以产生最终的姿态,有可能恢复被估计器遗漏的遮挡关节。在PoseTrack 2017和PoseTrack 2018数据集上的实验表明,该方法在人体姿态估计和跟踪任务方面都优于目前的水平。
2022
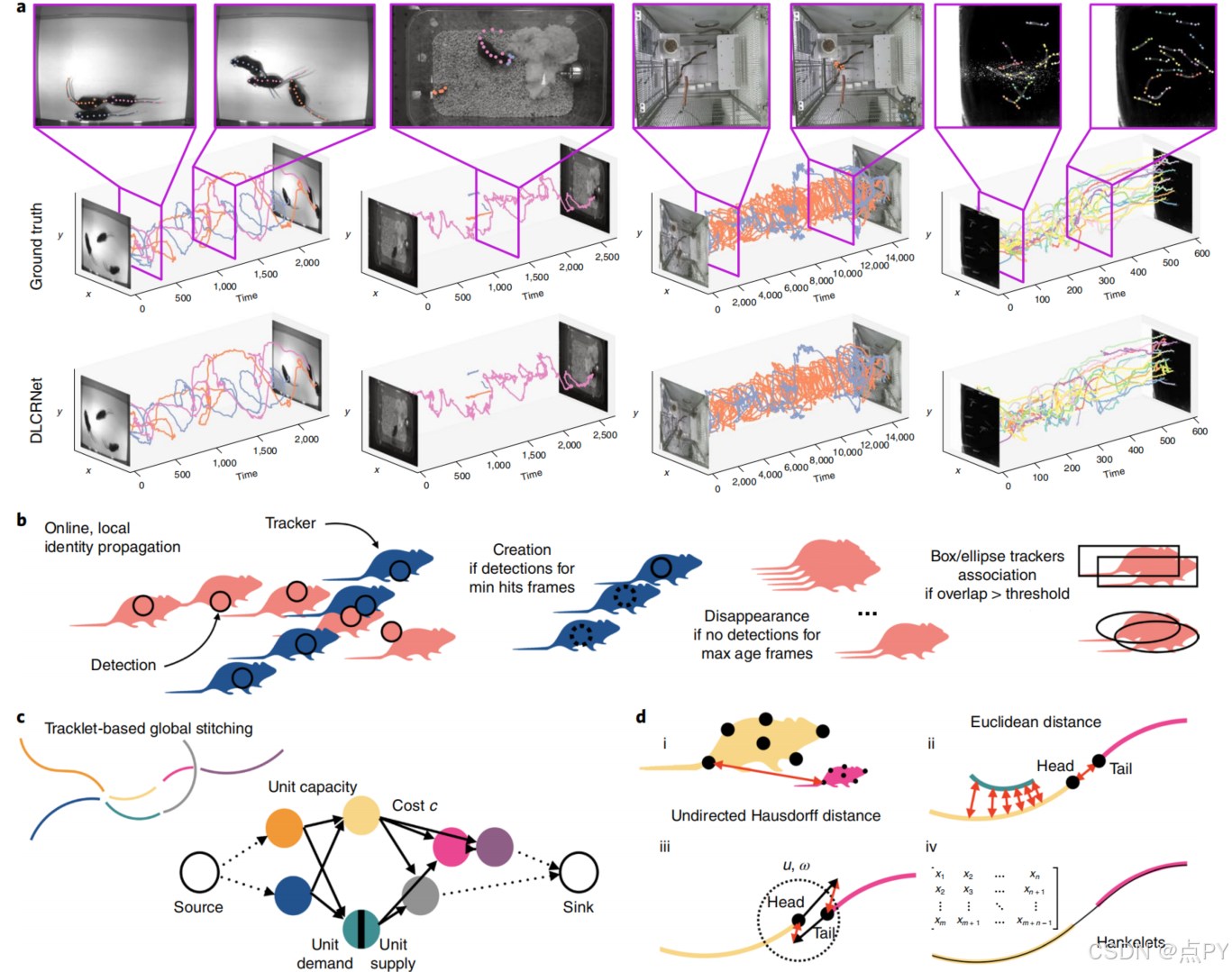
Multi-animal pose estimation, identification and tracking with DeepLabCut(Nature)
code: https://github.com/DeepLabCut/DeepLabCut
摘要: 估计多种动物的姿势是一个具有挑战性的计算机视觉问题:频繁的互动会导致遮挡,并使检测到的关键点与正确个体的关联复杂化,以及拥有高度相似的动物,这些互动比典型的多人类场景更接近。为了应对这一挑战,我们构建了DeepLabCut,并提供了多动物场景所需的高性能动物组装和跟踪特性。此外,我们整合了预测动物身份的能力,以协助跟踪(在遮挡的情况下)。我们用四个复杂性不同的数据集来说明这个框架的威力,我们发布这些数据集作为未来算法开发的基准。
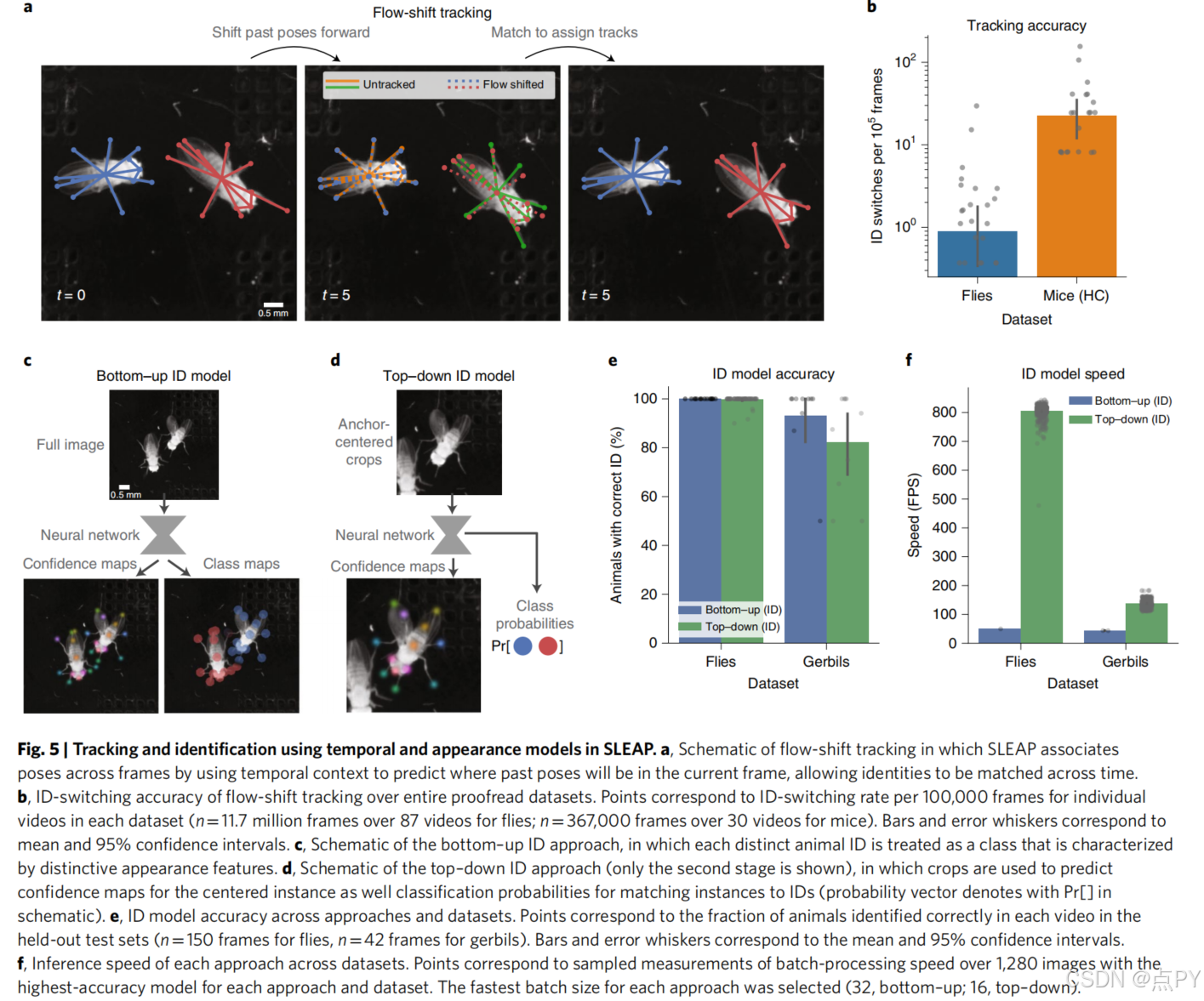
SLEAP: A deep learning system for multi-animal pose tracking(Nature)
code: https://github.com/talmolab/sleap
摘要: 对理解大脑如何产生和形成行为模式的渴望,推动了量化自然动物行为的工具的快速方法创新。虽然深度学习和计算机视觉的进步使个体动物的无标记姿态估计成为可能,但将其扩展到多种动物,对其自然环境中的社会行为或动物的研究提出了独特的挑战。在这里,我们提出了社会跳跃估计动物姿态(SLEAP),一个用于多动物姿态跟踪的机器学习系统。该系统为数据标记、模型训练和对以前未看到的数据进行推理提供了通用的工作流。SLEAP具有一个可访问的图形用户界面,一个标准化的数据模型,一个可重复的配置系统,超过30个模型架构,两种部分分组方法和两种身份跟踪方法。我们将SLEAP应用于横跨果蝇、蜜蜂、小鼠和沙鼠的7个数据集,以系统地评估每种方法和架构,并将其与其他现有的方法进行了比较。SLEAP实现了更高的精度和速度,超过每秒800帧,在全1024×1024的图像分辨率下,延迟小于3.5 ms。这使得SLEAP可以用于实时应用程序,我们通过在跟踪和检测与另一种动物的社会互动的基础上控制一种动物的行为来证明这一点。
2024
Multi-Person Pose Tracking With Sparse Key-Point Flow Estimation and Hierarchical Graph Distance Minimization (TIP)
摘要: 在本文中,我们提出了一个新的框架的多人姿态估计和跟踪具有挑战性的场景。鉴于遮挡和运动模糊阻碍了姿态跟踪的性能,我们提出将人体建模为图,并通过集中于人体中提供不完整骨骼信息的可见部分来进行姿态估计和跟踪。具体来说,所提出的框架包括三个部分: (i)稀疏关键点流估计模块(SKFEM)和层次图距离最小化模块(HGMM),分别用于估计像素级和人级运动;(ii)结合像素级外观一致性和人级结构一致性来测量身体关节的可见性得分。在假设可见和不可见部分在人类部分图中具有固有关联的情况下,分数指导姿态估计器通过观察高可见性部分来预测完整的骨骼。对姿态估计器进行迭代微调以实现这一能力;(iii)结合多个历史帧来有利于跟踪,并使用HGMM实现。该方法不仅在PoseTrack数据集上取得了最先进的性能,而且还有助于显著改进其他任务,如与人类相关的异常检测。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











