






摘要:提出两个实现模型,(Π-model)一个是一个样本计算两次,计算两次结果的loss; (Temporal Ensembling)另一个是一个样本计算一次,与之前历史结果作差异计算得到loss。然后把这个无标注数据计算出来的结果信息与监督数据计算出来的结果一并组成最后的Loss。
本文的两种半监督方法的性能非常恐怖,谷歌街景门牌号识别只需要500个有标签数据(不到1%),就能实现10%以下的错误率,相比监督方法好得多。当使用更多有标签数据时,两种半监督方法的错误率可以进一步降低。
两个方法比较来说,temporal ensembing的效果会更好一些。
作者:
Laine, Samuli, and Timo Aila
年份: ICLR 2017
Github: https://github.com/smlaine2/tempens
2. Self-Ensembling During Training
提出了两种集成训练方法,分别为Π-model (双模型)和Temporal Ensembling(时序组合模型)
2.1 Π-model
1) structure

2)伪代码

3)核心点
- 对每一个参与训练的样本,在训练阶段,进行两次前向运算。此处的前向运算,包含一次随机增强变换和一次模型的前向运算。由于增强变换是随机的,同时模型采用了 Dropout,这两个因素都会造成两次前向运算结果的不同,如图中所示的两个 zi。
- 损失函数由两部分构成,第一项由交叉熵构成,仅用来评估有标签数据的误差。第二项由两次前向运算结果的均方误差(MSE)构成,用来评估全部的数据(既包括有标签数据,也包括无标签数据)。另外,由于模型最开始时是很不准确的,所以产生的z可能没有多大意义,所以需要先对有label的数据进行训练,也就是需要把两次不同的z比较的loss进行屏蔽。作者这里设置了一个随时间变化的变量w(t),在t=0时,设置w(t)为0,也是z比较的loss权重为0,然后w(t)随着时间增大而增大。
2.2 Temporal Ensembling
1)structure

2)伪代码

3)核心点
- 时序ensembling模型相对于П-model,它也是计算两个预测结果,可是不同的是,П-model是经过在一个epoch中两次计算,这里则是当前的zi与历史的zi来计算,由于一次迭代期间内,只用产生一次z,那么相比于双模型,它就有了两倍的加速。
- 作者在论文中说,他们使用的以前的z,并不是恰恰上次迭代的z,而是历史z的加权和,公式如下
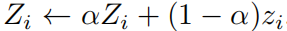
这样做的好处是能够保留历史信息,衰减长远历史信息和稳定当前值。 - 这样处理与优化,就像早以空间来换取时间,在每epoch的计算时就少向前计算了一次;另外,这个可以平滑历史而产生预测性的结果,避免单次计算的噪音。
3、Result


研究人员分别在 CIFAR-10 和 SVHN 数据集上进行了实验。从图中可以看出,对于 CIFAR-10 数据集上,在仅有 10% 的样本下(左边一列),相对于纯监督或者 GAN 的模型,文章所提出的两个算法模型提升了 23~6个百分点不等。即使在完整数据集下,此论文所提出的方法也比纯监督的方法更优,额外提升 0.5 个百分点。这说明本文所采用的一致性正则项完全可以充当通用的正则项,用来约束模型对于输入的局部噪声不敏感。















 1127
1127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









