










原理介绍
一图胜千言:
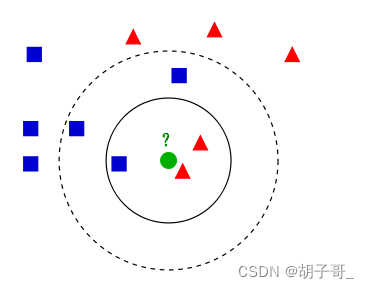
基本原理
- 首先,KNN算法是监督算法(即每个训练数据是有一个标签的)。
- KNN算法很简单,一句话,新的点(比如上图的绿色点)的周围哪种类型的点多就把它归到哪一类。如上图,绿色是待归类点。以绿色点为中心,对于内部的实心圆内,有两个红色三角形和一个蓝色正方形,所以判定绿色属于红色三角形一类。而如果以外围的虚线圆为判定条件,则蓝色正方形占多数,则判定绿色点属于蓝色正方形一类。
- K值是什么?即用来判定时选择周围多少个点作为判定条件。比如上图中如果选择K=3,则为实心圆所示,如果选择K=5,则为虚线圆所示。
(这里大家注意区分于KMeans, KMeans的k值是聚类的数量,而KNN是周围的点的数量)
大家很容易发现,其实按照新的点周围画圆而不是数点的方式也可以达到归类目的,也确实有相关的算法:sklearn.RadiusNeighborsClassifier,有兴趣可以看看。
K的选取
- 如果k选择的太小,比如k=1,则表示新点会被划分到离它最近的点为一类,很容易想像,如果数据中存在一些噪声点,则很容易误判。(模型更复杂,过拟合)
- 如果k选择的太大,比如K=N,则新的点永远属于样本中占多数的点。(模型太简单,欠拟合)
- 那K怎么选取呢?其实没有太好的办法,通过反复进行交叉实验选择最好的K值。
特征归一化
什么是归一化?为什么要归一化?
直接举例,比如有3个点计算到0点的距离(假设两个维度:x,y),A点=(1000,1),B点=(100,2), C点=(2100,3). 则有距离为:
A距离=
100
0
2
+
1
2
\sqrt{1000^2+1^2}
10002+12
B距离=
100
0
2
+
2
2
\sqrt{1000^2+2^2}
10002+22
C距离=
200
0
2
+
3
2
\sqrt{2000^2+3^2}
20002+32
我们发现,x值对结果影响太大,导致y维度容易被忽略,为了保证两个维度重要性相同,则需要进行归一化。
如何归一化?
举例:拿某一维度的所有值的和为分母,原值为分子。比如以上三个点归一化为:
x维度的和=
2000
+
1000
+
1000
=
4000
2000+1000+1000=4000
2000+1000+1000=4000
y维度的和=
1
+
2
+
3
=
6
1+2+3=6
1+2+3=6
A
=
(
1000
/
4000
,
1
/
6
)
=
(
0.25
,
0.167
)
A=(1000/4000,1/6)=(0.25,0.167)
A=(1000/4000,1/6)=(0.25,0.167)
B
=
(
1000
/
4000
,
2
/
6
)
=
(
0.25
,
0.333
)
B=(1000/4000,2/6)=(0.25,0.333)
B=(1000/4000,2/6)=(0.25,0.333)
C
=
(
2000
/
4000
,
3
/
6
)
=
(
0.5
,
0.5
)
C=(2000/4000,3/6)=(0.5,0.5)
C=(2000/4000,3/6)=(0.5,0.5)
实践
数据集
https://www.kaggle.com/datasets/mukeshmanral/knn-dataset
加载数据
import numpy as np
import pandas as pd
data = pd.read_csv('/kaggle/input/knn-dataset/knn-data/1.ushape.csv')
data.head()
可视化数据,观察规律
y = data.iloc[:,2]
X = data.iloc[:,0:1]
from matplotlib import pyplot as plt
plt.scatter(data.iloc[:,[0]][y == 1],data.iloc[:,[1]][y == 1])
plt.scatter(data.iloc[:,[0]][y == 0],data.iloc[:,[1]][y == 0])
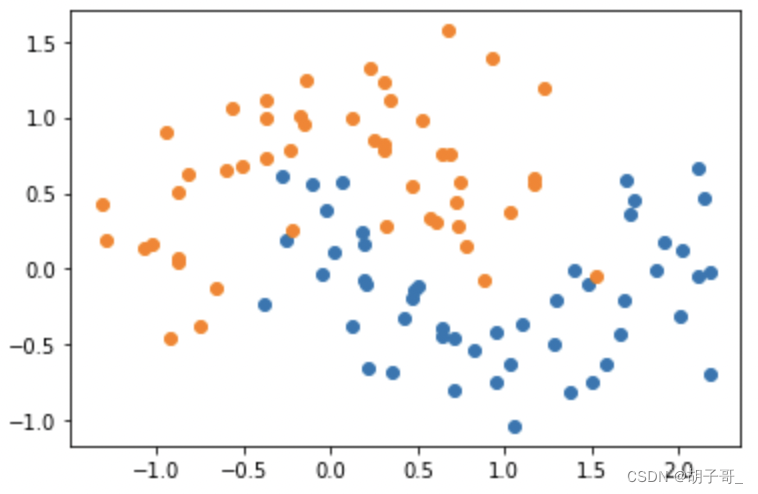
训练数据
from sklearn.neighbors import KNeighborsClassifier
# n_neighbors参数默认为5
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X, y)
预测 + 评估
y_predict = KNN.predict(X)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y, y_predict)
print(accuracy)
输出:0.8888888888888888
(通过尝试k=1-7),当k=1时候,accuracy=1(显然为1,因为找到的都是自己),不合理,然后尝试了其他k,发现k=3时最好,所以选择3.















 9106
9106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









