






前言
本文是对Java常见面试知识点的个人理解与总结,以下是目录结构
Java面试知识点总结
Java篇
Java原理部
为什么Java可跨平台?为什么Java是解释与编译并存的语言?
这两个问题是可以同时解答的,关键词:先编译(.java–>.class)后解释(.class–>机器码)。先编译保证了解释器面临的都是统一规则的字节码,后解释保证了Java的可跨平台性(针对不同操作系统的特定映射)。
在解释部分,有两种提速策略:JIT和AOT,分别是即时编译以及提前编译,都是将.class–>机器码的映射存储起来避免重新解释。AOT无法解决动态代理任务,因为动态代理是在运行时从内存中生成并加载修改后的.class,AOT无法作用
Oracle JDK和Open JDK的区别?
Oracle JDK更稳定更有保障,但11及之后版本商用收费
Open JDK更新更快Bug更多,但完全开源
Java与C++的区别?
Java无指针(无法对内存地址加加减减)
Java类是单继承,只有接口可多重继承
Java有GC,可自动释放内存
Java只支持方法重载
浮点数的存储结构,表示范围,精度,为什么会有精度损失?
以32位float为例,浮点数的存储结构为首位符号位,2至9位指数位(+127,表示范围-127~128),10至32位尾数位,尾数由整数部和小数部组成,小数部采用乘二取整,由高向低,最后结果遵循科学计数法,首位必1。最大值为 1.11... × 2 128 ≈ 2 129 1.11...\times2^{128}\approx2^{129} 1.11...×2128≈2129,范围可确定为正负该值。精度以二进制表示为0.0(共22位)1。精读损失来源于乘二取整的无穷尽
java内存区与对应的存储内容
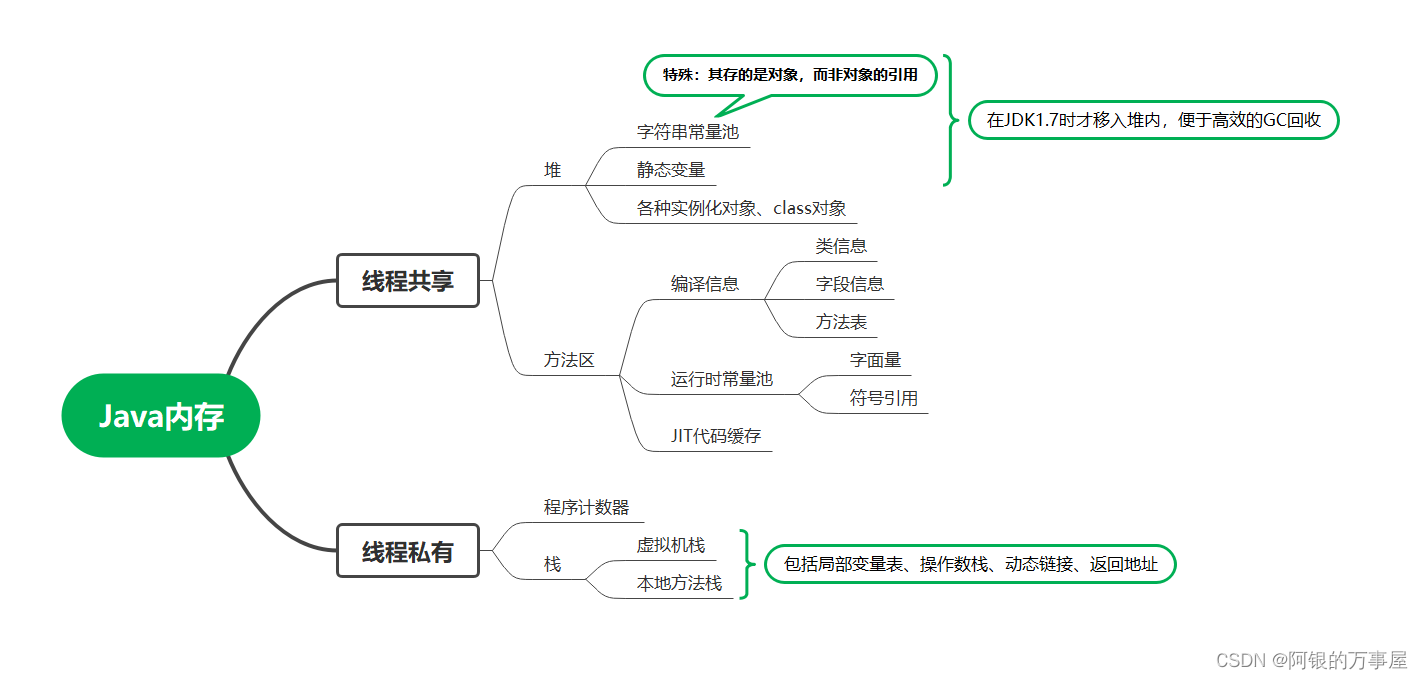
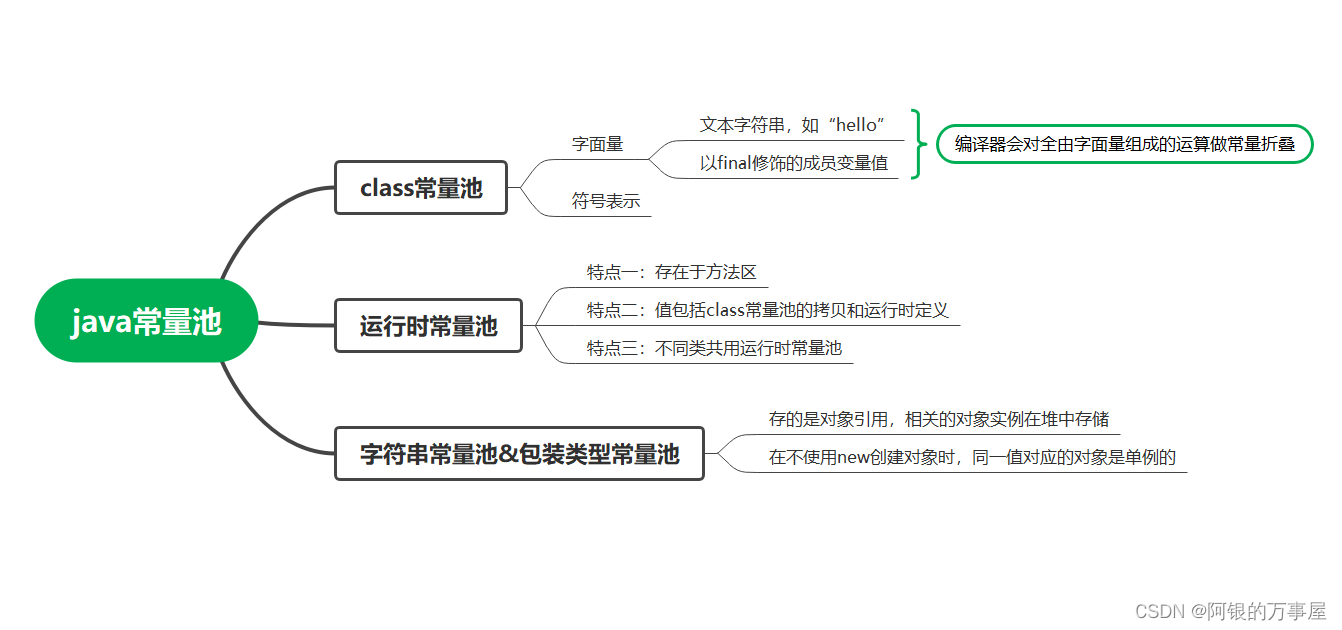
java常量池:四大类、各自包含的内容,加载的时机
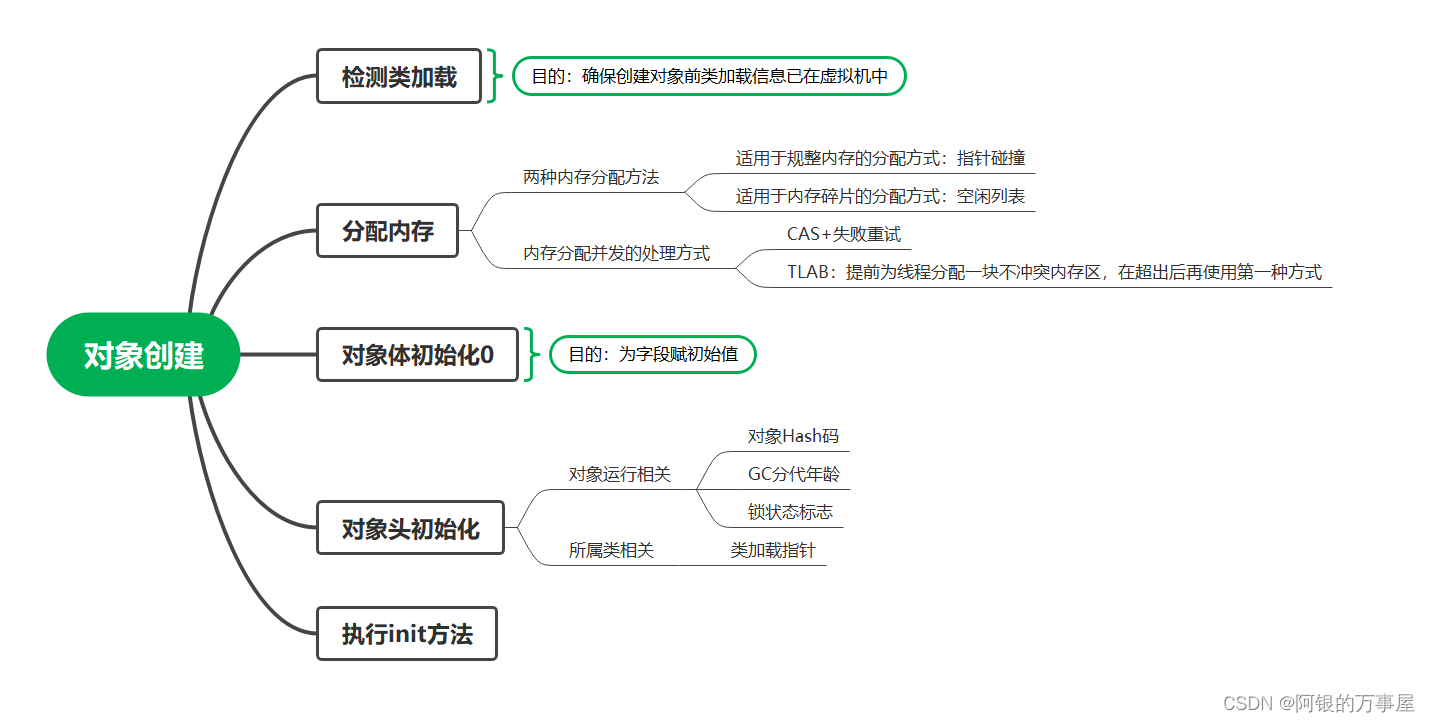
HotSpot创建对象的步骤?
Java IO五种模型(有的也总结为三种模型,分别是阻塞,非阻塞以及异步,但这里我们还是选取了五种这一分类)
详情请移步我的另一篇博客,其中有详细解读
Java的JDK代理模式和CGLIB代理模式的异同?
两者基本原理上相同,实现细节不同
基本原理相同,是指JDK代理模式与CGLIB都是由两部分组成:Part I - 方法拦截器,用于增强拦截下的原方法;Part II - proxy工厂,用于产生动态代理对象(解析原有方法,在proxy中根据方法拦截器重写/实现方法)
实现细节不同,是指JDK代理采用接口实现,其proxy工厂中的对象是对接口的实现;GCLIB代理采用子类继承,其proxy工厂中的对象是对父类的重写
Java内存模型,工作内存与主内存的刷新时机?
Java内存模型遵守以下几点:1. 变量均存在主内存的堆中;2. 线程开辟工作内存,用以拷贝主内存的变量,修改操作均在工作内存上进行;3. 不同线程的工作内存不共享,只能通过主内存进行沟通
刷新时机:工作内存的写修改将同步至主内存,但同步时机不确定(除非使用锁或是内存屏障:使用锁后,在锁释放前,工作内存中的变量一定会刷新回主内存;使用内存屏障后,写屏障前的写操作一定会在写屏障后的写操作执行前执行
工作内存重新同步主内存内容的时机包括但不限于以下几类:1. 线程获取锁时,强制从主内存同步数据;2. 同一内核切换至当前线程时,强制从主内存同步数据
Java中的类
Java的Unsafe类内存屏障的作用机理
loadFence(): 读屏障,保证读取代码前后顺序性以及可见性,可见性的作用机理是清空当前线程的工作空间,并重新对主内存的变量做拷贝,由此保证了读屏障后的代码读取到的是更新后的变量值
storeFence(): 写屏障,保证写入代码前后顺序性以及可见性,可见性的作用机理是强制同步当前线程的工作空间至主内存的变量,由此保证了写屏障后的代码面对的是已经更新的主内存
这里面的一个关键点是,由于Java的线程工作空间从主内存同步数据的时机至少包括以下两类:1. 线程获取锁时,强制从主内存同步数据;2. 同一内核切换至当前线程时,强制从主内存同步数据。因此写屏障后的代码不一定就能获取到更新的主内存,还必须确保线程强制同步主内存数据
Java中的并发
一句话讲明什么是JMM内存模型
JMM内存模型是Java为保证在不同平台执行同一套并发程序可以获得相同结果的规则定义。它可以看做是两部分,一部分是对线程与主内存关系的规定,另一部分是对由Java源码转换到可执行指令中要遵守的相关并发规定(即提供给开发者遵守的强内存模型happens-before)
乐观锁可能存在的问题,解决手段?
问题1: ABA,即无法保证当前相等的匹配一定是之前读取的值;
解决手段: 增加版本号标志,并保证整个CAS操作的原子性(Java类:AtomicStampedReference)
问题2: 长时间自旋带来的CPU浪费
解决手段: pause指令,一是延迟自旋,从而降低CPU占用;而是减少因内存顺序冲突而需要重排序的指令数,从而提升效率
问题3: CAS命令仅支持单共享变量
解决手段: 扩充CAS操作,使多个共享变量组成一个对象的属性,并保证该对象属性的修改满足CAS的原子性(Java类:AtomicReference)
AQS怎么实现的公平锁和非公平锁?
应明确,AQS实现的非公平仅仅只是部分的,已在阻塞队列中的线程节点的激活将是绝对公平的。部分非公平在于线程加入阻塞队列前:
当线程首次调用acquire方法时,会使用CAS操作判断是否可获取锁,获取成功直接返回
当失败后,内部会继续调用tryAcquire方法,此时公平锁会优先判断阻塞队列是否非空,并在非空的情况下直接加入队尾;而非公平锁则会优先尝试再获取一次锁,获取成功返回,失败则加入阻塞队列
Atomic原子类实现机理?
set时通过直接修改主内存中原变量的偏移地址对应值,从而保证写入的原子性(这也是CAS中的S操作的原理);通过volatile强制其他线程的读取操作,保证可见性
为什么TreadLocalMap中key要被设置为弱引用,value被设置为强引用?
我们知道key对应的是ThreadLocal对象,value对应的是初始化ThreadLocal对象时(或set时)给定的值。key被回收的条件是线程中不再有对ThreadLocal对象的强引用;而value被回收的条件是key被回收。在声明一个ThreadLocal对象时,其会在当前线程留下一个强引用,然后ThreadLocalMap中的key也需要一个引用,若这个引用为强引用,则在当前线程的引用失效后,该ThreadLocal对象仍不会被回收,因此ThreadLocalMap中的key必须为弱引用。此外,如果value被设置为弱引用,则其有可能在key失效前就已被垃圾回收
Runable和Callable的区别与联系?
两者都是作为线程的构造函数传入,用于定义线程待执行的任务(Runable类是重写run方法,Callable类是重写call方法);不同在于,Runable类的 run方法无返回值,Callable类的call方法有返回值
ThreadLocal的探测式清理做了什么?
ThreadLocal的探测式清理从index=i(传参)位置开始,向后查找key=null的entry并置entry.value=null,若遇key!=null的entry,则根据其hash值执行线性探测法重新确定插入位置(因为途中会出现本轮清理出的entry位置),优化查找效率。上述过程重复直至遇到entry=null
ThreadLocal扩容机制?
在执行ThreadLocal.set()的最后,会启动一次启发式清理,从当前插入节点位置向后遍历,遇key=null则在该位置启动一次探测式清理,否则直到扫描n>>>=1!=0次后退出。退出后,若size>=threshold启动rehash():首先在index=0处执行探测式清理(即全局扫描),结束后判断size>=0.75*threshold,若是则最终执行扩容
计算机原理篇
计算机网络
TCP的传输可靠性保证精简总结
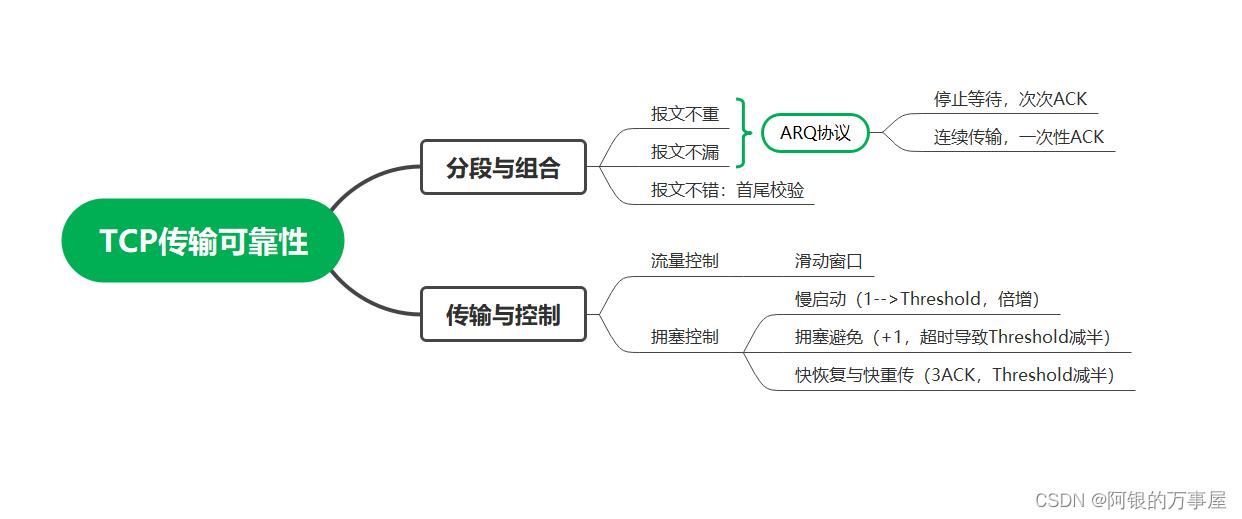
什么是TCP粘包/拆包?
由于网络传输与IO读写速度的差异,因此大部分时候需要设置缓冲区来缓存TCP数据包。但问题在于TCP数据包在传输层面仅仅表现为一串二进制流,因此有可能出现多个包的二进制流连在一起存于缓冲区,即粘包;或是一个包的二进制流被拆成多份传到缓冲区,即拆包。
危害:如果发送者在发送时如果并未对数据包首尾作出限制,那么接收者读取到的TCP包就是紊乱的。
解决:从定义数据包的边界着手,可以限制每包长度为固定值;或者通过结束符区分不同包;亦或者通过在包头定义消息长度
Linux操作系统
文件的权限数字表示什么意思,如764?
在Linux中,文件被三方“牵挂”,分别是用户、用户所在组、其他组,各自对应XXX中的一位。而文件操作共三类方法,分别是读(4或r)、写(2或w)、执行(1或x),X=7即X=4+2+1,即用户具备读写执行三种权利
数据库
关系型数据库
关系型数据库设计三范式?
一范式:消除码的可拆分
二范式:消除非主属性对主键的部分依赖(通过拆分部分依赖成新表)
三范式:消除非主属性对码的传递依赖 (拆除传递关系成新表)
数据库的脏读、不可重复读和幻读分别发生在什么情况下?
脏读:发生在读取未提交字段时
不可重复读:发生在并发事务时,读取其他事务提交的当前元祖修改 (解决方式:记录锁或MVCC)
幻读:发生在并发事务时,读取其他事务提交的元祖增加 (解决方式:临键锁)
InnoDB是如何实现RR隔离+拒绝幻读的?
- 对于普通select,InnoDB采用MVCC(多版本控制下的一致性非锁定读),为每一次事务分配一份
read view,该事务只能读取满足read view限制的元祖版本,如果当前数据库记录不满足,则从undo log中查询并读取满足版本的记录。该过程满足可重复读的同时,也不会产生幻读- 对于执行 select…for update/lock in share mode、insert、update、delete 等当前读,即每次均要读取最新值,此时需要通过行锁+间隙锁,前者解决不可重复读,后者解决幻读
InnoDB的next-key-lock加锁范围?
在RR隔离下,默认使用临键锁进行行锁操作且锁定范围为包括本行及之后插入位的范围;但对于唯一索引或主键的临键锁会自动退化成记录锁,因为不加间隙锁也不会导致上述情况的幻读(每行均是唯一的)
InnoDB三大日志各自的工作节点?
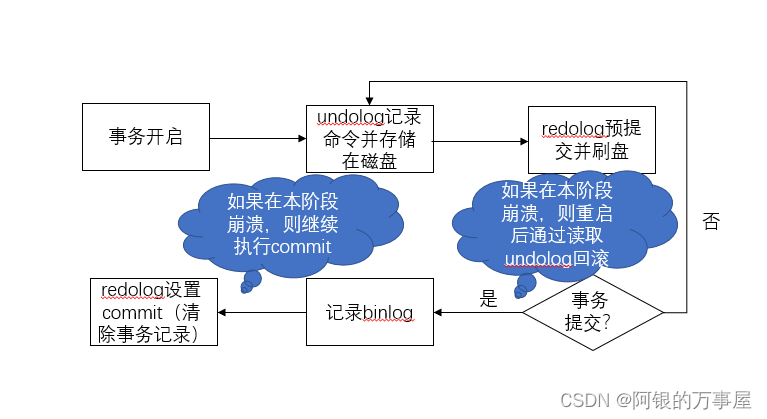
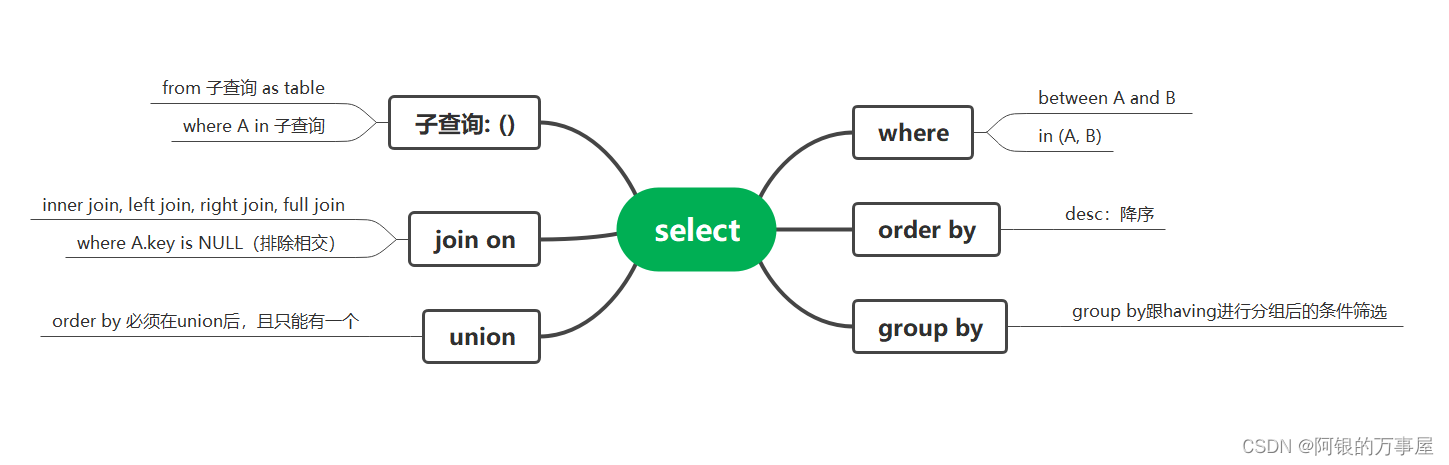
SQL查询语法一图流
非关系型数据库
Redis的AOF文件重写机制?
AOF重写主要是压缩原AOF文件的大小,将文件中无效的命令去除。比如:同一个key的值,只保留最后一次写入;已删除或者已过期数据相关命令会被去除
由于该检测过程需要时间,因此redis一般是fork出一个子进程进行AOF文件的重写的。为了避免重写过程与主进程的数据不一致问题,会维护一个重写缓冲区,重写过程的任意修改都将记录在缓冲区并在重写完成后追加在AOF文件末尾
常用框架
Spring框架
Spring的@Component和@Bean的区别?
@Component:将当前类创建为bean后注入Spring的loc容器
@Bean:将当前方法返回对象作为bean注入Spring的loc容器
SpringMVC的统一异常处理?
通过@ControllerAdvice为所有被@Controller注解的类添加AOP,通过@ExceptionHandler注解为发生异常的连接点添加通知
SpringBoot
SpringBoot自动配置的是怎么实现的?
自动配置主要来源于@EnableAutoConfiguration,自动配置分为两步:通过@import扫描spring.factories下的所有待配置类的全限名;对满足@condition的待配置类,生成对应bean并注入容器
SpringBoot常用的注解?
注入bean类型:@controller等;HTTP访问类型:@GetMapping;前端传参解析类型:@RequestBody,@RequestParam和@Pathvariable分别为问号传参与路径传参
Mybatis
Mybatis的Dao接口怎么成为Spring中可运行的Bean?
一、转换XML:将所有XML按照namespce分类,每个namespace下按照id生成MappedStatement对象
二、代理Dao接口:为Dao接口中的每个方法实现拦截与代理,对该方法的调用将被转移到实例化的MappedStatement对象上,同时代理对象也作为Bean注入容器















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









