







前言
测试用例的设计能力,是一名测试工程师的基本功,在我看来它比听起来高大上的自动化测试、性能测试、安全测试等等重要得多。测试用例的设计能力会直接影响到你测试的质量,如果对这方面不重视,可能会漏测许多Bug。
什么是测试用例
测试用例,可以理解为把要测试的点,转化成可量化、可执行、清晰易懂的文档,至少包含测试前提、测试过程、预期结果几个方面。那么测试用例的意义在哪里?测试工程师为什么要去写测试用例?我接到需求后直接对着文档测试不好吗?
针对刚才的几个问题,我是这样看待的:
1、测试用例能够帮你管控整个测试进度,通过测试用例的执行率,可以判断当前项目的进度大概是多少,是否有延期的风险,从而提前做出应对
2、测试用例是给你自己看的,虽然需要花很多时间精力去编写,但是编写完后可以直接对照着它进行测试,减少漏测的情况。如果你不写用例直接上手开始测试,东测一遍,西测一遍,可能自己也会测昏头。(当然这里不排除有天才级别选手就是能够不写用例也能做好需求,但是这种情况是极少数)
3、在编写测试用例的过程中,其实也是在熟悉需求的过程。通过编写测试用例,能够提前熟悉需求的目的、逻辑,以及判断需求是否存在不合理的地方
4、测试用例是测试用例评审的前提,如果没有用例,就没法评审了,整个项目流程也会缺掉一环,对软件质量是个很大的风险。当然,如果你接到的需求只是很小的改动,比如说就只是在原有的列表中加了一列字段,那么这种情况确实也可以不写用例,自己分析一下里面的逻辑以及可能涉及到系统哪些模块即可。
测试用例设计
设计思路
先说句有用的废话,一份好的测试用例,应该能够做到让其他人依照它也能进行测试。个人认为这句话确实是很有道理,但是它是没什么意义的。需不需要让其他人也能一眼看懂并且能够依照它进行测试要根据实际情况具体分析。如果你的测试用例只有你一个人用,那么你耗费太多的时间在让其他人理解用例上,反而会拖累你的效率。大多数情况下,测试用例只要你自己看懂,别人也能大概理解其中的意思就行了。即使是在用例评审环节,大家更多也是在听你的测试思路以及测试重点,对于细节的把控还是要靠你自身。
在设计用例方面,我个人的思路是这样的:把一个大的需求拆成多个小的模块,再对各个小模块考虑各方面的测试,通常有以下几个方面:功能、UI、性能、安全、兼容以及易用(一般是产品考虑这个问题)。当然,即使把需求拆成了各个小模块,依旧需要保留一条主线,这条主线的优先级是最高的,通常是主流程(最先测试的也是它,通常做冒烟测试用例)。以水杯的测试为例,出了一份简单的测试用例,可以参考下面的脑图
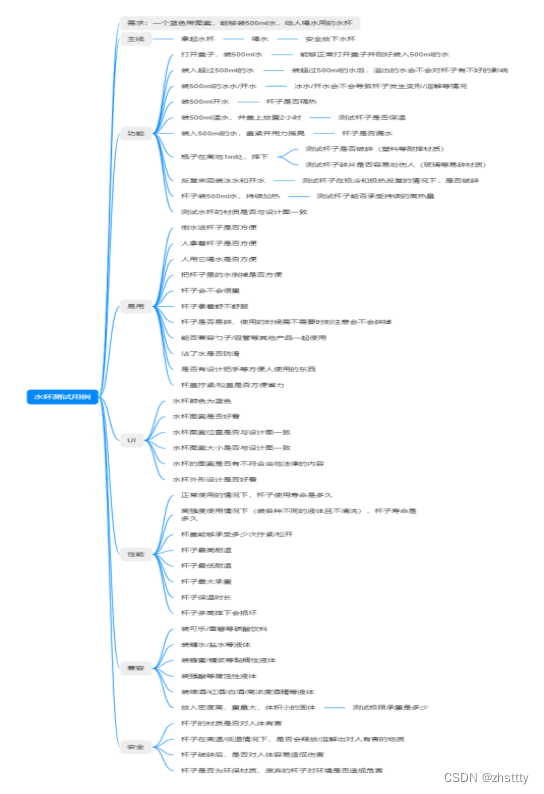
那么我们可以看出,设计测试用例时可以从这几个点入手
1、先分析需求,找到其中的主线,并围绕主线设计相关用例,这部分用例的优先级通常是比较高的
2、多考虑异常情况,你永远也不知道用户会做出什么操作
3、除了功能外,多想想其他的方面,比如UI、性能压力、安全、兼容性、易用性
4、把一个大问题分解成若干个小问题,再依次去解决。当需求内容比较多的时候,往往无从下手,这时候可以试着把大的需求拆成小的,再针对小功能进行用例设计
5、多思考这次的需求跟系统其他模块会不会有联系,改动会不会影响历史功能
还有一点,作为一名测试,要具有发散思维,试着从用户的角度去思考问题,举个例子:
如图,支付宝的app一打开你就能看到扫一扫和收付款的button,这是因为大多数的用户,打开支付宝的时候都是为了进行收款/付款,而现在中国二维码支付已经是非常普及了,所以扫一扫和收付款的button都放在了最显眼的位置。让用户一进来就能很快的找到这两个功能

而同样有在线支付的微信打开却没有直接显示首付款和扫一扫的button,个人认为这是因为微信的侧重点在于社交以及日常的衣食住行,并不像支付宝一样侧重交易。所以你会发现微信一打开时,显示的是聊天列表,因为当下社会绝大多数的在线聊天都是通过微信来完成的,聊天列表可以让你看到最新的信息。当然,上面所说的情况一般来说产品都会帮我们考虑好,但是毕竟人都会有犯错的时候,测试最好也有自己的想法
具体设计方法
等价类
等价类指的是同一个类型的数据,选择一个进行测试即可。打个比方,现在要测试银行卡的取款功能,在测试取款金额时,总不可能把所有的数字都测试一遍,先不说时间成本的问题,数字是无穷尽的,本身也测试不完。举例取款金额这个功能,从数字的层面考虑,我能想到的测试点有这些
| 1、负整数 2、小数 3、正整数 4、0 5、极大值(9999999999999999999999999999999999999999999999这种会导致溢出的值) 6、超出银行拥有金额的值 7、超出账户内金额的值 8、非100倍数的值 9、刚好等于账户内金额的值 |
可以看出,等价类实际上是把数据划分成多种类型,再从每个类型中选取一或多个进行测试的一种方法,实际的应用场景还有很多,它主要解决的是穷举测试的问题。
边界值
边界值和等价类是很像的,一般会用等价类和边界值结合起来设计用例。打个比方,上面说到的取款金额的等价类设计,其实就包含了边界值(极大金额)。只不过边界值更专注于临界的测试,等价类则是测试各种类型。
如果拿刚才的邮箱地址来说的话,邮箱长度的边界值要测试6个数字:分别是5、6、7与17、18、19。可以比较明显看出的是6与18是长度的边界,但是在测试边界时,我们一般会把边界的左右也一起测试。
场景法
一般来说,在软件系统中一个操作会触发一个事件,直到没有事件可以再触发为止。这一系列的操作可以串成一条事件流。场景法就是基于事件流的形式进行用例设计的。
举个例子,我们要去招商银行的atm取钱。正常来说我们能很顺利地完成取钱的流程:【插卡-输密码-输入金额-取钱-退卡】,但是真的每次取钱都能够这么丝滑地完成以上一系列的动作吗?让我们来分析一下整条流程
| 插卡 1、插入招商银行卡(正常事件) 2、插入招商信用卡(正常事件) 3、插入建行银行卡(异常事件) 4、插入招商银行卡,但是插反了(异常事件) 5、插入招商银行卡,没插反但是卡消磁了(异常事件) 6、插入招商银行卡,但是卡是断的(异常事件) 7、插入招商银行卡,但是银行停电了(异常事件) 8、插入学生卡/公交卡/深圳通......(异常事件) 9、插入招商银行卡,但是账号是被冻结的(异常事件) 10、多次插拔卡,导致吞卡(异常事件) 11、插入招商银行卡,但是账号由于多次输错密码,被锁定(异常事件) 12、插入招商银行卡,外部因素一切正常,但是系统出bug了(异常事件) | 输密码 1、输入正确密码(正常事件) 2、输入错误密码(异常事件) 3、多次输入错误密码(异常事件) 4、已经多次输入错误密码被锁卡(异常事件) 5、不输入密码(异常事件) 6、更改密码后,输入之前的密码(异常事件) 7、第一次输入错误密码,第二次输入正确密码(正常事件) 8、输入密码后,删除再重新输入正确密码(正常事件) | 输入金额 1、输入小于账户存款的金额(正常事件) 2、输入等于账户存款的金额(正常事件) 3、输入大于账户存款的金额(异常事件) 4、输入0(异常事件) 5、输入井号#或星号*按钮(异常事件) 6、不输入,直接点击取款(异常事件) 7、输入非100整数的金额(异常事件) 8、什么都不输入,一直挂机直到超时(异常事件) |
| 取钱 1、取款金额小于等于账户存款,取款成功(正常事件) 2、累计取款金额超过当日上限(异常事件) 3、累计取款次数超过当日上限(异常事件) | 退卡 1、取完钱,ATM正常退卡(正常事件) 2、取完钱,忘记退卡,超时后吞卡(异常事件) 3、取完钱,不退卡返回主界面重新操作(正常事件) | ATM 1、ATM一切正常,按程序运行(正常事件) 2、ATM发生吞卡等程序异常(异常事件) 3、ATM断电/断网(异常事件) 4、ATM硬件发生损坏导致无法正常使用(异常事件) 5、ATM内部没钱了(异常事件) |
可以看出,每一个流程都可能会有N种操作,只有操作属于正常事件的时候,才能继续操作下一个流程。我们继续提炼其中的内容,可以得出多条事件流,举例:
1、插入招商银行卡 - 输入正确密码 - 输入小于账户存款的金额 - 取款金额小于等于账户存款 - 取完钱,ATM正常退卡 - ATM一切正常,按程序运行(正常事件流)
2、插入招商银行卡 - 输入错误密码(异常事件流,到这里弹出提示并结束事件)
3、插入学生卡(异常事件流,开头就结束了)
可以提炼的事件流还有很多,在这里举了几个简单的例子。这种设计方法更像是把多条孤立的用例排列组合成了多条互相联系的事件流的一个过程。个人认为它能够帮助你缕清整个需求的业务链路,更好地理解需求逻辑。此外,用它给开发人员设计冒烟自测用例也是很好用的
因果图
因果图本质上是一种逻辑图,包含与/或/非等条件,具体使用哪个条件需要根据实际情况分析。举一个比较形象的例子:小明要跟女友结婚,但是丈母娘要求有车有房才同意结婚,这时候输入条件就是车和房,且它们是与的关系,输出结果为能否结婚,转换成表格就是这个样子
| 车 | 房 | 结婚 |
| 有 | 有 | 结婚 |
| 无 | 有 | 分手 |
| 有 | 无 | 分手 |
| 无 | 无 | 分手 |
再给出一个复杂一点且贴合实际的场景:邮箱注册。邮箱地址要求:6-18个字符,可以使用字母、下划线、数字,但是必须是以字母开头,这种场景你会怎么设计?
我一般的思路是把每个条件都单独拎出来,搞清楚它们之间的与/或/非关系,然后跟其他条件进行排列组合。就从邮箱地址的条件来说,字符长度是一个单独的条件,字母、下划线、数字是三个条件,但是分析后可以得出四个条件,以字母开头也是一个条件,可以列出公式
长度6-18个字符 and 包含(字符 or 下划线 or 数字) and not 包含字母、下划线、数字外的内容 and 以字母开头 = 有效邮箱,根据这条公式,可以得出以下表格
表格是假设在有一个条件不满足的情况下,其他所有条件都满足。这样可以快速的设计出基本的用例。当然这里面肯定还有很多情况没有考虑到,例如字母、下划线、数字外的内容还需要再进行分类,又比如空或者跟系统逻辑关联的内容,需要根据实际情况进行补充
| 6-18个字符 | 字母 | 下划线 | 数字 | 字母、下划线、数字外的内容 | 以字母开头 | 等价类类型 |
| 15个字符 | 包含字母 | 包含下划线 | 包含数字 | 不包含 | 以字母开头 | 有效等价类 |
| 5个字符 | 包含字母 | 包含下划线 | 包含数字 | 不包含 | 以字母开头 | 无效等价类 |
| 19个字符 | 包含字母 | 包含下划线 | 包含数字 | 不包含 | 以字母开头 | 无效等价类 |
| 15个字符 | 不包含字母 | 包含下划线 | 包含数字 | 不包含 | 以字母开头 | 有效等价类 |
| 15个字符 | 包含字母 | 不包含下划线 | 包含数字 | 不包含 | 以字母开头 | 有效等价类 |
| 15个字符 | 包含字母 | 包含下划线 | 不包含数字 | 不包含 | 以字母开头 | 有效等价类 |
| 15个字符 | 包含字母 | 包含下划线 | 包含数字 | 包含 | 以字母开头 | 无效等价类 |
| 15个字符 | 包含字母 | 包含下划线 | 包含数字 | 不包含 | 不以字母开头 | 无效等价类 |
错误推断法
听起来很厉害,其实是根据自己的测试经验来判断哪些地方可能会出现bug,比较考验测试对系统业务的熟悉程度以及测试技术。
正交实验法
百度查了资料,它是从大量的实验(测试)数据中根据正交原则 取出最优的数据的组合。 然后,根据最优数据组合 实验的结果 来分析整个测试的结果。那么怎么用呢?我也不清楚,没用过这种设计方法。只知道它用在因果法设计用例太多的场景,为了减少用例数目。用尽量少的用例覆盖输入的两两组合。
结尾
在用例设计中,设计方法起的作用并没有很大,更重要的是对业务的熟悉程度以及思维。站在不同的角度思考是很有帮助的,把自己代入用户视角,你能够更好地发现产品中对用户体验不友好的地方。站在业务视角,也能够看明白很多问题,减少无效工作。
比如,在测试不同的产品时,侧重点是不同的。像微信、QQ这种基本盘在用户的纯C端产品,需要考虑到不同用户使用的不同终端,因此这一类产品对兼容性的要求是极高的。且由于它是一款聊天型产品,因此数据安全以及性能的问题也很重要,谁也不希望自己发的信息会泄露给收信人以外的用户。
但是如果是像office、xmind这类产品,侧重点可能就更多地放在可移植性、稳定性以及兼容性上,由于这类产品基本都是单机不联网的,因此对于数据安全以及性能的问题反而没那么看重。
最后,希望这篇文章对你能够有所帮助,有不够完善的内容欢迎补充
















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









