






数据劫持
对data进行初始化时,会调用observe方法对数据实现劫持
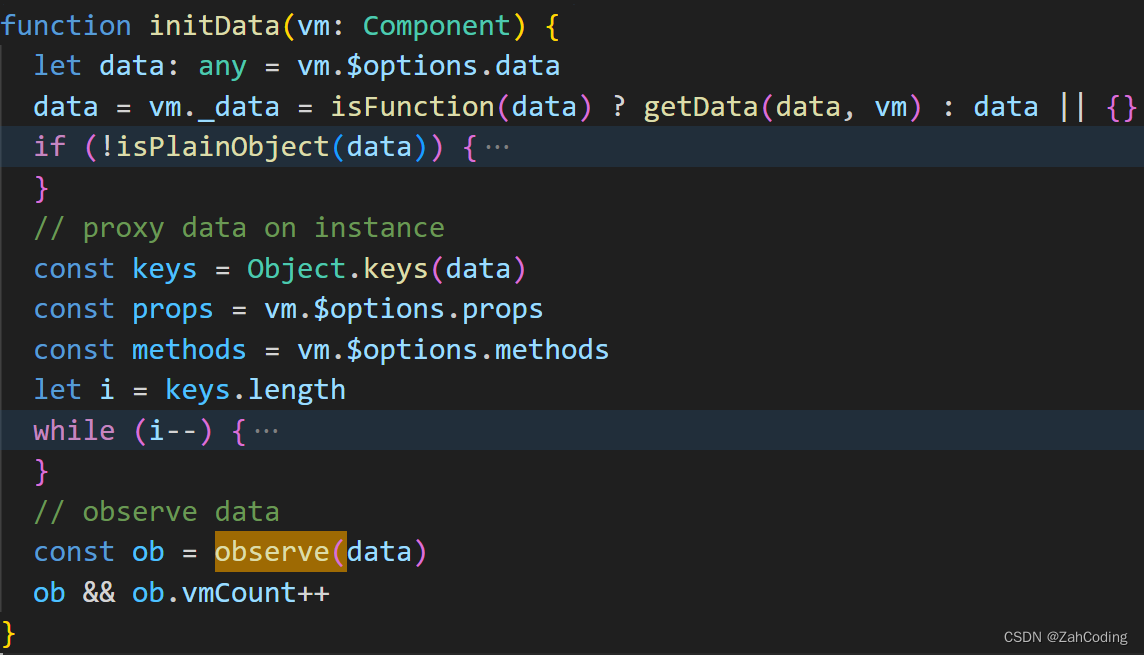
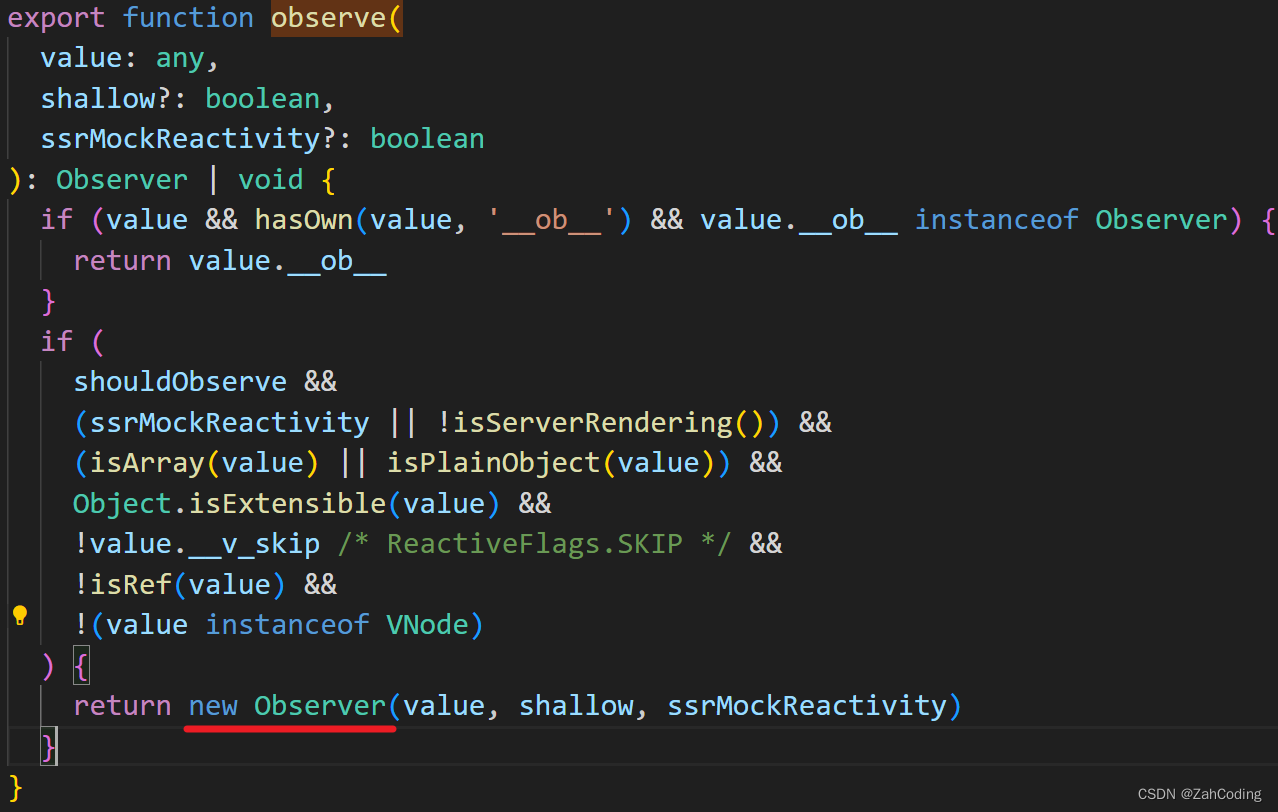
observe方法是通过维护Observer对象实现的
在Observer中,主要是对对象按key进行遍历,逐个属性进行数据拦截
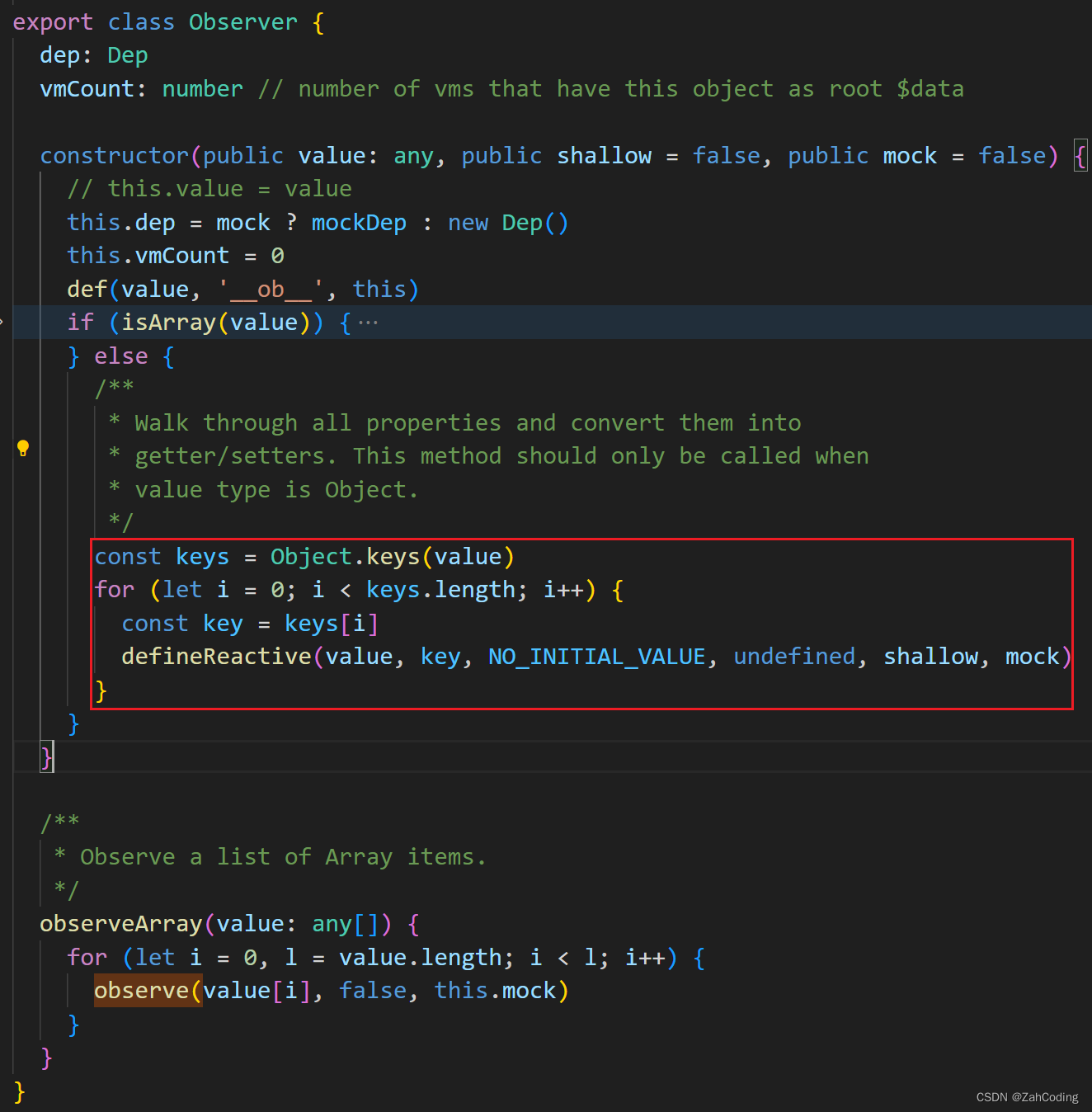
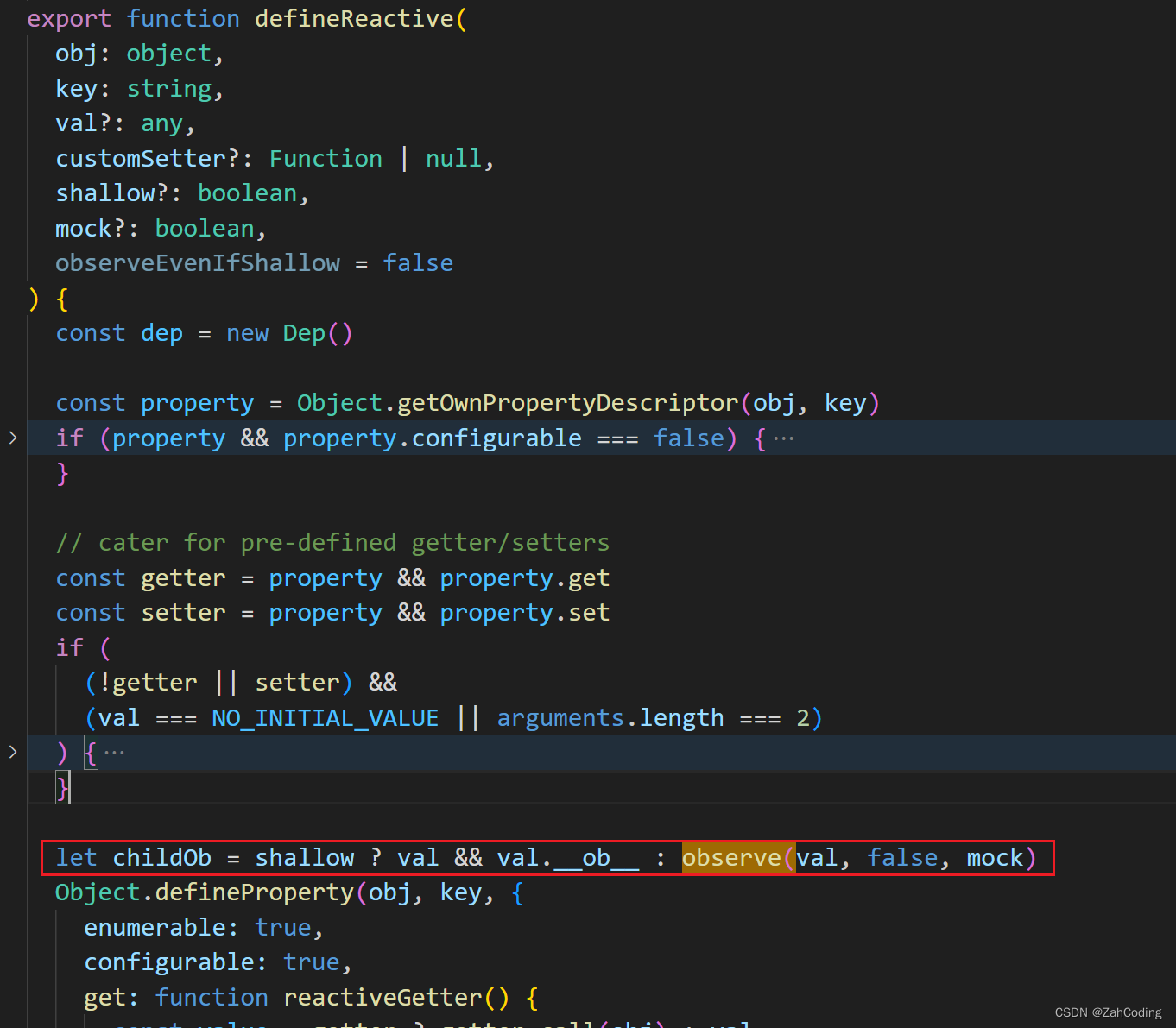
而defineReactive则会进一步对data内的对象进行深度劫持(shallow默认是false的)
而数组是用函数拦截的方式去实现的,直接在数组数据的原型上挂载自己拦截的push等操作
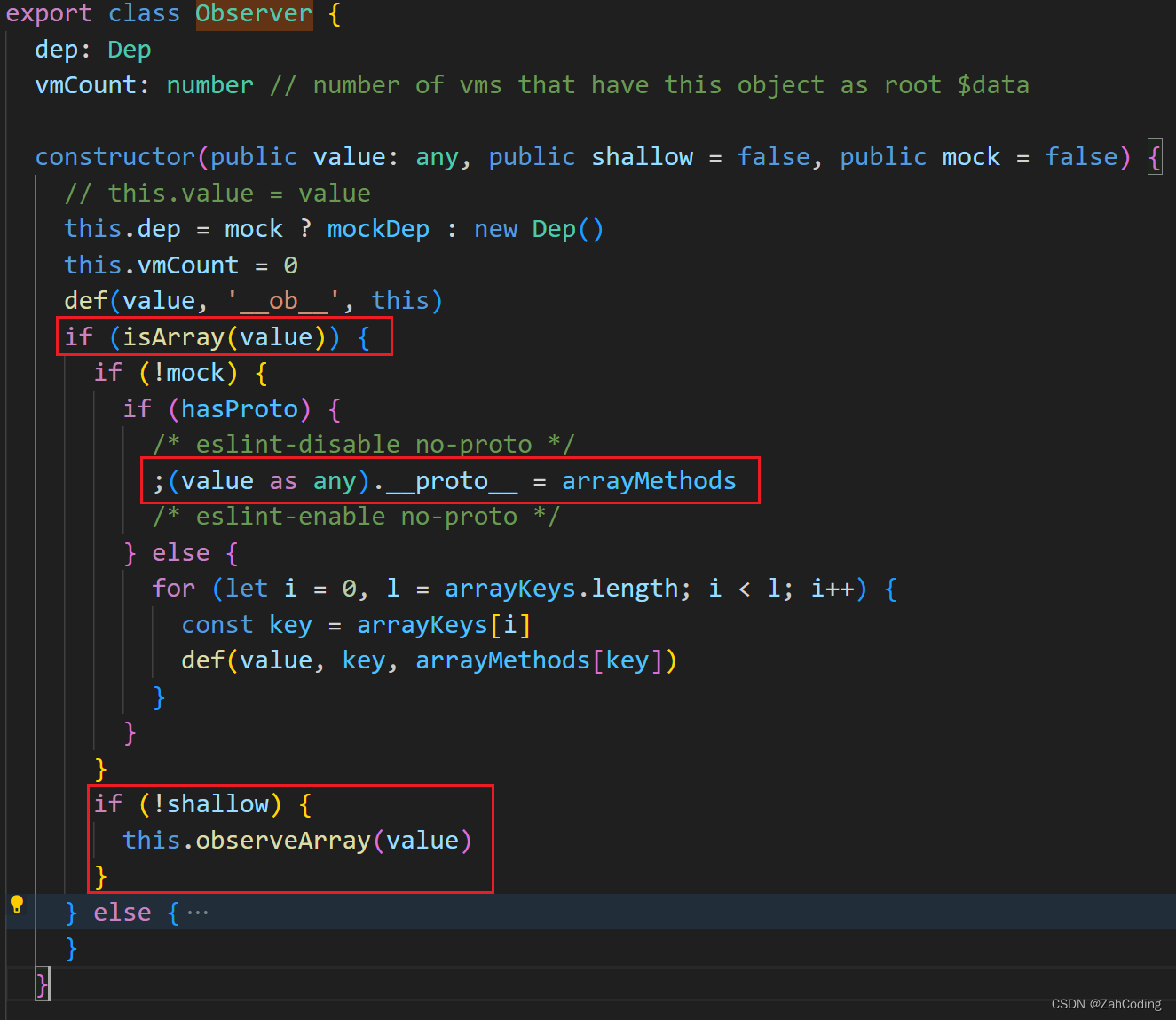
可以看到直接把整一个数组的操作都给重写了
/*
* not type checking this file because flow doesn't play well with
* dynamically accessing methods on Array prototype
*/
import { TriggerOpTypes } from '../../v3'
import { def } from '../util/index'
const arrayProto = Array.prototype
export const arrayMethods = Object.create(arrayProto)
const methodsToPatch = [
'push',
'pop',
'shift',
'unshift',
'splice',
'sort',
'reverse'
]
/**
* Intercept mutating methods and emit events
*/
methodsToPatch.forEach(function (method) {
// cache original method
const original = arrayProto[method]
def(arrayMethods, method, function mutator(...args) {
const result = original.apply(this, args)
const ob = this.__ob__
let inserted
switch (method) {
case 'push':
case 'unshift':
inserted = args
break
case 'splice':
inserted = args.slice(2)
break
}
if (inserted) ob.observeArray(inserted)
// notify change
if (__DEV__) {
ob.dep.notify({
type: TriggerOpTypes.ARRAY_MUTATION,
target: this,
key: method
})
} else {
ob.dep.notify()
}
return result
})
})
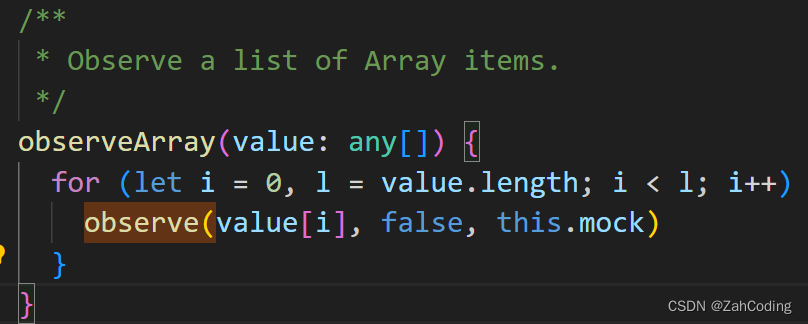
而对于数组中的数据,则是通过一次遍历,来对数组中的数据进行遍历实现深层拦截,核心方法是observeArray
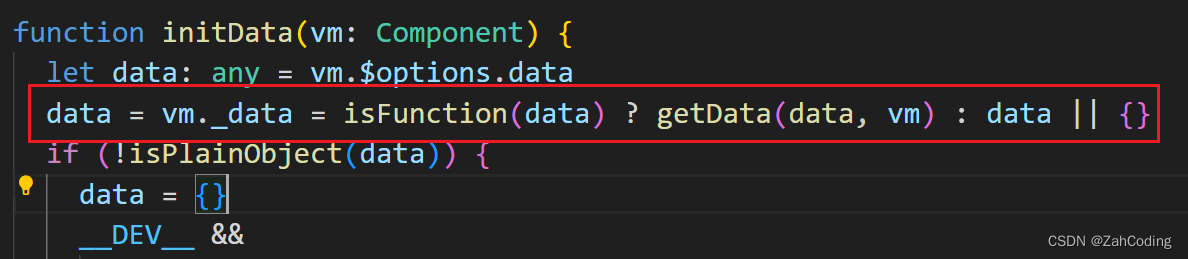
数据拦截处理完后,要实现能够通过this.msg访问data.msg,所以在initData中有这个操作
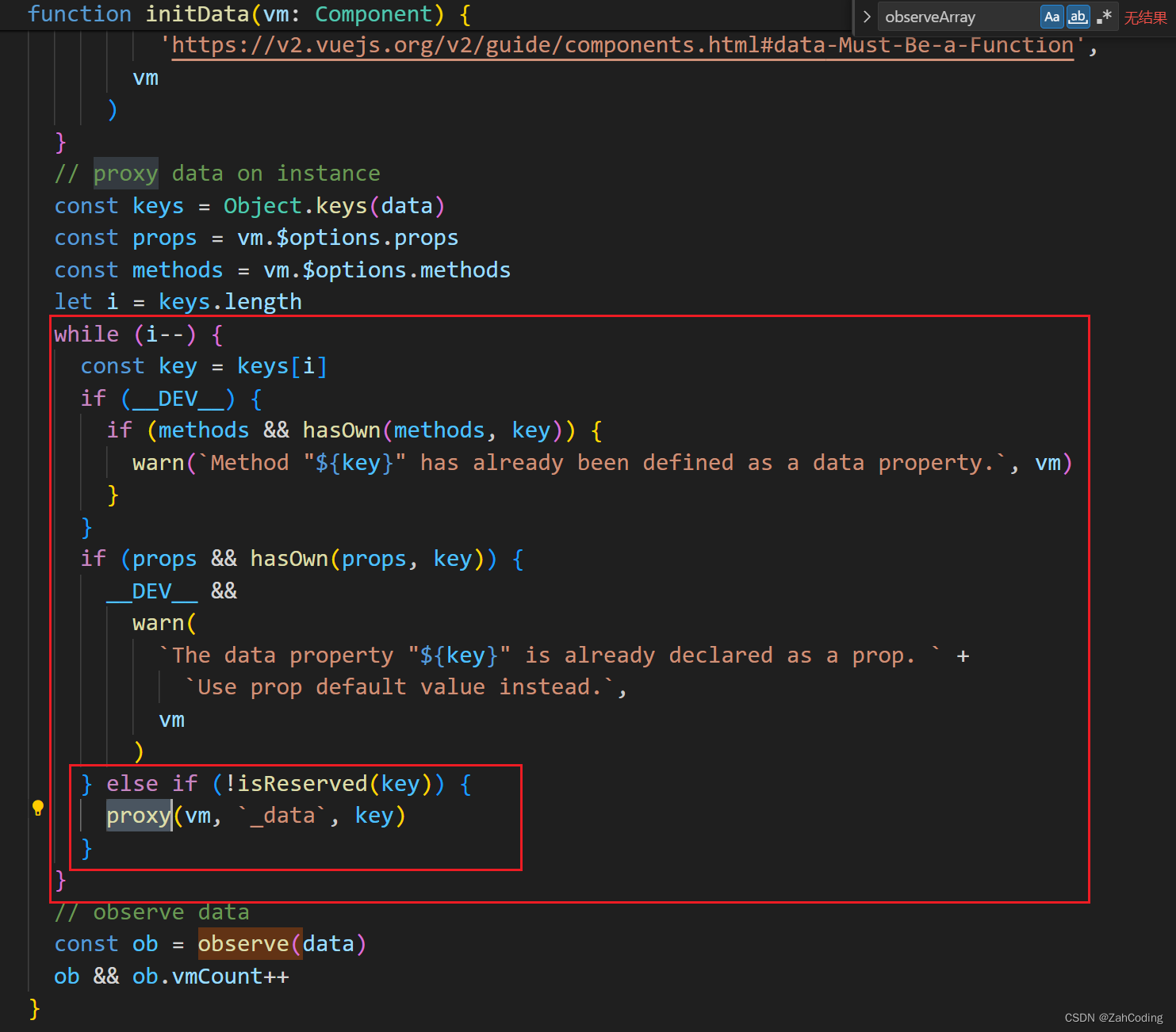
这里只需要对第一层进行proxy即可
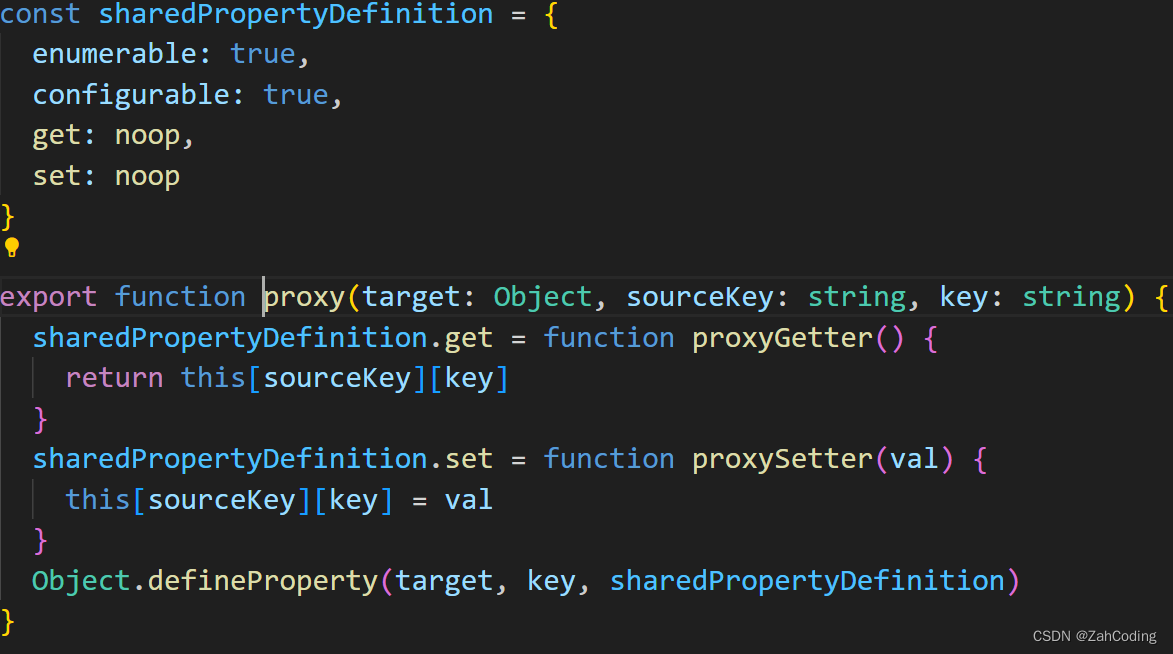
这里的Object.defineProperty对vm进行proxy,这样就实现了vm.msg或this.msg时,获取到的实际上是this._data.msg
注意_data早就在一开始就声明挂载好了
模板编译
初始化数据完成后,会调用$mount进行模板编译
Vue.prototype.$mount = function (
el?: string | Element,
hydrating?: boolean
): Component {
el = el && query(el)
/* istanbul ignore if */
if (el === document.body || el === document.documentElement) {
__DEV__ &&
warn(
`Do not mount Vue to <html> or <body> - mount to normal elements instead.`
)
return this
}
const options = this.$options
// resolve template/el and convert to render function
if (!options.render) {
let template = options.template
if (template) {
if (typeof template === 'string') {
if (template.charAt(0) === '#') {
template = idToTemplate(template)
/* istanbul ignore if */
if (__DEV__ && !template) {
warn(
`Template element not found or is empty: ${options.template}`,
this
)
}
}
} else if (template.nodeType) {
template = template.innerHTML
} else {
if (__DEV__) {
warn('invalid template option:' + template, this)
}
return this
}
} else if (el) {
// @ts-expect-error
template = getOuterHTML(el)
}
if (template) {
/* istanbul ignore if */
if (__DEV__ && config.performance && mark) {
mark('compile')
}
const { render, staticRenderFns } = compileToFunctions(
template,
{
outputSourceRange: __DEV__,
shouldDecodeNewlines,
shouldDecodeNewlinesForHref,
delimiters: options.delimiters,
comments: options.comments
},
this
)
options.render = render
options.staticRenderFns = staticRenderFns
/* istanbul ignore if */
if (__DEV__ && config.performance && mark) {
mark('compile end')
measure(`vue ${this._name} compile`, 'compile', 'compile end')
}
}
}
return mount.call(this, el, hydrating)
}
首先会读取el属性,获取到对应要挂载的节点,然后使用template进行模板解析
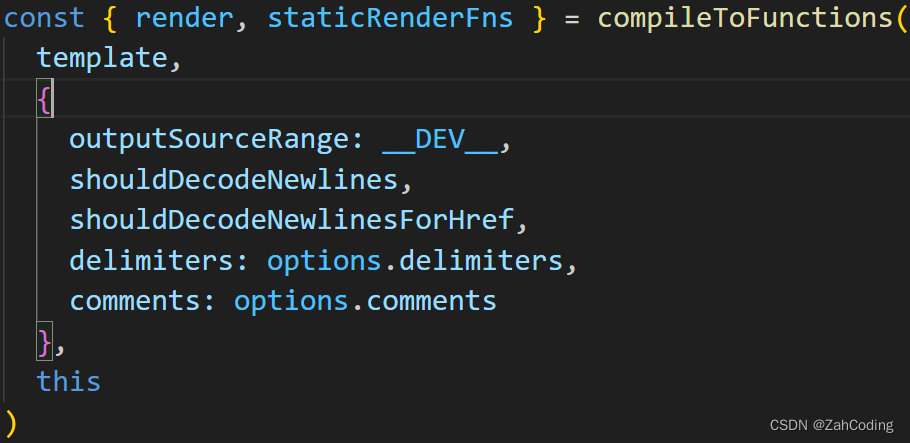
可以看到解析的优先级为
render > template > el(getOutterHTML),如果有render,就不会进行模板解析(因为render方法执行就可以获取到VNode了)
进入compileToFunctions,跳了比较多的层,但核心是parse和generate方法,里面的核心是parseHTML方法
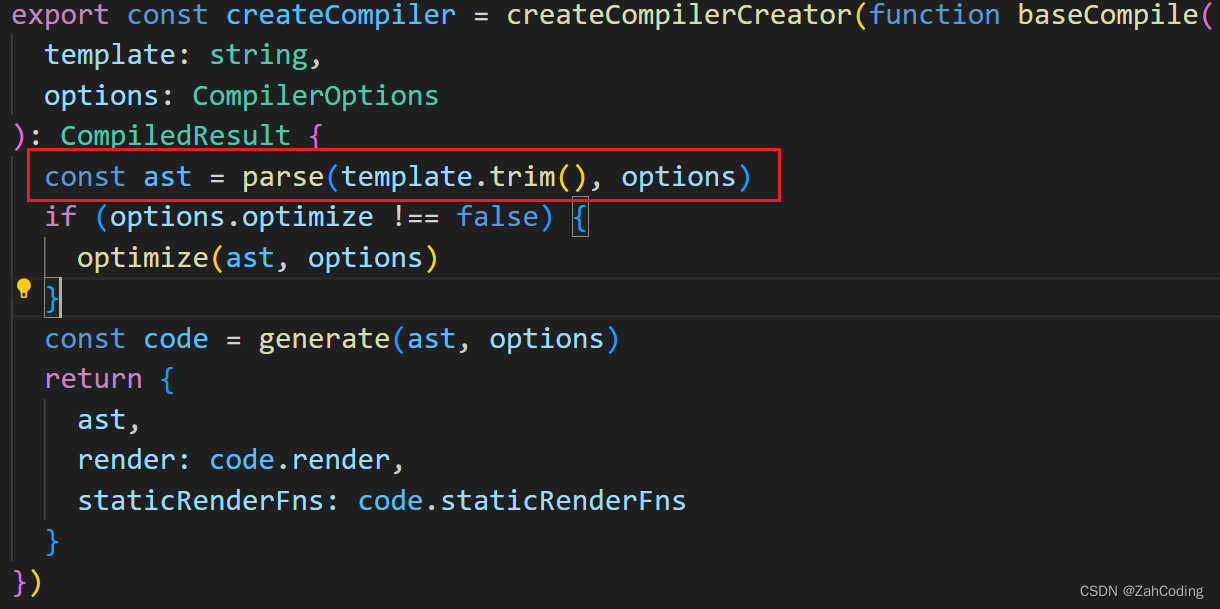
parse方法就是对template进行解析的核心方法,其中的
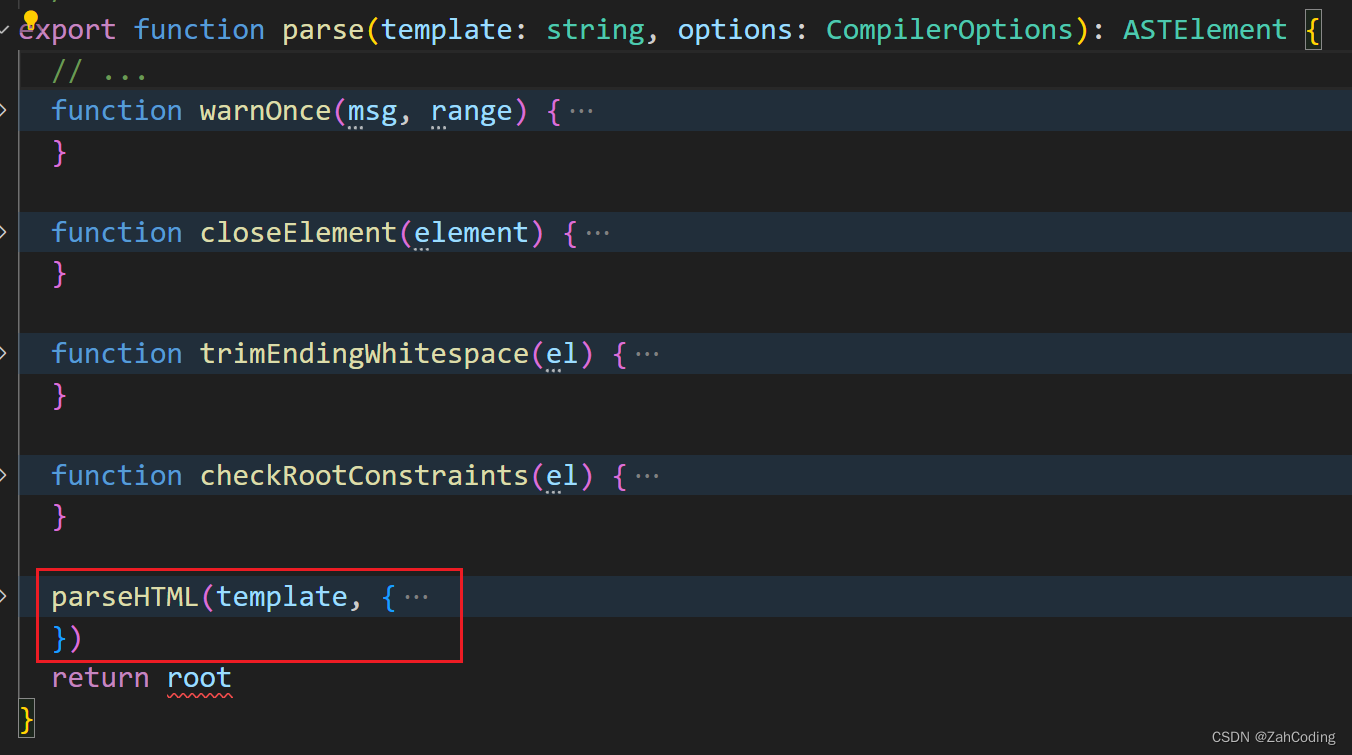
parseHTML做的就是使用while循环遍历模板代码,通过使用正则表达式来匹配各个标签、文本,最终转为AST抽象语法树
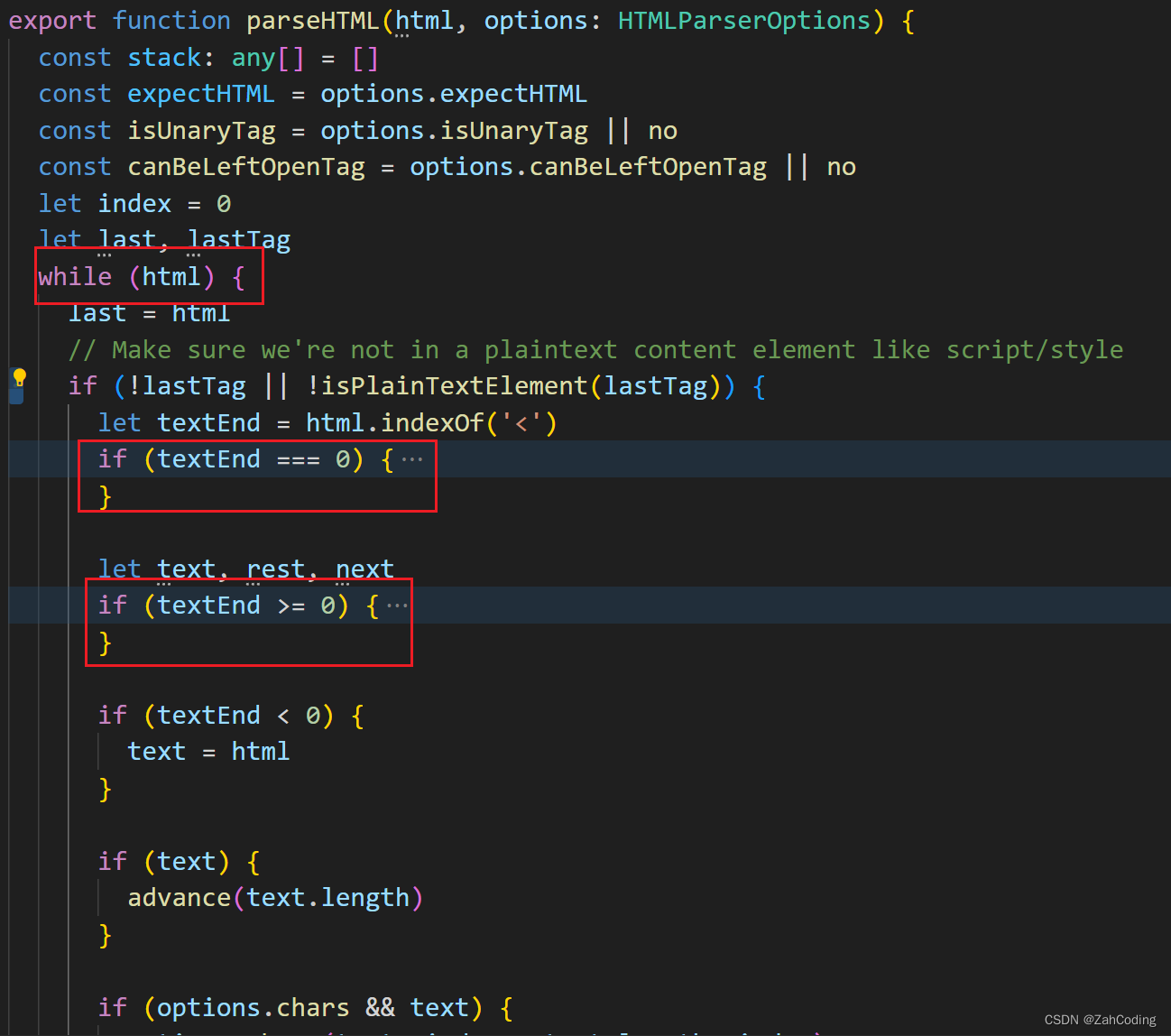
AST语法树解析要点:
- 通过
textEnd判断当前解析的是标签还是文本 textEnd === 0代表为标签,textEnd > 0调用parseXXXTag解析出用对象表示的标签,比如
const match = {
tagName: 'div',
attrs: [],
start: xx,
end: xx
}
解析完成后会调用
advance方法对while循环的html字符串进行裁剪
- 调用
createASTElement重新构建一个AST对象,对该对象设置attrs、tag等信息后入栈(识别startTag是入栈,识别endTag是出栈) - 最终可以获取到一个根节点,里面的
children数组记录了HTML树节点的父子关系
生成render函数
获取到上一步的AST对象(一个根节点)后,调用generate方法将AST拼接为字符串形式
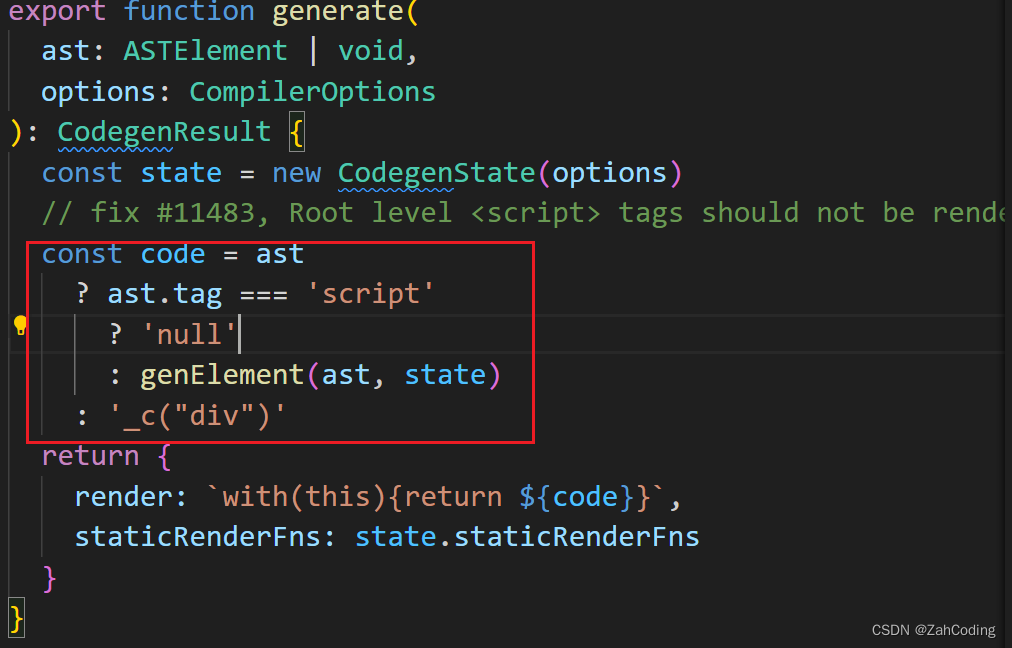
进入到genElement,分别调用genXXX等处理各种不同的情况,最后一个else处理元素或组件的情况
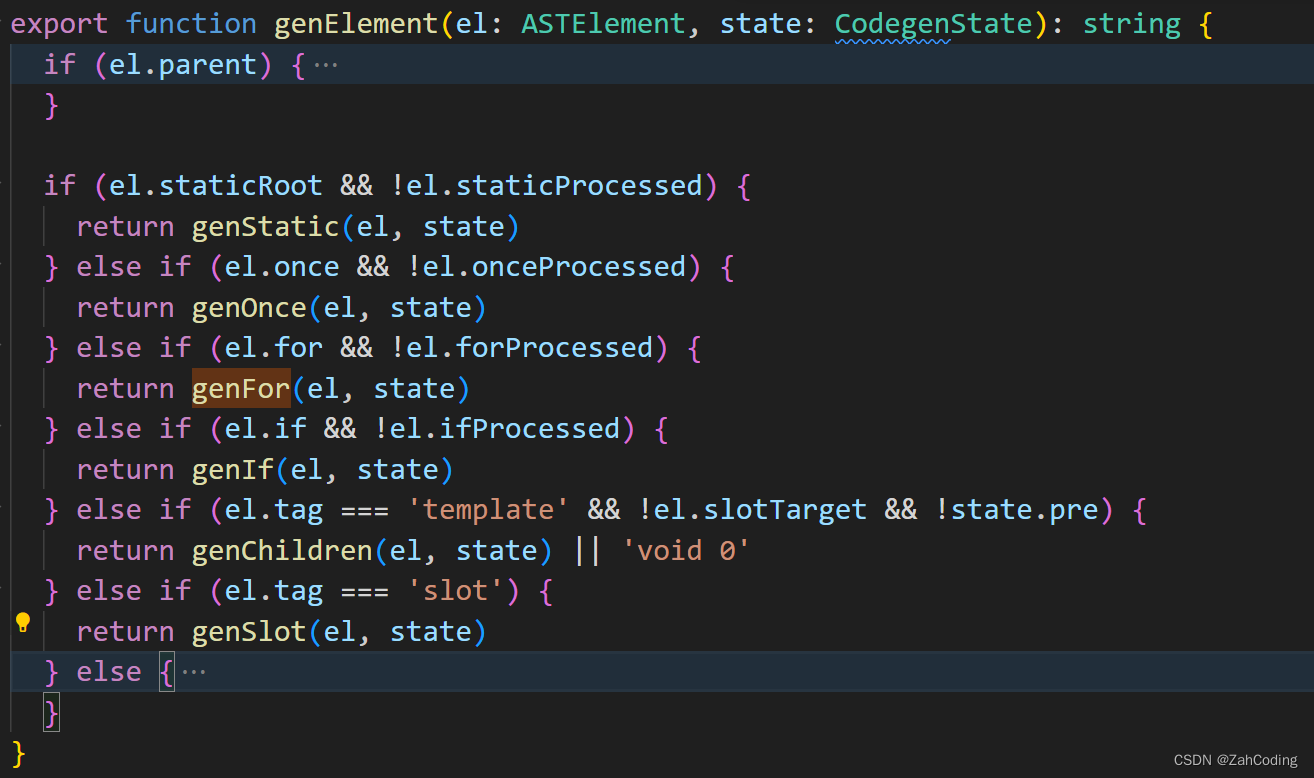
可以看到最后要生成的是以_c方法调用的字符串形式,这里的data、children也是通过genData、genChildren等方法计算而来
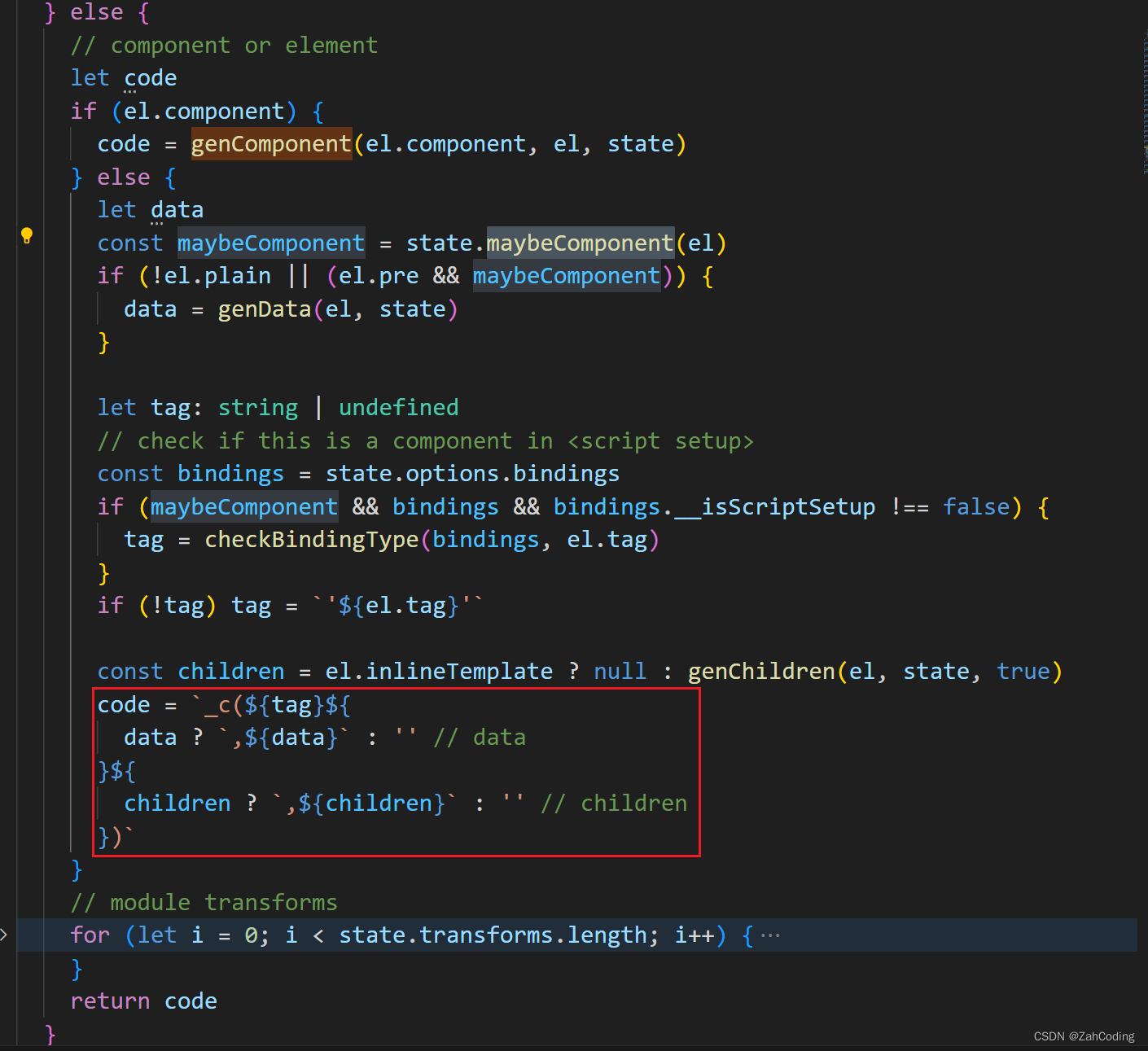
而_c对应的就是createElement方法,即生成VNode的方法
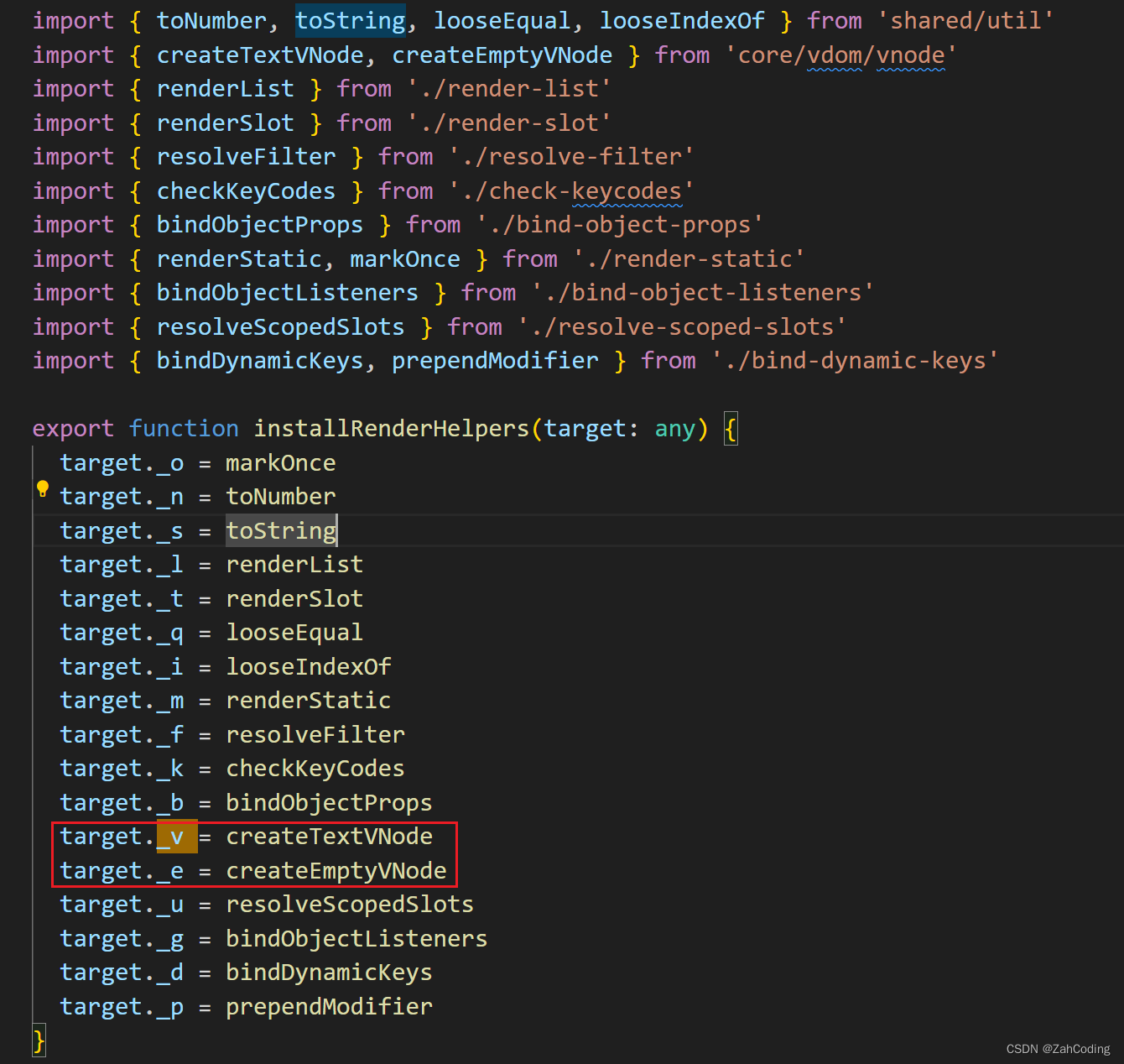
除了设置_c(xxx,xxx,xxx...)的形式,还有_v、_g等方法,这些也都是用vm上挂载的方法进行设置的
最终大概会获取到类似下面这样的结构:
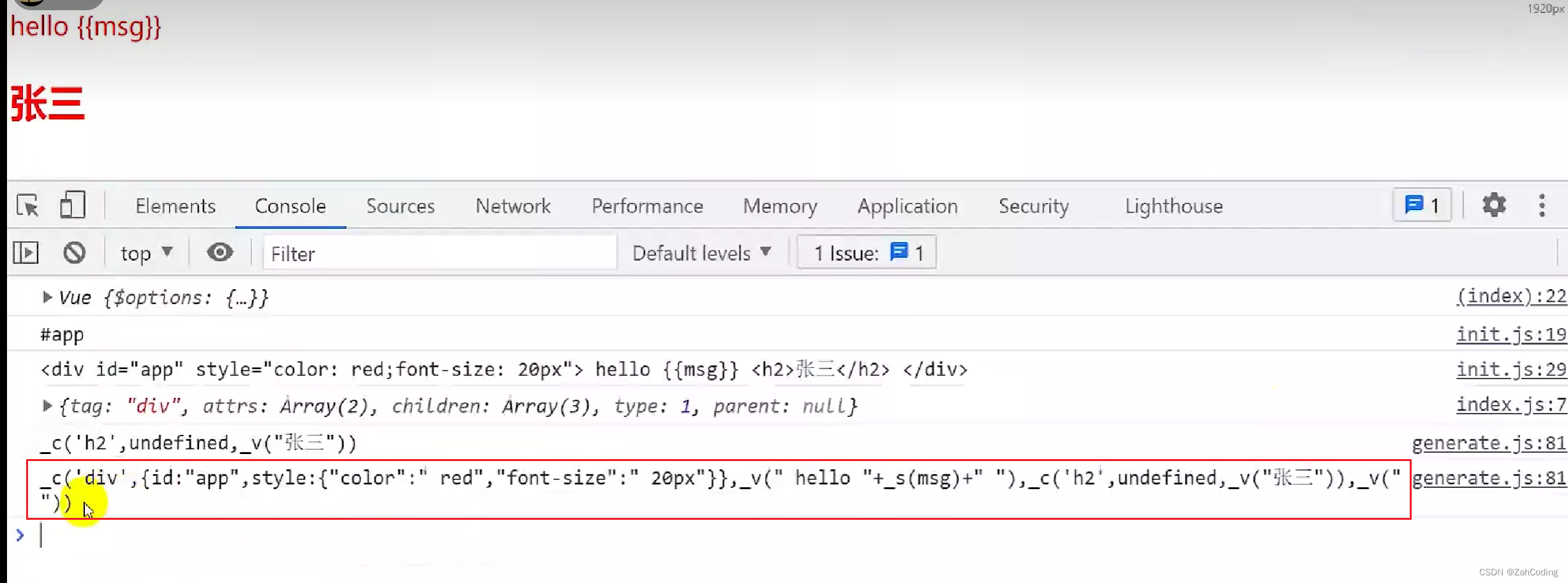
获得到上面这种形式的字符串后,最终会走到createCompileToFunctionFn方法中,在这个方法中就把render函数字符串使用newFunction变成了方法
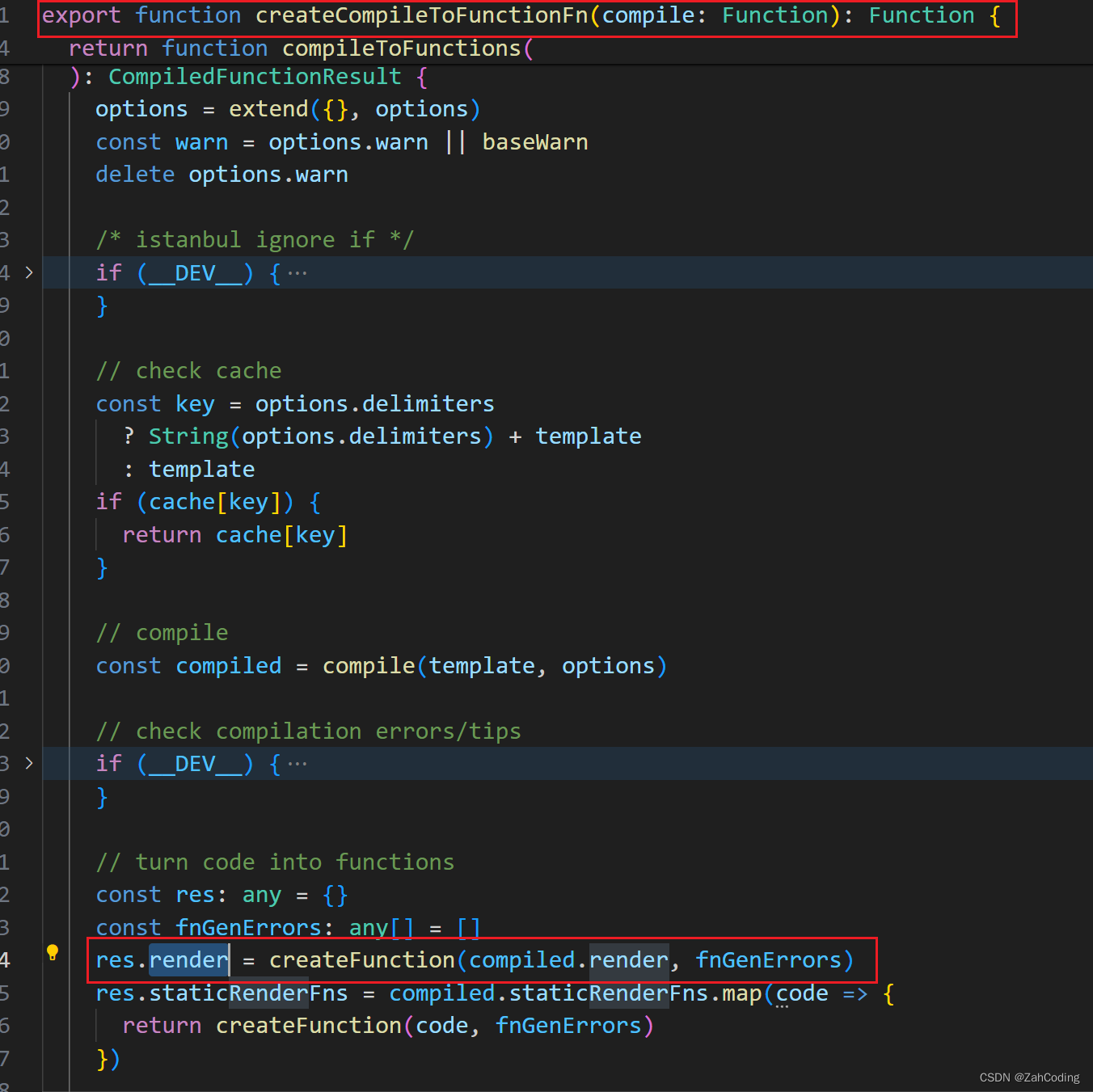
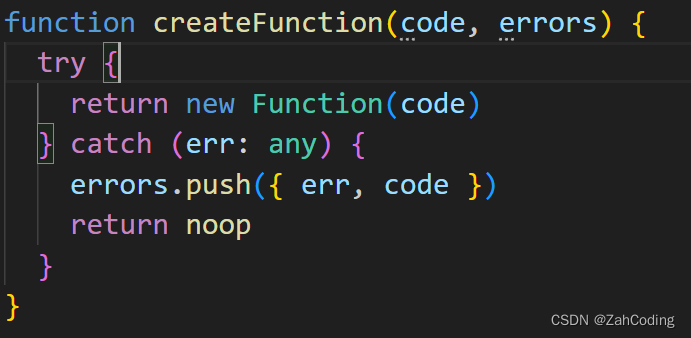
上面得到的最终的字符串,是直接访问的
_c,之所以可以这么使用,是因为code里写的是with(this),这样在调用的时候,传入vm,即可把作用域限制在vm下

render函数调用
获取到render函数,挂载到options上,随后开始执行mount渲染
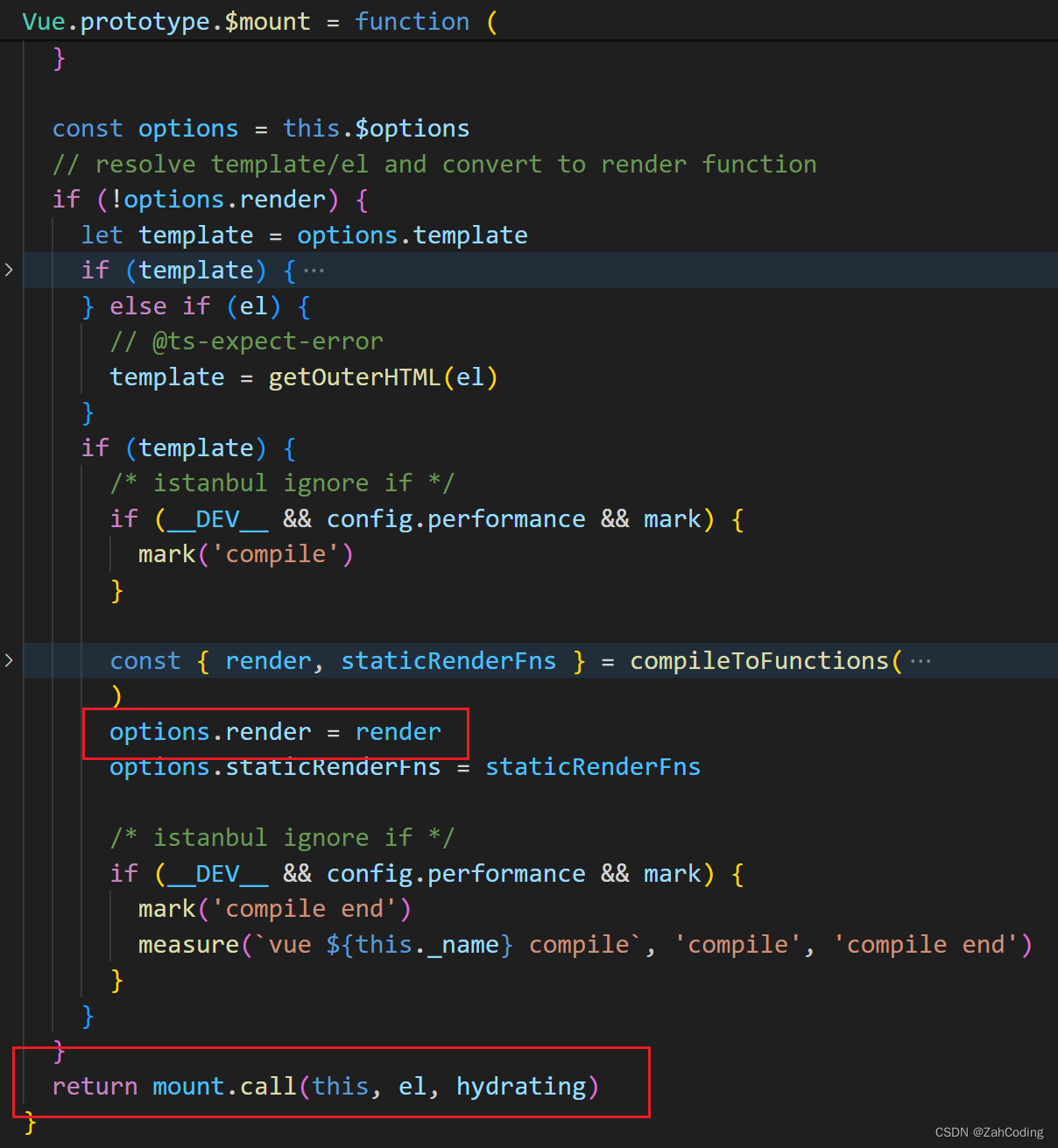
这里的mount对应初始挂载的mountComponent方法,其中核心为_update与_render
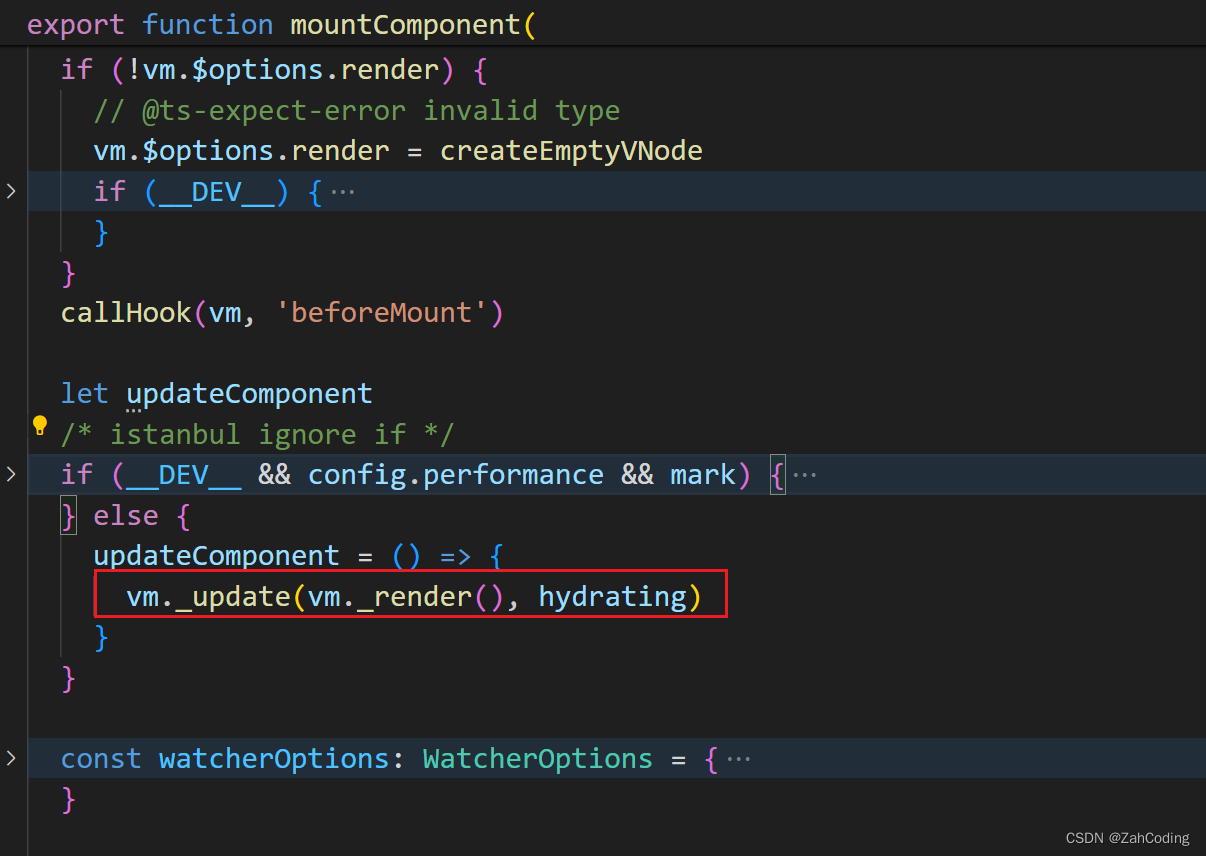
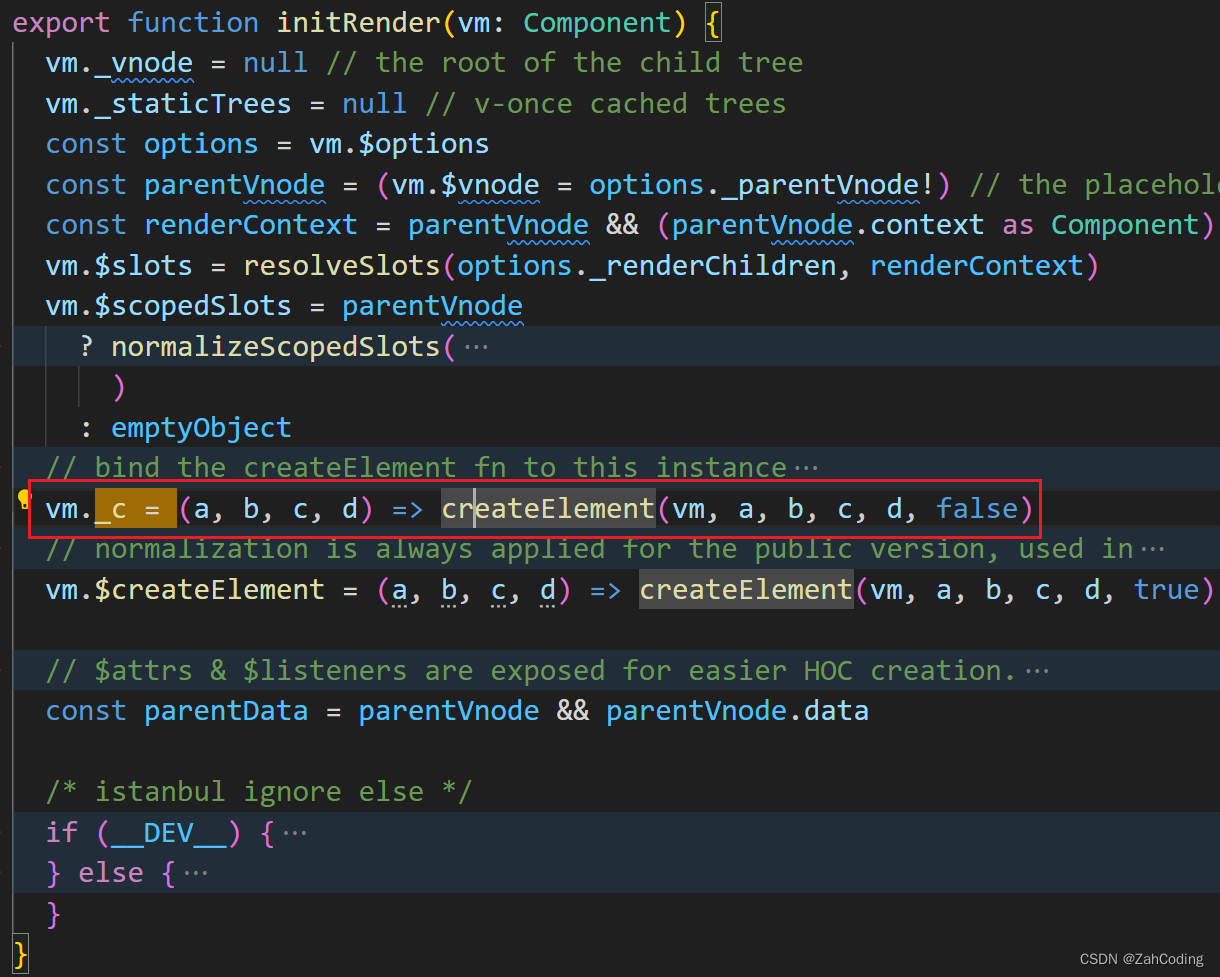
_render实际上就是调用render方法,同时把createElement方法传给render当作参数,这样就获取到了VNode
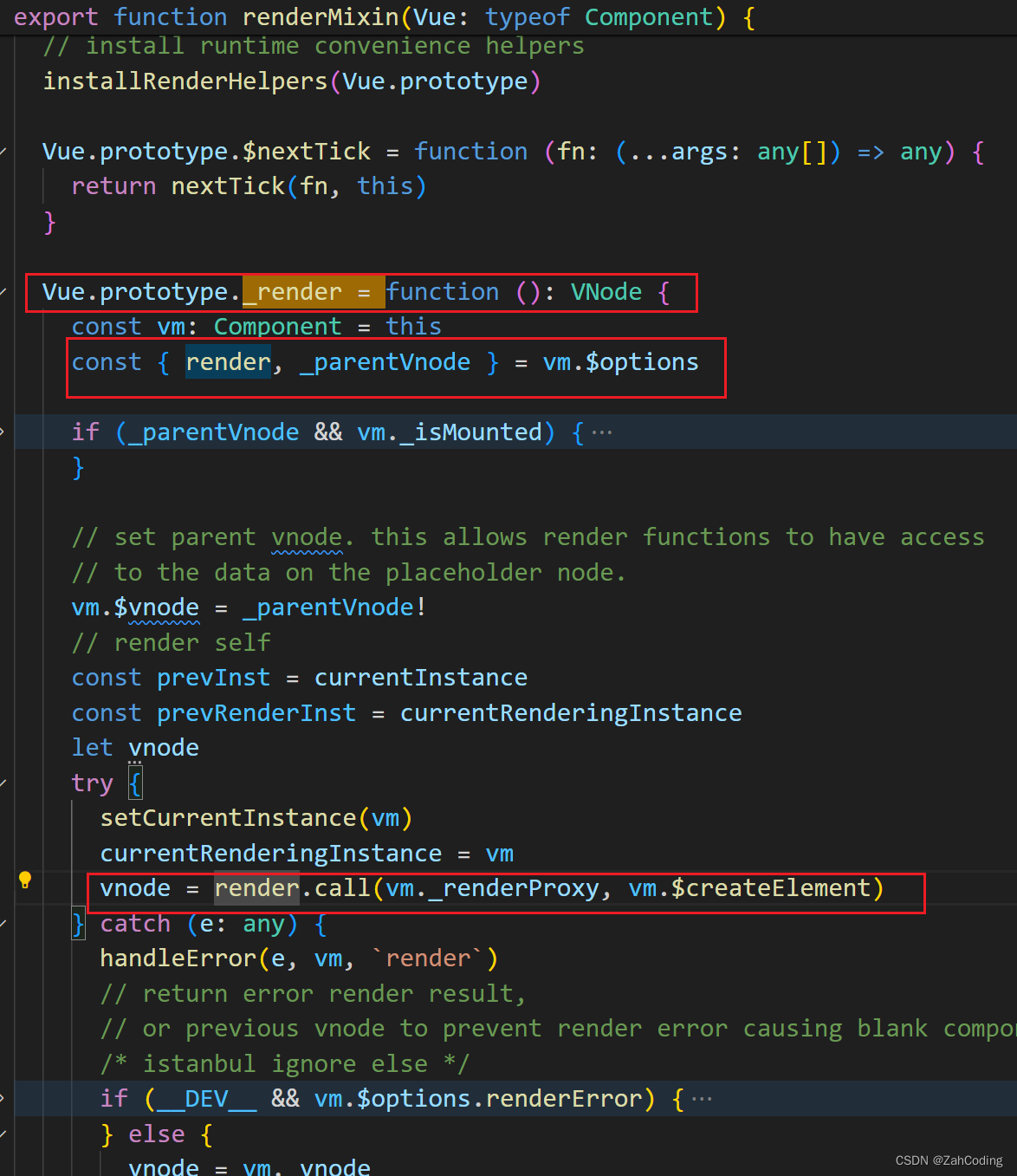
这里结合上面的with(this),就成功把作用域限制在了renderProxy下,而renderProxy实际上就是vm本身而已
生成虚拟DOM
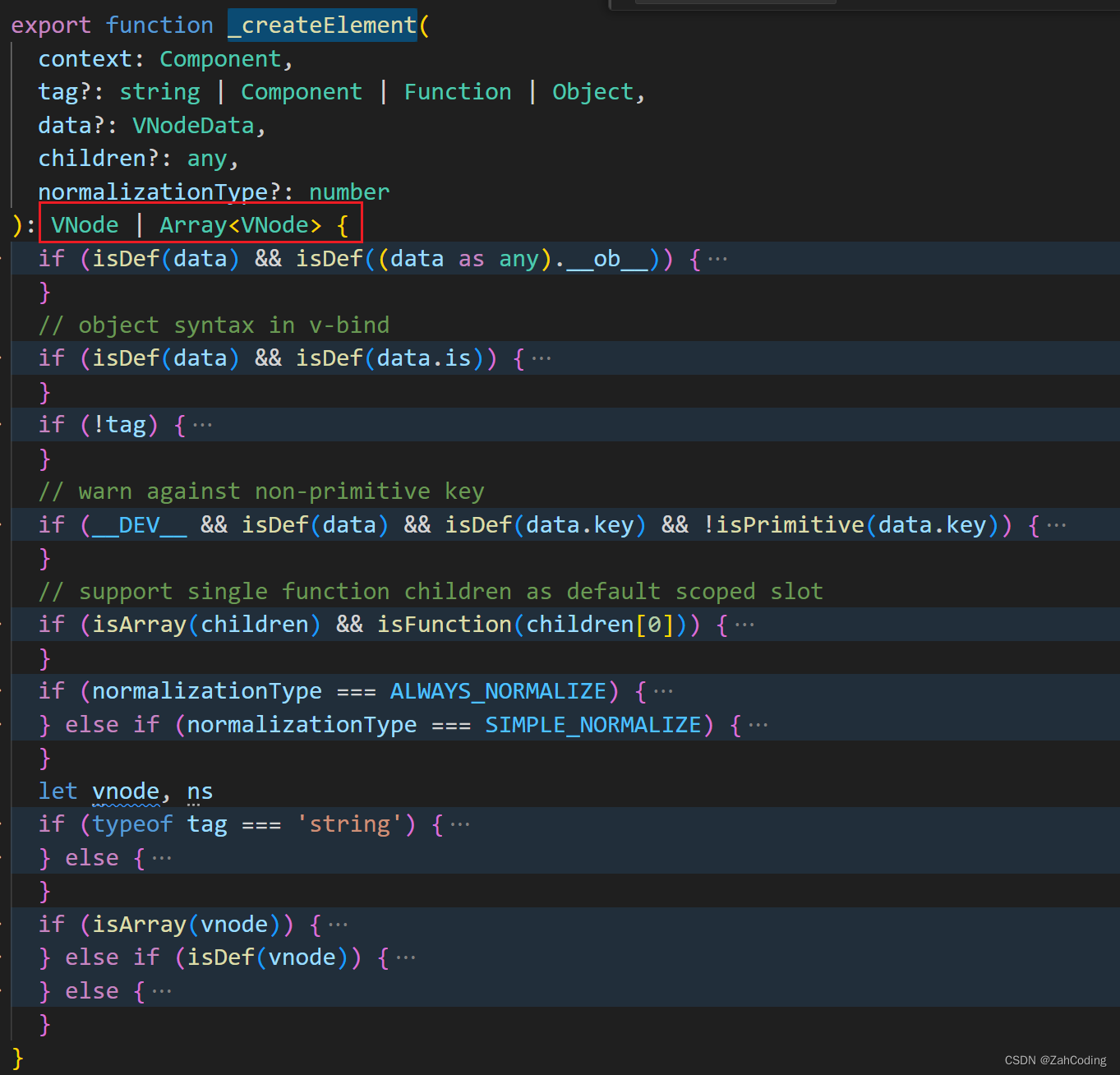
调用render函数,即执行了_c('div', xxx)这样的语句,就等于调用了createElement函数来创建VNode
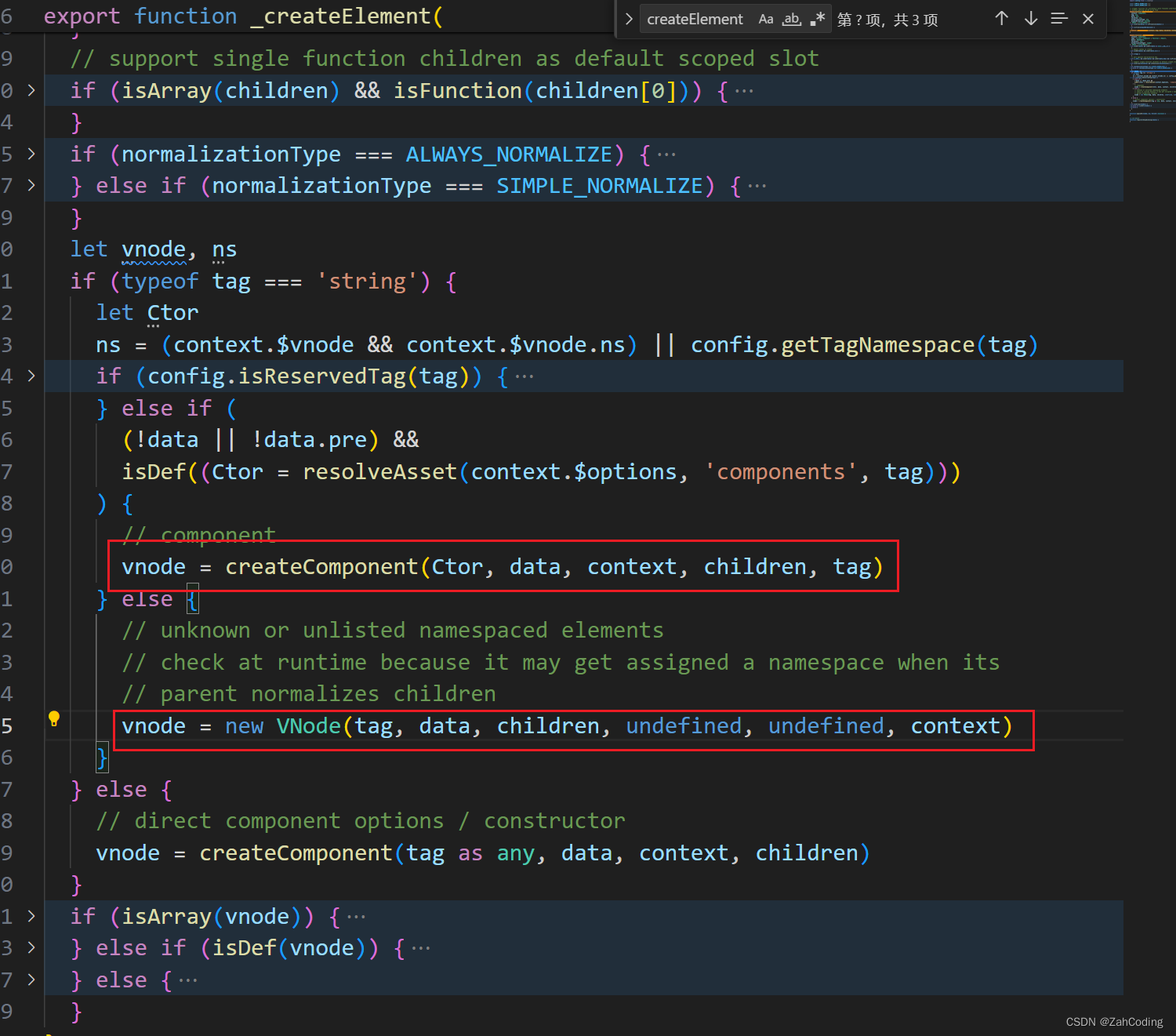
Vnode就是将传入的tag、data等放到VNode类里,声明一堆变量而已
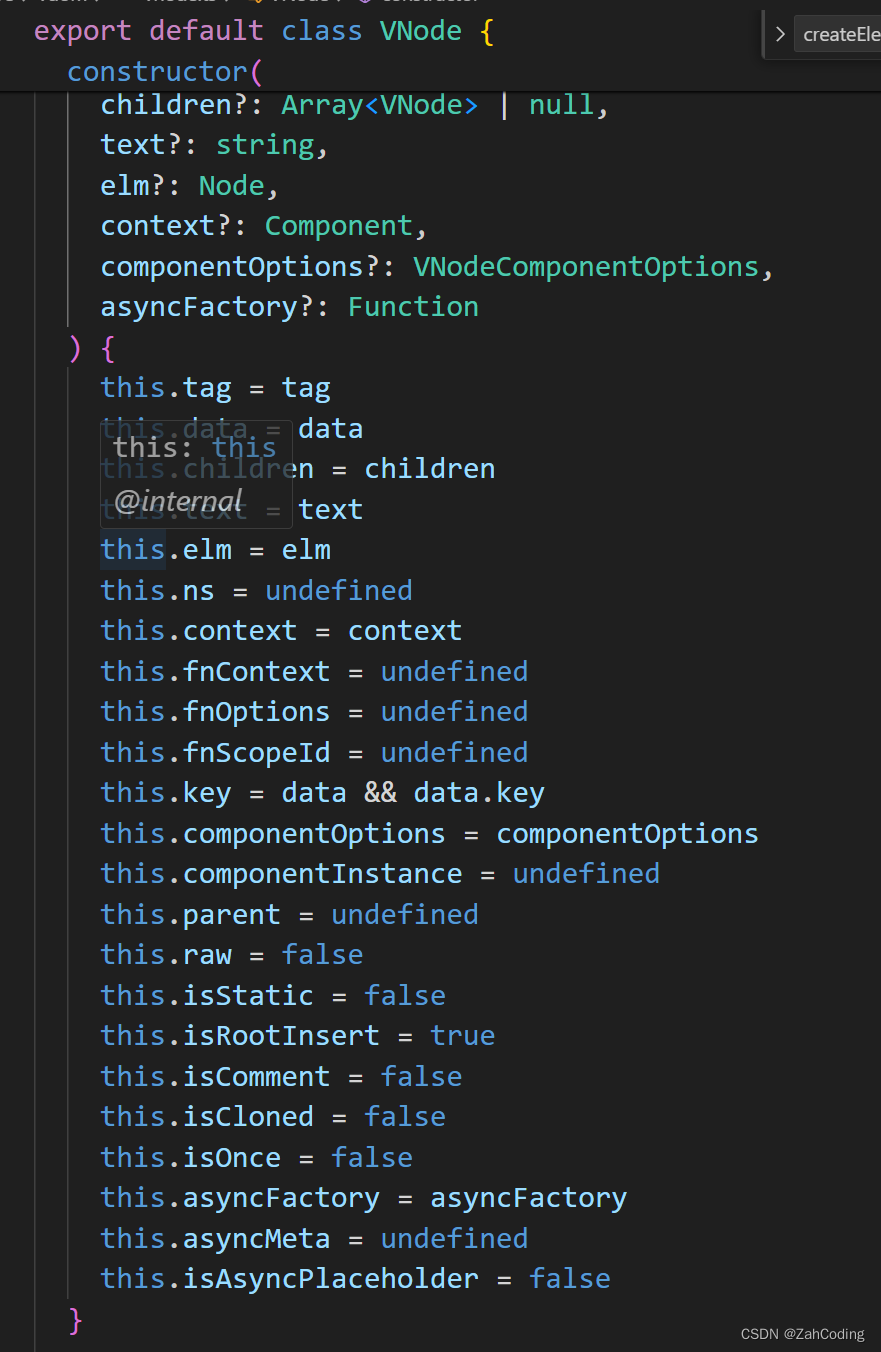
AST与VNode有什么不同?
- AST 是描述语法的, 他并没有用户自己的逻辑,只有语法解析出来的内容;并且AST还适用于跨平台的渲染和使用,比如用在
weex里- Vnode 是描述dom结构的 ,可以自己去扩展,比如塞入一堆状态控制的变量
虚拟DOM变为真实DOM
调用_update方法,就会用_render生成的VNode去执行patch,patch便是把虚拟dom通过document的原生API转为真实DOM进行渲染的方法

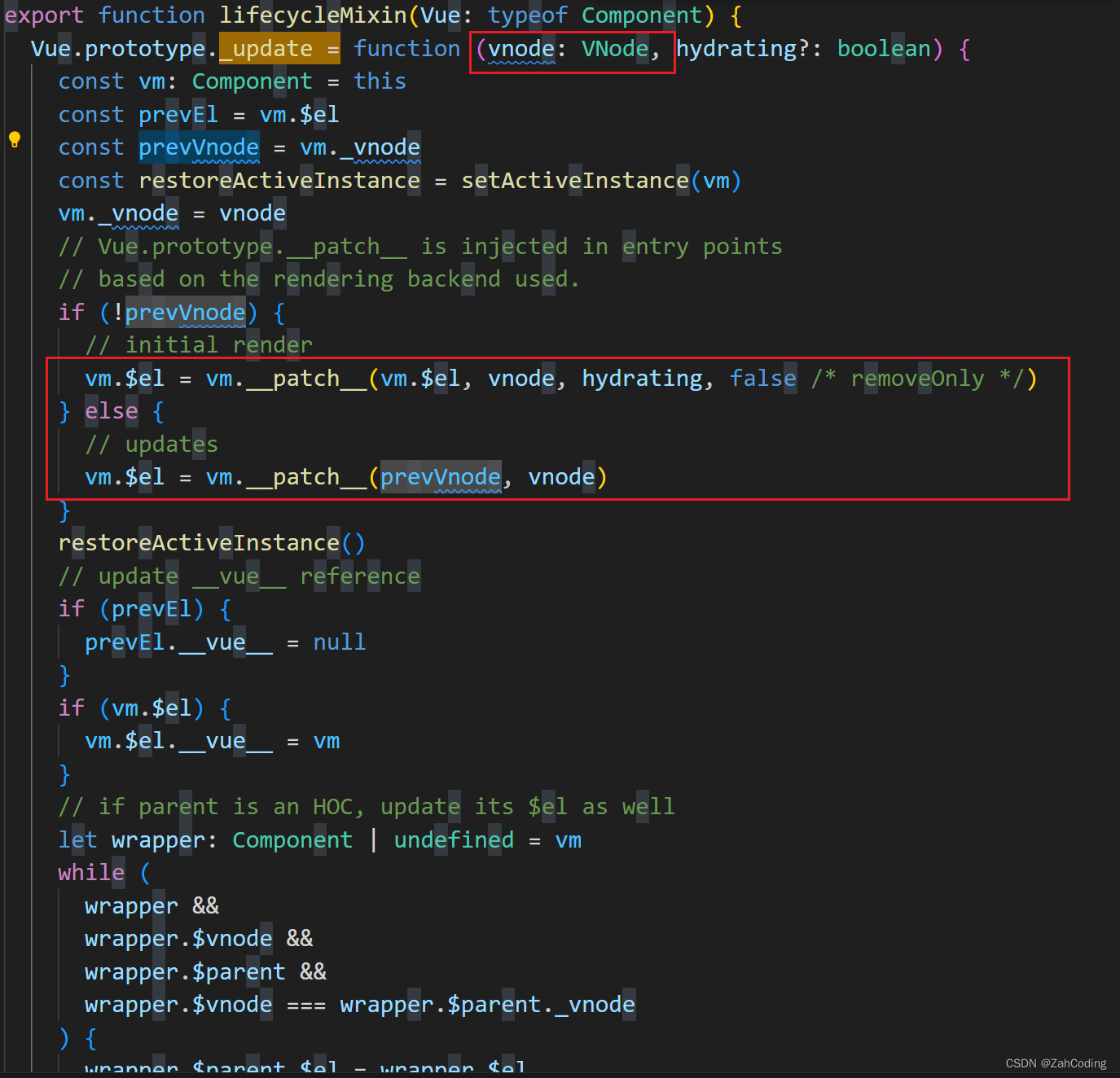
而update调用的时机,就是watch监听到页面变化时进行调用
patch
生命周期合并与调用
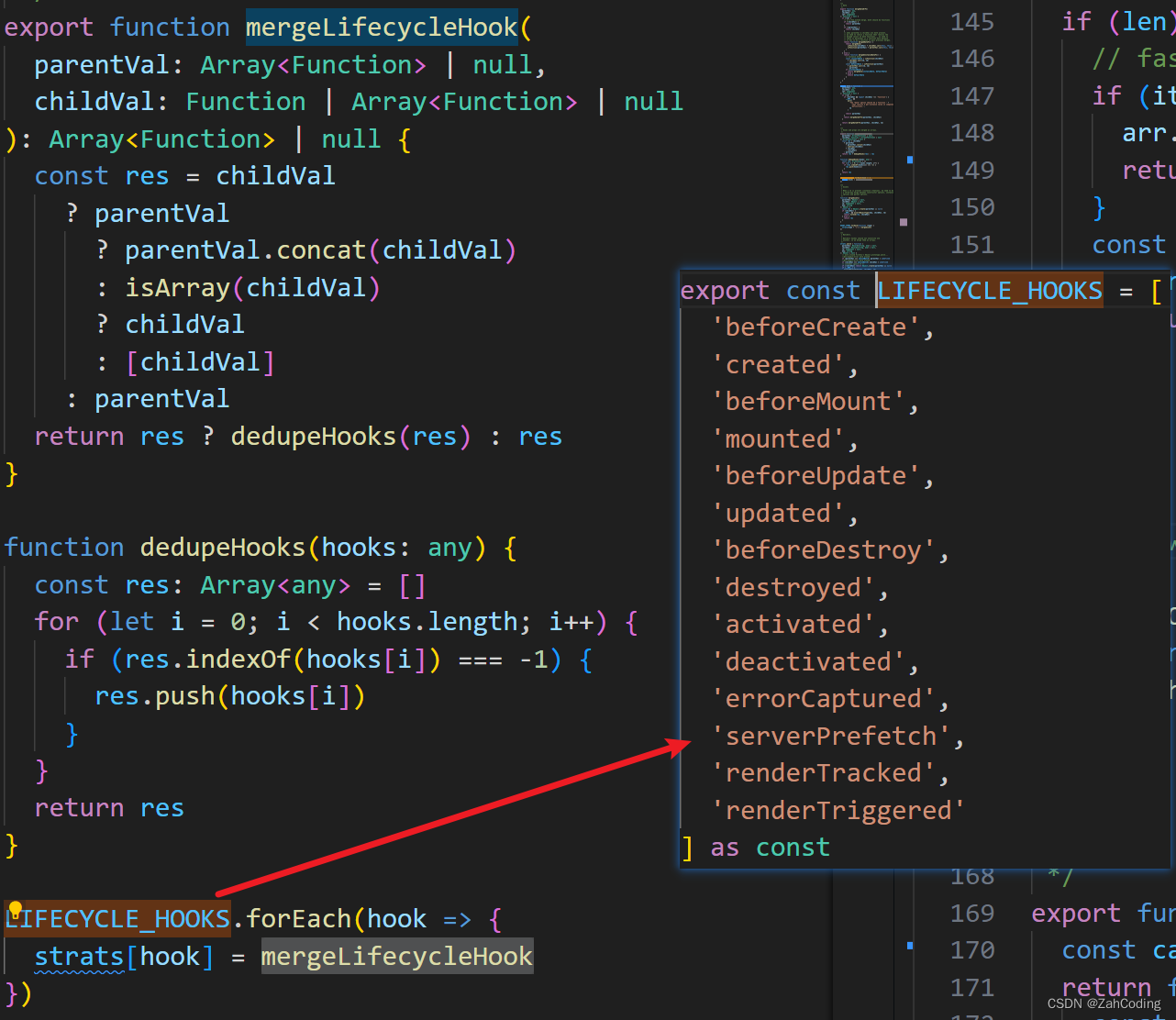
一般声明生命周期的地方,除了组件内部,还有Vue.mixin({created()})的方式进行注入,此时会对options进行合并
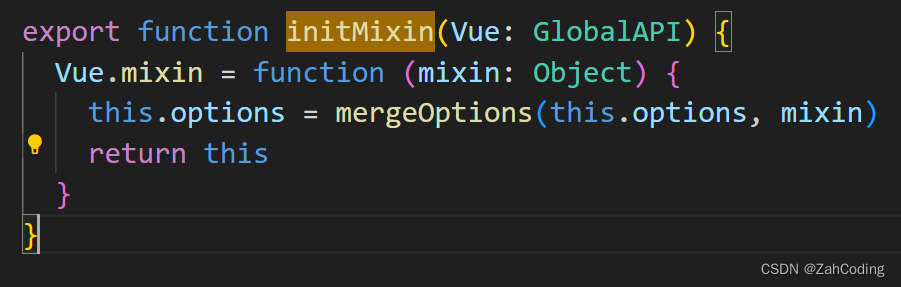
在mergeOptions方法中,会遍历两个要合并的options的对象,对每个key的对应值按照策略模式进行处理
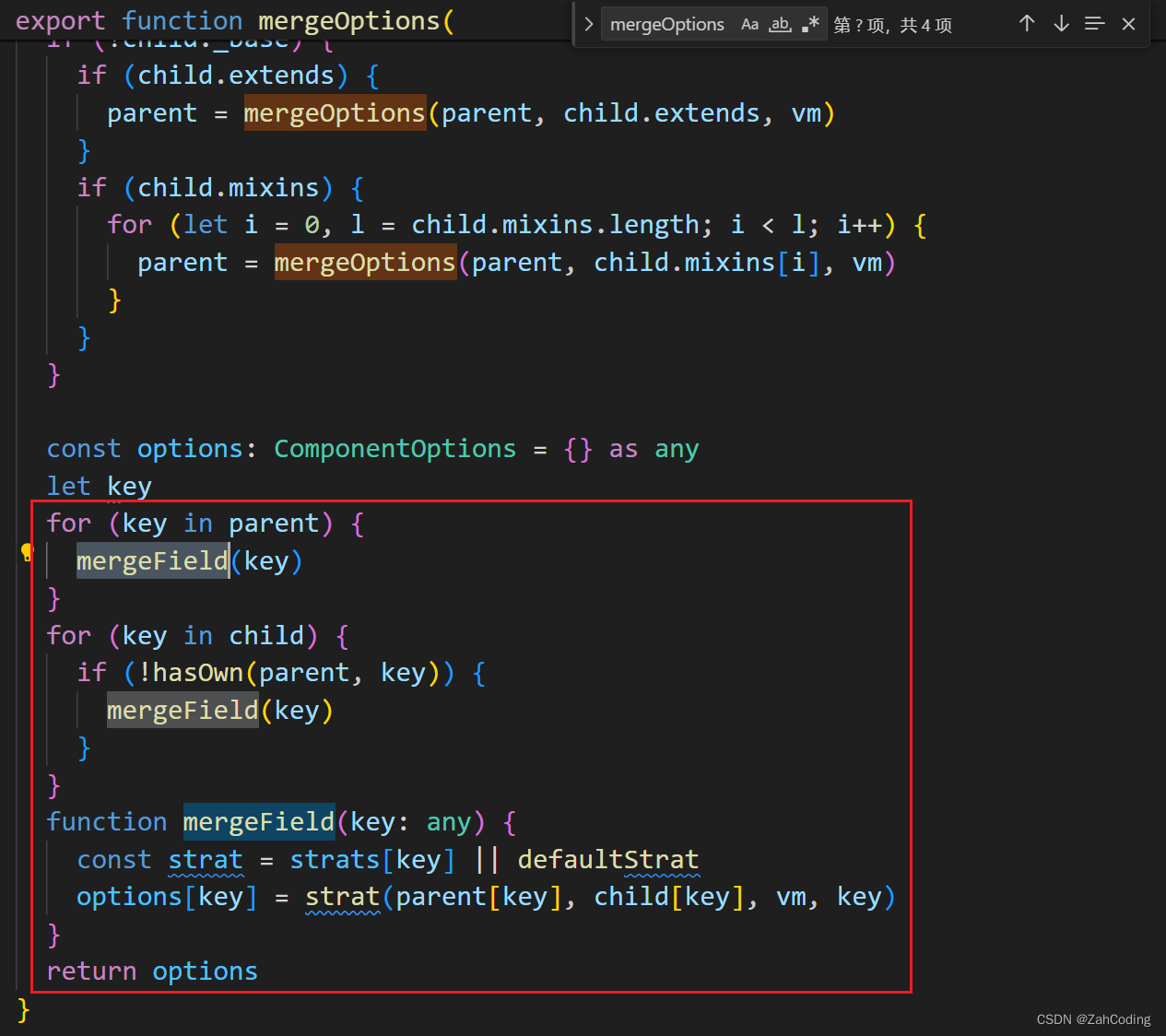
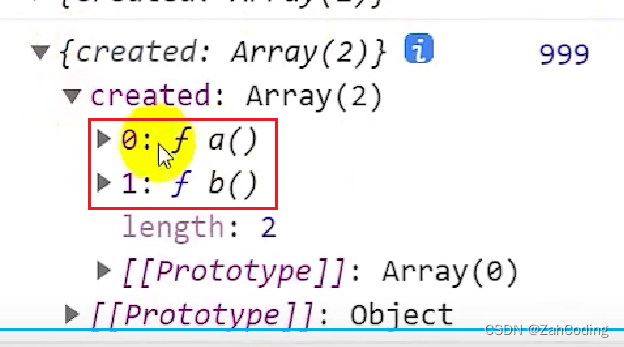
这里所谓的策略模式,其实就是优化了if的判断,将parent和child中相同key的值整合成数组
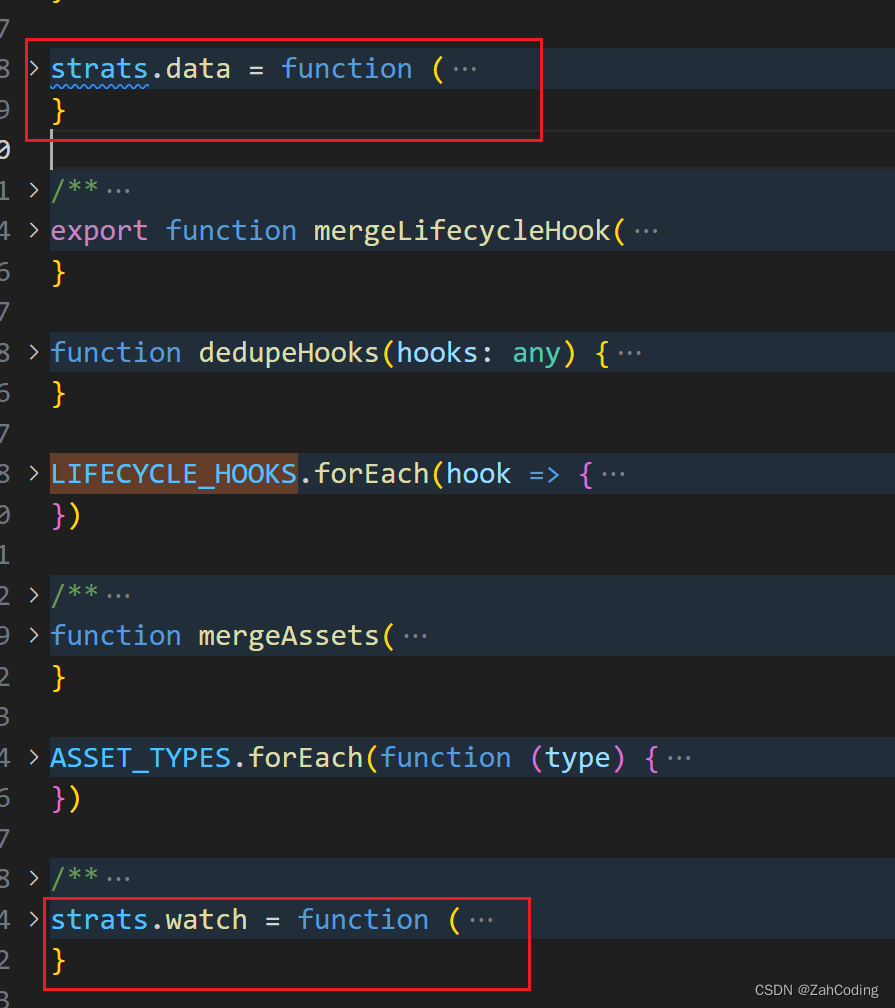
而对于data或watch的合并,也有对应的处理
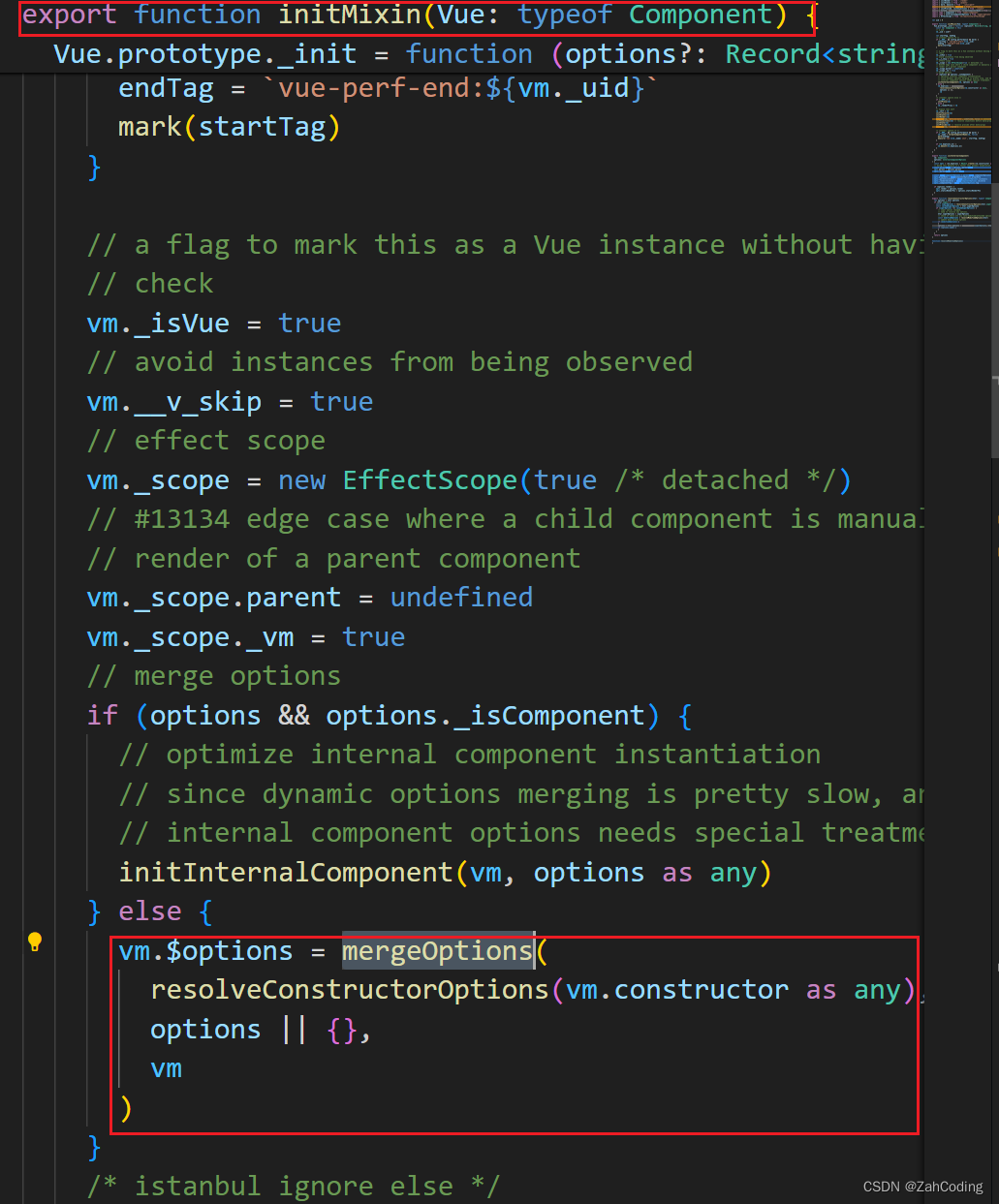
同理的,在Vue初始化时,也会调用mergeOptions进行合并操作
生命周期的调用,则是通过callHooks实现
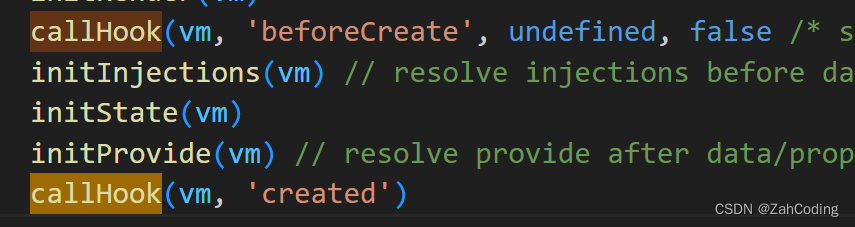
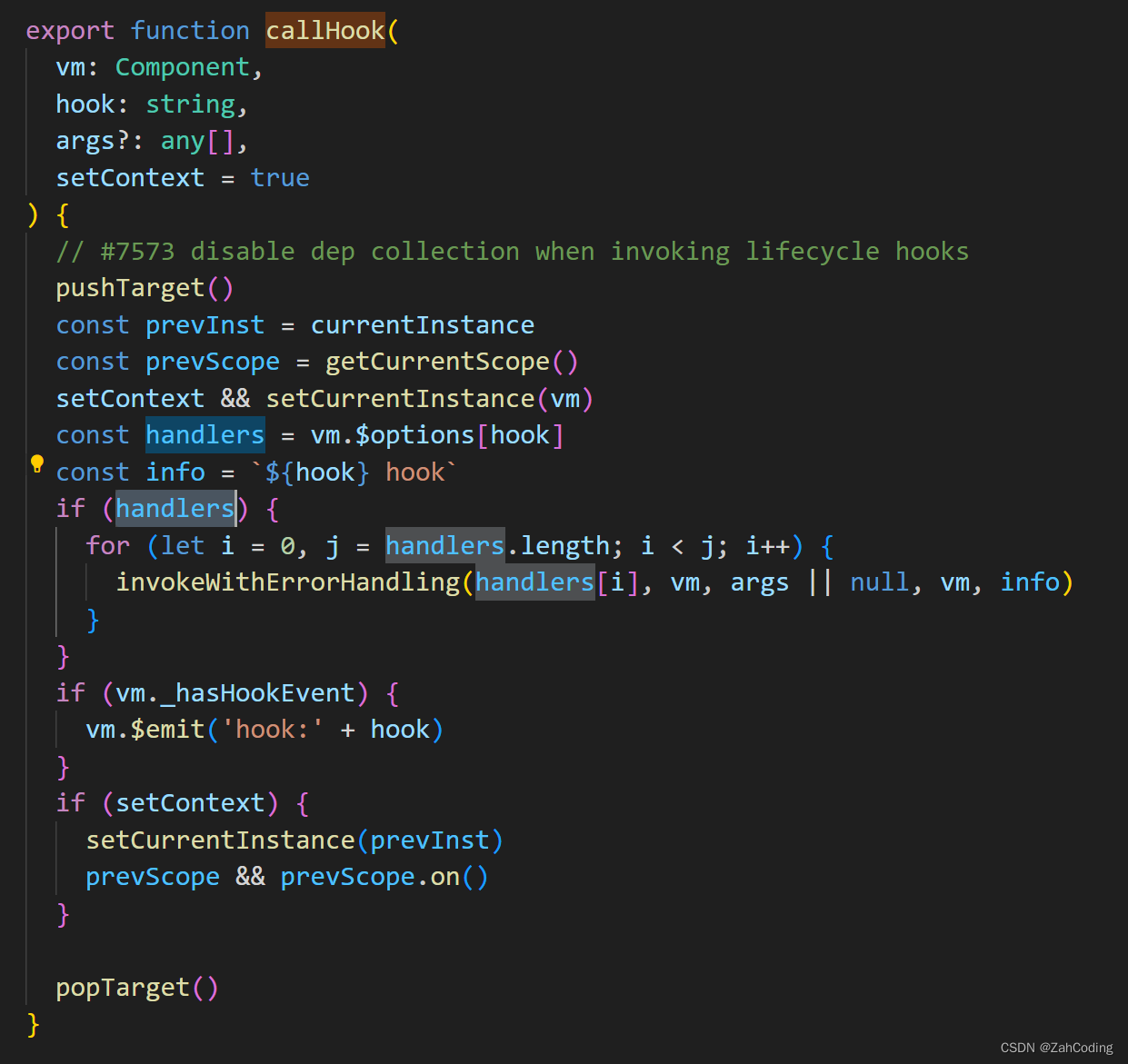
callhooks便是对所有的hook进行遍历和调用
dep与watcher
通过发布-订阅模式来完成依赖收集
- dep:
data上有多少响应式数据的属性,就有多少个dep(对象里的每一个属性都有一个dep)(发布者) - watcher:视图上用了几处,就有多少
watcher(订阅者) - dep与watcher是多对多关系
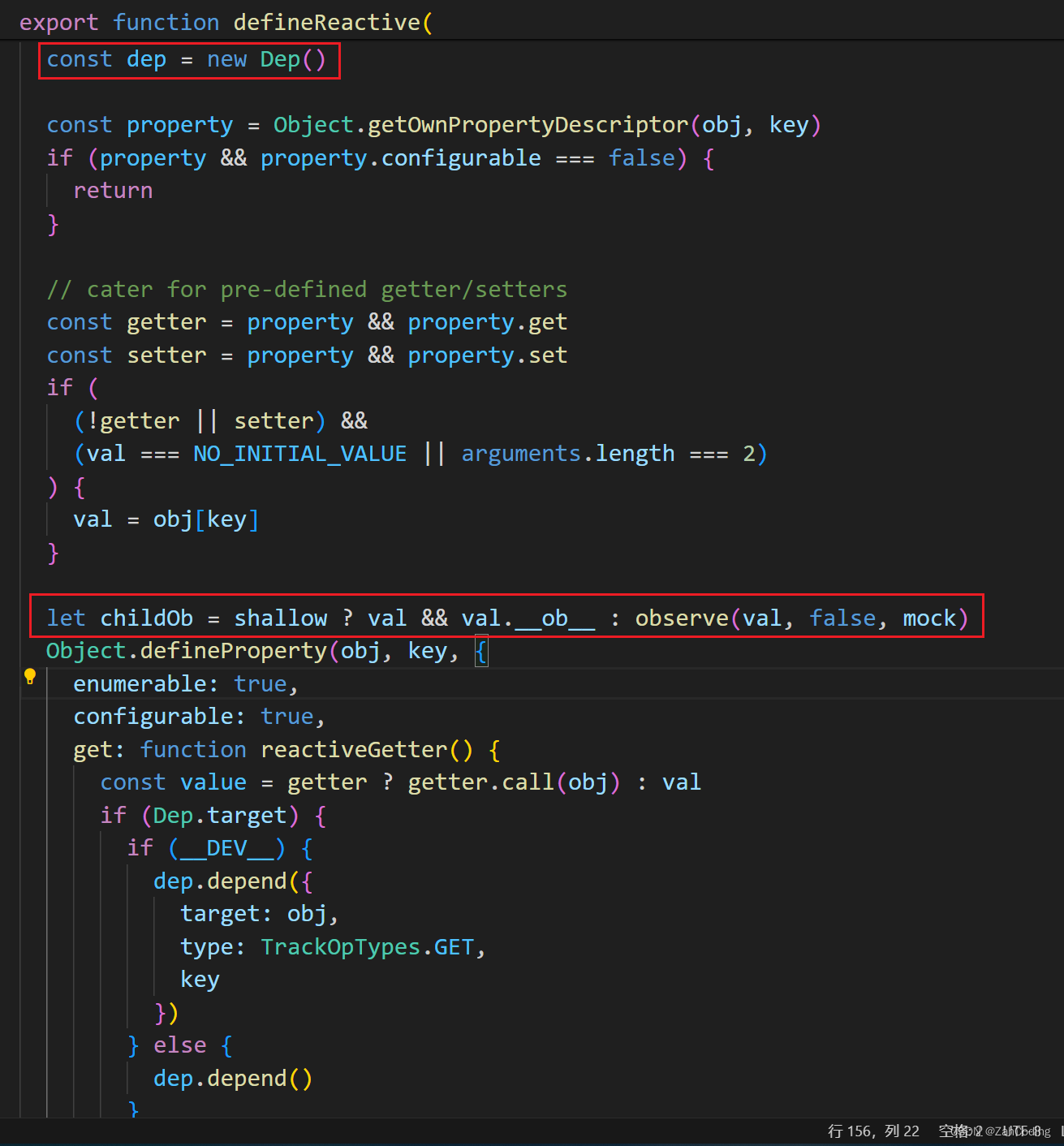
首先需要注意在数据初始化的时候就对data里的数据完成了数据劫持,每个数据被劫持时,就会创建一个dep实例,对于对象而言,则会进一步深层地进行数据劫持与创建dep
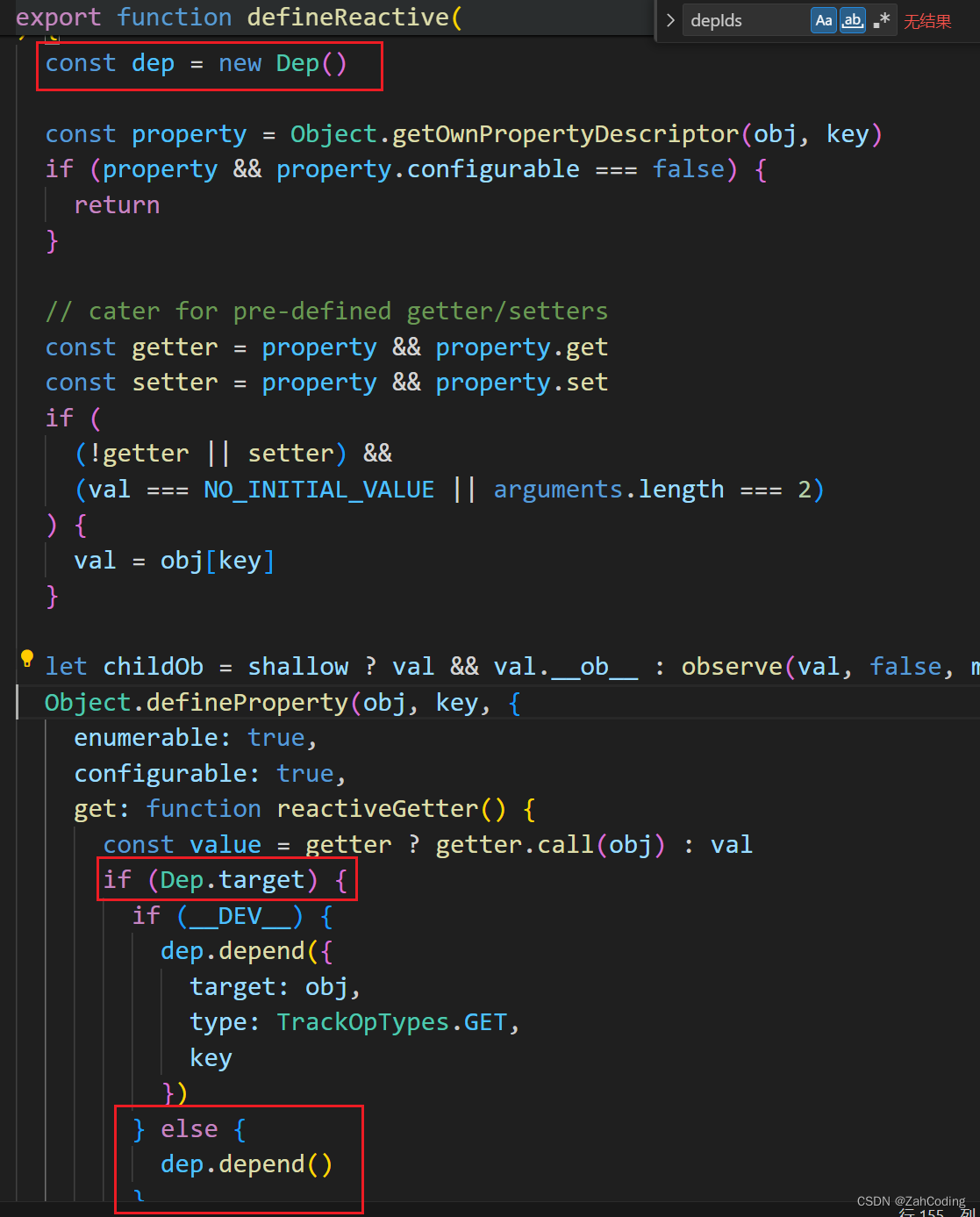
dep.depend实际上就是给watcher里绑上对应的dep
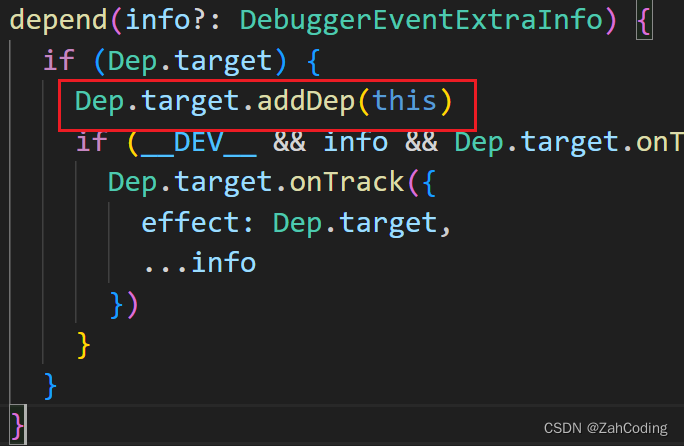
基本数据类型的依赖收集:
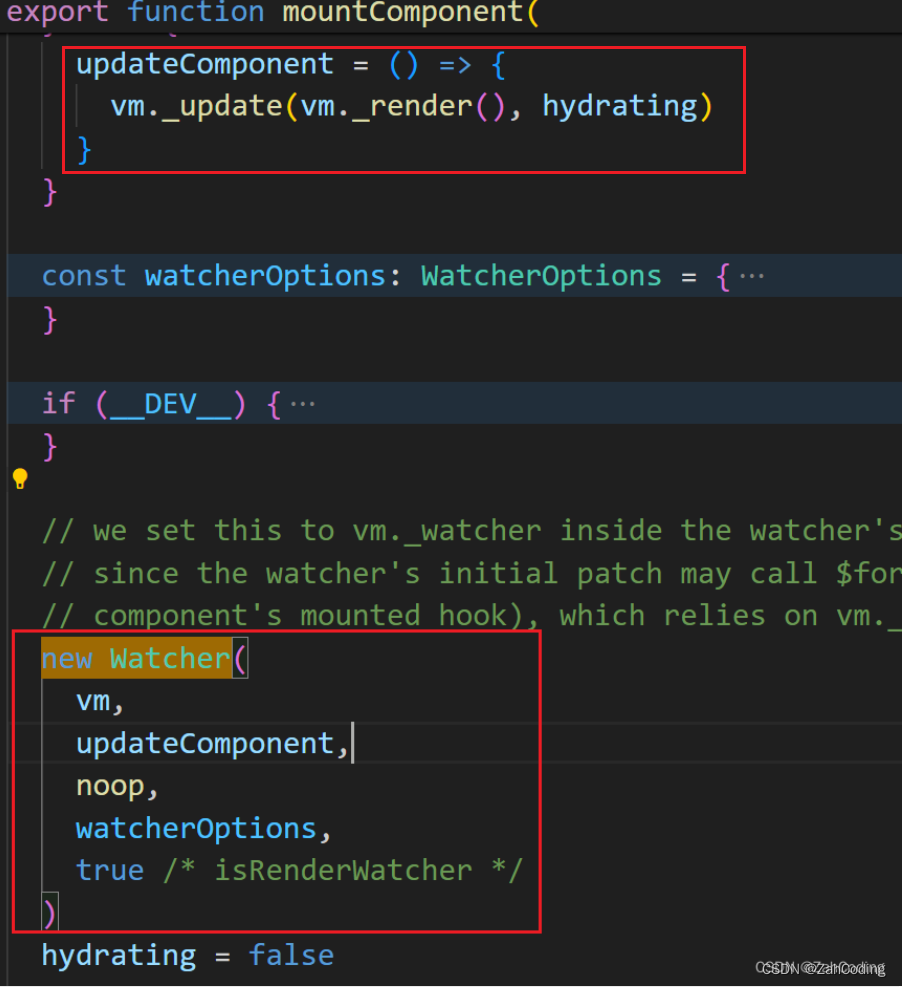
以页面初次渲染来举例,数据拦截完成后,到了渲染阶段时,会执行mountComponent时,执行时本身就会创建一个watcher
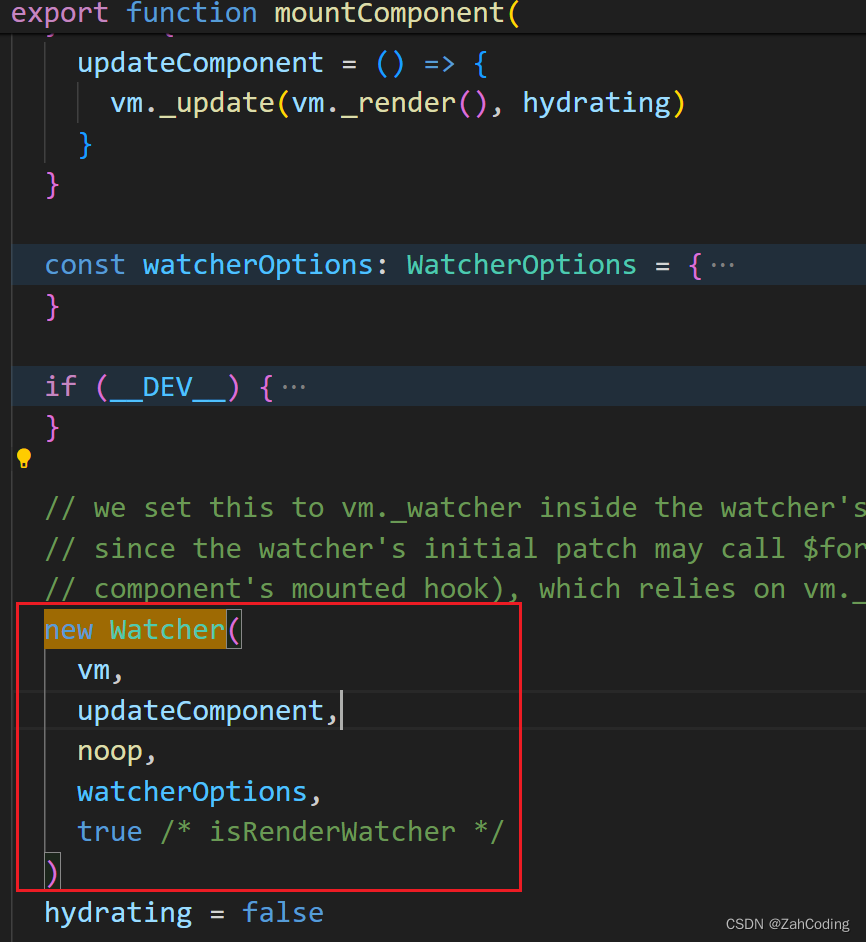
而走new Watcher构造函数时,就会自调用一次get方法进行计算,get里执行的getter就是传入的updateComponent方法,updateComponent实际上就是跑_s、_c等方法来把虚拟DOM变成真实DOM渲染到页面上
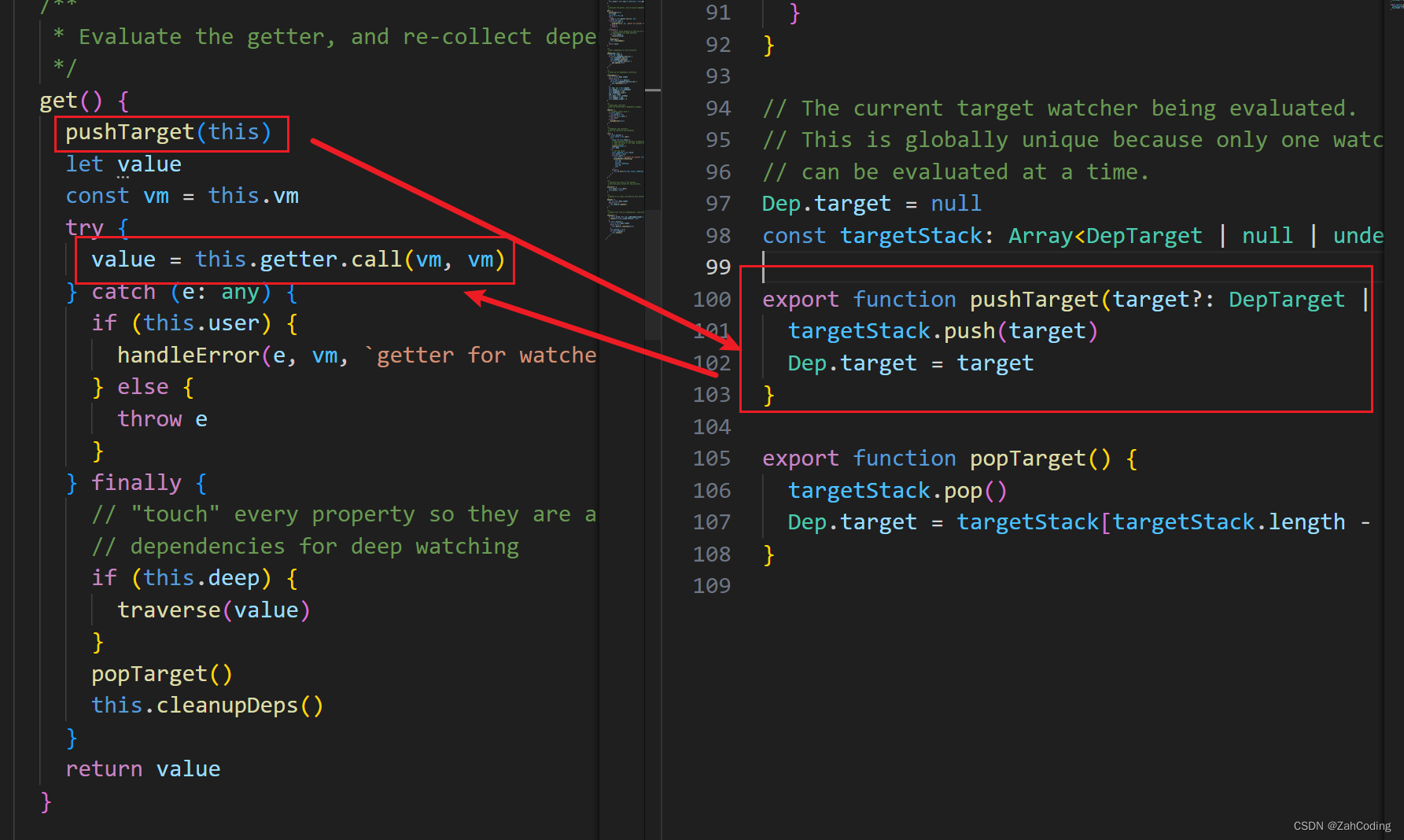
当执行get方法时,首先要执行pushTarget方法将这个watcher实例暂存到Dep的原型上
页面渲染,那么getter执行的方法就是updateComponent,也就是把虚拟DOM渲染成真实DOM
假设渲染的模板字符串为带有{{ msg }},这就意味着要访问data上的msg属性,这样就会触发msg的get拦截,在get拦截中会调用它的dep的depend方法来收集依赖
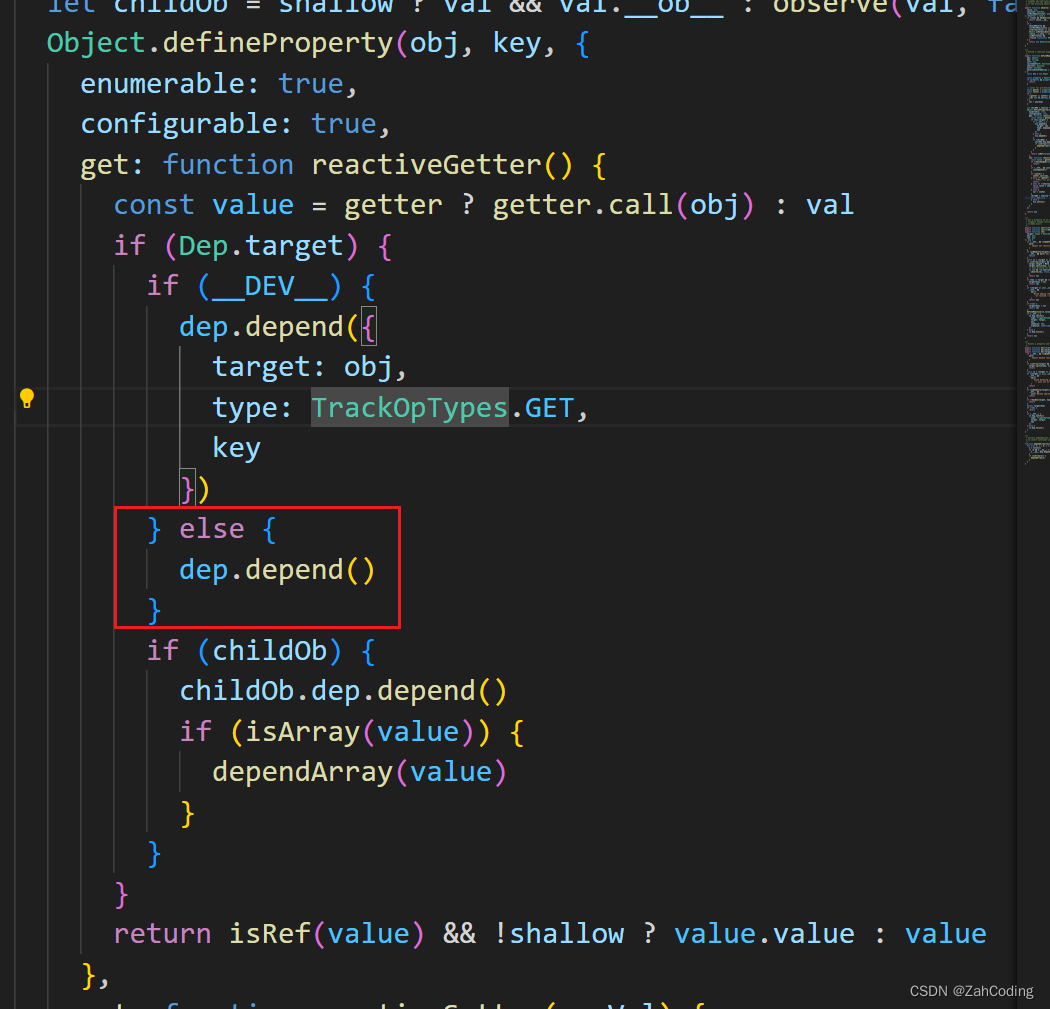
depend方法调用了watcher实例的addDep,在watcher的addDep方法里就完成了 “dep挂载到watcher实例上” 的操作与 “watcher绑定到dep中” 的操作
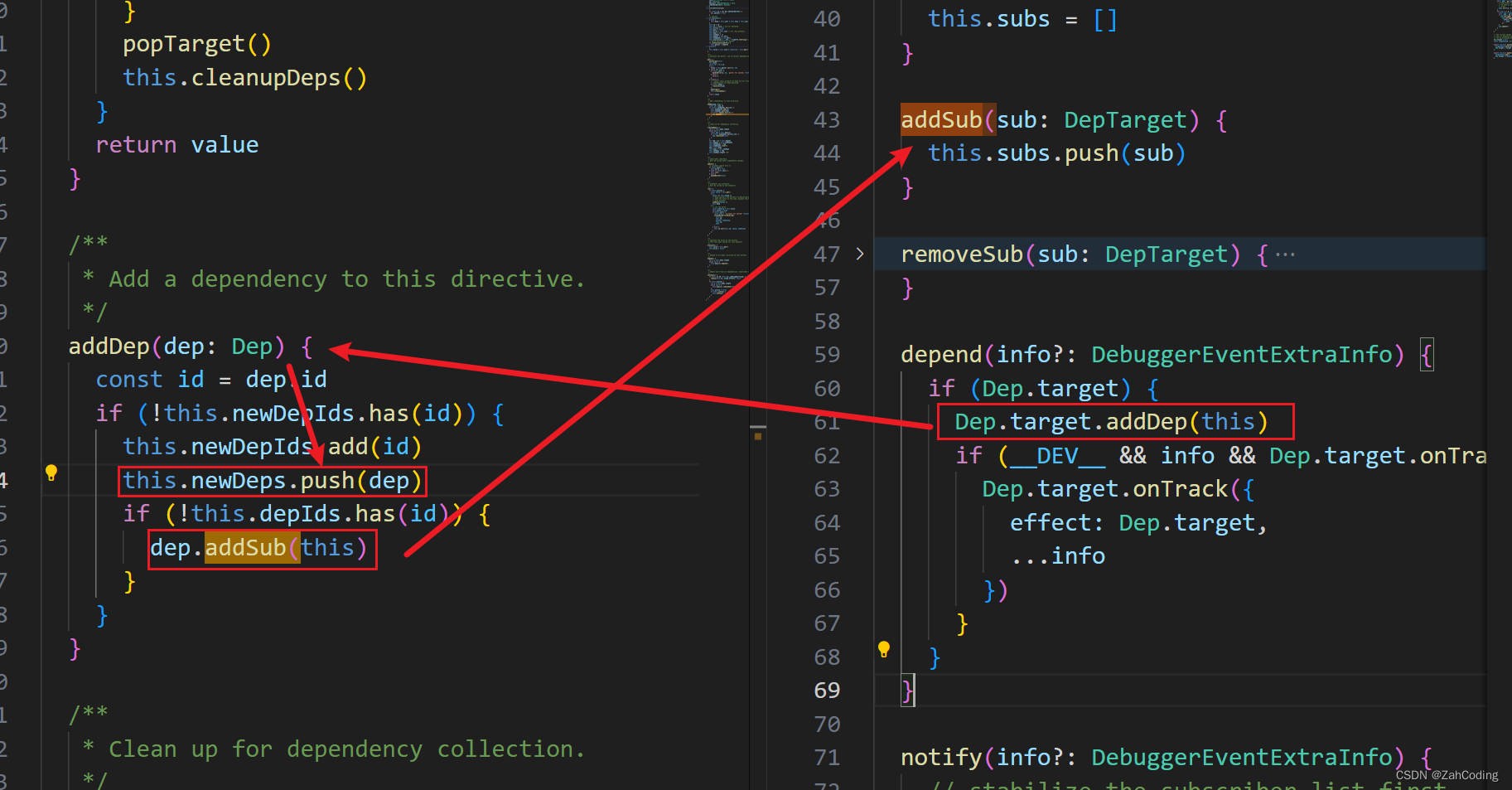
执行完对每个属性的依赖收集后,调用popTarget将当前绑定的dep.target给pop出去
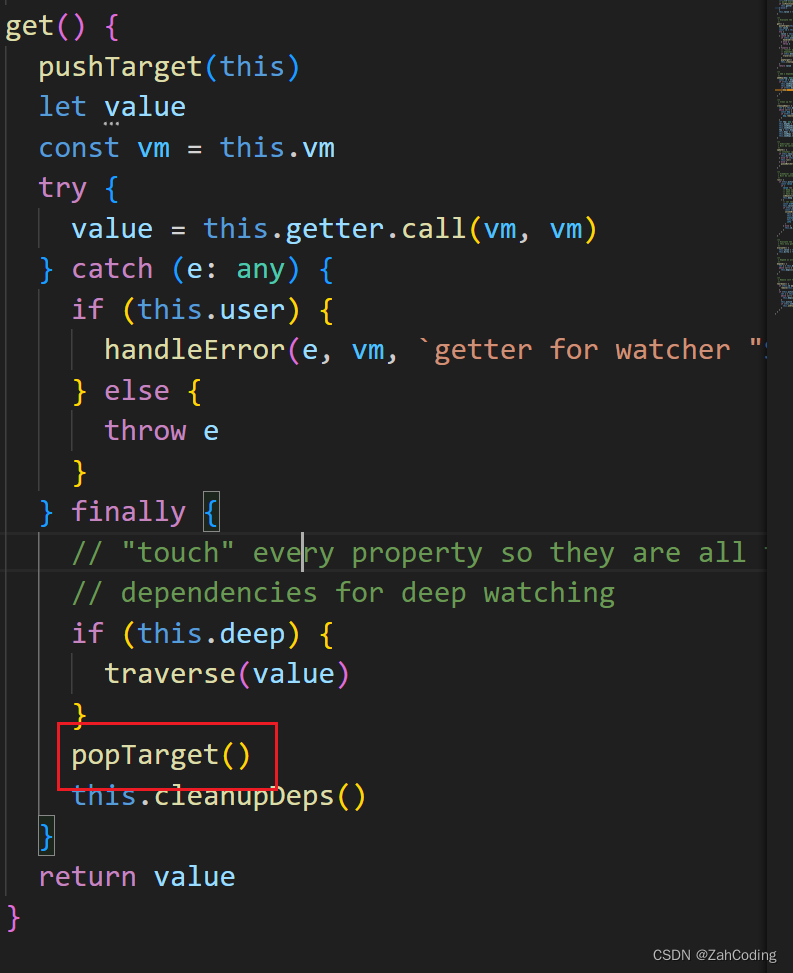
这样就完成了对msg属性的依赖收集与页面渲染,页面会自动用msg对应的值替换模板字符串{{msg}}
这里主要是通过
_xx的方法来实现的,至于是哪个,不确定
对象的依赖收集
对于对象而言,比如{{ info.name }}}实际上就是对info里的name和其他属性都进行一次observe的递归
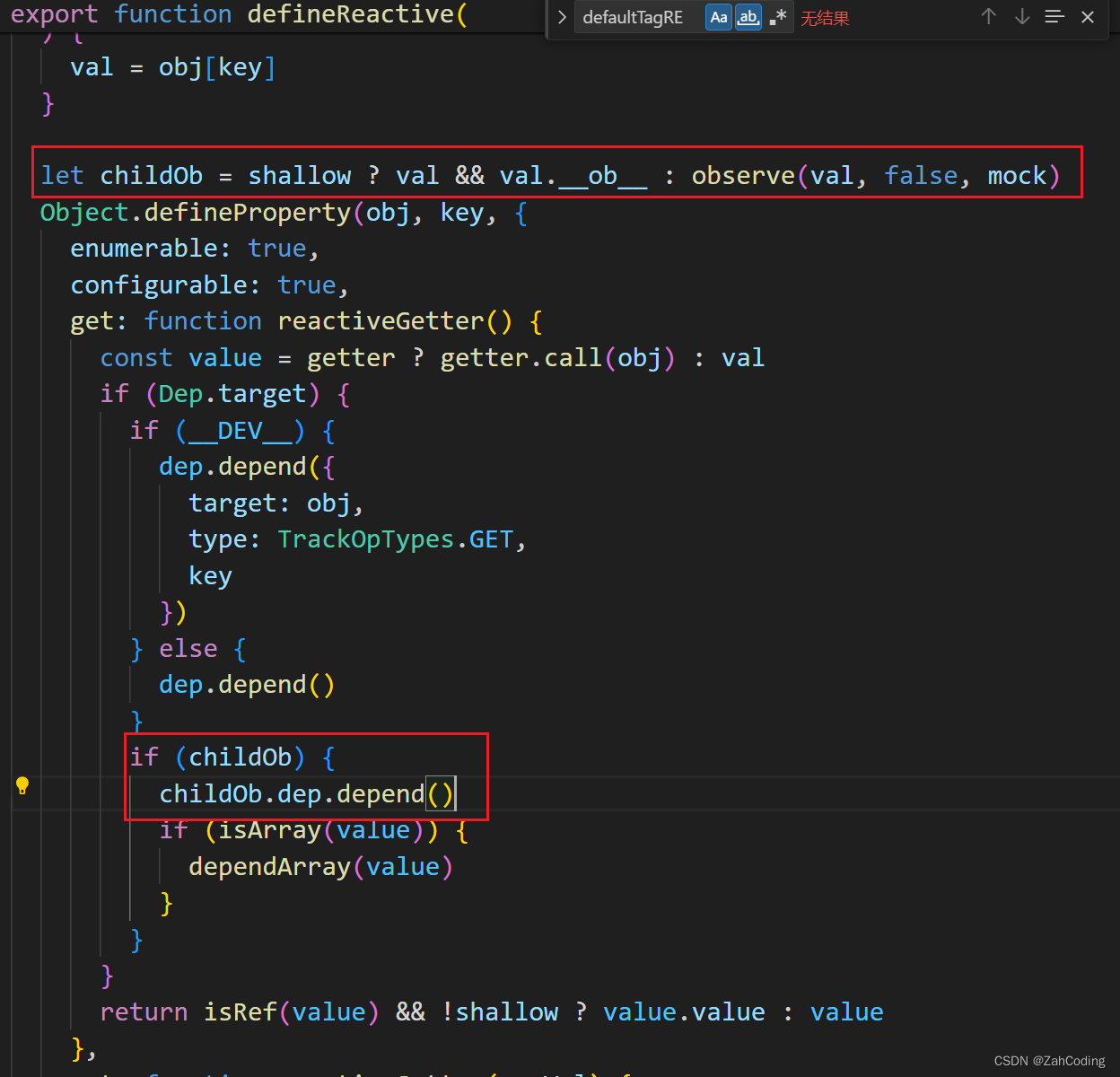
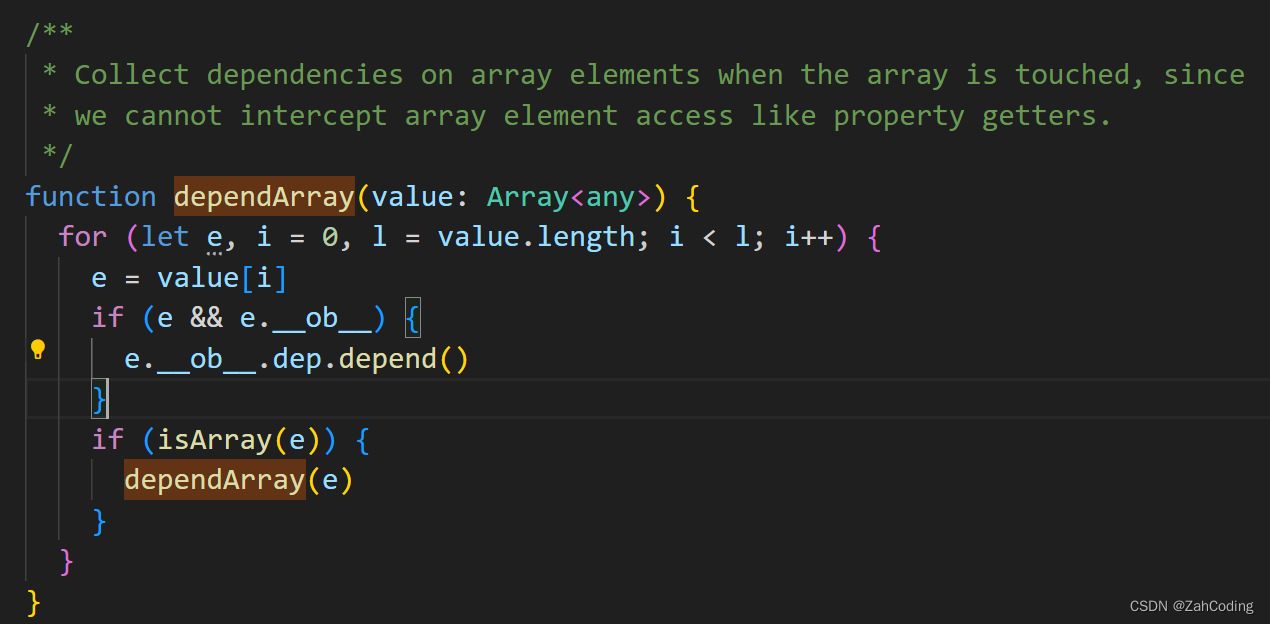
可以想到,他既对info对象的每个属性进行了深层拦截,也在触发info对象的get时,同时将对象内的各个属性作依赖收集(childOb.dep.depend())
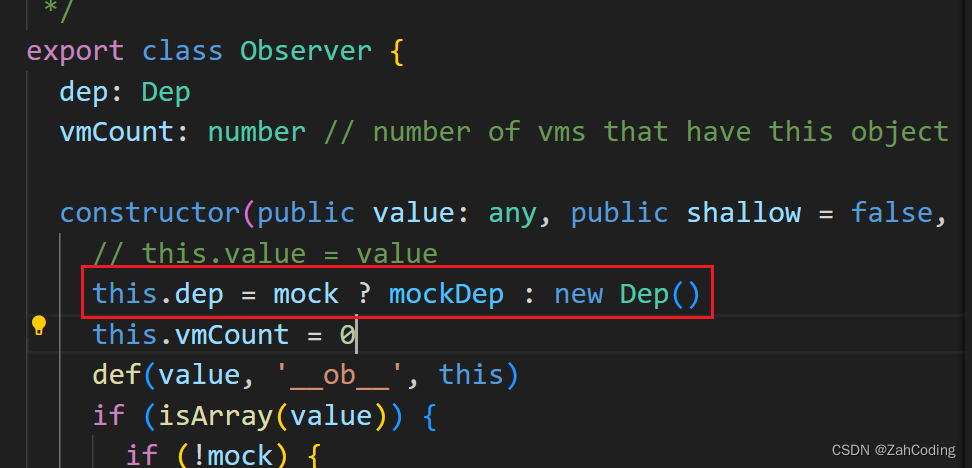
这里的childOb.dep,就来源于对Observer构造时声明的一个dep实例
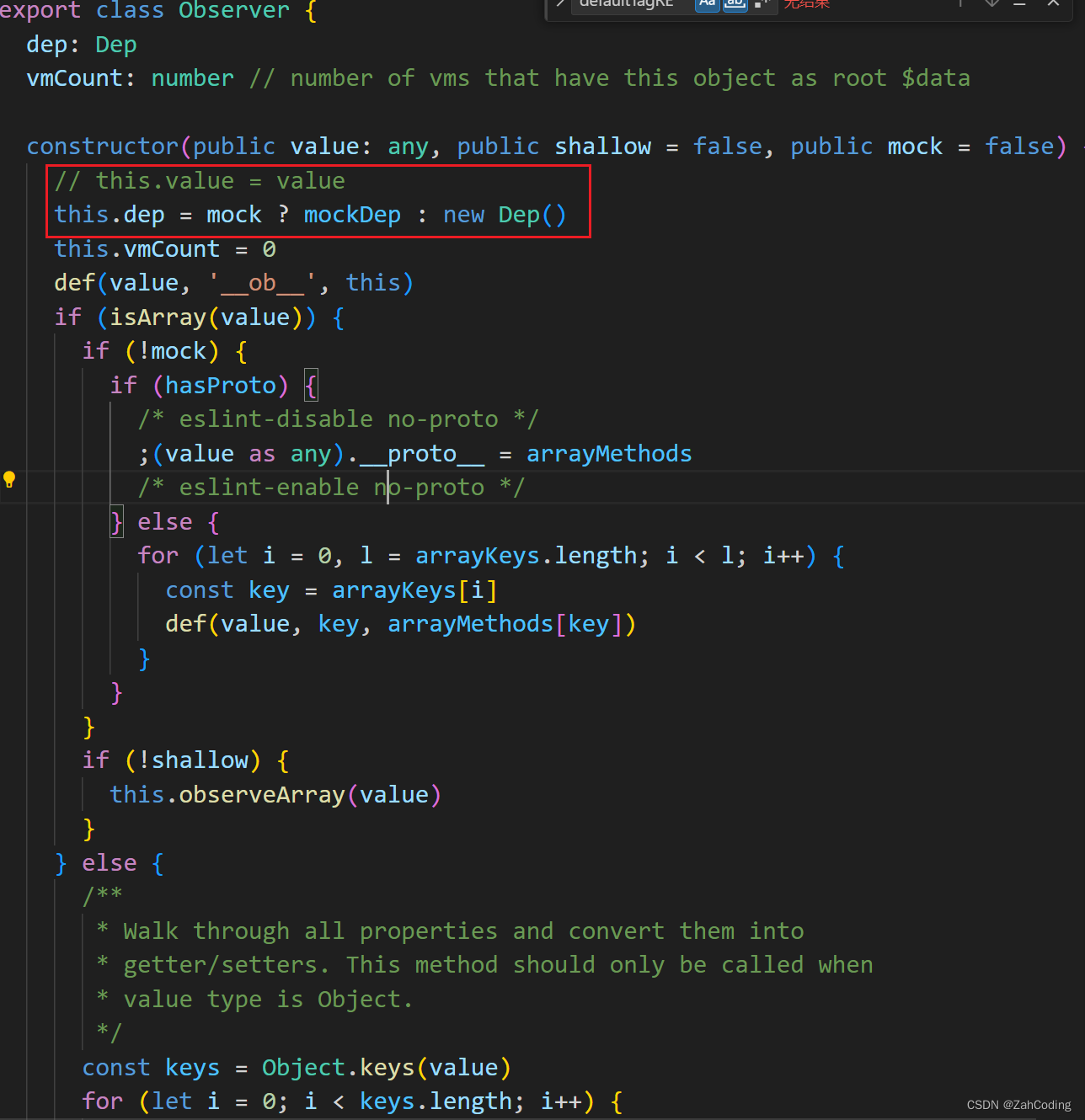
数组的依赖收集
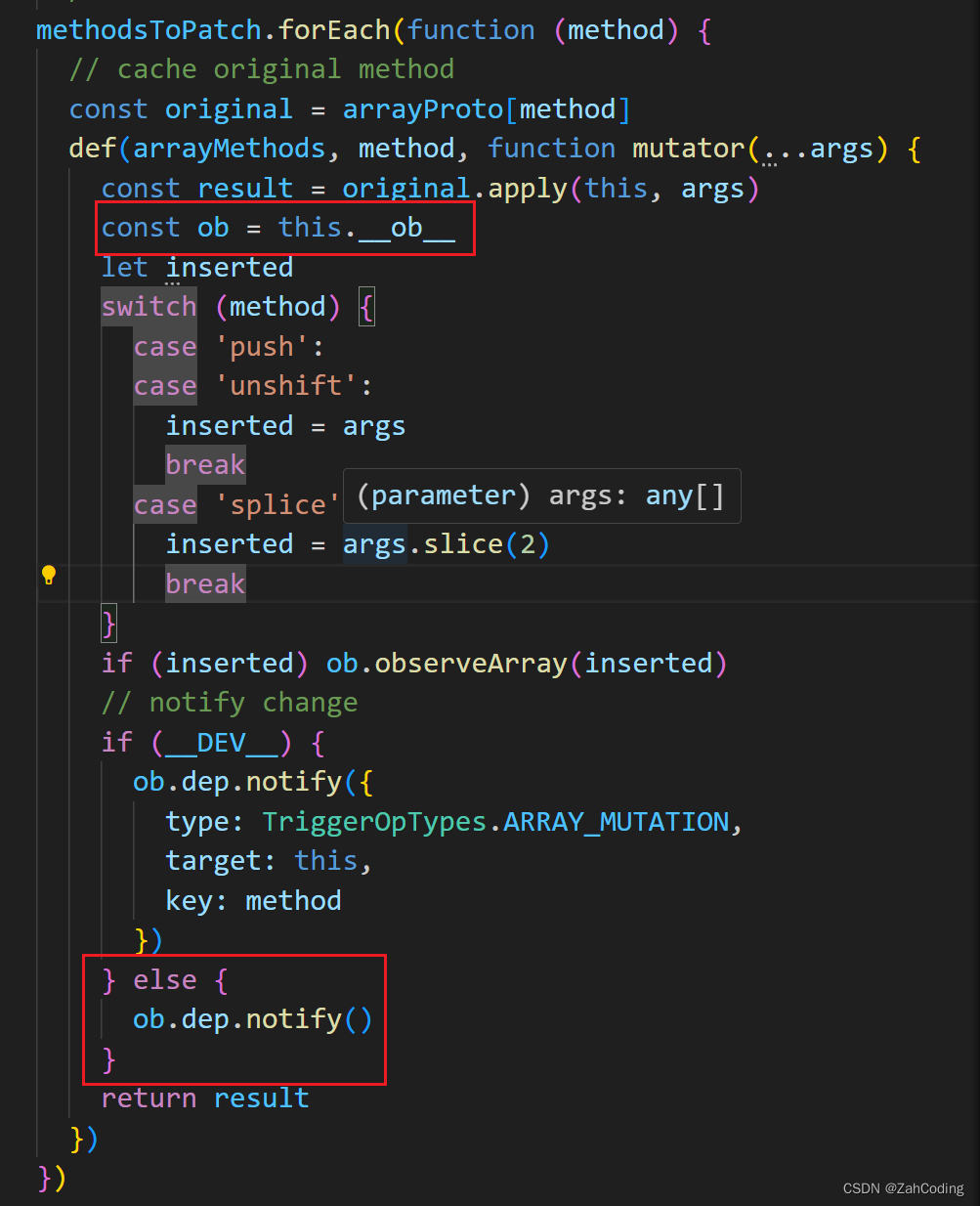
observe一个数组时,实际上就是对数组push等操作方法进行拦截,并且这里把__ob__绑定到了这个数组的原型上,值为该Observer实例
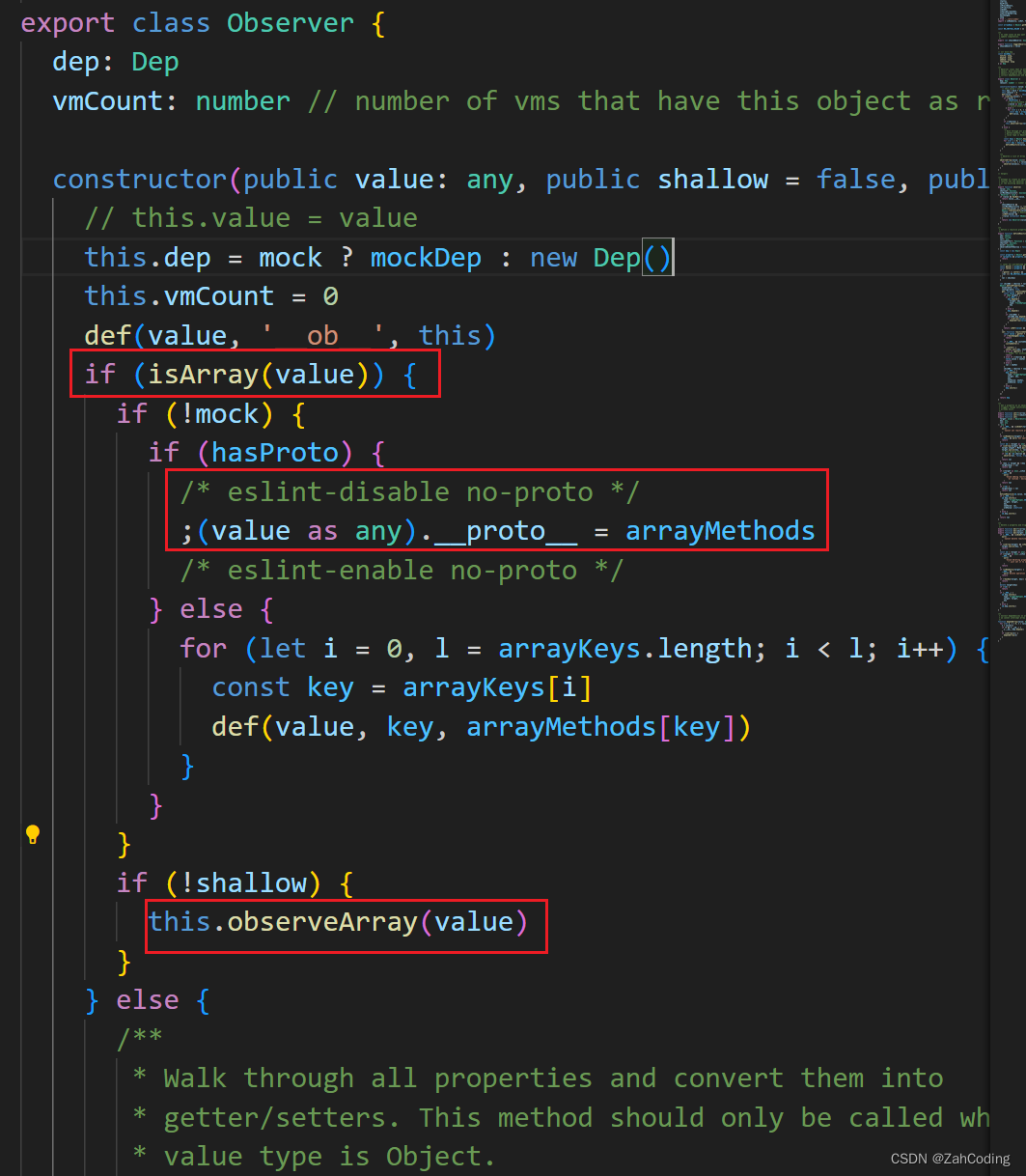
observeArray就是对数组里的每个值进行observe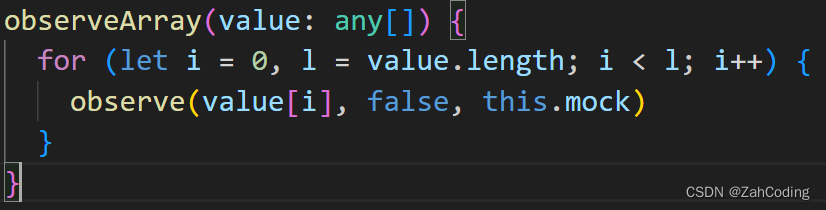
那么可以想到,对于数组内的基本数据类型,就会不符合条件从而不作任何的拦截与监听;而如果是[{a: 1}]或[[a: 1]]才会对应的进行数据拦截
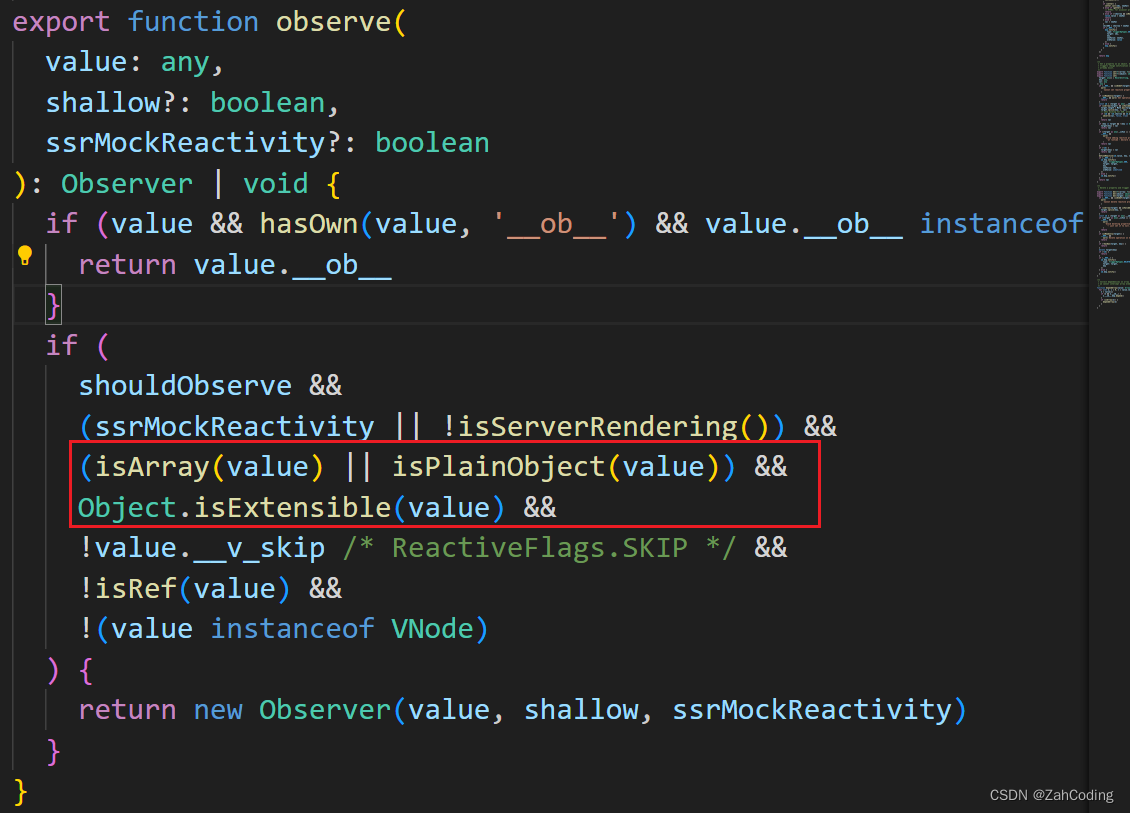
这也是为什么调用arr[1] = xx不会触发vue的监听的原因
对于下面这个例子:
data () {
return {
info: [1, 2, {a: 1}]
}
}
首先info这个数组本身会被作数据拦截,设置info = [3,4,5]时是响应式的,然后对数组内的数据进行监听,获取到内部数据的Observer,也就是childOb

这样在读取info时,除了收集info的依赖,也会同时收集数组值的依赖,调用对应的depend方法
调用了数组的push等方法时(等同于对象中属性的set),就是靠__ob__去调用dep.notify来通知所有的watcher进行更新的
这也解释了为什么Observer本身要声明一个this.dep = new Dep
异步队列处理与nextTick
发布订阅模式是只要发现修改,就进行更新,所以为了节省计算性能,应该用一个机制来处理多次修改的情况,让更新只更新一次
data.push(1)
data.push(2)
data.push(3)
data.push(4)
上面这段,如果不处理,那么会更新4次,即调用watcher里的getter4次
当修改数据触发set或者调用数组的push等方法时,便会触发dep.notify,通知所有watcher进行更新
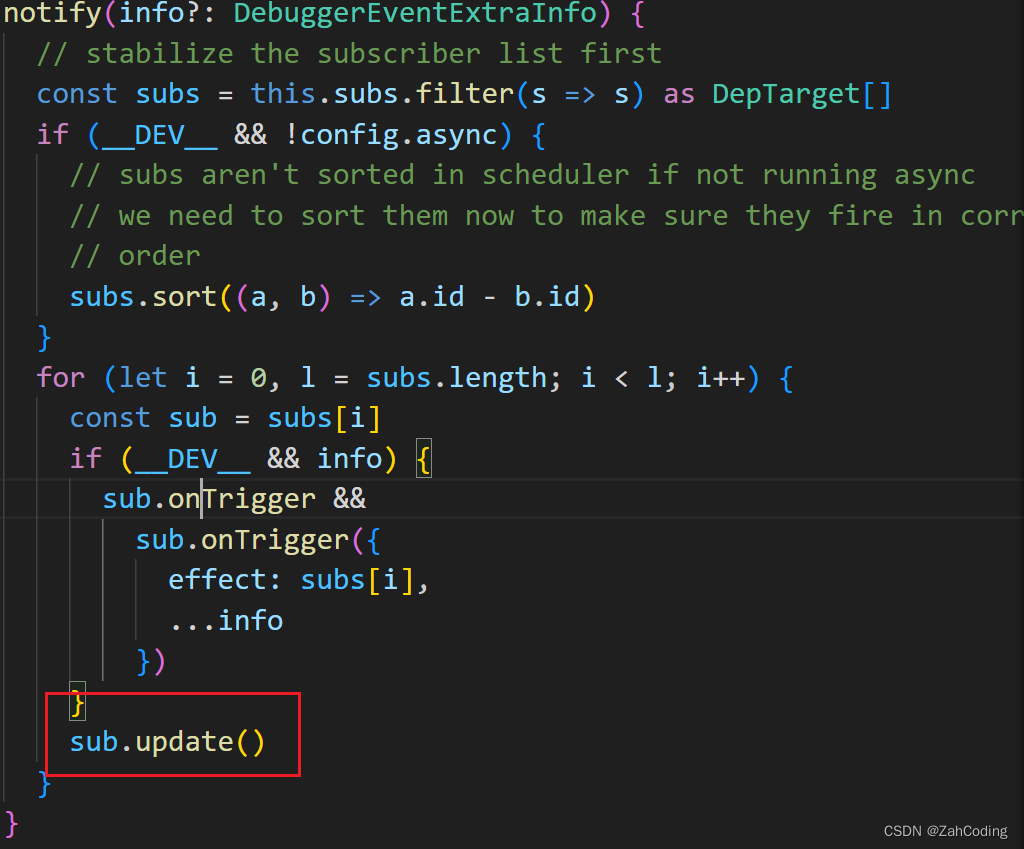
在Watcher的update方法里,正常情况下会执行queueWatcher
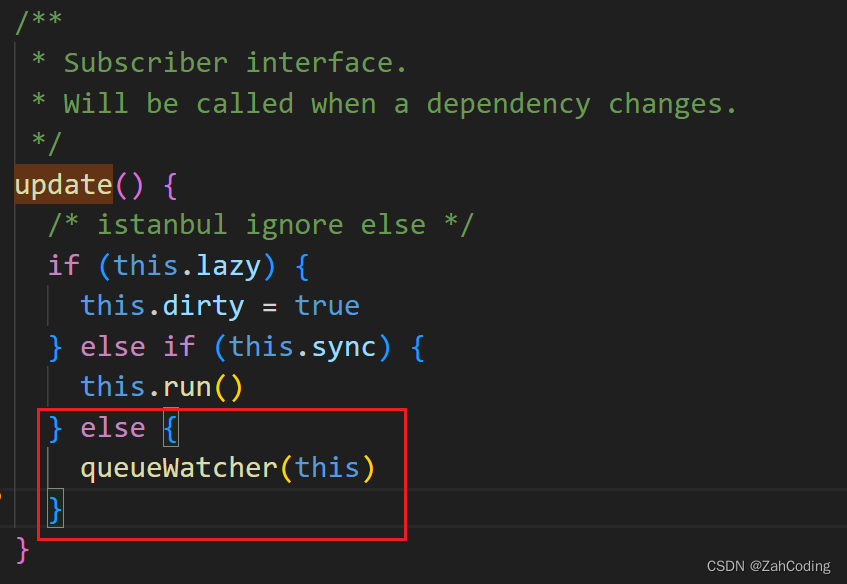
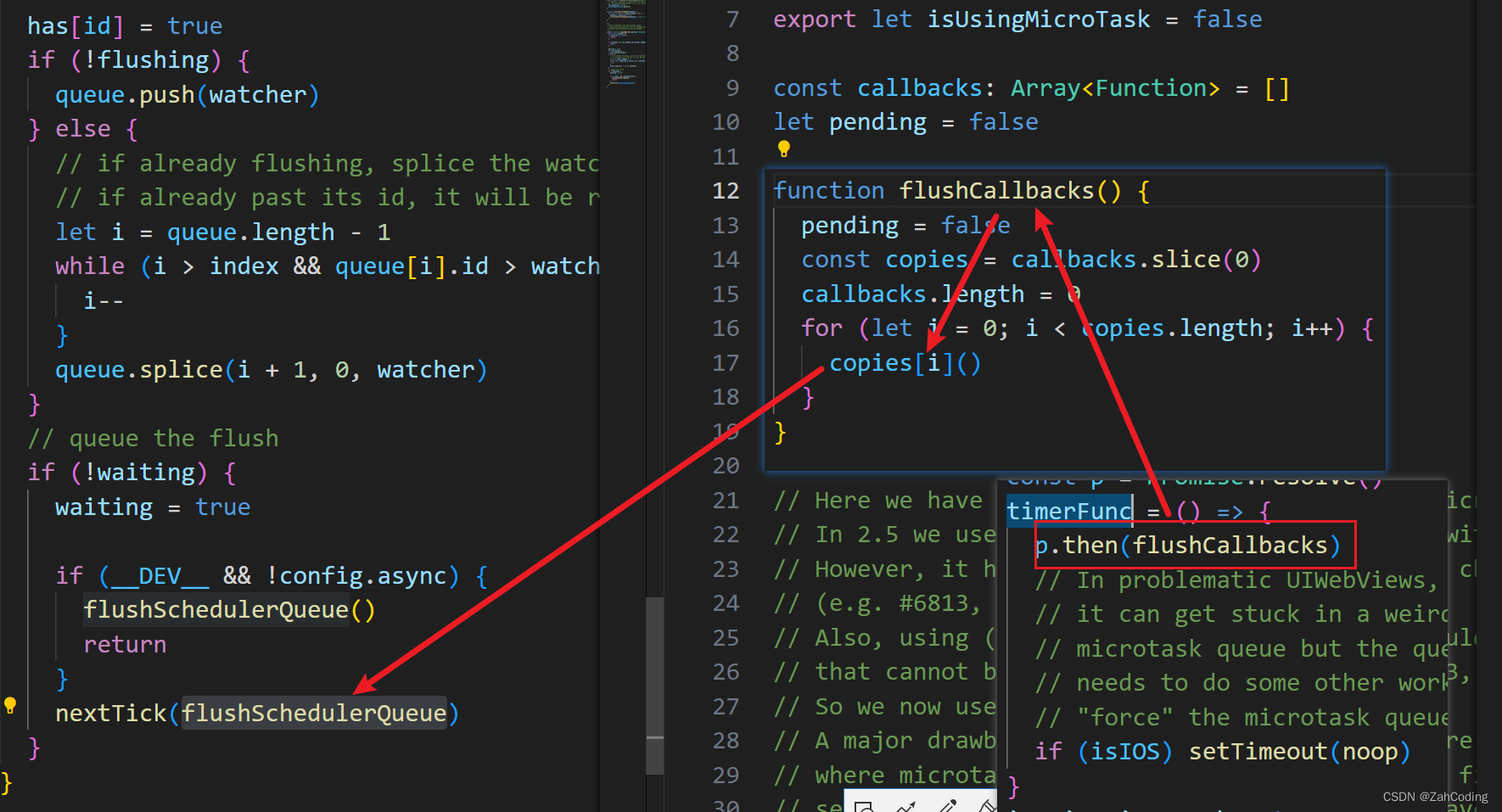
queueWatcher实际上是将watcher放入一个队列中,以id区分,并在最后通过nextTick来执行队列中的所有watcher,watcher调用的是run方法
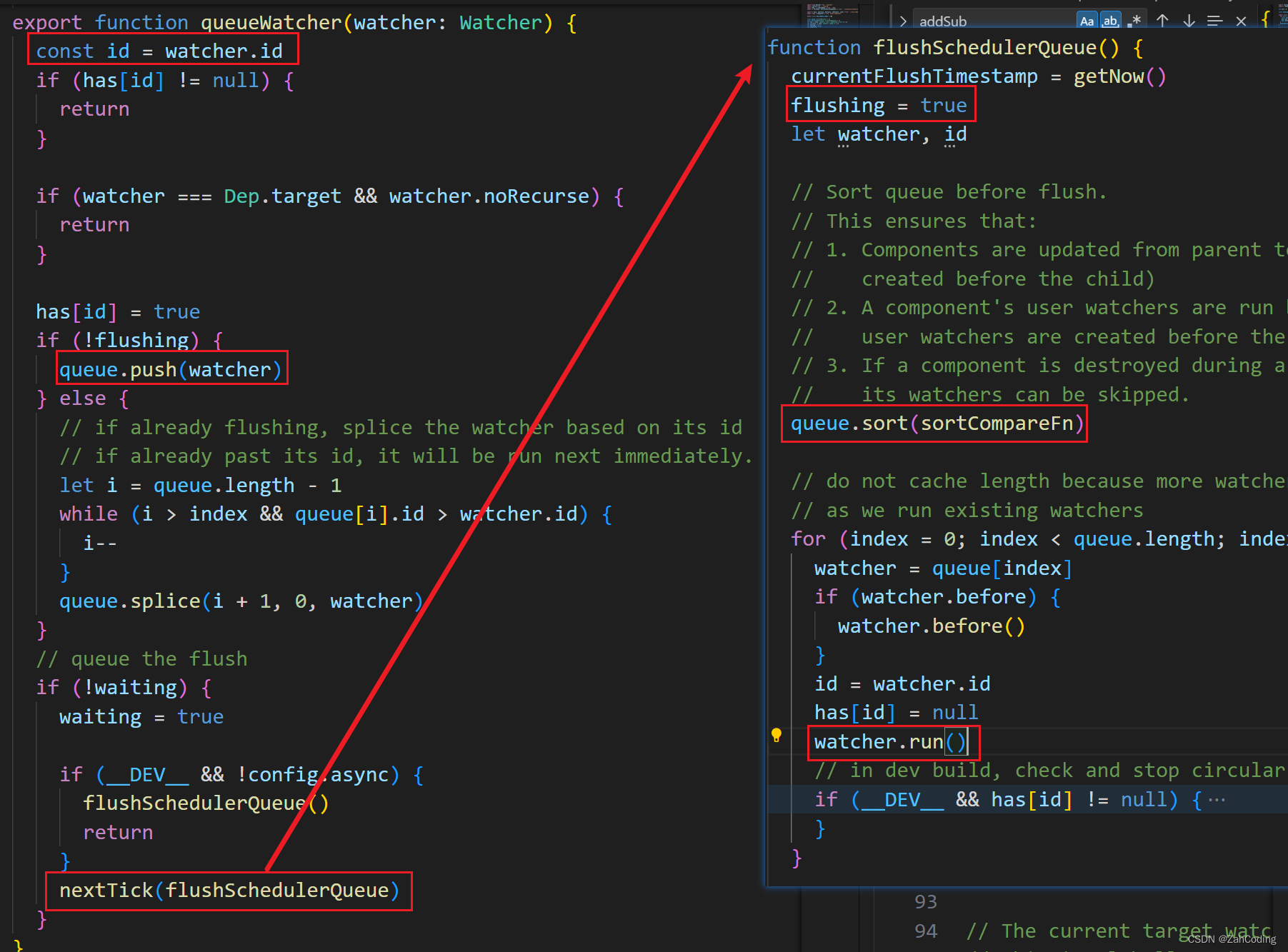
先看run方法,暂时只关注第一句,执行的就是getter而已,即触发视图的计算,下面的是watch对应的回调
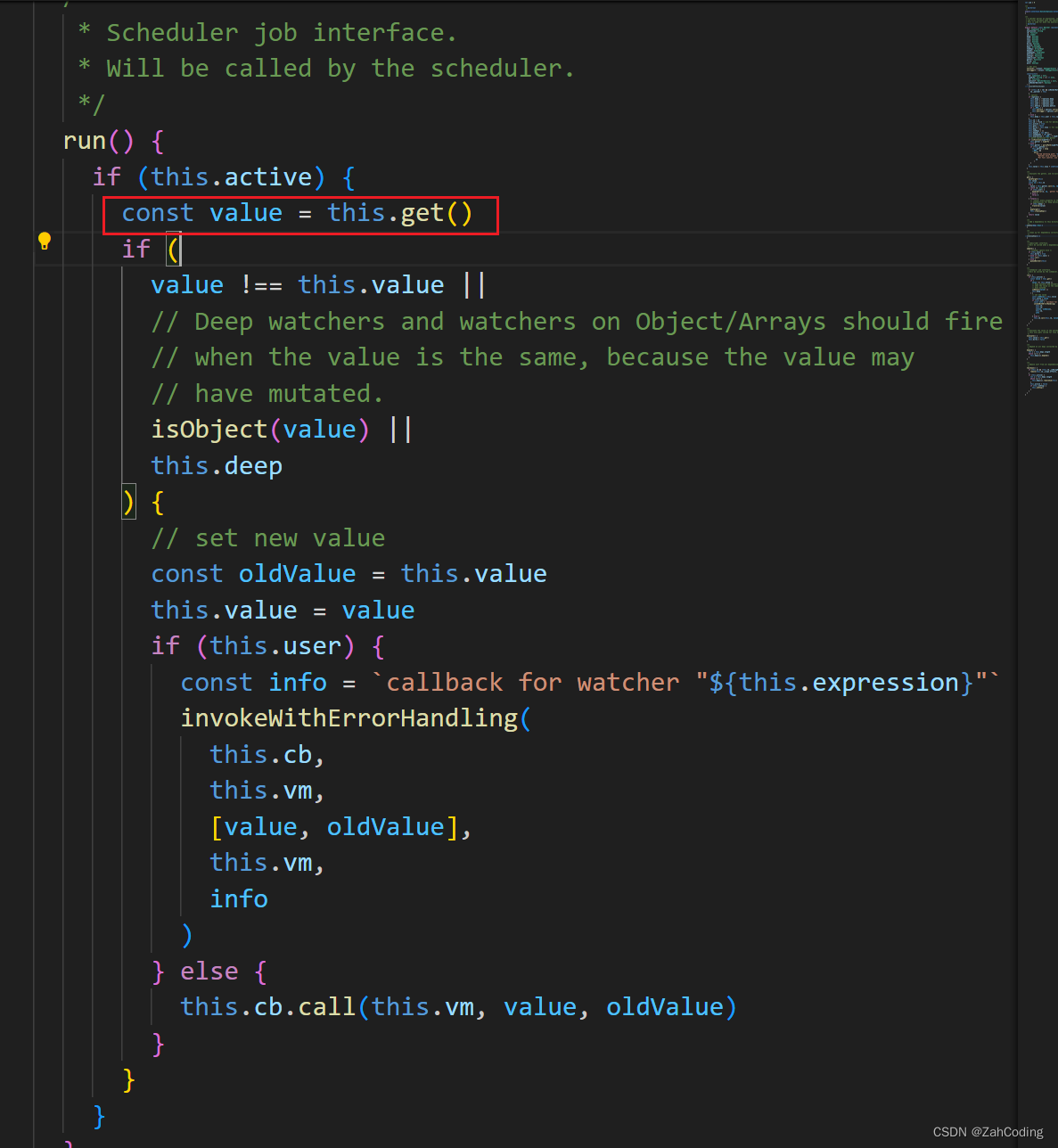
由于watcher已经在queueWatcher中去重了,所以每次run都是特定的唯一watcher进行run,即更新视图
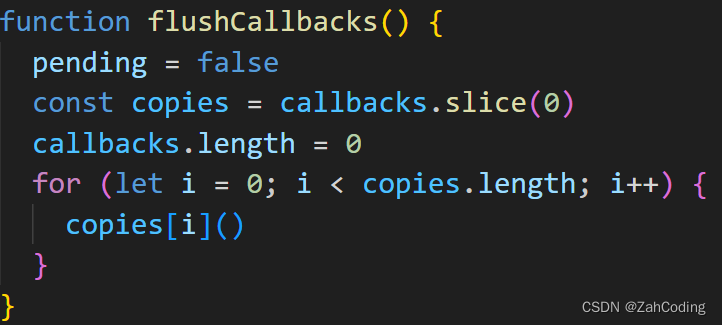
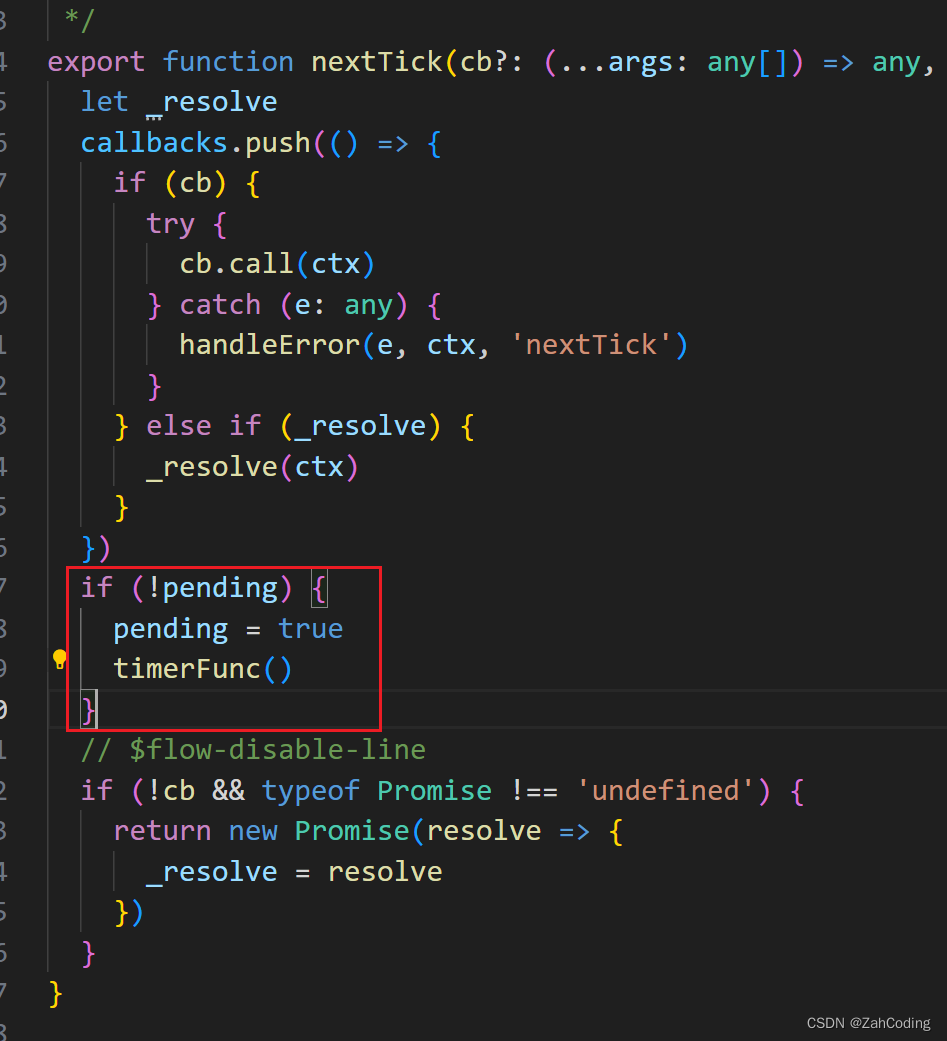
flushSchedulerQueue 是放到nextTick中执行的,nextTick通过异步的方式来对传入的callback进行调用
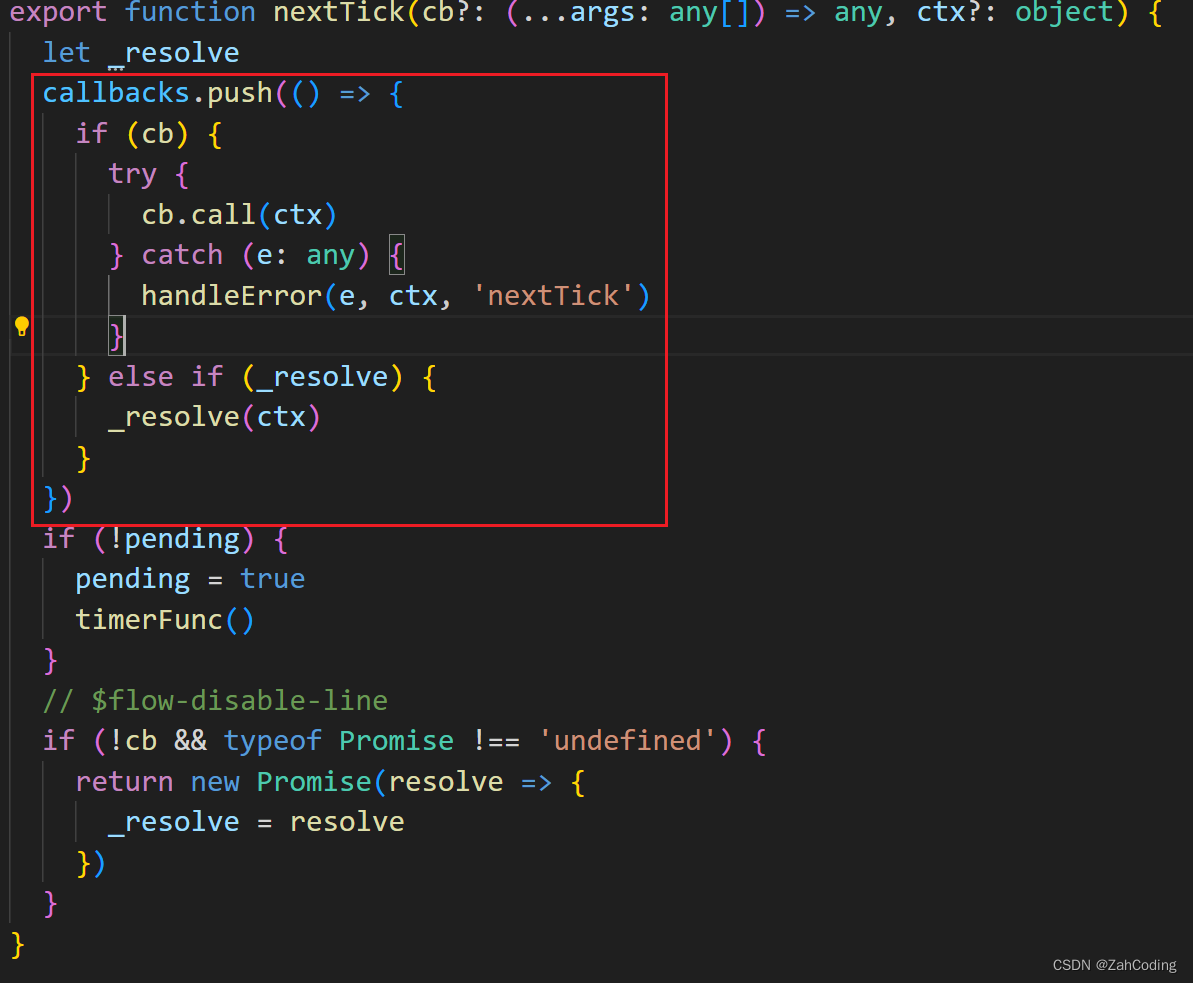
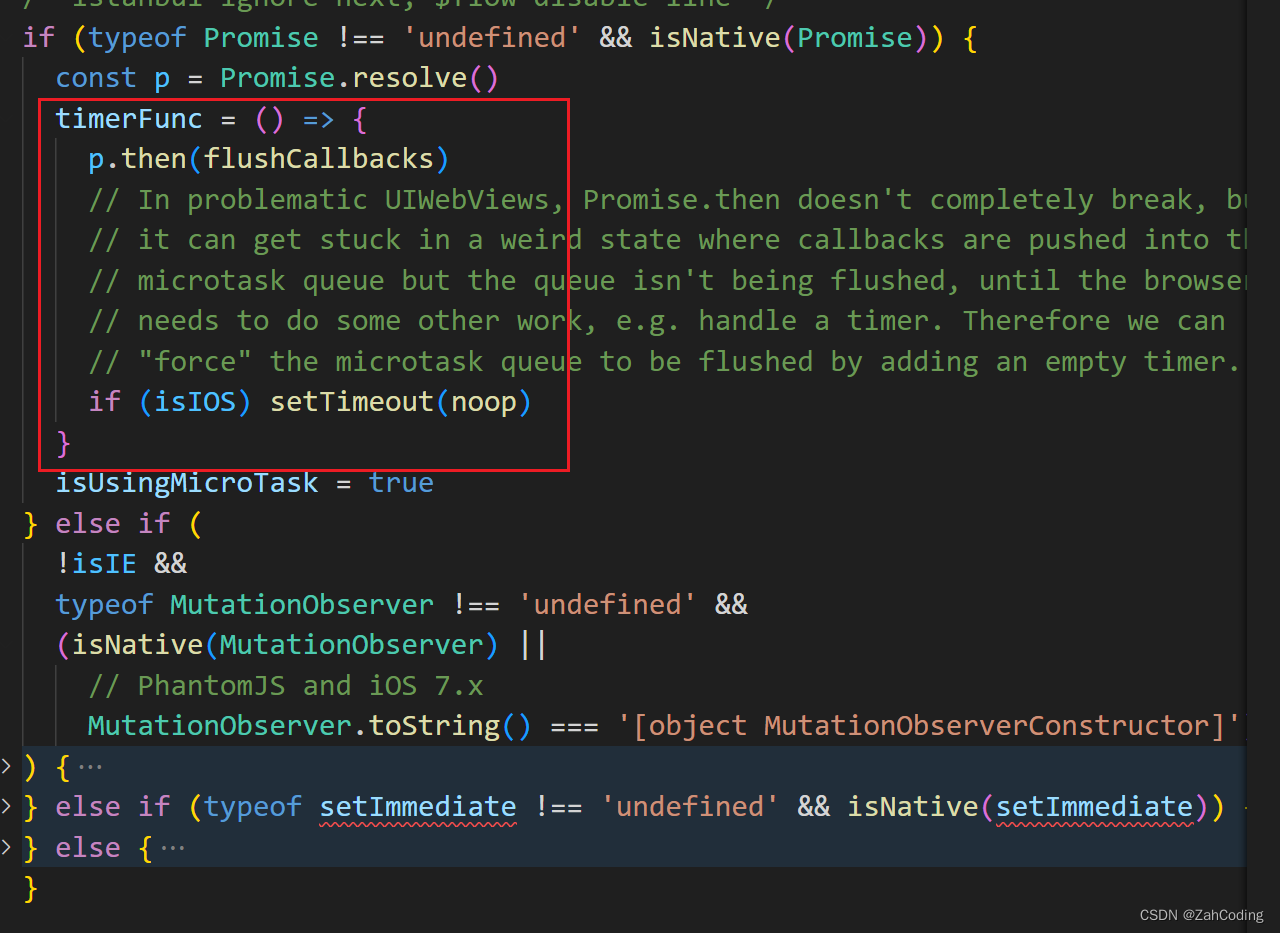
timerFunc是提前实现的,根据浏览器环境的支持与否,使用Promise > MutationObserver > setImmediate > setTimeout来实现异步调用callbacks
举个实际的例子结合事件循环机制来讲:
// 代码操作
methods: {
someMethod () {
this.arr.push(1)
this.arr.push(2)
this.arr.push(3)
this.arr.push(4)
this.$nextTick(() => {
console.log(this.$refs.someRef.innerHTML)
})
}
}
// 页面
<div>{{ arr }}</div>
<span>{{ arr }}</span>
比如对于上面这段代码,页面渲染之后有一个watcher,他的getter就是把div和span渲染出来;
执行this.arr.push4次,那么就调用了4次dep.notify,等价于调用4次这个watcher的update方法,也等于调用4次queueWatcher,而watcher的队列有去重处理,所以队列中只有一个这个watcher
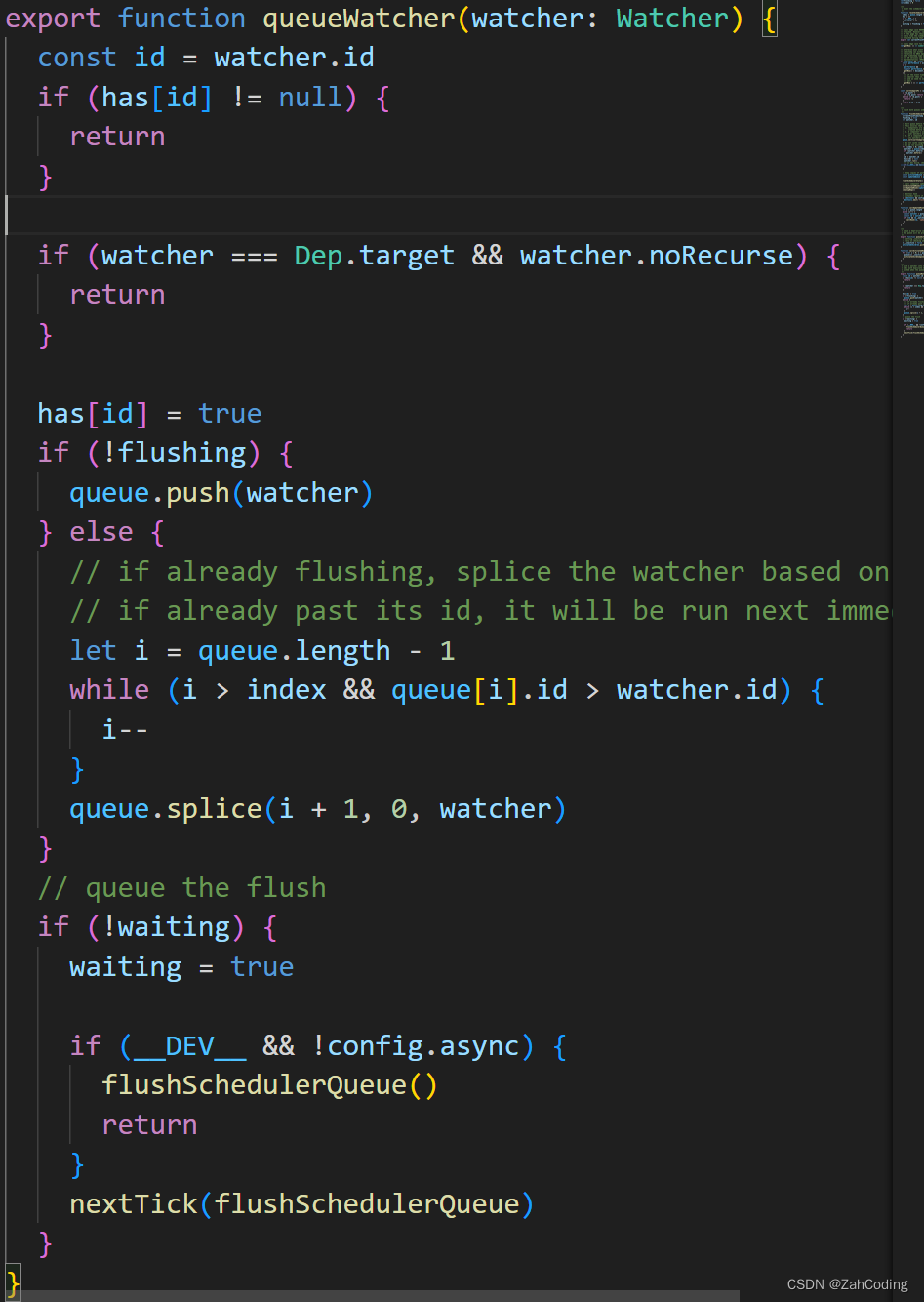
第一次进入queueWatcher,waiting是false,调用一次nextTick(flushSchedulerQueue),随后几次调用都不会进来,事件循环机制此时是主脚本(代码)执行阶段
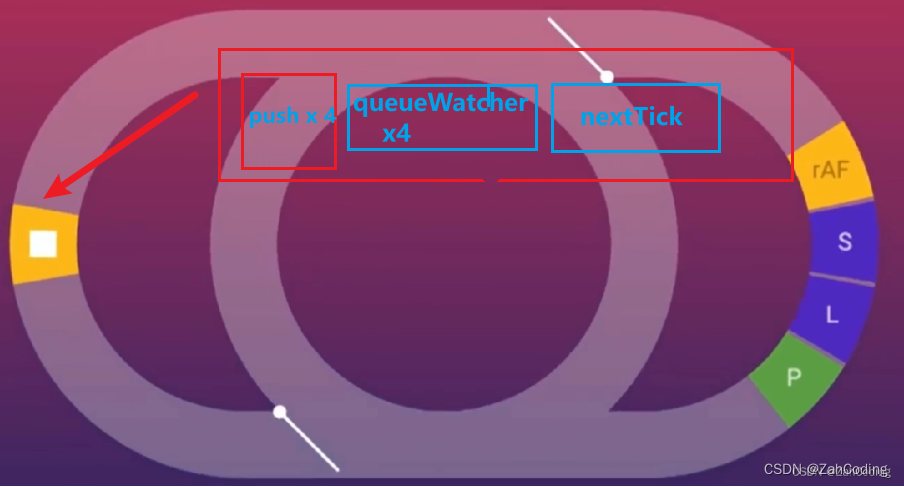
nextTick里执行了timerFunc,所以实际上的队列应该是
push x4 -> queueWatcher -> nextTick -> timerFunc -> queueWatcher(退出) -> queueWatcher(退出) -> queueWatcher(退出)
跑完上面这一段后,退出脚本执行,进入下一个事件循环
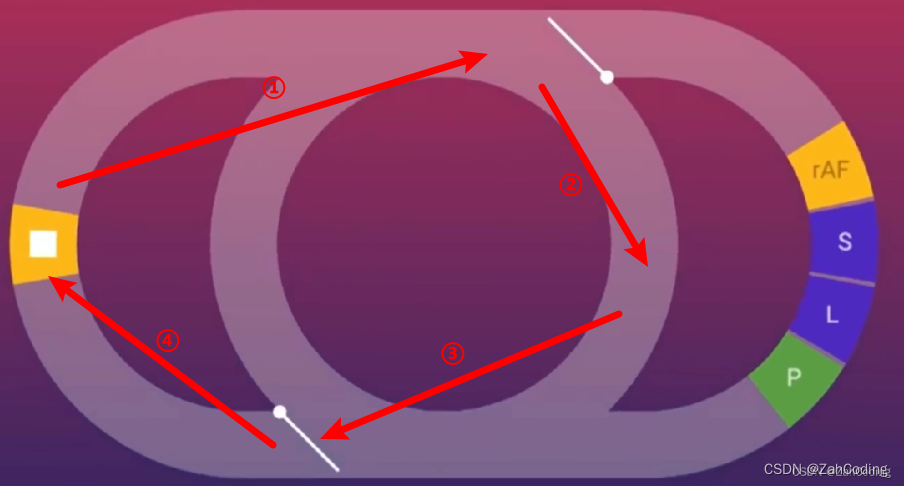
那么进入到下一个事件循环时,就会执行timerFunc里调用的微任务,也就是调用所有的callback,也就是实际地执行flushSchedulerQueue
而flushSchedulerQueue就是调用watcher队列的run来触发视图更新,这样就确保了只更新一次视图,大大节省了性能
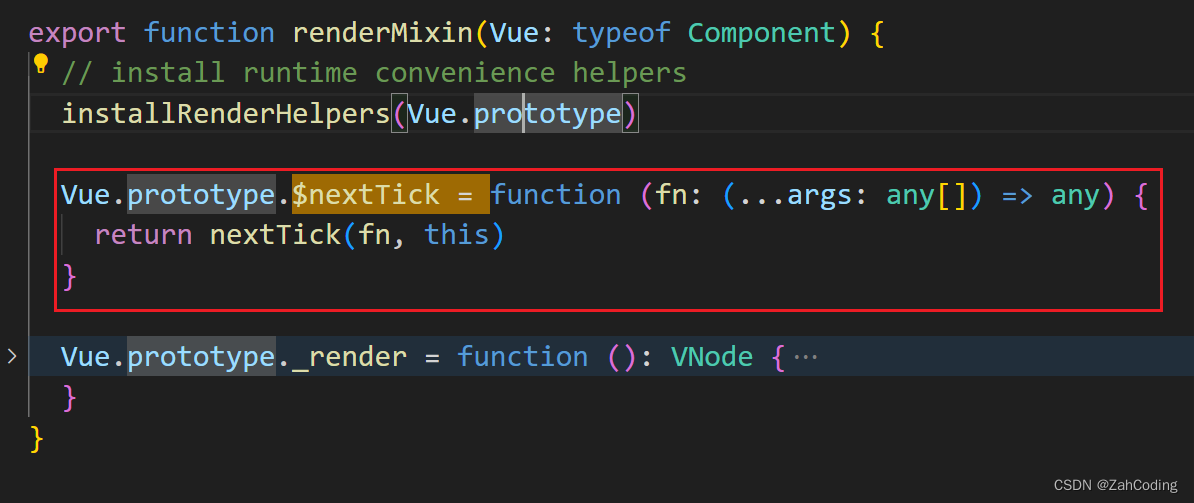
另外,用户调用this.$nextTick时,实际上也是调用nextTick并把回调放到nextTick的执行栈中处理,等到下一个事件循环中再触发更新
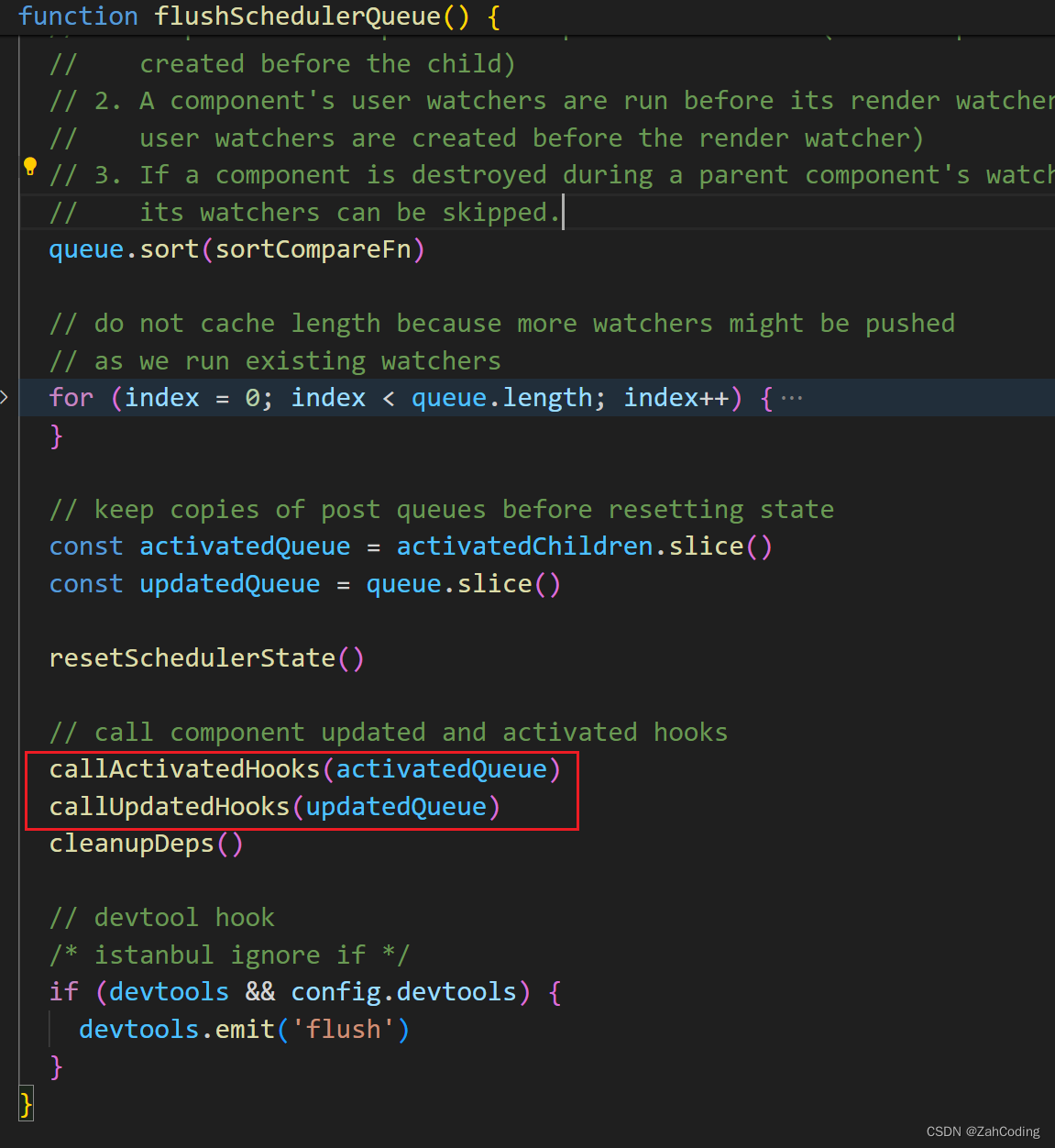
明确了flushSchedulerQueue是处理watcher的更新(遍历调用watcher的run方法)后,可以看到在这个方法中有声明周期的队列调用,即抛出activated钩子和updated钩子
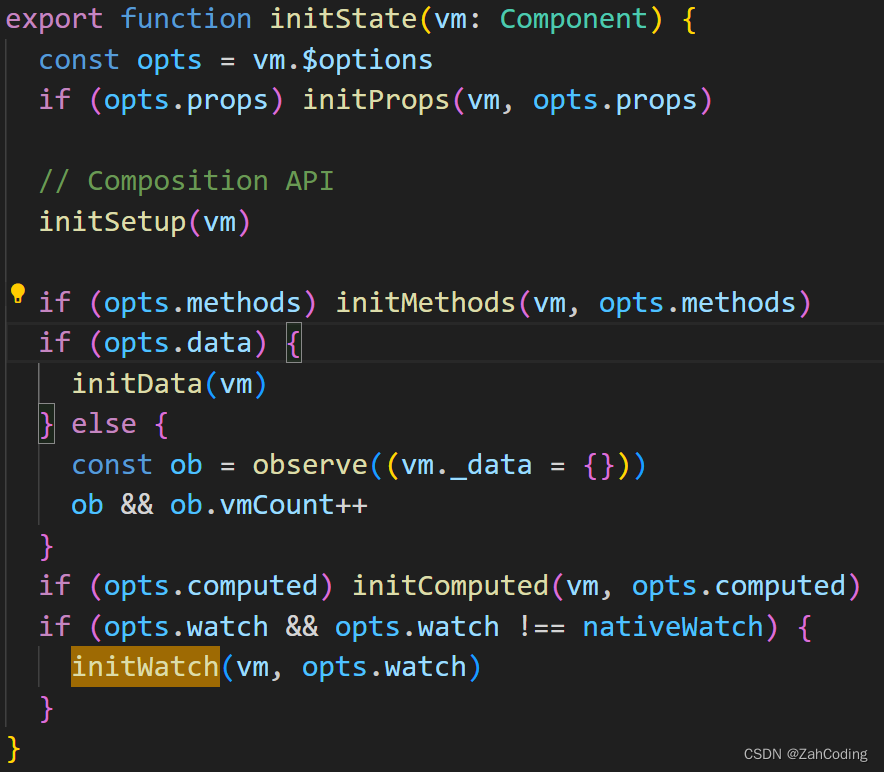
watch源码
用户使用watch时,可以传多种形式,比如:
watch: {
a () {}
// a: 'handleWatch'
// a: [handler1, handler2]
// a: {
// handler () {},
// immediate: true
// }
}
所以第一步是对同一属性的所有watch进行统一,调用的是initWatch方法
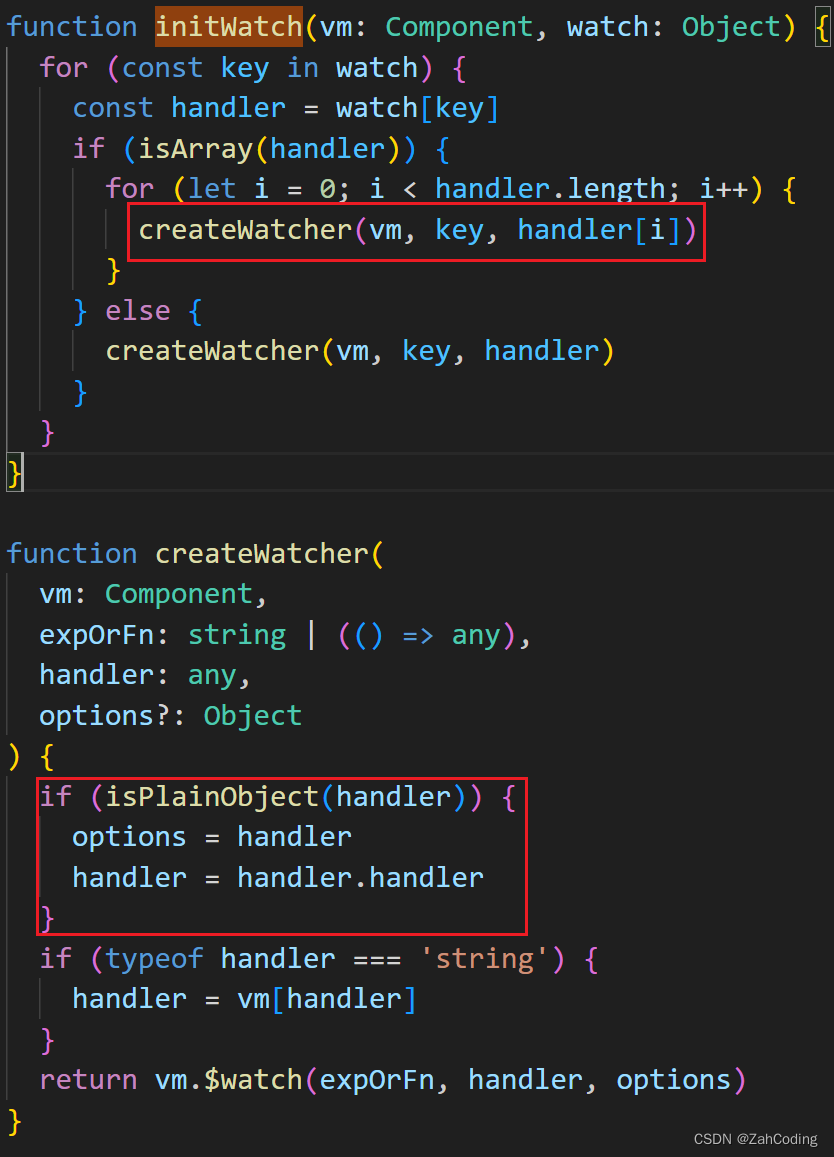
处理时,调用createWatcher进行处理,当handler传的是字符串时,实际上就是去Vue实例上获取对应的methods,然后调用$watch来实现
$watch首先判断handler是否为对象,这种情况一般在用户手动调用this.$watch时才出现
然后创建一个Watcher实例,注意它将options.user设置为了true,这是用来区分用户写的watch和渲染页面时使用的watcher的
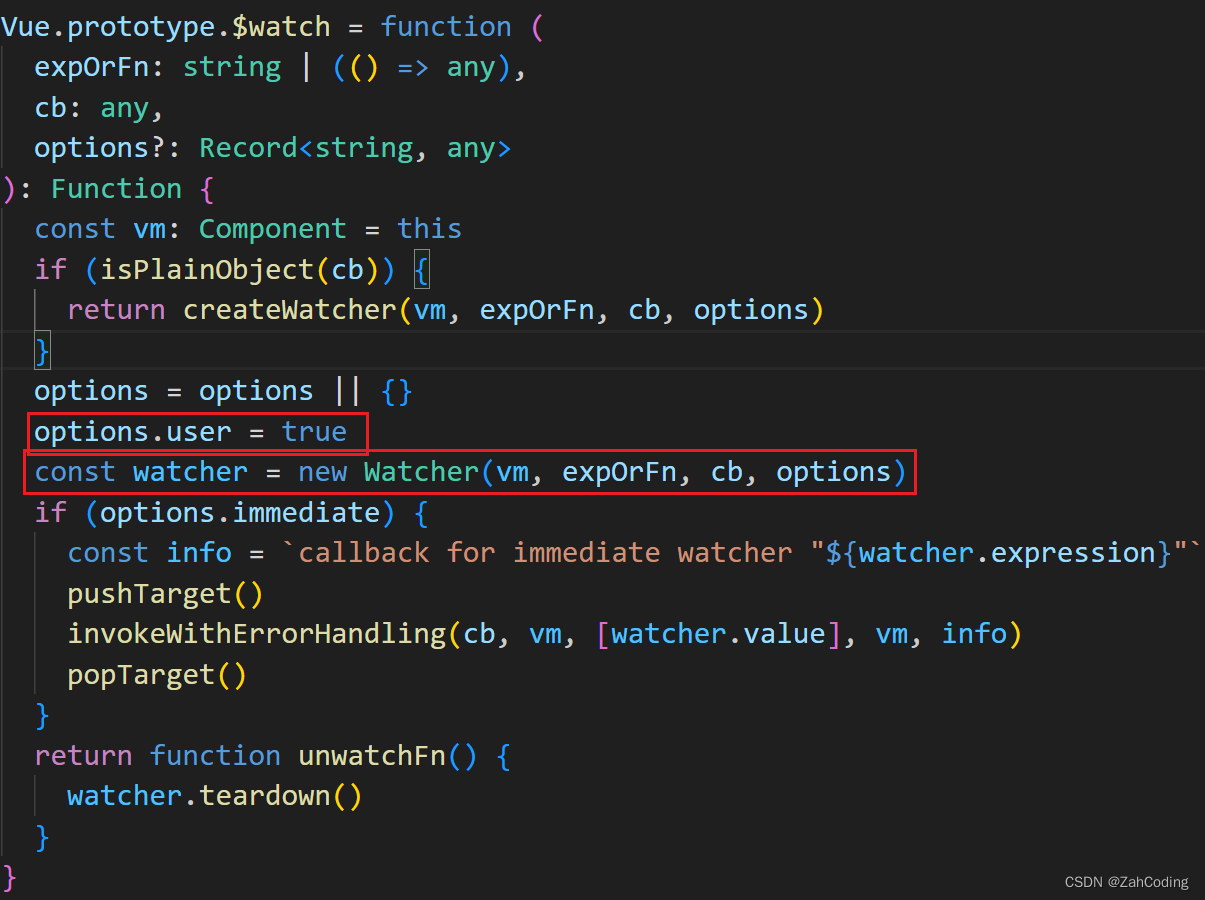
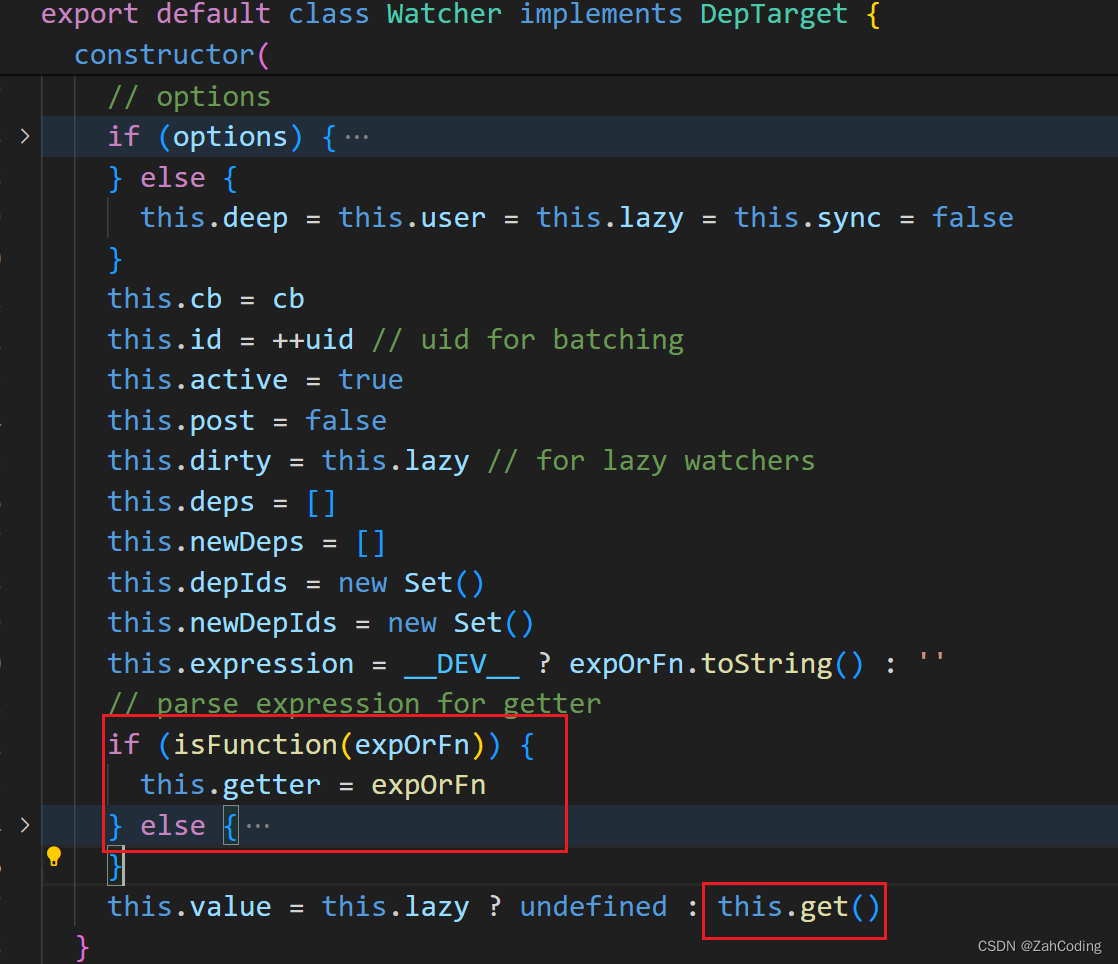
进入到Watcher的构造函数,可以看到如果expOrFn传字符串时,比如a: 'handleWatch'的情况,那么就会去Vue实例上找到这个方法来设置Watcher实例里的getter,以便后续调用
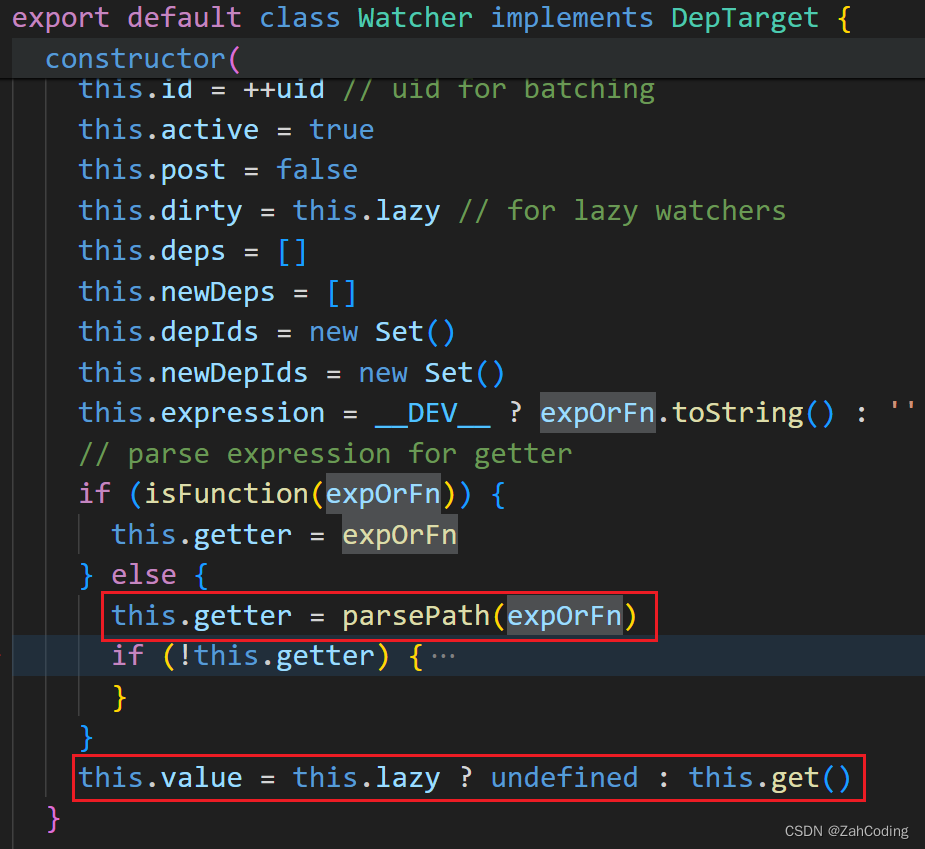
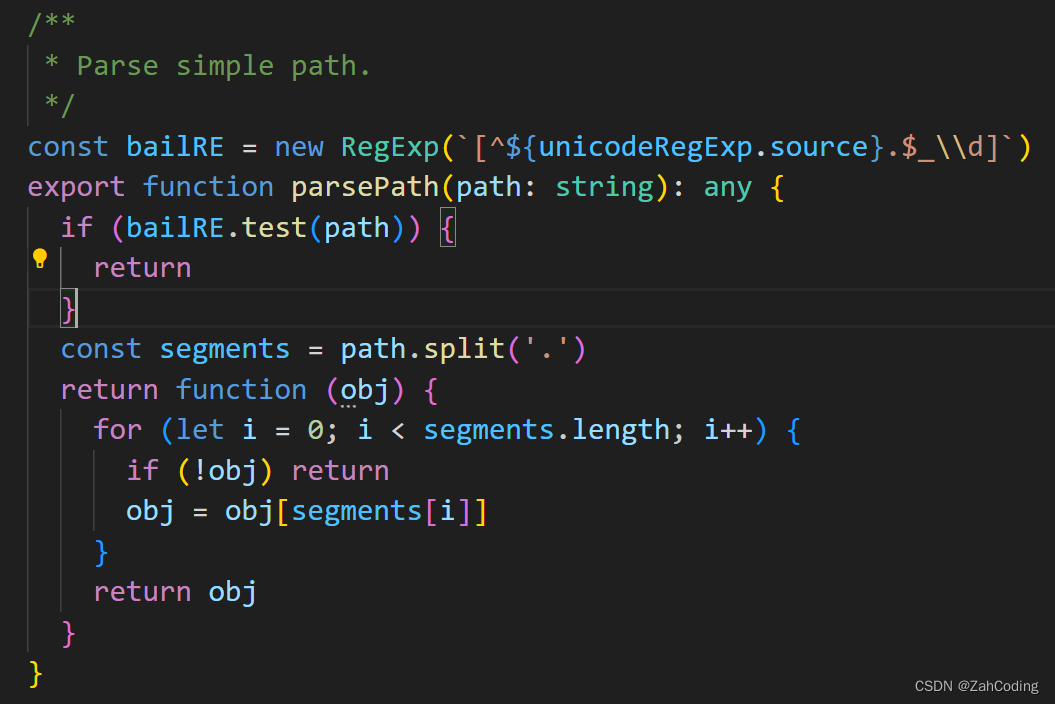
进到parsePath里可以看到,实际上就是去vm上不断地查找对应的属性值,比如c.c.c,实际上就是vm['c'] -> vm['c']['c']
同时因为Watcher本身在声明时会自调用一次,这样就会获取到一个初始值并保存在this.value中

那么可以想到,当属性值被修改时,触发该值的dep.notify,然后所有的Watcher队列被拿出来执行,走run方法,在里面会先获取最新的值,然后拿来做对比,判断是否需要进行更新
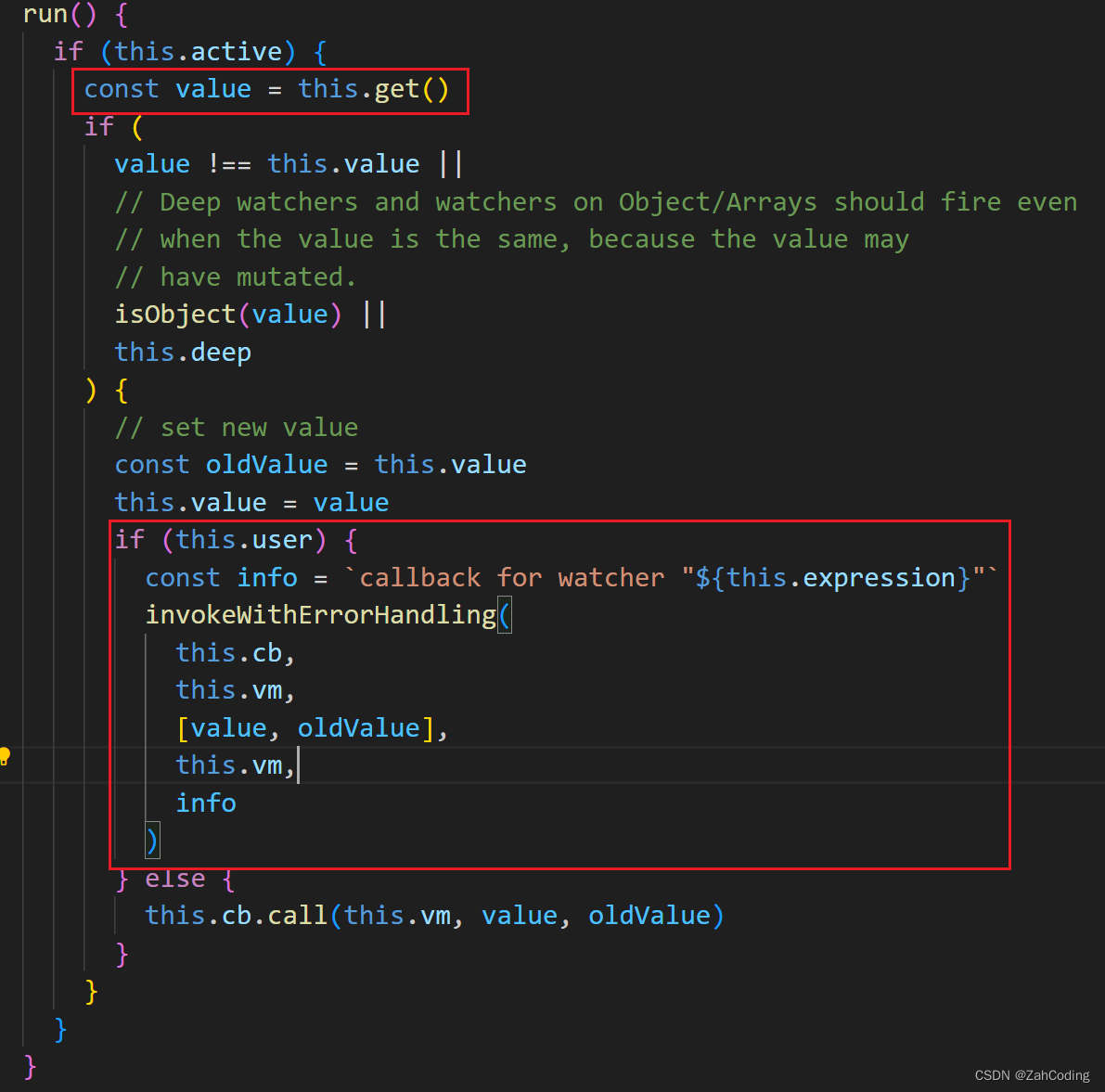
当判断前后两次获取的值不同时,就调用了用户的回调,这样就实现了watch















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









