







vq
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
class VectorQuantizer(nn.Module):
"""
VQ-VAE layer: Input any tensor to be quantized.
Args:
embedding_dim (int): the dimensionality of the tensors in the
quantized space. Inputs to the modules must be in this format as well.
num_embeddings (int): the number of vectors in the quantized space.
commitment_cost (float): scalar which controls the weighting of the loss terms (see
equation 4 in the paper - this variable is Beta).
"""
def __init__(self, embedding_dim, num_embeddings, commitment_cost):
super().__init__()
self.embedding_dim = embedding_dim
self.num_embeddings = num_embeddings
self.commitment_cost = commitment_cost
# initialize embeddings
self.embeddings = nn.Embedding(self.num_embeddings, self.embedding_dim) #[n,64]
self.loss = nn.MSELoss()
def forward(self, x,epoch=0):
maxvalue = torch.max(torch.abs(x))+1e5#1e5#
minvalue = torch.min(x)
x = torch.div((x-minvalue), maxvalue) # torch.Size([7, 64, 4, 4])
# print('torch.isnan(x).any()',torch.isnan(x).any())
# [B, C, H, W] -> [B, H, W, C]
x = x.permute(0, 2, 3, 1).contiguous() # torch.Size([7, 4, 4, 64])
# [B, H, W, C] -> [BHW, C] [BHW, 64]
flat_x = x.reshape(-1, self.embedding_dim) #torch.Size([112, 64])
encoding_indices = self.get_code_indices(flat_x)# BHW
# print("输出一下编码",encoding_indices.topk(5, dim=0))
quantized = self.quantize(encoding_indices)
quantized = quantized.view_as(x) # [B, H, W, C]
if not self.training:
quantized = quantized.permute(0, 3, 1, 2).contiguous()
return quantized
# embedding loss: move the embeddings towards the encoder's output
q_latent_loss = self.loss(quantized, x.detach()) #????????
# commitment loss
# print(x.shape, quantized.shape)
e_latent_loss = self.loss(x, quantized.detach())
loss = q_latent_loss + self.commitment_cost * e_latent_loss
# Straight Through Estimator
quantized = x + (quantized - x).detach()
quantized = quantized.permute(0, 3, 1, 2).contiguous()
quantized = (quantized * maxvalue) +minvalue
return quantized, loss
def get_code_indices(self, flat_x):
# compute L2 distance
distances = (
torch.sum(flat_x ** 2, dim=1, keepdim=True) +
torch.sum(self.embeddings.weight ** 2, dim=1) -
2. * torch.matmul(flat_x, self.embeddings.weight.t())
) # [N, M]
encoding_indices = torch.argmin(distances, dim=1) # [N,]
return encoding_indices
def quantize(self, encoding_indices):
"""Returns embedding tensor for a batch of indices."""
return self.embeddings(encoding_indices)
if __name__ == "__main__":
for i in range(10):
x = ((torch.rand( 7, 64, 4, 4))*1000)
x = ((torch.rand(7, 64, 4, 4)) * 1000)
vq = VectorQuantizer(64, 5, 0.25) # 16,128,0.25
out, e_q_loss = vq(x)
e_q_loss.backward()
- c维度的方法
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
class VectorQuantizer(nn.Module):
"""
VQ-VAE layer: Input any tensor to be quantized.
Args:
embedding_dim (int): the dimensionality of the tensors in the
quantized space. Inputs to the modules must be in this format as well.
num_embeddings (int): the number of vectors in the quantized space.
commitment_cost (float): scalar which controls the weighting of the loss terms (see
equation 4 in the paper - this variable is Beta).
"""
def __init__(self, embedding_dim, num_embeddings, commitment_cost):
super().__init__()
self.embedding_dim = embedding_dim
self.num_embeddings = num_embeddings
self.commitment_cost = commitment_cost
# initialize embeddings
self.embeddings = nn.Embedding(self.num_embeddings, self.embedding_dim) #[n,16]
self.loss = nn.MSELoss()
# bn = nn.BatchNorm2d(64) x = bn(x)
def forward(self, x,epoch=0):
maxvalue = torch.max(torch.abs(x))+1e5#1e5#
minvalue = torch.min(x)
x = torch.div((x-minvalue), maxvalue) # torch.Size([7, 64, 4, 4])
# [B, C, H, W] -> [BC, HW]
flat_x = x.reshape(-1, self.embedding_dim) #torch.Size([7*64, 16])
encoding_indices = self.get_code_indices(flat_x)# BHW
# print("输出一下编码",encoding_indices.topk(5, dim=0))
quantized = self.quantize(encoding_indices)
quantized = quantized.view_as(x) # [B, C, H, W]
# if not self.training:
# quantized = quantized.permute(0, 3, 1, 2).contiguous()
# return quantized
# embedding loss: move the embeddings towards the encoder's output
q_latent_loss = self.loss(quantized, x.detach()) #????????
e_latent_loss = self.loss(x, quantized.detach())
loss = q_latent_loss + self.commitment_cost * e_latent_loss
# Straight Through Estimator
quantized = x + (quantized - x).detach()
quantized = (quantized * maxvalue) +minvalue
return quantized, loss
def get_code_indices(self, flat_x):
# compute L2 distance
distances = (
torch.sum(flat_x ** 2, dim=1, keepdim=True) +
torch.sum(self.embeddings.weight ** 2, dim=1) -
2. * torch.matmul(flat_x, self.embeddings.weight.t())
) # [N, M]
encoding_indices = torch.argmin(distances, dim=1) # [N,]
return encoding_indices
def quantize(self, encoding_indices):
"""Returns embedding tensor for a batch of indices."""
return self.embeddings(encoding_indices)
if __name__ == "__main__":
for i in range(10):
x = ((torch.rand( 7, 64, 4, 4))*1000)
x = ((torch.rand(7, 64, 4, 4)) * 1000)
vq = VectorQuantizer(16, 50, 0.25) # 16,128,0.25
out, e_q_loss = vq(x)
e_q_loss.backward()
- paper VQVAE2
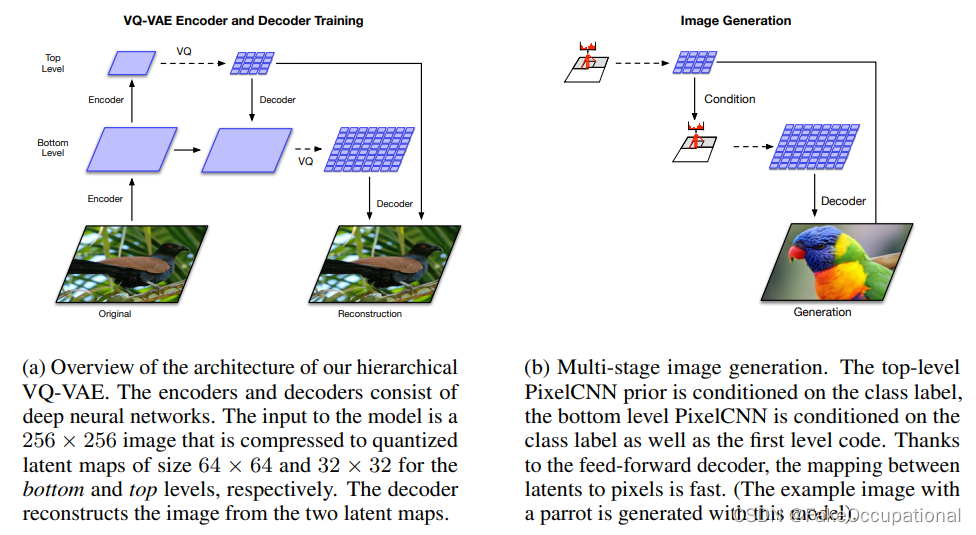
(
a
)
V
Q
−
V
A
E
2
的结构,
(
b
)
图像生成的结构
(a)VQ-VAE2的结构,(b)图像生成的结构
(a)VQ−VAE2的结构,(b)图像生成的结构
- 实验结果

5 Experiments
客观评估和比较生成模型,特别是跨模型族的生成模型,仍然是一个挑战[33]。当前的图像生成模型权衡了样本质量和多样性(或精度与召回率[29])。在本节中,我们展示了我们在以下方面训练的模型的定量和定性结果:ImageNet 256×256。从图5中提供的类条件样本可以看出,在几个代表性类中,样本质量确实很高且清晰。在多样性方面,我们提供的样本来自我们的模型,与BigGAN deep[4]的样本并置,BigGAN deep是最先进的GAN模型从这些并排比较中可以看出,VQ-VAE能够提供具有可比保真度和更高多样性的样本。
5.1 Modeling High-Resolution Face Images
为了进一步评估我们的多尺度方法捕捉数据中极长距离依赖关系的有效性,我们在1024×1024分辨率的FFHQ数据集[14]上训练了一个三层层次模型。该数据集包含70000幅高质量的人像,在性别、肤色、年龄、姿势和服装方面具有相当大的多样性。尽管与ImageNet相比,人脸建模通常被认为不那么困难,但在如此高的分辨率下,也存在着独特的建模挑战,可以以有趣的方式探索生成模型。例如,人脸中存在的对称性需要能够捕捉长距离依赖关系的模型:具有受限感受野的模型可能会分别为每只眼睛选择看似合理的颜色,但可能会错过彼此相距数百像素的两只眼睛之间的强相关性,从而产生眼睛颜色不匹配的样本。




5.2 Quantitative Evaluation
在本节中,我们报告了基于几个指标的定量评估结果,这些指标旨在衡量样本的质量和多样性。
5.2.1 Negative Log-Likelihood and Reconstruction Error
……
5.2.2 Precision - Recall Metric
……
5.3 Classification Accuracy Score
……
5.3.1 FID and Inception Score
……
6 Conclusion
我们提出了一种使用VQ-VAE和强大的自回归模型生成不同高分辨率图像的简单方法。我们的编码器和解码器架构与原始VQ-VAE一样简单、重量轻,唯一的区别是我们使用分层多尺度潜在映射来提高分辨率。我们的最佳类条件样本的保真度与最先进的生成对抗网络具有竞争力,在几个类中具有更广泛的多样性,将我们的方法与GAN的已知局限性进行对比。尽管如此,样本质量和多样性的具体措施仍处于初级阶段,目视检查仍有必要。最后,我们相信我们的实验证明了潜在空间中的自回归建模是学习大规模生成模型的一个简单有效的目标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









