







大侠幸会,在下全网同名「算法金」
0 基础转 AI 上岸,多个算法赛 Top
「日更万日,让更多人享受智能乐趣」
引言
在众多数据挖掘技术中,聚类算法(Clustering Algorithms)扮演着至关重要的角色。
它帮助我们理解数据的内在结构,特别是在没有明确标签的数据集中,聚类算法可以让我们发现数据的自然分组,从而获得深刻的洞见。
本文将介绍10种顶流的聚类算法,它们分别是:K-均值聚类(K-Means Clustering)、层次聚类(Hierarchical Clustering)、DBSCAN、高斯混合模型(Gaussian Mixture Models, GMM)、谱聚类(Spectral Clustering)、均值漂移聚类(Mean Shift Clustering)、OPTICS、基于密度的聚类算法(Density-Based Clustering)、模糊C-均值聚类(Fuzzy C-Means Clustering)和BIRCH。
我们将一一探讨这些算法的原理、优缺点、适用场景以及通过Python实现的示例,以期给读者在选择和应用聚类算法时提供参考和指导。
万字长文,建议先收藏再慢慢细品


1K-均值聚类(K-Means Clustering)
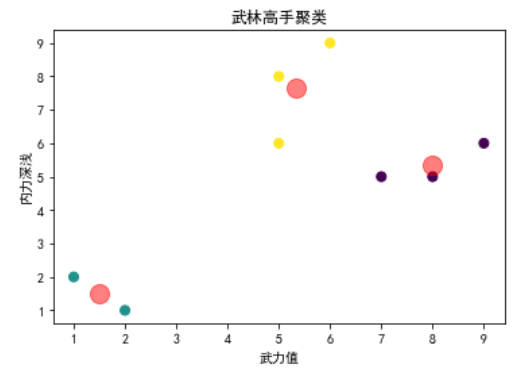
from sklearn.cluster import KMeansimport numpy as npimport matplotlib.pyplot as plt# 设置matplotlib支持中文显示plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示plt.rcParams['axes.unicode_minus'] = False # 正确显示负号# 假想数据集:金庸小说中的武林高手# 武力值和内力深浅X = np.array([[5, 8], [6, 9], [5, 6], # 东邪、西毒、南帝[8, 5], [9, 6], [7, 5], # 北丐、中神通、老顽童[1, 2], [2, 1]]) # 平民武者1、平民武者2# 应用K-均值聚类算法,设置簇的数量为3(高手、中等、平民)kmeans = KMeans(n_clusters=3, random_state=0).fit(X)# 预测每个样本所属的簇labels = kmeans.labels_# 打印每个簇的中心centers = kmeans.cluster_centers_# 可视化结果plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.5)plt.title("武林高手聚类")plt.xlabel("武力值")plt.ylabel("内力深浅")plt.show()
-
算法原理
-
目标:将数据分为K个簇,使得簇内距离最小化,簇间距离最大化。
-
初始化:随机选择K个数据点作为初始簇中心。
-
迭代过程:每个数据点被分配到最近的簇中心所代表的簇,然后每个簇中心更新为簇内所有点的平均位置。这一过程迭代进行,直到簇中心不再显著变化或达到设定的迭代次数。
-
-
优缺点
-
需要预先指定K值,但实际应用中K值往往不易确定。
-
对初始簇中心的选择敏感,不同的初始化可能导致不同的结果。
-
假设簇是凸形的和同质的,因此对于复杂形状的簇或大小差异大的簇聚类效果不佳。
-
对噪声和异常点敏感。
-
实现简单,易于理解。
-
计算效率高,适合处理大规模数据集。
-
适用性广,可用于多种类型数据的聚类。
-
-
应用场景
-
市场细分:根据消费者行为或偏好将消费者分群,以进行更有针对性的营销。
-
文档聚类:将文档集合根据内容相似度进行分组,用于信息检索、文档管理等。
-
图像分割:基于像素的颜色、亮度等特征将图像分割成若干部分,用于图像分析和物体识别。
-
-
Python 实现示例
-
场景:使用金庸小说中武林高手的“武力值”和“内力深浅”进行聚类,将其分为高手、中等、平民三个级别。
-


2 层次聚类(Hierarchical Clustering)
2.1 算法原理
-
分类方式:可以是自底向上的凝聚方法或自顶向下的分裂方法。
-
凝聚方法:最初将每个数据点视为一个簇,然后逐步合并最近的簇。
-
分裂方法:最初将所有数据视为一个簇,然后逐步分裂至个体。
-
-
结果表示:通常用树状图(Dendrogram)表示,显示数据点合并成簇的过程。
2.2 优缺点
-
优点:
-
不需预先指定簇数。
-
直观显示数据层次结构。
-
适应性强,可识别任意形状的簇。
-
-
缺点:
-
计算复杂度高,不宜处理大数据。
-
一旦合并或分裂,不能调整。
-
对噪声和异常点敏感。
-
2.3 应用场景
-
基因表达数据分析:识别具有相似表达模式的基因。
-
客户分群:分析消费行为,识别消费群体。
-
文档归类:管理大量文档,提高检索效率。
2.4 Python 实现示例
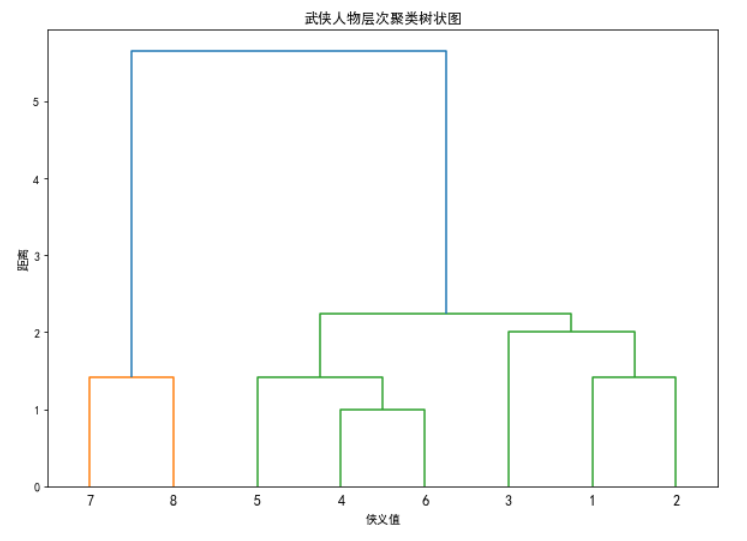
from scipy.cluster.hierarchy import dendrogram, linkagefrom matplotlib import pyplot as pltimport numpy as np# 构建数据集:金庸小说武侠人物的侠义值和武功高低X = np.array([[5, 8], [6, 9], [5, 6], # 侠义高,武功高[8, 5], [9, 6], [7, 5], # 侠义中,武功中[1, 2], [2, 1]]) # 侠义低,武功低# 使用凝聚的层次聚类linked = linkage(X, 'single')# 绘制树状图plt.figure(figsize=(10, 7))dendrogram(linked,orientation='top',labels=range(1, 9),distance_sort='descending',show_leaf_counts=True)plt.title('武侠人物层次聚类树状图')plt.xlabel('侠义值')plt.ylabel('距离')plt.show()
-
-
场景:将金庸小说中的武侠人物根据“侠义值”和“武功高低”进行层次聚类,识别不同侠义层级的武侠人物群体。
-


3 DBSCAN
(Density-Based Spatial Clustering of Applications with Noise)
3.1 算法原理
-
基于密度的聚类:DBSCAN通过连接高密度的点区域形成簇,能够识别任意形状的簇,并有效处理噪声点。
-
核心概念:
-
核心点:在指定半径内包含足够多数量的点。
-
边界点:在半径内有较少的邻居点,但是属于某个核心点的邻域。
-
噪声点:既不是核心点也不是边界点的点。
-
-
聚类过程:从某个核心点开始,递归地将密度可达的所有点加入到相同的簇中。
3.2 优缺点
-
优点:
-
不需要预先指定簇的数量。
-
能够识别任意形状的簇。
-
对噪声点具有良好的鲁棒性。
-
-
缺点:
-
对于密度不均的数据集,选择合适的半径和邻居点数量参数可能较为困难。
-
高维数据的密度估计较为困难,对参数选择敏感。
-
3.3 应用场景
-
异常点检测:有效识别和分离噪声点或异常数据。
-
复杂结构数据聚类:适用于传统聚类算法难以处理的复杂形状数据。
-
地理空间数据分析:例如,根据地理位置信息对地点进行分组。
3.4 Python 实现示例
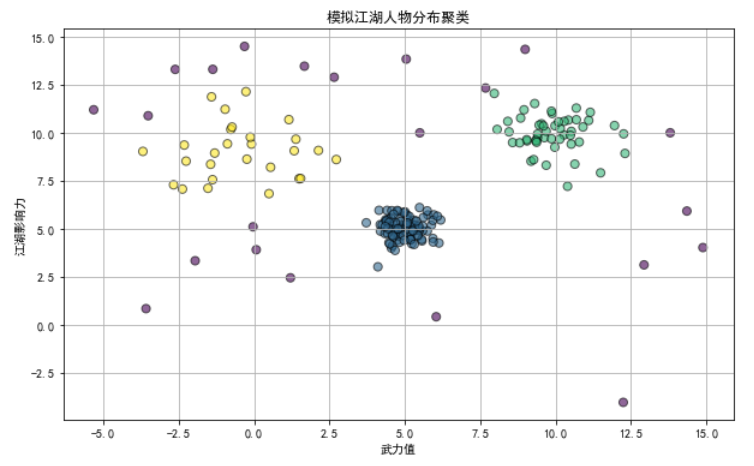
场景:利用DBSCAN对金庸小说中的江湖恩怨图进行聚类,将密切相关的人物分为一组。
模拟江湖中不同门派的人物分布,其中包括大派高手、散落江湖的侠客、以及一些游走于江湖之间的普通人。
from sklearn.cluster import DBSCAN
import numpy as np
import matplotlib.pyplot as plt
# 模拟大量数据集:不同门派高手(高密度区),散落江湖侠客(中密度区),游走江湖普通人(低密度区)
np.random.seed(0) # 确保生成数据的一致性
# 生成高密度区数据(大派高手)
high_density = np.random.randn(100, 2) * 0.5 + [5, 5]
# 生成中密度区数据(散落江湖侠客)
medium_density = np.random.randn(50, 2) + [10, 10]
# 生成低密度区数据(游走江湖普通人)
low_density = np.random.randn(30, 2) * 2 + [0, 10]
# 合并成一个数据集
X = np.vstack((high_density, medium_density, low_density))
# 添加一些噪声点
noise = np.random.uniform(low=-5, high=15, size=(20, 2))
X = np.vstack((X, noise))
# 应用DBSCAN聚类
dbscan = DBSCAN(eps=1.5, min_samples=5).fit(X)
# 获取每个点的簇标号
labels = dbscan.labels_
# 可视化聚类结果
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50, alpha=0.6, edgecolor='k')
plt.title('模拟江湖人物分布聚类')
plt.xlabel('武力值')
plt.ylabel('江湖影响力')
plt.grid(True)
plt.show()
通过这个示例,DBSCAN算法根据“武力值”和“江湖影响力”将江湖中的人物分为不同的组,从而识别出彼此之间关系密切的人物群体。
该方法特别适用于处理包含复杂关系或噪声数据的情景。
免费知识星球,欢迎加入交流


4 高斯混合模型
(Gaussian Mixture Models, GMM)
4.1 算法原理
-
基本假设:数据由多个高斯分布组成,每个分布对应一个簇。
-
参数估计:使用期望最大化(Expectation-Maximization, EM)算法来估计每个高斯分布的参数(均值、方差)和每个簇的混合系数。
-
数据归属:根据这些分布的参数,为每个数据点计算属于各个簇的概率,数据点更可能属于概率最高的簇。
4.2 优缺点
-
优点:
-
提供软聚类(soft clustering),即给出数据点属于各簇的概率。
-
能够模拟和识别复杂的数据分布,适用于不同形状和大小的簇。
-
-
缺点:
-
需要预先设定簇的数量。
-
对初始参数敏感,可能收敛到局部最优解。
-
计算复杂度较高,尤其是对大数据集。
-
4.3 应用场景
-
图像处理:如图像分割,通过模型不同组分来区分图像中的不同对象。
-
异常检测:基于数据点在正常行为模型中的概率,来识别异常行为。
-
语音识别:GMM 能够对声音信号的复杂分布进行建模。
4.4 Python 实现示例
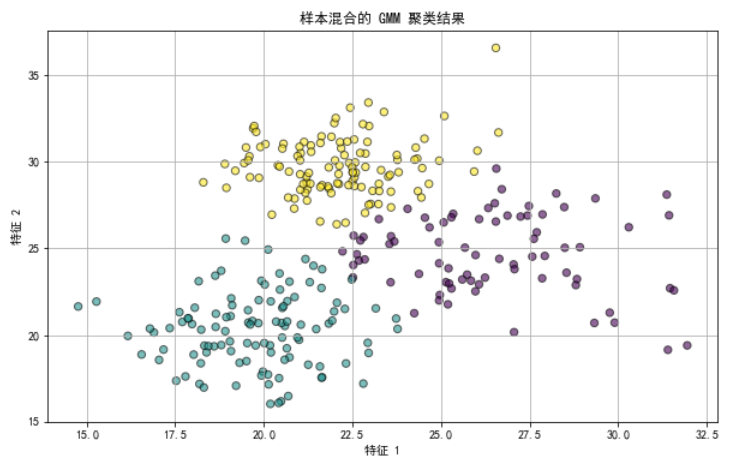
场景:使用GMM对金庸小说中的人物按“武力值”和“智谋值”进行聚类,尝试发现不同特质的人物群体
from sklearn.mixture import GaussianMixtureimport numpy as npimport matplotlib.pyplot as plt# 设置随机种子,确保结果的可重复性np.random.seed(42)# 生成三组中心点较接近的高斯分布数据group1 = np.random.randn(100, 2) * 2 + [20, 20]group2 = np.random.randn(100, 2) * 3 + [25, 25]group3 = np.random.randn(100, 2) * 1.5 + [22, 30]# 合并这些数据集成一个大的数据集X = np.vstack((group1, group2, group3))# 应用GMM聚类gmm = GaussianMixture(n_components=3, random_state=0).fit(X)labels = gmm.predict(X)# 可视化聚类结果plt.figure(figsize=(10, 6))plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=40, alpha=0.6, edgecolor='k')plt.title('样本混合的 GMM 聚类结果')plt.xlabel('特征 1')plt.ylabel('特征 2')plt.grid(True)plt.show()
在这个示例中,我们使用GaussianMixture模型对数据进行了聚类,并且设置了n_components=3,意味着我们假设数据由3个高斯分布组成。
每个点的颜色代表了它最有可能属于的高斯分布(即簇)。
GMM不仅能够告诉我们每个点属于哪个簇,还能提供属于每个簇的概率,这是一种非常灵活和强大的聚类方法。


5 谱聚类(Spectral Clustering)
5.1 算法原理
-
图构建:首先根据数据点之间的相似度构建一个图,每个数据点都是图中的一个节点,而节点之间的边表示数据点之间的相似度。
-
拉普拉斯矩阵:接着计算图的拉普拉斯矩阵,并根据该矩阵求解特征值和特征向量。
-
特征向量聚类:选择最小的几个非零特征值对应的特征向量,利用这些特征向量的信息对数据点进行聚类(例如,通过K-均值)。
5.2 优缺点
-
优点:
-
能够识别任意形状的簇,并处理非线性可分的数据集。
-
相比于传统的聚类方法,如K-均值,更不易受到数据分布形态的影响。
-
-
缺点:
-
计算复杂度相对较高,尤其是对于大规模数据集。
-
需要预先设定簇的数量。
-
5.3 应用场景
-
图像分割:基于像素或区域的相似性将图像分割成多个部分。
-
社交网络分析:发现社交网络中的社区结构。
-
基因表达数据聚类:根据基因在不同条件下的表达模式进行聚类。
5.4 Python 实现示例
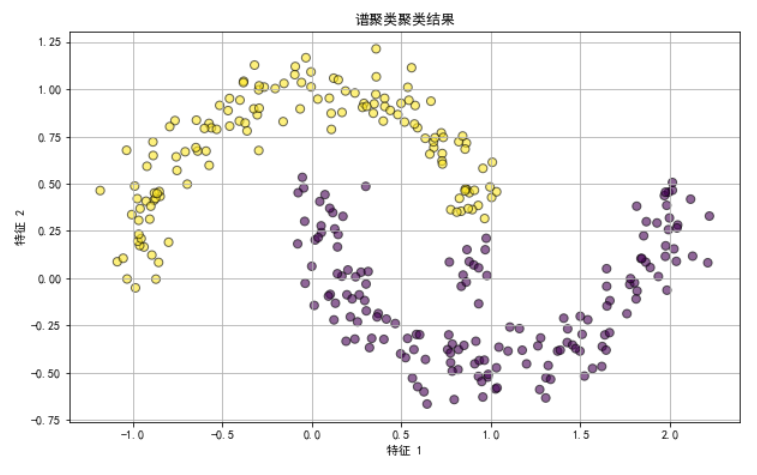
场景:对一个包含两个“月亮形”簇的数据集进行聚类,这是一个典型的非线性可分问题,用以展示谱聚类在处理特殊数据结构上的能力
from sklearn.datasets import make_moonsfrom sklearn.cluster import SpectralClusteringimport matplotlib.pyplot as plt# 生成“月亮形”数据X, y = make_moons(n_samples=300, noise=0.1, random_state=4)# 应用谱聚类sc = SpectralClustering(n_clusters=2, affinity='nearest_neighbors', random_state=42)labels = sc.fit_predict(X)# 可视化聚类结果plt.figure(figsize=(10, 6))plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50, alpha=0.6, edgecolor='k')plt.title('谱聚类聚类结果')plt.xlabel('特征 1')plt.ylabel('特征 2')plt.grid(True)plt.show()
在这个示例中,我们首先使用 make_moons 函数生成了具有两个“月亮形”簇的数据集,这种数据集的特点是两个簇之间有明显的非线性边界。
然后,我们使用谱聚类对数据进行了聚类,并通过可视化展示了聚类结果。
可以看到,谱聚类能够有效地识别并分离这种复杂形状的簇,展示了其在处理非线性可分数据时的强大能力。

6. 均值漂移聚类(Mean Shift Clustering)
均值漂移聚类是一种基于密度的非参数聚类算法,它不需要预先指定簇的数量,而是通过寻找样本空间中的密度极大值点来确定簇的中心。
6.1 算法原理
-
核心思想:对每个点,均值漂移聚类算法会在其周围区域内搜索,计算并向密度最高的方向移动(即均值漂移),直到收敛到局部密度最大值点。
-
带宽(Bandwidth):算法的关键参数,决定了搜索区域的大小。不同的带宽值会导致聚类结果的显著不同。
6.2 优缺点
-
优点:
-
不需要预先指定簇的数量。
-
可以发现任意形状的簇。
-
-
缺点:
-
计算成本较高,尤其是对于大规模数据集。
-
带宽参数的选择对聚类结果有很大影响。
-
6.3 应用场景
-
图像分析:例如图像分割和图像平滑。
-
聚类分析:适用于数据分布复杂且簇形状多样的情况。
6.4 Python 实现示例
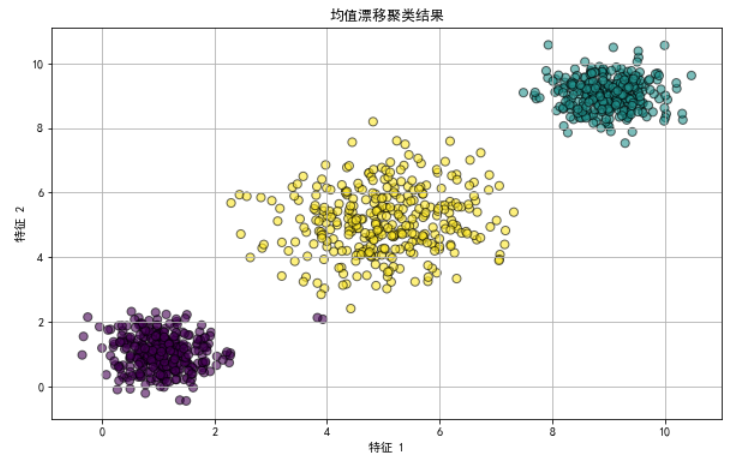
场景:对一个包含不同密度和形状簇的数据集进行均值漂移聚类,演示其在自动确定簇数量和识别复杂簇形状方面的能力。
from sklearn.cluster import MeanShiftfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as pltimport numpy as np# 生成数据集,包含不同密度的簇centers = [[1, 1], [5, 5], [9, 9]]X, _ = make_blobs(n_samples=1000, centers=centers, cluster_std=[0.5, 1, 0.5])# 应用均值漂移聚类meanshift = MeanShift(bandwidth=2)meanshift.fit(X)labels = meanshift.labels_# 可视化聚类结果plt.figure(figsize=(10, 6))plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50, alpha=0.6, edgecolor='k')plt.title('均值漂移聚类结果')plt.xlabel('特征 1')plt.ylabel('特征 2')plt.grid(True)plt.show()
在这个示例中,我们首先使用 make_blobs 函数生成了一个包含三个中心点,但标准差不同的簇的数据集。这模拟了具有不同密度簇的情形。
然后,我们使用均值漂移聚类算法对数据进行了聚类,并通过可视化展示了聚类结果。
可以看到,均值漂移聚类能够根据数据的密度自动确定簇的数量,并有效地识别出不同密度和形状的簇,这展示了其在处理复杂数据结构时的优越性能。

7. OPTICS
(Ordering Points To Identify the Clustering Structure)
OPTICS(Ordering Points To Identify the Clustering Structure)算法是一种基于密度的聚类方法,与 DBSCAN 类似,但它可以在不同密度的区域识别出簇的结构,克服了 DBSCAN 在处理不同密度簇时的限制。
7.1 算法原理
-
核心思想:OPTICS 算法不直接进行聚类,而是创建一个达到核心距离排序的点的列表,这个列表能够反映数据结构的密度分布情况。
-
可变密度:通过在不同区域自适应地选择适当的密度条件,OPTICS 能够处理具有变化密度的数据。
7.2 优缺点
-
优点:
-
能够发现任意形状的簇,并适应不同密度的数据集。
-
不需要预先指定全局的簇数量。
-
-
缺点:
-
结果的解释比 DBSCAN 更为复杂,需要通过可视化或其他方法来理解聚类结构。
-
计算复杂度和内存需求较高,尤其是对大规模数据集。
-
7.3 应用场景
-
复杂结构数据聚类:适用于数据密度变化大的复杂数据集。
-
大规模空间数据分析:如地理信息系统(GIS)中的空间数据分析。
7.4 Python 实现示例
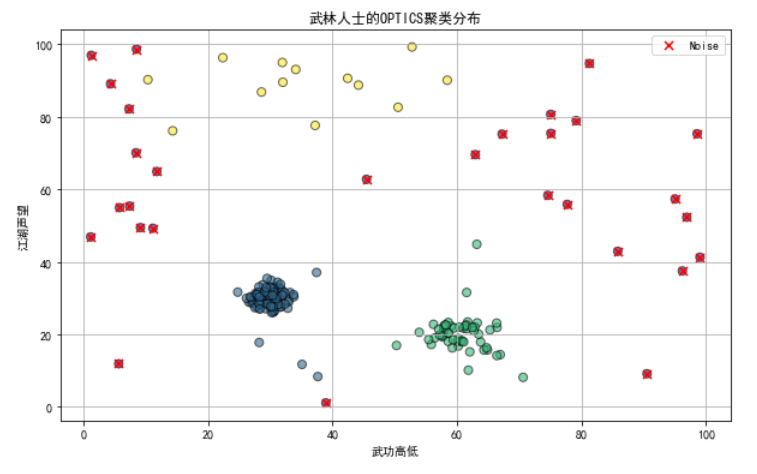
场景:将金庸小说中的武林人士根据“武功高低”和“江湖声望”进行聚类,模拟在江湖中不同势力范围和密度的门派分布。
from sklearn.cluster import OPTICS
import matplotlib.pyplot as plt
import numpy as np
# 设置随机种子,确保结果的可重复性
np.random.seed(42)
# 创建数据集:模拟金庸小说中的武林世界
# 大门派成员:密集分布
big_sect = np.random.randn(100, 2) * 2 + [30, 30]
# 小门派成员:较为稀疏
small_sect = np.random.randn(50, 2) * 3 + [60, 20]
# 散人:随机分布
lone_wolf = (np.random.rand(50, 2) * 100) % 100 # 保证散人分布在整个100x100的区域内
# 将这些分布合并到一起
X = np.vstack((big_sect, small_sect, lone_wolf))
# 应用OPTICS聚类
optics = OPTICS(min_samples=10, xi=0.05, min_cluster_size=0.05) # 9
optics.fit(X)
# 获取每个点的簇标号
labels = optics.labels_
# 可视化聚类结果,使用不同颜色表示不同的聚类
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50, alpha=0.6, edgecolor='k', marker='o')
# 未被归入任何聚类的点视为噪声点,特别标注
noise = X[labels == -1]
plt.scatter(noise[:, 0], noise[:, 1], c='red', s=50, alpha=1, edgecolor='k', marker='x', label='Noise')
plt.title('武林人士的OPTICS聚类分布')
plt.xlabel('武功高低')
plt.ylabel('江湖声望')
plt.legend()
plt.grid(True)
plt.show()
在这个示例中,我们模拟了金庸小说中的武林人士按“武功高低”和“江湖声望”分布的数据集,其中包括不同密度的大门派、小门派和散人。
通过 OPTICS 算法,我们可以看到算法如何识别出不同的聚类结构,包括密集的大门派区

8. 基于密度的聚类算法
(Density-Based Clustering)
为了展示基于密度的聚类方法的多样性,我们接下来讨论一种通常视作DBSCAN算法的扩展,但适用于更广泛情况的算法框架,它能够处理不同密度的数据集。虽然OPTICS算法已经提到,它是处理变化密度数据集的强大工具,我们将进一步探讨基于密度的聚类算法的其他方面。
基于密度的聚类方法的关键优势在于它们对于簇的形状几乎没有假设,能够发现任意形状的簇,并且能够识别并处理噪声数据。这些算法通常需要两个参数:邻域大小(如DBSCAN中的eps)和形成密集区域所需的最小点数(如DBSCAN中的min_samples)。
8.1 算法原理
-
密度可达:一个点从另一个点通过一系列密度相连的点可达。
-
核心点、边界点和噪声点:核心点是在其邻域内有足够多邻居的点;边界点少于
min_samples但属于某个核心点邻域的点;噪声点既不是核心点也不是边界点。
8.2 应用场景
-
异常检测:识别出与高密度区域不相连的噪声点。
-
地理数据分析:如根据地理位置信息对地点进行聚类。
-
图像分割:基于像素的密度对图像进行分割。
8.3 Python 实现示例
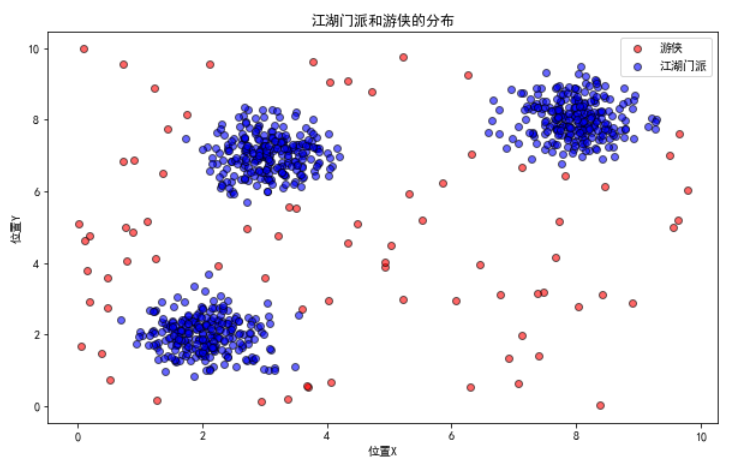
场景:我们将创建一个江湖地图,其中包含了大大小小的门派(密集区域)和散布于江湖中的游侠(稀疏区域),然后使用基于密度的聚类算法来识别这些门派和游侠。
为了简化,这里我们使用DBSCAN作为示例,因为它是最常见和广泛应用的基于密度的聚类算法之一
from sklearn.cluster import DBSCANfrom sklearn.datasets import make_blobsimport matplotlib.pyplot as pltimport numpy as np# 设置随机种子np.random.seed(42)# 生成示例数据:江湖门派和游侠centers = [[2, 2], [8, 8], [3, 7]] # 门派中心X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.50)# 添加散布的游侠(噪声点)X = np.concatenate([X, np.random.uniform(low=0, high=10, size=(100, 2))])# 应用DBSCAN聚类dbscan = DBSCAN(eps=0.5, min_samples=10).fit(X)labels = dbscan.labels_# 可视化聚类结果plt.figure(figsize=(10, 6))# 标记噪声点plt.scatter(X[labels == -1, 0], X[labels == -1, 1], c='red', label='游侠', alpha=0.6, edgecolor='k')# 标记门派(聚类)plt.scatter(X[labels != -1, 0], X[labels != -1, 1], c='blue', label='江湖门派', alpha=0.6, edgecolor='k')plt.title('江湖门派和游侠的分布')plt.xlabel('位置X')plt.ylabel('位置Y')plt.legend()plt.show()
9. 模糊C-均值聚类
(Fuzzy C-Means Clustering)
模糊C-均值(FCM)聚类算法是一种软聚类方法,它允许一个数据点属于多个聚类,每个聚类都有一个隶属度来表示数据点属于该聚类的程度。
9.1 算法原理
-
隶属度:算法核心是为每个数据点计算其对每个簇的隶属度(membership degree),即该点属于各簇的概率。
-
目标函数:通过最小化目标函数(通常是数据点与簇中心的加权距离之和),来更新簇中心和隶属度。
9.2 优缺点
-
优点:
-
提供了数据点隶属度的信息,为数据的模糊分类提供了可能。
-
可以处理属于多个簇的情况,更加灵活。
-
-
缺点:
-
相比硬聚类方法,计算复杂度较高。
-
结果依赖于初始化簇中心的选择。
-
9.3 应用场景
-
图像处理和分割:通过考虑像素点可能同时属于多个对象的属性,对图像进行更细致的分割。
-
模式识别:在不完全确定数据分类的情况下,提供更灵活的分类方法。
-
数据分析:处理数据存在模糊边界或重叠的场景。
9.4 Python 实现示例
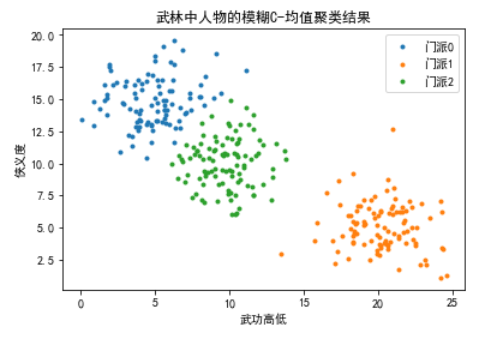
场景:在武侠的世界里,武林中的人物往往不是单纯地属于一个门派,而是可能同时受到多个门派影响。我们将使用模糊C-均值聚类方法来模拟这种情况,对武林中人物的“武功高低”和“侠义度”进行聚类。
由于Python的sklearn库不直接支持模糊C-均值聚类,这里我们使用skfuzzy库来实现,该库是一个开源的模糊逻辑工具包
pip install scikit-fuzzy
import numpy as np
import skfuzzy as fuzz
import matplotlib.pyplot as plt
# 生成数据:武侠世界中的人物,"武功高低"和"侠义度"
np.random.seed(42)
n_points = 300
X = np.zeros((n_points, 2))
# 生成三个门派
X[:100, :] = np.random.normal(0, 2, (100, 2)) + [10, 10] # 门派A
X[100:200, :] = np.random.normal(0, 2, (100, 2)) + [20, 5] # 门派B
X[200:, :] = np.random.normal(0, 2, (100, 2)) + [5, 15] # 门派C
# 应用模糊C-均值聚类
cntr, u, u0, d, jm, p, fpc = fuzz.cluster.cmeans(
X.T, 3, 2, error=0.005, maxiter=1000, init=None)
# 聚类结果
cluster_membership = np.argmax(u, axis=0)
# 可视化结果
fig, ax = plt.subplots()
for j in range(3):
ax.plot(X[cluster_membership == j, 0], X[cluster_membership == j, 1], '.', label='门派{}'.format(j))
ax.legend()
plt.title('武林中人物的模糊C-均值聚类结果')
plt.xlabel('武功高低')
plt.ylabel('侠义度')
plt.show()在这个示例中,我们首先为武侠世界中的人物生成了一些示例数据,代表他们的"武功高低"和"侠义度"两个维度。然后,我们使用模糊C-均值(Fuzzy C-Means,FCM)聚类算法来处理这些数据,尝试找到属于三个不同"门派"的聚类中心,并为每个人物分配隶属度。
通过可视化结果,我们可以看到各个人物根据他们的武功和侠义度被聚类到最接近的门派中,而每个人物同时也可能以不同的隶属度属于其他门派,这正体现了模糊C-均值聚类方法的特点:允许数据点以一定的隶属度属于多个聚类。
这种方法在处理像武侠世界这样的复杂场景时非常有用,因为它可以捕捉到人物或数据点之间的微妙关系,如同一个人物可能受到多个门派的影响,或在不同情境下表现出不同的属性特质。通过模糊聚类,我们能够更灵活地理解和解释这些复杂的关系。
10. BIRCH
(Balanced Iterative Reducing and Clustering using Hierarchies)
BIRCH算法专为大规模数据集的聚类而设计,通过构建一个名为CF树(Clustering Feature Tree)的树状结构来压缩数据,同时尽量保持数据的聚类特征,然后在这个压缩后的数据上应用聚类算法。
10.1 算法原理
-
CF树:CF树是一种特殊的平衡树,用于存储数据点的聚合信息。每个节点代表了数据点的一个聚合(如聚合的中心、样本数、方差等)。
-
构建和压缩CF树:通过扫描数据集来构建CF树,并在此过程中压缩数据。
-
全局聚类:在CF树的基础上,使用传统聚类算法(如K-均值)进行全局聚类。
10.2 优缺点
-
优点:
-
特别适合于大规模数据集的聚类。
-
聚类速度快,占用内存少。
-
-
缺点:
-
对噪声和离群点比较敏感。
-
结果依赖于CF树的参数设置,如分支因子和阈值。
-
10.3 应用场景
-
大规模数据聚类:适用于需要快速处理大量数据的场景。
-
实时数据流聚类:适用于需要从持续到来的数据流中实时提取聚类信息的应用。
10.4 Python 实现示例
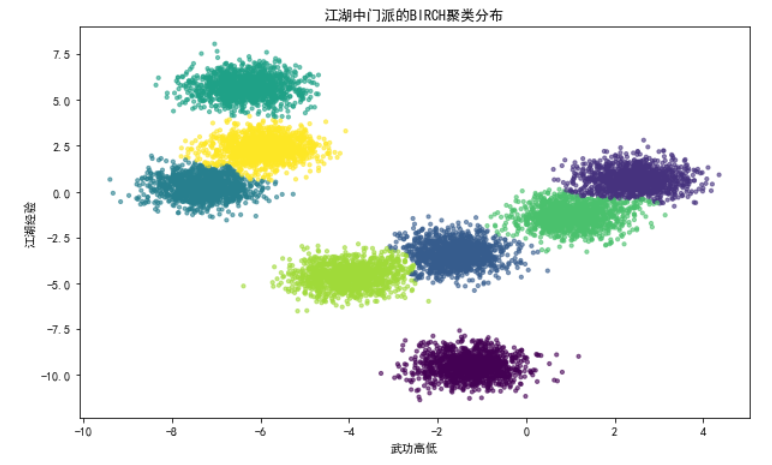
场景:假设江湖中有成千上万的武林人士,我们需要将他们根据“武功高低”和“江湖经验”进行快速聚类,以识别出各个大小不同的门派
from sklearn.cluster import Birch
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy as np
# 生成大规模数据集:武林人士
X, _ = make_blobs(n_samples=10000, centers=8, cluster_std=0.60, random_state=2)
# 应用BIRCH聚类
brc = Birch(n_clusters=8)
brc.fit(X)
# 获取每个点的簇标号
labels = brc.predict(X)
# 可视化聚类结果
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=10, alpha=0.6)
plt.title('江湖中门派的BIRCH聚类分布')
plt.xlabel('武功高低')
plt.ylabel('江湖经验')
plt.show()
在这个示例中,我们首先生成了一个大规模的模拟“武林人士”数据集,其中包含了数千名武林人士的信息。
然后,我们使用BIRCH算法对这些数据进行了快速聚类,以便识别出不同的门派。
最后,通过可视化展示了聚类结果,每个颜色代表一个门派,可以看出BIRCH算法能够有效地处理大规模数据集,并快速识别出数据中的聚类结构
[ 抱个拳,总个结 ]
本文介绍了10种顶流的聚类算法,包括K-均值聚类、层次聚类、DBSCAN、高斯混合模型、谱聚类、均值漂移聚类、OPTICS、基于密度的聚类算法、模糊C-均值聚类和BIRCH。每种算法都有其独特的优点和适用场景,同时也有其局限性。
聚类算法的选择指南
-
对于大规模数据集,优先考虑BIRCH或均值漂移聚类。
-
当数据集包含噪声或离群点时,DBSCAN或OPTICS是更好的选择。
-
如果需要处理具有复杂分布或形状的数据集,谱聚类或高斯混合模型可能更适合。
-
对于需要软聚类的场景,模糊C-均值聚类提供了每个数据点属于各聚类的程度。
-
层次聚类适用于那些需要了解数据层次结构的应用。
未来趋势和研究方向
-
可扩展性:随着数据量的不断增长,开发能够有效处理大规模数据集的聚类算法将是未来的一个重要趋势。
-
自适应性:自动确定最佳聚类数量,减少人工干预,提高聚类算法的智能化水平。
-
多模态数据聚类:研究如何有效聚类来自不同源和类型的数据,例如文本、图像和声音数据的集成聚类。
-
深度学习与聚类:结合深度学习技术和聚类算法,提高聚类的性能和准确性,尤其是在非结构化数据上的应用。
参考文献
本文中提及的聚类算法和概念可以在以下参考文献中找到更详细的描述和分析:
-
Jain, A.K., Murty, M.N., and Flynn, P.J. (1999). "Data clustering: a review." ACM computing surveys (CSUR), 31(3), 264-323.
-
Ester, M., Kriegel, H.P., Sander, J., and Xu, X. (1996). "A density-based algorithm for discovering clusters in large spatial databases with noise." Kdd, 96(34), 226-231.
-
MacQueen, J. et al. (1967). "Some methods for classification and analysis of multivariate observations." Proceedings of the fifth Berkeley symposium on mathematical statistics and probability. 1. University of California Press. 281–297.
-
Rokach, L. and Maimon, O. (2005). Clustering methods. In Data mining and knowledge discovery handbook (pp. 321-352). Springer, Boston, MA.
这些参考文献提供了聚类算法的基础知识、应用案例和研究进展,是进一步了解和研究聚类算法的宝贵资源。

日更时间紧任务急,难免有疏漏之处,还请各位大侠海涵
本篇内容仅供学习交流之用,部分素材来自网络,侵联删















 9701
9701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









