







有些人在碰到问题时,就想“我知道,我可以使用正则表达式”。现在,他就有了两个问题。
正则表达式为高级的文本模式匹配、抽取、与文本形式的搜索和替换功能提供了基础。简单地说,正则表达式(简称为 regex)是一些由字符和特殊符号组成的字符串,它们描述了
模式的重复或者表述多个字符,于是正则表达式能按照某种模式匹配一系列有相似特征的字符串。换句话说,它们能够匹配多个字符串……一种只能匹配一个字符串的正则表达式模式是很乏味并且毫无作用的,不是吗?
在Python中我们使用re模块来支持正则表达式。由于笔者使用的Python版本是3.7版本,这里给出Python3.7的说明文档url:https://docs.python.org/3.7/library/re.html
接下来笔者将从正则表达式的符号与规则、re模块的主要函数及其使用方法、Python实操三个部分展开,试图带给读者们一种快速上手正则匹配的直观印象。开始之前,需要说明的是,你不需要去可以记忆本文提到的很多符号与规则,唯手熟尔。当然,这里的re编程希望大家能够亲自动手实操一遍。
目录
【1】特殊符号与规则
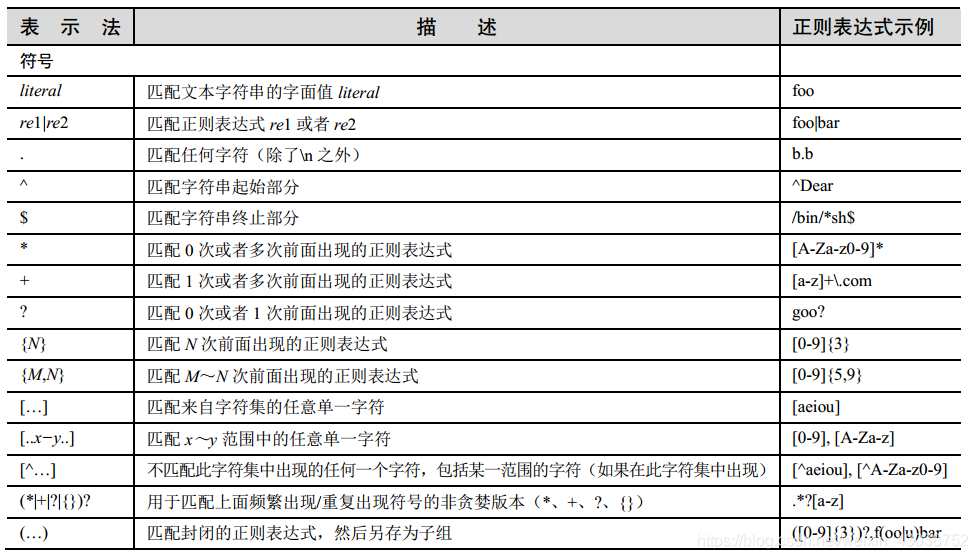
- ①表示择一匹配的管道符号(|),也就是键盘上的竖线,表示一个“从多个模式中选择其一”的操作。它用于分割不同的正则表达式;
- ②点号或者句点(.)符号匹配除了换行符\n 以外的任何字符,注意是一个字符。如果需要去匹配点号,则需要使用反斜线\去对其进行转义;
- ③脱字符^和美元符号$分别指示了字符串起始和结束的边界。^From匹配任何以 From 作为起始的字符串,/bin/tcsh$匹配任何以/bin/tcsh 作为结尾的字符串;
- ④方括号[]正则表达式能够匹配一对方括号中包含的任何字符,[cr][23][dp][o2] 一个包含四个字符的字符串,第一个字符是“c”或“r”,然后是“2”或“3”,后面是“d”或“p”,最后要么是“o”要么“2”。例如,c2do、r3p2、r2d2、c3po 等;
- ⑤方括号中两个符号中间用连字符(-)连接,用于指定一个字符的范围;例如,A-Z、a-z 或者 0-9 分别用于表示大写字母、小写字母和数值数字。如果脱字符(^)紧跟在左方括号后面,这个符号就表示不匹配给定字符集中的任何一个字符;
- ⑥特殊符号*、+和?:星号或者星号操作符(*)将匹配其左边的正则表达式出现零次或者多次的情况(在计算机编程语言和编译原理中,该操作称为 Kleene 闭包)。加号(+)操作符将匹配一次或者多次出现的正则表达式(也叫做正闭包操作符),问号(?)操作符将匹配零次或者一次出现的正则表达式。还有大括号操作符({}),里面或者是单个值或者是一对由逗号分隔的值。这将最终精确地匹配前面的正则表达式 N 次(如果是{N})或者一定范围的次数;例如,{M,N}将匹配 M~N 次出现。 </?[^>]+> 匹配全部有效的(和无效的)HTML标签;
- ⑦ \d+(\.\d*)? 表示简单浮点数的字符串;也就是说,任何十进制数字,后面可以接一个小数点和零个或者多个十进制数字,例如“0.004”、“2”、“75.”等。
实际上,以上特殊符号及其规则只是正则匹配表达式中的核心部分,还有一些规则笔者并没有涵盖到,一者过于庞杂,会对初学者造成一种很难的假象,二者核心字符与规则之外的很少设计,故而不需要刻意关注。介绍到这里,读者就可以为了完成一定的匹配目标来书写其正则表达式了。值得一提的是,不管是office(word)还是其他高级的文档编辑软件,这种正则匹配都有涉及,掌握这一部分内容,还有其他用处。
【2】re模块的主要函数
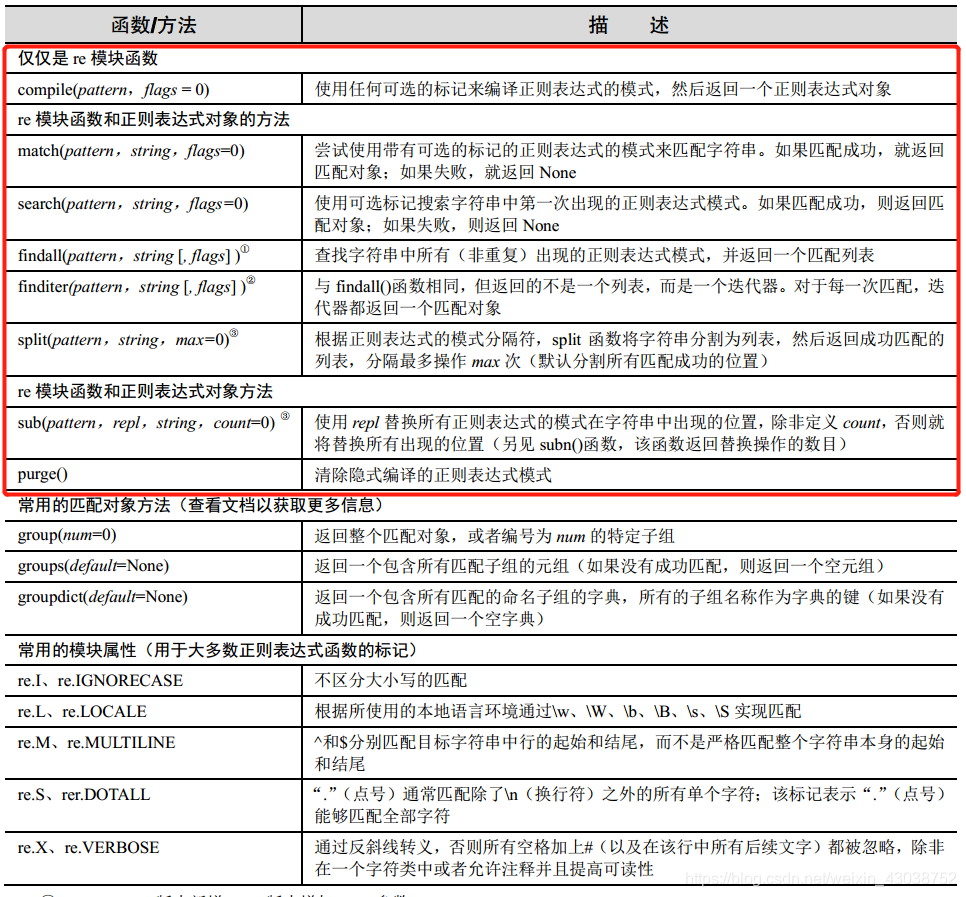
一开始,希望读者能够对主要的函数有大致的把握,笔者给出了这一张图,其中红框标识出来的部分为需要重点掌握的内容。接下来,将介绍每个函数的具体用法。
1.compile():我们写出来的正则表达式一开始是一个字符串对象,那么,在后续匹配,检索的过程中,需要转换为 regex 对象,这就是compile需要完成的;
2.当处理正则表达式时,除了正则表达式对象之外,还有另一个对象类型:匹配对象。这些是成功调用 match()或者 search()返回的对象。匹配对象有两个主要的方法:group()和groups()。group()要么返回整个匹配对象,要么根据要求返回特定子组。groups()则仅返回一个包含唯一或者全部子组的元组。如果没有子组的要求,那么当group()仍然返回整个匹配时,groups()返回一个空元组;
3.match()是将要介绍的第一个 re 模块函数和正则表达式对象(regex object)方法。match()函数试图从字符串的起始部分对模式进行匹配。如果匹配成功,就返回一个匹配对象;如果匹配失败,就返回 None;
4.search()的工作方式与 match()完全一致,不同之处在于 search()会用它的字符串参数,在任意位置对给定正则表达式模式搜索第一次出现的匹配情况。如果搜索到成功的匹配,就会返回一个匹配对象;否则,返回 None。


5. findall()查询字符串中某个正则表达式模式全部的非重复出现情况。这与 search()在执行字符串搜索时类似,但与 match()和 search()的不同之处在于,findall()总是返回一个列表。如果 findall()没有找到匹配的部分,就返回一个空列表,但如果匹配成功,列表将包含所有成功的匹配部分(从左向右按出现顺序排列)。

6.有两个函数/方法用于实现搜索和替换功能:sub()和 subn()。两者几乎一样,都是将某字符串中所有匹配正则表达式的部分进行某种形式的替换。用来替换的部分通常是一个字符串,但它也可能是一个函数,该函数返回一个用来替换的字符串。subn()和 sub()一样,但 subn()还返回一个表示替换的总数,替换后的字符串和表示替换总数的数字一起作为一个拥有两个元素的元组返回。

7.re 模块和正则表达式的对象方法 split()对于相对应字符串的工作方式是类似的,但是与分割一个固定字符串相比,它们基于正则表达式的模式分隔字符串,为字符串分隔功能添加一些额外的威力。如果你不想为每次模式的出现都分割字符串,就可以通过为 max 参数设定一个值(非零)来指定最大分割数。如果给定分隔符不是使用特殊符号来匹配多重模式的正则表达式,那么 re.split()与str.split()的工作方式相同。
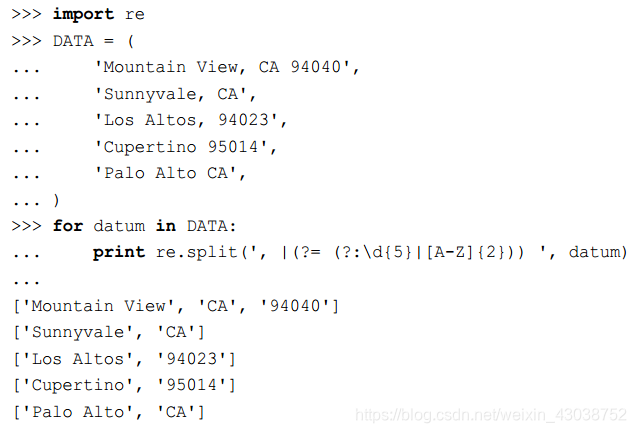
【3】Python实操与常见匹配
在现实工程中,我们的算法往往需要去匹配的内容都很实际,比如识别手机号、电话号、邮箱地址、去除一段HTML代码中的所有标签、更不必说负数、复数、浮点数等内容了。以下做一归纳:
# 匹配手机号
1[35678]\d{9}
# 匹配邮箱号
1\d{1,15}@\w{2,6}\.com
# 匹配浮点数
\d+(.\d+)?
# 匹配汉字
[\u4e00-\u9fa5]+
# 匹配单字符,英文、数字、特殊符号
[\x00-\xff]
# 匹配全部有效的(和无效的)HTML标签
</?[^>]+>常见匹配持续更新……














 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









