







logistics模型
建立一个logistic回归模型来预测学生是否被大学录取。假设你是一所大学的系主任,你想根据每个申请者在两次考试中的成绩来决定他们的入学机会。建立一个分类模型来评估申请人根据这两次考试的分数,录取的可能性。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data1 = pd.read_csv('ex2data1.txt', header=None, names=['Exam1', 'Exam2', 'a'])
a = data1.iloc[:,-1]
data1 = (data1 - data1.mean())/data1.std()
data1.insert(2,'admitted',a)
positive = data1[data1['admitted'].isin([1])]
negative = data1[data1['admitted'].isin([0])]
fig, ax = plt.subplots(figsize=(12, 8))
ax.scatter(positive['Exam1'], positive['Exam2'], s=50, c='b', marker='o', label='Admitted')
ax.scatter(negative['Exam1'], negative['Exam2'], s=50, c='r', marker='x', label='Not Admitted')
ax.legend()
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')
plt.show()
读取数据并将数据归一化后分为是否录取两类(不归一化的话用有可能因数据太大导致迭代发散)

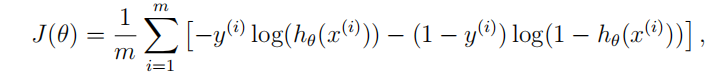
由sigmoid函数的cost函数的定义编写相关代码,并初始化X,Y,theta,学习系数Alpha和迭代次数num
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def compute_cost(theta, x, y):
A = sigmoid(x @ theta)
inner1 = -y * np.log(A)
inner2 = (1 - y) * np.log(1 - A)
return np.sum(inner1 - inner2) / len(x)
data1.insert(0, 'Ones', 1)
dat_array = np.array(data1)[:, 1:3]
x1 = np.array(data1)[:, :-2]
y1 = np.array(data1)[:, - 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1055
1055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









