







IDEA在不修改端口的前提下,
有如下文件:
web目录——>input1.html
项目直属目录——>input2.html
1.不运行tomcat,直接点浏览器标志跳转到网页
input1.html端口号是63342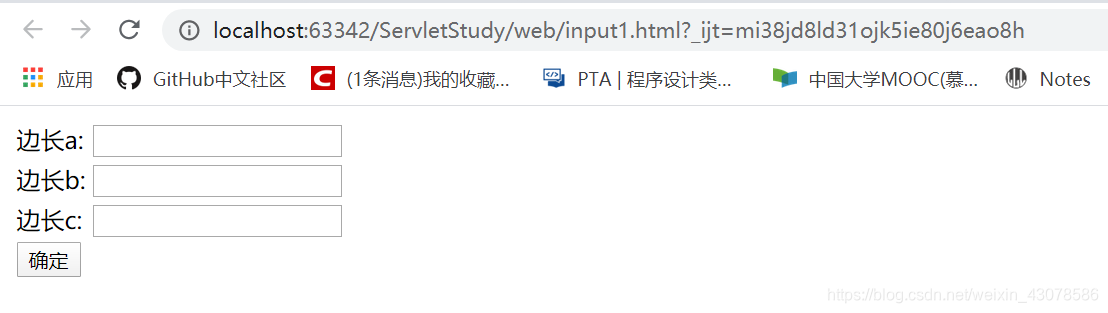
input2.html端口号是63342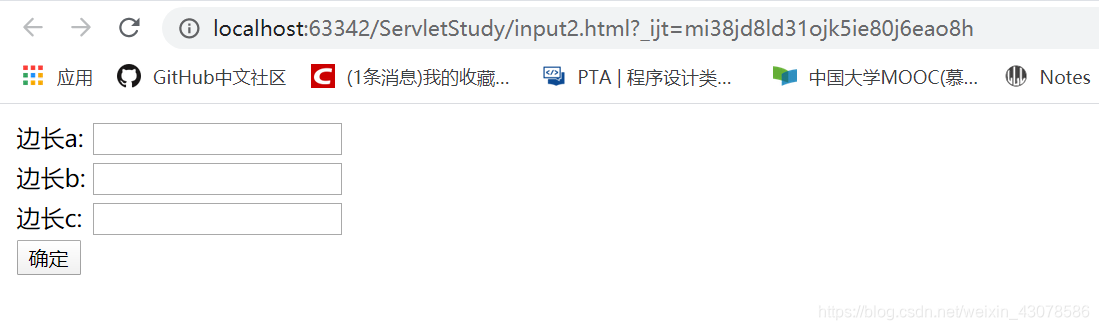
2.运行tomcat,直接点浏览器标志跳转到网页
input1.html端口号是tomcat的默认端口号8080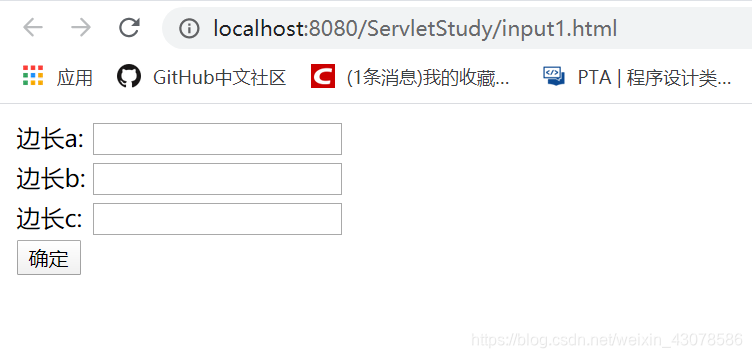
input2.html端口号是63342

如果将http://localhost:8080/ServletStudy/input1.html中的input1.html改为input2.html,将会有404问题
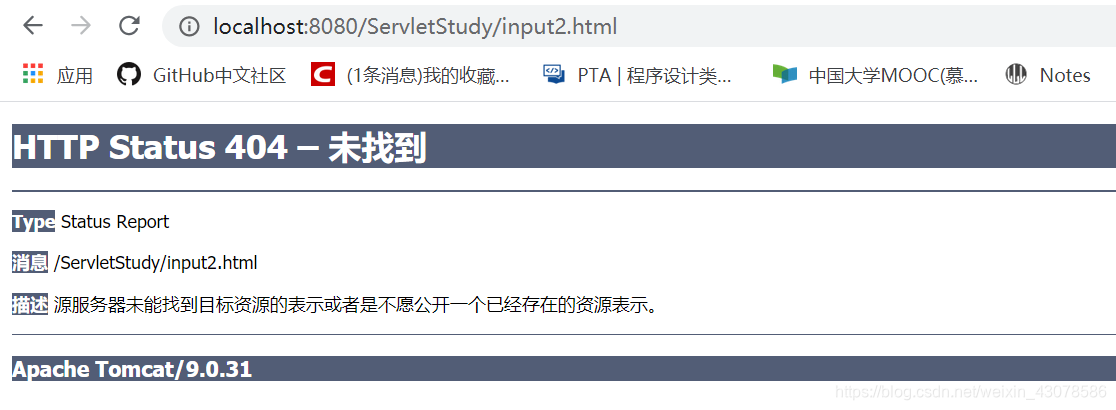
试着把html文件放在web目录下,问题解决,html可以成功跳转到servlet!
所以一般都是把html、jsp文件放在web或者webapp目录下,否则会404错误。
刚开始学servlet自己一直把html文件放在项目直属目录下,导致一直404错误。网上查资料,修改Setting那里的端口号或者是修改tomcat中的端口号,总是会发生端口号冲突,今天早上试着试着就发现了问题所在。
通过这件事,明白到:尽管现在网上资源很多,有问题可以方便地查询,之前敲代码时遇到的问题大都可以通过上网解决。但是,要有自己辨别对错的能力,不能在网上看到一个别人的解决方法就乱试,导致最后修改了很多地方,不对的也给修改错了,这样只会越来越乱。
总之,解决问题的能力还很差,切记,遇到报错与问题,静下心来慢慢分析,慢慢解决,bug总会解决的。

















 1860
1860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









