







转载自不会写作文的李华
文章地址:https://blog.csdn.net/qq_40195360/article/details/88378248
文章目录
前言
数据预处理的工具有许多,在我看来主要有两种:pandas数据预处理和scikit-learn中的sklearn.preprocessing数据预处理。
前面更新的博客中,我已有具体的根据pandas来对数据进行预处理,原文请点击这里。其中主要知识点包括一下几个方面:
- 数据的集成:merge、concat、join、combine_first;
- 数据类型转换:字符串处理(正则表达式)、数据类型转换(astype)、时间序列处理(to_datetime)等;
- 缺失值处理:查找、定位、删除、填充等;
- 重复值处理:查找、定位、删除等;
- 异常值处理:根据原理自定义函数处理异常数据(不推荐);
- 特征修改:增加、删除、变换(简单函数变换)、离散化等;
- 数据抽样:简单随机抽样、分层抽样等;
- …………
这里,本文主要针对与在scikit-learn中的sklearn.preprocessing数据预处理。
首先,sklearn.preprocessing包提供了几个常用的实用函数和转换器类(这里主要介绍类的使用),以将原始特征向量转换为更适合下游估计器的表示。
preprocessing中有很多的类,但主要有以下几种常用的数据处理类:
1. 标准化
标准化相信大家接触的也多所以这里就不过多介绍,这里只是顺带提一下。
- StandardScaler
- MinMaxScaler
- MaxAbsScaler
- RobustScaler
1. StandardScaler
Standardization标准化:将特征数据的分布调整成标准正太分布,也叫高斯分布,也就是使得数据的均值维0,方差为1.
2. MinMaxScaler
最小-最大规范化对原始数据进行线性变换,变换到[0,1]区间(也可以是其他固定最小最大值的区间)每个特征中的最小值变成了0,最大值变成了1.
3. MaxAbsScaler
原理与上面的很像,只是数据会被规模化到[-1,1]之间。也就是特征中,所有数据都会除以最大值。这个方法对那些已经中心化均值维0或者稀疏的数据有意义,后者不会改变矩阵的稀疏性,是0的还是0,而前者会改变。
4. RobustScaler
根据四分位数来缩放数据。对于数据有较多异常值的情况,使用均值和方差来标准化显然不合适,按中位数,一、四分位数缩放效果要好。
2. 非线性变换
- QuantileTransformer
- PowerTransformer
1. QuantileTransformer
QuantileTransformer 类将每个特征缩放在同样的范围或分布情况下。但是,通过执行一个秩转换能够使异常的分布平滑化,并且能够比缩放更少地受到离群值的影响。但是它的确使特征间及特征内的关联和距离失真了。以下是QuantileTransformer参数:
sklearn.preprocessing.QuantileTransformer(n_quantiles=1000, output_distribution=’uniform’,
ignore_implicit_zeros=False, subsample=100000, random_state=None, copy=True)
- 1
- 2
该方法将特征变换为均匀分布或正态分布(通过设置output_distribution=‘normal’)。因此,对于给定的特性,这种转换倾向于分散最频繁的值。它还减少了(边缘)异常值的影响:因此,这是一个健壮的预处理方案。
2. PowerTransformer
映射到高斯分布。在许多建模场景中,数据集中的特性是正常的。幂变换是一类参数的单调变换,其目的是将数据从任意分布映射到尽可能接近高斯分布,以稳定方差和最小化偏度。
PowerTransformer目前提供了两个这样的幂变换,Yeo-Johnson变换和Box-Cox变换,利用极大似然估计了稳定方差和最小偏度的最优参数。并且,box-Cox要求输入数据严格为正数据,而Yeo-Johnson支持正负数据。参数如下:
sklearn.preprocessing.PowerTransformer(method=’yeo-johnson’, standardize=True, copy=True)
- 1
注意:PowerTransformer只有在0.20.0才有,不然会报错。 你可以使用conda update scikit-learn来进行更新。
3. 正则化( Normalizer)
归一化是缩放单个样本以具有单位范数的过程,这里的”范数”,可以使用L1或L2范数。如果你计划使用二次形式(如点积或任何其他核函数)来量化任何样本间的相似度,则此过程将非常有用。
这个观点基于 向量空间模型(Vector Space Model) ,经常在文本分类和内容聚类中使用。
sklearn.preprocessing.Normalizer(norm=’l2’, copy=True)
- 1
其中,norm : ‘l1’, ‘l2’, or ‘max’, optional (‘l2’ by default)
4. 编码分类特征
- OrdinalEncoder
- OneHotEncoder
1. OrdinalEncoder
这个类好幸也是0.20.0才出来的也要更新scikit-learn,资料相对较少,根据原文的翻译大概有以下几个意思:
这个转换器的输入应该是一个类似数组的整数或字符串,表示由分类(离散)特性获得的值。特征被转换为序数整数。这将导致每一个特征都有一列整数(0到n-类别-1)。
sklearn.preprocessing.OrdinalEncoder(categories=’auto’, dtype=<class ‘numpy.float64’>)
- 1
然而,这种整数表示不能直接与所有Scikit-Learning估值器一起使用,因为这些估计器需要连续的输入,并且将类别解释为被排序,这通常是不需要的(即浏览器的集合是任意排序的)。
2. OneHotEncoder
另一种将分类特征转换为能够被scikit-learn中模型使用的编码是one-of-K或one-hot编码,在 OneHotEncoder 中实现,也称为一个热编码或虚拟编码。这个类使用 n 个可能值转换为 n值化特征,将分类特征的每个元素转化为一个值,它可以将有n种值的一个特征变成n个二元的特征,选择该选项则对应特征值为1否则为0。
sklearn.preprocessing.OneHotEncoder(n_values=None, categorical_features=None,
categories=None, sparse=True, dtype=<class ‘numpy.float64’>, handle_unknown=’error’)
- 1
- 2
默认情况下,每个特征使用几维的数值由数据集自动推断。当然,你也可以通过使用参数n_values来精确指定
5. 离散化
离散化(也称为量化或绑定)提供了一种将连续特征划分为离散值的方法。某些具有连续特征的数据集可能受益于离散化,因为离散化可以将连续属性的数据集转换为仅具有名义属性的数据集。
- KBinsDiscretizer
- Binarizer
1. KBinsDiscretizer
k个等宽箱的离散化特征,默认情况下,输出是one-hot编码成稀疏矩阵,并且可以使用encode参数。对于每个特性,在fit再加上分箱的数量,他们会定义间隔。
sklearn.preprocessing.KBinsDiscretizer(n_bins=5, encode=’onehot’, strategy=’quantile’)
- 1

2. Binarizer
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。二值化是对文本计数数据的常见操作,分析人员可以决定仅考虑某种现象的存在与否。
sklearn.preprocessing.Binarizer(threshold=0.0, copy=True)
- 1
当k=2时,当bin边处于值阈值时,Binarizer类似于KBinsDiscreizer。
6. 缺失值处理(Imputer)
针对于最新的0.20.0版本的scikit-learn中,Imputer好象是被取代了换成了sklearn.impute这里面包含两个类:
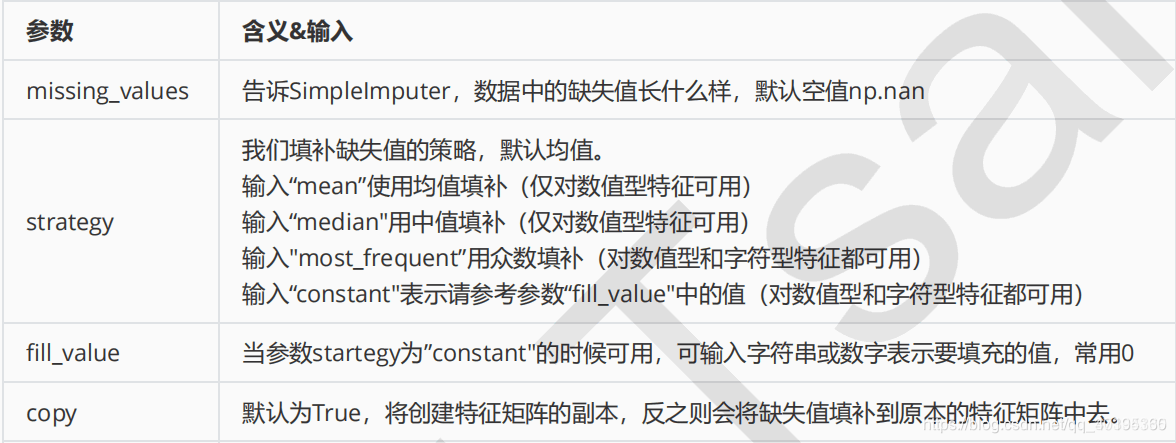
sklearn.impute.SimpleImputer(missing_values=nan, strategy=’mean’, fill_value=None, verbose=0, copy=True)
- 1
sklearn.impute.MissingIndicator(missing_values=nan, features=’missing-only’, sparse=’auto’, error_on_new=True)
- 1
由于用的较多的是SimpleImputer,下面给出一般参数:
7. 生成多项式特征(PolynomialFeatures)
在机器学习中,通过增加一些输入数据的非线性特征来增加模型的复杂度通常是有效的。一个简单通用的办法是使用多项式特征,这可以获得特征的更高维度和互相间关系的项。多项式特征经常用于使用多项式核函数的核方法(比如SVC和KernelPCA)。这在 PolynomialFeatures 中实现:
sklearn.preprocessing.PolynomialFeatures(degree=2, interaction_only=False, include_bias=True)
- 1
8. 自定义转换器(FunctionTransformer)
我们经常希望将一个Python的函数转变为transformer,用于数据清洗和预处理。可以使用FunctionTransformer方法将任意函数转化为一个Transformer。
sklearn.preprocessing.FunctionTransformer(func=None, inverse_func=None, validate=None,
accept_sparse=False, pass_y=’deprecated’, check_inverse=True, kw_args=None, inv_kw_args=None)
- 1
- 2
总结
自0.20.0版本的scikit-learn中,变化还是挺大的,其中有些类增加了,有些类减少了(其他模块中去了)。所以对于新的知识个人建议去scikit-learn官网中进行查找阅读。
</div>
欢迎使用Markdown编辑器
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片:
带尺寸的图片:
居中的图片:
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' | ‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" | “Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash | – is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t   . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图::
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
注脚的解释 ↩︎














 4355
4355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









