






代价函数 梯度下降
什么是代价函数?大家都知道误差。误差就是实际值与预测值之间的差别。
损失函数(Loss Function )是定义在单个样本上的,算的是一个样本的误差。
代价函数(Cost Function )是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
概况来讲,任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数都可以叫做代价函数C(θ),如果有多个样本,则可以将所有代价函数的取值求均值,记做J(θ)。因此很容易就可以得出以下关于代价函数的性质:
- 对于每种算法来说,代价函数不是唯一的;
- . 代价函数是参数θ的函数;
3 .总的代价函数J(θ)可以用来评价模型的好坏,代价函数越小说明模型和参数越符合训练样本(x, y);
4 .J(θ)是一个标量;
对于线性回归来说

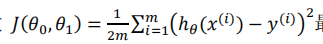
m:训练样本的个数;
hθ(x):用参数θ和x预测出来的y值;
y:原训练样本中的y值,也就是标准答案
上角标(i):第i个样本
当我们确定了模型h,后面做的所有事情就是训练模型的参数θ。那么什么时候模型的训练才能结束呢?这时候也涉及到代价函数,由于代价函数是用来衡量模型好坏的,我们的目标当然是得到最好的模型(也就是最符合训练样本(x, y)的模型)。因此训练参数的过程就是不断改变θ,从而得到更小的J(θ)的过程。理想情况下,当我们取到代价函数J的最小值时,就得到了最优的参数θ。
在优化参数θ的过程中,最常用的方法是梯度下降,这里的梯度就是代价函数J(θ)对θ1, θ2, …, θn的偏导数
说到梯度下降,梯度下降中的梯度指的是代价函数对各个参数的偏导数,偏导数的方向决定了在学习过程中参数下降的方向,学习率(通常用α表示)决定了每步变化的步长,有了导数和学习率就可以使用梯度下降算法(Gradient Descent Algorithm)更新参数了。
梯度下降的基本过程就和下山的场景很类似。
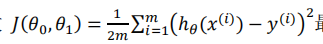
首先,我们有一个可微分的函数。这个函数就代表着一座山。我们的目标就是找到这个函数的最小值,也就是山底。根据之前的场景假设,最快的下山的方式就是找到当前位置最陡峭的方向,然后沿着此方向向下走,对应到函数中,就是找到给定点的梯度 ,然后朝着梯度相反的方向,就能让函数值下降的最快!因为梯度的方向就是函数之变化最快的方向。
所以,我们重复利用这个方法,反复求取梯度,最后就能到达局部的最小值,这就类似于我们下山的过程。

上图中的α是什么含义?
α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离,以保证不要步子跨的太大扯着蛋,哈哈,其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以α的选择在梯度下降法中往往是很重要的!α不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点。

为什么要梯度要乘以一个负号?
梯度前加一个负号,就意味着朝着梯度相反的方向走!我们都知道,梯度的方向实际就是函数在此点上升最快的方向!而我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号。
















 1909
1909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











