







前段时间,360 公司董事长周鸿祎用个人账号在视频平台上发布一条动态:“红衣大叔成就解锁:万米高空掼蛋初体验”,视频中,他在前往美国的飞机上偶遇四位企业家,一同在万米高空玩掼蛋游戏。网友看了直呼:“这是一场千亿级别的掼蛋啊!”

(图源:网易视频)
掼蛋起源于江苏淮安,由当地的扑克游戏“跑得快”和“八十分”演化而来,在淮安方言里,“掼”是摔、砸的意思,打牌人将手中的“蛋”,即“炸弹”砸向桌面的动作,即为“掼蛋”。简单来说,掼蛋需要两副 108 张扑克牌,4 人两两组队进行,游戏规则综合了“跑得快”“八十分”“斗地主”等牌类游戏,哪队玩家最先出完手中的牌,即为胜。
淮安当地流传着一句话:“饭前不掼蛋,等于没吃饭;饭后不掼蛋,等于白吃饭!” ,从江苏火到全国,从体制内火到金融圈,掼蛋成为了新晋“社交密码”。游戏规则简单、容易凑到局、变幻莫测的配牌出牌方式,让每一局游戏都充满了悬念和挑战。这就是掼蛋独特魅力。

(图片来源:网络)
线下的掼蛋爱好者们打得火热,线上的掼蛋游戏也因方便、快捷等优点,成为大家休闲娱乐的热门选择。与其他手游相比,棋牌类型游戏更聚焦于玩家心态,是否能抓住玩家心理,是决定玩家留存率的关键因素,甚至能够直接影响游戏营收。
例如,在游戏上线初期、冷启动阶段或非高峰时段,如半夜,常常难以聚集足够的真人玩家,这限制了玩家的游戏体验。另外,传统的规则机器人缺乏智能性,无法提供有挑战性和策略性的对抗,玩家需求得不到满足,游戏体验感差,这直接导致用户留存率和活跃度的大幅下降。随着市场竞争的加剧,获取游戏新用户的成本也在不断上升,这对游戏公司的财务状况也构成了重大压力。
针对以上痛点,网易数智游戏 AI 智能体解决方案 能够为游戏公司提供有效的应对策略:
1. 提升游戏策略深度与竞技性
通过模仿学习,AI 智能体掌握了丰富的掼蛋策略和战术,能够根据牌局状况灵活应用,如精准计算牌力、巧妙配牌、适时进贡、合理利用王炸等高级技巧。这不仅提高了游戏的策略维度,使每场对决充满智谋较量,还提升了游戏的竞技性,吸引热衷于策略博弈的玩家群体。
2. 实现动态平衡与公平竞赛
AI 智能体能够根据玩家的技能水平动态调整自身策略强度,确保游戏对局既具有挑战性又不失公平。新手玩家面对 AI 时,可以得到适中的引导与锻炼;而对于经验丰富的玩家,AI 能提供高强度的对抗,保持游戏的刺激性。这种动态平衡机制有助于维持玩家持久的兴趣,促进玩家技能的逐步提升。

3. 持续优化游戏规则与系统
作为线上掼蛋游戏的一部分,AI 智能体可以充当规则验证器和优化工具。通过大量的模拟对局,AI可以帮助检测游戏规则的合理性与漏洞,为游戏开发者提供数据支持,以便及时调整规则设置,保证游戏公平性和趣味性的最佳结合。同时,AI 的反馈数据可用于评估新功能或改版效果,助力游戏迭代升级。
4. 扩展玩法模式与社交互动
AI 智能体可以融入多元化的游戏模式,如单人挑战模式、人机合作模式、AI 教学模式等,丰富玩家的游戏体验。在人机合作模式中,AI 智能体作为可靠的队友,能与玩家形成有效配合,提升团队作战的乐趣。AI 教学模式则通过演示高水平决策过程,帮助玩家提升技巧。此外,AI 智能体的参与也能在一定程度上缓解线上匹配等待时间长的问题,提升玩家满意度。
5. 24/7 全天候游戏服务与稳定性保障
AI 智能体不受时间限制,能够为玩家提供全天候无间断的游戏服务,满足不同时间段玩家的游戏需求。同时,AI 的稳定性和可靠性高于人类玩家,避免了因网络波动、临时离线等人为因素导致的游戏中断,为玩家创造顺畅、连贯的游戏环境。
近期,在与网易数智游戏 AI 算法专家何竞交谈过程中,小智得知网易数智已助力多家棋牌类游戏公司落地并应用游戏 AI 智能体解决方案。今天,我们以广受欢迎的棋牌手游《欢乐掼蛋》为例,一探 AI 智能体与棋牌游戏结合的奇妙火花。
大规模预训练模型, 深度强化学习,深度模仿学习等技术开发的智能竞技机器人,带来更加真实的游戏体验,助力提升游戏品质。游戏AI智能体解决方案已落地多项游戏!欢迎大家前来畅聊探讨~
- 方案详情可以👉 ✉ V:LTT936
- 或查看以下卡片点击按钮【立即咨询】👇
 https://grow.163.com/solution/combat-robot?from=csdn_yxzy_0426
https://grow.163.com/solution/combat-robot?from=csdn_yxzy_0426
(图片来源:网络)
首先,向大家介绍《欢乐掼蛋》游戏的相关规则:
牌型:掼蛋游戏中共有十种牌型,分别是单张、对子、三张、三带二、三连对(也称为两连对)、钢板(三顺)、顺子、同花顺、天王炸和普通炸弹;
普通牌型:普通牌型的大小比较依据牌点数决定,通常 A 最大,2 最小,但同花顺中的牌型比较特殊,最小的同花顺是 A-2-3-4-5,最大的同花顺是 10-J-Q-K-A;
炸弹:炸弹是指四张及以上相同数值的牌,最大的炸弹是天王炸,即两个大王和两个小王。普通炸弹的大小则根据所含牌的数量决定,数量多的炸弹大于数量少的炸弹;
逢人配(红星):在掼蛋中,红桃 2 被视为逢人配,可以替代除大小王之外的任何牌;
游戏流程:游戏通常由四人分成两组进行对抗,其中东家负责洗牌,南家负责翻牌;
出牌规则:掼蛋的出牌规则与斗地主有所不同。例如,掼蛋中不允许三带一,顺子最多五张,钢板最多三张。
在当前游戏 AI 开发领域,尤其是针对规则复杂、策略性强的掼蛋游戏,各类方法论各显神通,主要可以分为行为树、强化学习、模仿学习三类。
1.行为树:传统框架的坚守与局限
行为树(Behavior Tree, BT),作为游戏 AI 领域的常用工具,以其结构清晰、调试方便的特点,广泛应用于各类游戏的 AI 设计。然而,在应对掼蛋游戏的特殊规则与复杂策略时,其局限性逐渐显现:
-
规则复杂性束缚: 掼蛋游戏规则繁多,如逢人配、级牌等特色规则,加上丰富的牌型组合与团队协作要求,构建全面的行为树结构需要投入大量人力物力,且随着游戏更新或策略演变,维护工作量巨大;
-
策略灵活性缺失:预设的行为路径难以应对掼蛋实战中层出不穷的变数与对手策略,可能导致 AI 行为过于程式化,缺乏人类玩家所展现的机敏应变与创造性决策。
2.强化学习:前沿探索的潜力与制约
强化学习(Reinforcement Learning, RL),作为游戏 AI 研究的热点,其自我学习与优化能力颇具吸引力。但在掼蛋 AI 的实际应用中,却遭遇了如下难题:
-
海量数据困局:强化学习需要大量试错以求最优策略,而掼蛋的高度复杂性意味着所需训练数据呈指数级增长,带来漫长训练周期与高昂计算成本;
-
环境动态性挑战:对手策略变化、牌局随机性等因素使掼蛋环境处于持续变动中,这对强化学习算法的稳定性与收敛速度构成严峻考验;
-
奖励机制设计难题:设计合适的奖励函数以正确引导 AI 学习掼蛋的复杂策略是一项挑战,既要考虑短期得分,也要兼顾长远合作和竞争关系。
3.模仿学习:创新抉择的智慧源泉
正是在上述主流方法面临挑战的背景下,模仿学习(Imitation Learning, IL)以其独特优势,成为了我们打造卓越掼蛋 AI 的首选途径:
-
速成大师之道:模仿学习如同站在巨人的肩膀上,直接从人类专家或顶级玩家的游戏记录中汲取精华,无需从零开始摸索,极大地缩短了学习周期,降低了计算资源消耗。
-
驾驭复杂策略:通过观察与模仿人类玩家的决策过程,AI 智能体得以领悟掼蛋中深邃的牌型组合、灵活的战术变换以及微妙的心理战艺术,这些往往是规则难以完全刻画或强化学习难以独立探索的精髓。
-
传承人类智慧:模仿学习保留了人类玩家在实战中磨砺出的直觉、经验和创新策略,使得 AI 智能体展现出更贴近人类的决策风格,增强了游戏的沉浸感与竞技乐趣。
-
随需应变的适应力:当游戏环境或玩家行为模式发生变化时,只需更新模仿学习的训练数据,AI 智能体就能迅速适应新情况,无需对行为树进行繁琐调整或重新配置强化学习参数。
综上所述,尽管行为树和强化学习在游戏 AI 开发中各有其应用场景,但在应对掼蛋游戏的特殊挑战时,它们分别遭遇了复杂性管理难题、样本效率瓶颈、环境适应性问题及奖励函数设计困难。相比之下,模仿学习凭借其快速习得技能、精准捕获复杂策略、融入人类智慧及强大适应性等优势,成为我们构建高效、智能且富有竞技魅力的掼蛋 AI 的理想选择。经过模仿学习训练的掼蛋 AI 智能体,已然展现出卓越的表现,有力验证了这一决策的正确性与前瞻性。
方案详情:
大规模预训练模型, 深度强化学习,深度模仿学习等技术开发的智能竞技机器人,带来更加真实的游戏体验,助力提升游戏品质。游戏AI智能体解决方案已落地多项游戏!欢迎大家前来畅聊探讨~
- 方案详情可以👉 ✉ V:LTT936
- 或查看以下卡片点击按钮【立即咨询】👇
领取干货资料:
- 《游戏 AI 实践指南》免费领取方式——评论区留言【指南】或 ✉V:LTT936,立即get√
- 《2023 年度游戏安全观察与实践报告》,戳我立即领取!
- 《2023年中国移动游戏私域运营白皮书》扫描下方二维码领取~

01 接入流程
1.录像文件传输
网易数智提供了便捷的文件上传接口,支持轻松上传录像文件。
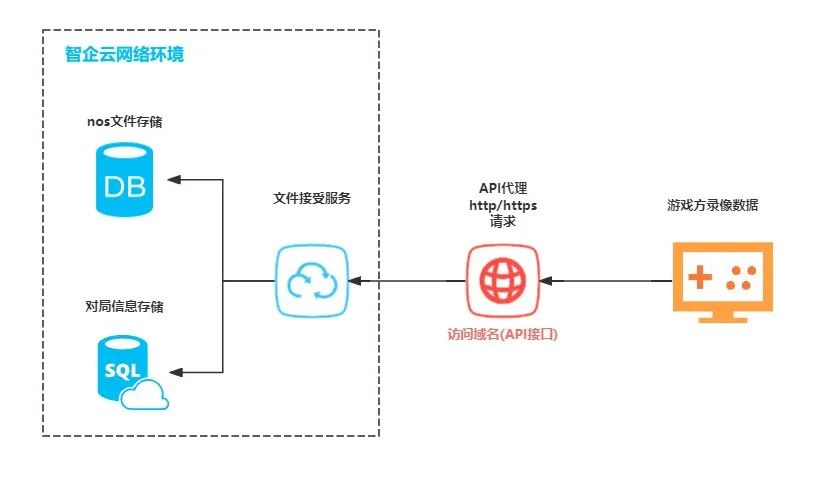
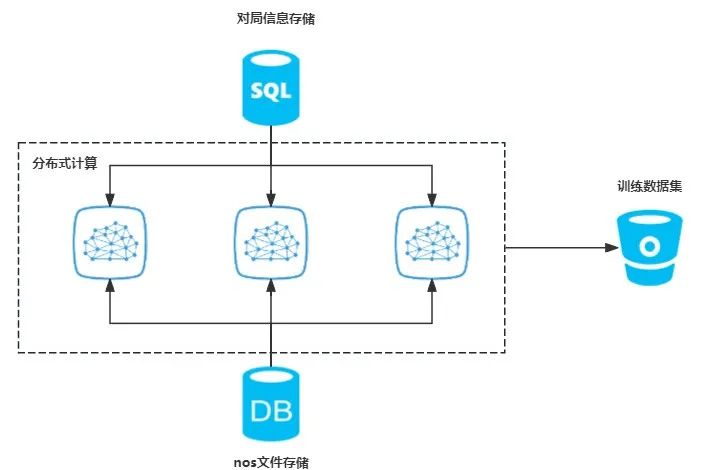
2.数据集构建
使用 ray 集群分布式解析录像文件,加速数据集构建。
02 状态空间定义
1.卡牌表示
掼蛋模仿学习采用的是 9*14 的矩阵来对每个可行的牌组合进行编码如图所示:

具体来说,掼蛋游戏与斗地主不同,其出牌动作更加复杂多样,需要考虑花色、级牌以及逢人配牌在出牌时的不同组合。同时,随着级牌的变化,牌点大小和万能牌也会相应变化。为此,我们使用以下方式对卡牌进行编码:
首先,用 4*14 的矩阵,对卡牌(除逢人配,大小王以外)进行编码。其中行表示四种不同的花色,列对应于卡牌的点数,矩阵中的值则表示该卡牌的数量;
其次,使用 3*14 的矩阵,对卡牌中的级牌信息进行编码,对于级牌分为两种:第一种是红心级牌:逢人配牌,可以变成大小王以外的任何牌,在组牌时点数不具有意义。第二种是非红心级牌:级牌,是除大小王以外最大的牌,在组牌时仍然需要考虑点数。因此,在组牌过程中,矩阵的第一行表示卡牌中是否有红心级牌,如果有则全部置 1。第二行为该红心级牌的标识位,用于表示对应的级牌点数。第三行表示卡牌中非红心级牌的数量;
最后,使用 2*14 的矩阵,对卡牌的 Joker 信息编码,如果手牌中有对应的王牌,对应行则全部加 1。
2.状态表示
状态空间的信息分为三种,分别是卡牌信息、回合信息和历史信息。
-
卡牌信息:将所有的 9*14 的卡牌矩阵进行堆叠得到 10*9*14 的矩阵;
-
回合信息:将剩余手牌数量与该局游戏级牌,拉平并拼接得到 1*125 的向量;
-
历史信息:将前 8 次出牌的卡牌进行编码得到 8*9*14 的矩阵,历史两轮的动作序列可表示为 2*504。
掼蛋的状态特征设计,如下表所示:
| 特征 | 大小 | ||||
| 手牌 | 1*9*14 | ||||
| 所有人已打出的牌 | 4*9*14 | ||||
| 最近一次队友的动作 | 1*9*14 | ||||
| 最近一次上家的动作 | 1*9*14 | ||||
| 最近一次下家的动作 | 1*9*14 | ||||
| 其他玩家手牌的并集 | 1*9*14 | ||||
| 上一个最大牌(开局为pass) | 1*9*14 | ||||
| 所有人剩余手牌数量 | 4*28 | ||||
| 该局游戏级牌 | 1*13 | ||||
| 前2轮出牌的历史动作 | 2*504 | ||||
💡 提前解锁完整文章内容,可以关注小智公众号【游戏智眼】,获取最新游戏行业资讯~
👍收藏点赞关注我,下期内容进行全篇分享~不见不散!
方案详情:
游戏AI智能体解决方案已落地多项游戏!欢迎大家前来畅聊探讨~
- 方案详情可以👉 ✉ V:LTT936
- 或查看以下卡片点击按钮【立即咨询】👇
领取干货资料:
- 《游戏 AI 实践指南》免费领取方式——评论区留言【指南】或 ✉V:LTT936,立即get√
- 《2023 年度游戏安全观察与实践报告》,戳我立即领取!
- 《2023年中国
- 移动游戏私域运营白皮书》扫描下方二维码领取~
-
— END—
我来自网易~ 是你最得力的游戏行业战略家,也是最硬核的游戏技术布道师,一起让技术发光~ 欢迎各位游戏人一起探讨交流~点赞👍关注❤

















 2086
2086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









