







introduction
本文是参考了以下经典论文和网络上其它解读文章。
Effective Approaches to Attention-based Neural Machine Translation
网络上有很多attention的解读,但大部分是复制论文和莫名其妙的公式,前几天深入看了下论文和代码才略微搞懂一些,便记录一下我对attention的理解,以便初学者和我理解。
什么是attention
attention可以简单的理解为,当我读完一句话,再去预测一个词时,我需要从开始的那一句话提炼出哪些精华。

attention矩阵是一个mxn维的矩阵,m、n分别是encoder和decoder时间步的长度。矩阵的明亮程度决定了当我们翻译某一个词时需要从原文集中的注意力。
怎么计算attention
又要贡献出这幅图了,我在论文的原图上加了几个符号以便理解。


这里的h都是隐藏层的输出,与无attention别无二样。唯一的区别是引入了attention权重和上下文向量。
1、attention权重向量a的计算方法在文中提供了四种,看下图

2、计算得到权重向量便可以以它为权重,对encoder的隐藏层向量作加权平均得到上下文向量C

3、得到上下文向量,我们可以将它与一开始的隐藏层做级联,再连接FNN后激活,作为新的decoder隐藏层,到此接下来就和无attention机制一样了。

4、由新的隐藏层再链接FNN并用softmax激活得到预测向量,也即和无attention相同。
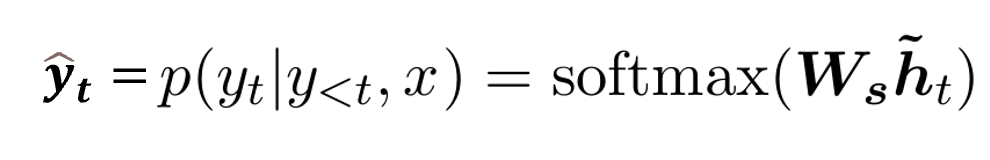
实例讲解attention计算流程

这里还用上面的图为例,注意到encoder有5个时间步;decoder只画出了2个当然后面还有,我们就以计算第二个时间步为例。即t=2:

补充
一些其它技巧:
1、刚才我们介绍的是global attention。
2、hard attention
global attention也可以说是soft attention,即给每一个encoder隐藏层赋予一个权重或概率,而hard attention与之不同的是,我们用0或1来取代原来的权重,即对隐藏层向量,我要么注意要么不注意。
3、local attention:
Soft attention 每次对齐的时候都要考虑前面的encoder的所有hi,所以计算量会很大,因此一种朴素的思想是只考虑部分窗口内的encoder隐藏输出,其余部分为0,在窗口内使用softmax的方式转换为概率。
滑动窗口选择方法:

4、Input-feeding Approach
这个我还没搞懂,大概是说用弱监督,即前一时刻的输出和隐藏层作为当前时刻的输入。
区别于上文介绍的强监督,即前一时刻的真实标签值和隐藏层作为当前时刻的输入。














 7840
7840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









