



 本文介绍了问答系统的工作原理,包括规则式、统计/机器学习和深度学习模型在处理Query时的角色。重点讨论了问答系统的定义、问题类型,如彷真陈述问答、清单问答和定义问答,并提及了时间限制问题和序列问题的复杂性。实战部分提到了使用AC Tree进行问句过滤和命名实体识别的任务。
本文介绍了问答系统的工作原理,包括规则式、统计/机器学习和深度学习模型在处理Query时的角色。重点讨论了问答系统的定义、问题类型,如彷真陈述问答、清单问答和定义问答,并提及了时间限制问题和序列问题的复杂性。实战部分提到了使用AC Tree进行问句过滤和命名实体识别的任务。
1.任务理解
-
问答系统的范畴
-
问答系统的准确度取决于 Query 的方法不同
- 规则式
- 统计/机器学习分类模型 e.g. HMM, CRF
- 深度学习模型 e.g. LSTM, BERT
- 结合以上,取其所长 e.g. Bi-LSTM+CRF
-
问题拆解(Entity Extraction)结合意图类型辨识
2.问答系统
2.1 定义
问答系统外部的行为上来看,其与目前主流资讯检索技术有两点不同:首先是查询方式为完整而口语化的问句,再来则是其回传的为高精准度网页结果或明确的答案字串。
2.2 问题定义类型
问答系统的 input 是自然语言问句,为了有效控制研究变因,多会定制可接受的问题类型来限制研究范围。
- 彷真陈述问答(Factoid Question Answering):最基本的类型,此类系统根据答案语料所述资讯,取出一小段字串作为答案。由于答案的正确与否是根据答案语料的内容来决定,在现实生活中不一定为真,故称为彷真陈述问答。
- 清单问答(List Question Answering):系统把问答范围进一步缩小,限定在人、地、组织等明确的专有名词上。e.g.清单型问句:『请列举美国历届总统』
- 定义问答( Definition Question Answering):若能回答定义问题,以此类推还能定义出其他类型的问题。
除了上述问题定义与资讯内容有关的类型外,还有两种比较複杂的问句类型: - 时间限制问题(Temporally Restricted Questions):时间限制型的问题会在问句中明确指出答案的时间范围限制,比如说以「民国九十年时的国民党主席是谁」这问句来说,系统必须有根据答案语料结构化资料,或上下文来推论正确答案的能力。
- 序列问题(Series of Questions):把问答系统未来的应用定位在互动式的系统上,经过来回多次问答的方式来满足使用者的资讯需求。
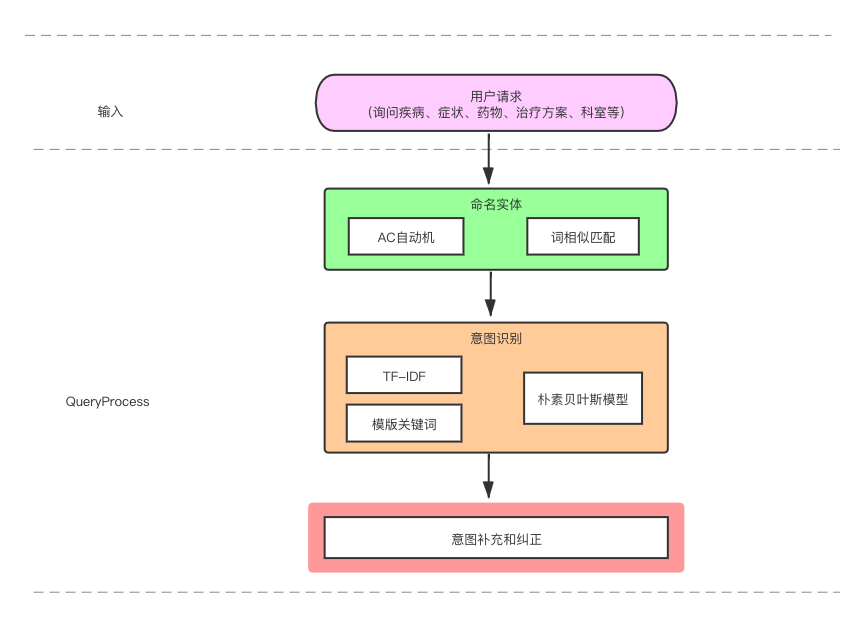
3.实战练习
下载预训练好的文本模型的路径 word2vec_path .
Chinese Word Vectors 中文词向量
我选的是 sgns.wiki.bigram-char (Wikipedia_zh 中文维基百科)
使用AC Tree进行问句过滤
- AC自动机是多模式匹配算法,这样构建fail指针的目的是为了让匹配时可以一直在trie树上面跳
- 当前节点匹配失败时可以通过fail指针跳转到其他节点,不用回溯就可以一直匹配下去了
- 每个节点的失配指针所指向的深度永远是比i小的,因为fail所指向的是永远是后缀
命名实体识别任务实践
此部分代码理解整合在 Task5 当中。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









