






1. Batch Norm
深度学习的话尤其是在CV上都需要对数据做归一化,因为深度神经网络主要就是为了学习训练数据的分布,并在测试集上达到很好的泛化效果,但是,如果我们每一个batch输入的数据都具有不同的分布,显然会给网络的训练带来困难。另一方面,数据经过一层层网络计算后,其数据分布也在发生着变化,此现象称为Internal Covariate Shift。

接下来,我们来看batch norm的伪代码(pseudocode):

2. Layer Norm
BN并不适用于RNN等动态网络和batchsize较小的时候效果不好,LN和BN不同点是归一化的维度是互相垂直的,BN如右侧所示,它是取不同样本的同一个通道的特征做归一化;LN则是如左侧所示,它取的是同一个样本的不同通道做归一化。
如图1右侧部分,BN是按照样本数计算归一化统计量的,当样本数很少时,比如说只有4个。这四个样本的均值和方差便不能反映全局的统计分布息,所以基于少量样本的BN的效果会变得很差。在一些场景中,比如说硬件资源受限,在线学习等场景,BN是非常不适用的。
3. Group Norm
BN的问题,主要是在batch这个维度上进行归一化,但这个维度并不是固定不变的,比如训练和测试时一般不一样,一般都是训练的时候在训练集上通过滑动平均预先计算好平均-mean,和方差-variance参数。而在测试的时候,不再计算这些值,而是直接调用这些预计算好的来用,但,当训练数据和测试数据分布有差别是时,训练时上预计算好的数据并不能代表测试数据,这就导致在训练,验证,测试这三个阶段存在不一致。
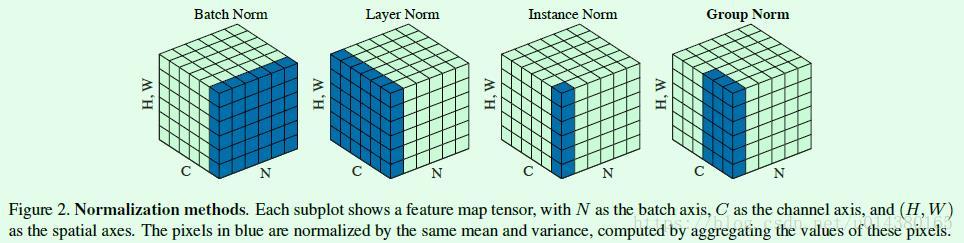
BatchNorm:batch方向做归一化,算N*H*W的均值
LayerNorm:channel方向做归一化,算C*H*W的均值
InstanceNorm:一个channel内做归一化,算H*W的均值
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)*H*W的均值














 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









