






Redis主从模式
主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。
作用:
1、读写分离,性能扩展
2.容灾恢复 从服务顶替主服务
一个主服务器可以拥有多个从服务器,而一个从服务器只能拥有一个主服务器。其结构图如下所示:

主从模式工作机制
主从具体工作机制为(全量复制(初始化)+增量复制),如下图所示:

从服务器Slave向主服务器Master发送SYNC命令
Master接收到SYNC命令后,通过bgsave保存快照,生成RDB文件,同时使用缓冲区记录从现在开始执行的所有的写命令;
Master将快照文件(RDB文件)发送给Slave,Slave接收到快照文件后,载入数据;
Master快照发送完后开始向Slave发送缓冲区的写命令,Slave接收命令并执行,完成复制初始化;
此后Master每次执行一个写命令都会同步发送给Slave,保持Master与Slave之间数据的一致性。
优点
Master能自动将数据同步到Slave,可以进行读写分离,分担Master的读压力;
Master、Slave之间的同步是以非阻塞bgsave的方式进行的,同步期间,客户端仍然可以提交查询或更新请求。
缺点
不具备自动容错与恢复功能,Master或Slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复;
Master宕机,如果宕机前数据没有同步完,则切换IP后会存在数据不一致的问题;
难以支持在线扩容,Redis的容量受限于单机配置。
主节点宕机的解决
当主节点宕机后,此时需要让从节点顶替主节点,只要在从节点执行 slaveof no one 即可。当宕机节点恢复,可以重新执行命令把原先宕机并恢复的节点挂到新的 Master 节点之上。
简单搭建一下主从
使用docker-compose 指定一下自定义网络和ip (需要先创建对应的docker的网络)
yaml文件
version: '3.7'
services:
master:
image: redis:7.0
container_name: redis-master
ports:
- 6380:6379
networks:
default:
ipv4_address: 172.18.20.4
slave1:
image: redis:7.0
container_name: redis-slave-1
ports:
- 6381:6379
networks:
default:
ipv4_address: 172.18.20.5
slave2:
image: redis:7.0
container_name: redis-slave-2
ports:
- 6382:6379
networks:
default:
ipv4_address: 172.18.20.6
networks:
default:
external: true
name: mynetwork docker-compose up -d 一下

进入redis-slave-1容器执行一下

可以看到目前还是master身份
执行一下slaveof

可以看到已经成功 (同理redis-slave-2)下面进行测试 首先进入redis-master 容器
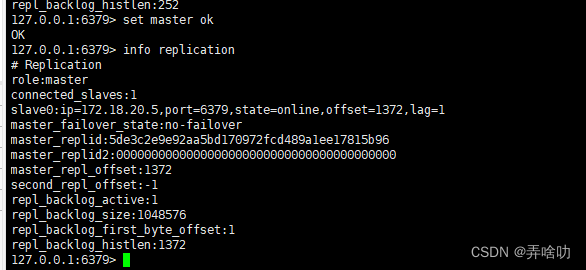
然后在从服务器上查看一下key是否同步

哨兵模式
由于无法进行主动恢复,因此主从模式衍生出了哨兵模式。哨兵模式基于主从复制模式,只是引入了哨兵来监控与自动处理故障
High availability with Redis Sentinel | Redis 官方sentinel文档
同样的也使用docker-compose 构建一下3个哨兵
yml文件
version: '3.7'
services:
sentinel1:
image: redis:7.0
container_name: redis-sentinel1
ports:
- 26379:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/usr/local/etc/redis/sentinel.conf
networks:
default:
ipv4_address: 172.18.20.7
sentinel2:
image: redis:7.0
container_name: redis-sentinel2
ports:
- 26380:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/usr/local/etc/redis/sentinel.conf
networks:
default:
ipv4_address: 172.18.20.8
slave2:
image: redis:7.0
container_name: redis-sentinel3
ports:
- 26381:26379
command: redis-sentinel /usr/local/etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/usr/local/etc/redis/sentinel.conf
networks:
default:
ipv4_address: 172.18.20.9
networks:
default:
external: true
name: mynetwork 咱们需要在和yml文件同目录下配置sentinel1.conf,sentinel2.conf,sentinel3.conf,文件
sentinel1.conf
port 26379
dir "/tmp"
sentinel monitor mymaster 172.18.20.4 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
sentinel2.conf sentinel3.conf同样的配置 然后构建一下镜像

进入sentinel1 容器 查看一下是否成功

可以看到master的ip 和另外有2个从服务器和2个sentinel

获取当前master的地址
正如我们已经指定的那样,Sentinel 还充当想要连接到一组主服务器和副本的客户端的配置提供程序。由于可能发生故障转移或重新配置,客户端不知道谁是给定实例集的当前活动主节点,因此 Sentinel 导出一个 API 来询问这个问题:
127.0.0.1:26379> SENTINEL get-master-addr-by-name mymaster
1) "172.18.20.4"
2) "6379"然后我们直接stop掉redis-master这个容器
如果你再问当前的主地址是什么mymaster,最终我们这次应该会得到不同的答复:
可以看到主从自动做了切换
搭建一个简单集群
Redis集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
Redis如何分配数据到节点
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个,集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽 。
同样的也使用docker-compose
redis
yml文件
version: '3.7'
services:
redis1:
image: redis:7.0
container_name: redis-1
environment:
- PORT=6380
- TZ=Asia/Shanghai
ports:
- 6380:6379
- 16380:16379 # 集群节点通信
stdin_open: true # 标准输入打开
tty: true # 后台运行不退出
privileged: true # 拥有容器内命令执行的权限
volumes:
- ./6380/redis.conf:/usr/local/etc/redis/redis.conf
command: sh -c "redis-server /usr/local/etc/redis/redis.conf"
networks:
default:
ipv4_address: 172.18.20.10
redis2:
image: redis:7.0
container_name: redis-2
environment:
- PORT=6381
- TZ=Asia/Shanghai
ports:
- 6381:6379
- 16381:16379 # 集群节点通信
stdin_open: true # 标准输入打开
tty: true # 后台运行不退出
privileged: true # 拥有容器内命令执行的权限
volumes:
- ./6381/redis.conf:/usr/local/etc/redis/redis.conf
command: sh -c "redis-server /usr/local/etc/redis/redis.conf"
networks:
default:
ipv4_address: 172.18.20.11
redis3:
image: redis:7.0
container_name: redis-3
environment:
- PORT=6382
- TZ=Asia/Shanghai
ports:
- 6382:6379
- 16382:16379 # 集群节点通信
stdin_open: true # 标准输入打开
tty: true # 后台运行不退出
privileged: true # 拥有容器内命令执行的权限
volumes:
- ./6382/redis.conf:/usr/local/etc/redis/redis.conf
command: sh -c "redis-server /usr/local/etc/redis/redis.conf"
networks:
default:
ipv4_address: 172.18.20.12
redis4:
image: redis:7.0
container_name: redis-4
environment:
- PORT=6383
- TZ=Asia/Shanghai
ports:
- 6383:6379
- 16383:16379 # 集群节点通信
stdin_open: true # 标准输入打开
tty: true # 后台运行不退出
privileged: true # 拥有容器内命令执行的权限
volumes:
- ./6383/redis.conf:/usr/local/etc/redis/redis.conf
command: sh -c "redis-server /usr/local/etc/redis/redis.conf"
networks:
default:
ipv4_address: 172.18.20.13
redis5:
image: redis:7.0
container_name: redis-5
environment:
- PORT=6384
- TZ=Asia/Shanghai
ports:
- 6384:6379
- 16384:16379 # 集群节点通信
stdin_open: true # 标准输入打开
tty: true # 后台运行不退出
privileged: true # 拥有容器内命令执行的权限
volumes:
- ./6384/redis.conf:/usr/local/etc/redis/redis.conf
command: sh -c "redis-server /usr/local/etc/redis/redis.conf"
networks:
default:
ipv4_address: 172.18.20.14
redis6:
image: redis:7.0
container_name: redis-6
environment:
- PORT=6385
- TZ=Asia/Shanghai
ports:
- 6385:6379
- 16385:16379 # 集群节点通信
stdin_open: true # 标准输入打开
tty: true # 后台运行不退出
privileged: true # 拥有容器内命令执行的权限
volumes:
- ./6385/redis.conf:/usr/local/etc/redis/redis.conf
command: sh -c "redis-server /usr/local/etc/redis/redis.conf"
networks:
default:
ipv4_address: 172.18.20.15
networks:
default:
external: true
name: mynetwork
reids.conf文件
daemonize no #当redis.conf配置文件中daemonize参数设置的yes,这使得redis是以后台启动的方式运行的,由于docker容器在启动时,需要任务在前台运行,否则会启动后立即退出,因此导致redis容器启动后立即退出问题。所以redis.conf中daemonize必须是no
port 6380 #分别对应每个机器的端口号进行设置6380 6381 6382 6383 6384 6385
pidfile /var/run/redis.pid
cluster-enabled yes #启动集群模式
cluster-config-file nodes.conf
cluster-node-timeout 10000
bind 0.0.0.0 (bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通 过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
protected-mode no
appendonly yesScaling with Redis Cluster | Redis
同理构建一下 可以看见构建成功

进入随便一个集群执行一下集群创建命令
redis-cli --cluster create 10.225.137.105:6380 10.225.137.105:6381 10.225.137.105:6382 10.225.137.105:6383 10.225.137.105:6384 10.225.137.105:6385 ‐‐cluster‐replicas 1
可以看到16383个虚拟槽分配完毕
进入集群查看一下集群信息

进行简单的set和get


redis缓存数据的淘汰机制
Redis 缓存使用内存保存数据,避免了系统直接从后台数据库读取数据,提高了响应速度。由于缓存容量有限,当缓存容量到达上限,就需要删除部分数据挪出空间,这样新数据才可以添加进来。Redis 定义了「淘汰机制」用来解决内存被写满的问题。
Redis 4.0 之前一共实现了 6 种内存淘汰策略,在 4.0 之后,又增加了 2 种策略。截止目前,Redis定义了「8种内存淘汰策略」用来处理 redis 内存满的情况:
noeviction: 不会淘汰任何数据,当使用的内存空间超过 maxmemory 值时,返回错误;
volatile-ttl:筛选设置了过期时间的键值对,越早过期的越先被删除;
volatile-random:筛选设置了过期时间的键值对,随机删除;
volatile-lru:使用 LRU 算法筛选设置了过期时间的键值对;
volatile-lfu:使用 LFU 算法选择设置了过期时间的键值对;
allkeys-random:在所有键值对中,随机选择并删除数据;
allkeys-lru:使用 LRU 算法在所有数据中进行筛选;
allkeys-lfu:,使用 LFU 算法在所有数据中进行筛选。
可以参考一下
Redis 的内存淘汰机制,看这篇就够了。_徐俊生的博客-CSDN博客_内存淘汰机制
redis结合lua脚本
背景:在我们使用redis的时候可能会在一些场景下使用到一些特殊的功能,但是redis现有的命令不满足我们的需求,所以我们需要自定义一些命令,但是我们自定义命令一般是多个指令结合在一起的,所以会存在并发执行中数据被修改问题,这就要求我们的自定义命令是原子性的,排它性的,在执行这个命令的时候不允许其他脚本、命令执行。
在redis 的官方文档中有描述lua脚本在执行的时候具有排他性,不允许其他命令或者脚本执行,类似于事务。但是存在的另一个问题是,它在执行的过程中如果一个命令报错不会回滚已执行的命令,所以要保证lua脚本的正确性
主要是使用redis.call来写一段lua 脚本 然后redis使用eval来执行一下脚本















 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









