







文章目录
时序的一些基本定义
特征统计量
-
均值
对时间序列 X t , t ∈ T {X_t,t \in T} Xt,t∈T而言,任意时刻的序列值 X t X_t Xt都是一个随机变量
μ t = E X t \mu_t=EX_t μt=EXt -
方差
方差用来描述序列值围绕其均值做随机波动时的平均波动程度
σ t 2 = D X t = E ( X t − μ t ) 2 \sigma_t^2=DX_t=E(X_t-\mu_t)^2 σt2=DXt=E(Xt−μt)2 -
自协方差函数和自相关系数
对于时间序列来说,自协方差函数定义为:
γ ( t , s ) = E [ ( X t − μ t ) ( X s − μ s ) ] \gamma(t,s)=E[(X_t-\mu_t)(X_s-\mu_s)] γ(t,s)=E[(Xt−μt)(Xs−μs)]
自相关系数(ACF)定义为:
ρ ( t , s ) = γ ( t , s ) D X t ∗ D X s \rho(t,s)=\frac{\gamma(t,s)}{\sqrt{DX_t*DX_s}} ρ(t,s)=DXt∗DXsγ(t,s) -
偏自相关系数

平稳序列
严平稳时间序列的定义:

宽平稳时间序列的定义:

平稳时间序列的统计性质
- 常数均值
- 自协方差函数与自相关系数只依赖于时间的平移长度而与时间的起止点无关
平稳时间序列的检验
平稳性检验方法这篇汇总是比较完整的。
这里就介绍一点时序图和自相关图,通过观察图来判断是否为平稳序列,存在很强的主观性。一般来说,时序图和自相关图可以得出不平稳的结论,但是如果要说某种序列为平稳序列,最好使用一些假设检验方法来判断。
-
时序图
平稳序列的时序图应该显示该序列始终在一个常数值附近随机波动,而且波动的范围有界。如果时序图显示出该序列有明显的趋势性或者周期性,那么就不是平稳序列。 -
自相关图
平稳序列通常具有短期相关性,随着延迟期数 k k k的增加,平稳序列的自相关系数 ρ k \rho_k ρk会很快衰减向0,而非平稳序列的自相关系数衰减向零的速度比较慢。
白噪声序列
白噪声序列的定义:

白噪声序列的性质
- 纯随机性。白噪声序列的各项之间没有任何相关关系 γ ( k ) = 0 \gamma(k)=0 γ(k)=0
- 方差齐性。就是序列中每个变量的方差都相等,即 D X t = γ ( 0 ) = σ 2 DX_t=\gamma(0)=\sigma^2 DXt=γ(0)=σ2
白噪声检验(纯随机性检验)
可构造检验统计量来检验序列的纯随机性
原假设:延迟期数小于或等于
m
m
m期的序列值之间相互独立
备择假设:延迟期数小于或等于
m
m
m期的序列值之间具有相关性
检验统计量:
-
Q统计量
其中,n为序列观测期数,m为指定延迟期数,且Q统计量近似服从自由度为m的卡方分布 -
LB统计量
其中,n为序列观测期数,m为指定延迟期数,且LB统计量也近似服从自由度为m的卡方分布
时间序列预处理
关于时间序列预处理这一块,以后有时间来补哈哈哈哈哈。预处理文章(我看到有一个博主写的蛮不错的,大家可以点击链接,进行学习)
平稳序列建模
如果某个观察值序列通过序列预处理可以判断为平稳非白噪声序列,就可以利用ARMA模型对该序列建模,建模步骤如下:
计算样本自相关系数和偏自相关系数。
样本自相关系数:

样本偏自相关系数:
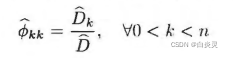
ARMA模型识别
根据ACF和PACF表现出来的性质,选择适当的ARMA模型拟合观察值序列。ARMA模型定阶的基本原则如下:
但在实践中,由于样本的随机性,什么情况下应该看做相关系数截尾,什么情况下应该看做相关系数在延迟若干阶后正常衰减到零值附近作拖尾波动,其实没有绝对的标准,很大程度上依靠主观经验,但可以借助这两个统计量的近似分布来帮助判断。
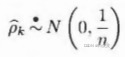
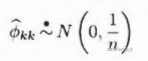
根据正态分布的性质,有:

如果样本自相关系数或偏自相关系数在最初的d阶明显超过2倍标准差范围,而后几乎95%的自相关系数都落在2倍标准差的范围以内,而且由非零自相关系数衰减为小值波动的过程非常突然,可视为自相关系数截尾,截尾阶数为d。
如果有超过5%的样本自相关系数落入2倍标准差范围之外,或者由显著非零的自相关系数衰减为小值波动的过程比较缓慢或者非常连续,这时,通常视为自相关系数不截尾。
R提供了auto.arima函数实现自动定阶,该函数基于信息量最小原则自动识别模型阶数,并给出该模型的参数估计值。
参数估计
选择好模型之后,下一步就是估计模型中未知参数的值。
对于一个非中心化ARMA(p,q)模型,有
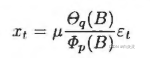
其中

该模型共含有p+q+2个未知参数:
ϕ
1
,
.
.
.
,
ϕ
p
,
θ
1
,
.
.
.
,
θ
q
,
μ
,
σ
ϵ
2
\phi_1,...,\phi_p,\theta_1,...,\theta_q,\mu,\sigma_\epsilon^2
ϕ1,...,ϕp,θ1,...,θq,μ,σϵ2
其中参数
μ
\mu
μ是序列均值,通常采用矩估计方法,用样本均值估计总体均值即可得到它的估计值。
对剩下的
p
+
q
+
1
p+q+1
p+q+1个未知参数的估计方法有三种:矩估计、极大似然估计和最小二乘估计
矩估计
运用p+q个样本自相关系数估计总体自相关系数
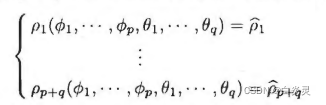
从中解出的参数值
ϕ
^
1
,
.
.
.
,
ϕ
^
p
,
θ
^
1
,
.
.
.
,
θ
^
q
\hat\phi_1,...,\hat\phi_p,\hat\theta_1,...,\hat\theta_q
ϕ^1,...,ϕ^p,θ^1,...,θ^q就是
ϕ
1
,
.
.
.
,
ϕ
p
,
θ
1
,
.
.
.
,
θ
q
\phi_1,...,\phi_p,\theta_1,...,\theta_q
ϕ1,...,ϕp,θ1,...,θq的矩估计
用序列样本方差估计序列总体方差:

在ARMA(p,q)模型两边同时求方差,整理得到
σ
ϵ
2
\sigma_\epsilon^2
σϵ2关于
σ
x
2
\sigma_x^2
σx2的函数形式:
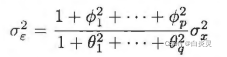
把参数值
ϕ
^
1
,
.
.
.
,
ϕ
^
p
,
θ
^
1
,
.
.
.
,
θ
^
q
\hat\phi_1,...,\hat\phi_p,\hat\theta_1,...,\hat\theta_q
ϕ^1,...,ϕ^p,θ^1,...,θ^q代入上式可得到白噪声序列方差的矩估计:
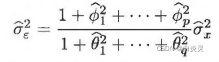
矩估计方法的思想简单,不需要假设总体分布,但是这种估计方法中只用到了p+q个样本自相关系数,即样本二阶矩的信息,观察值序列中其他信息都被忽略了。这种方法比较粗糙,估计精度不高。
极大似然估计
极大似然准则下,样本来自使该样本出现概率最大的总体,因此未知参数的极大似然估计就是使得似然函数达到最大的参数值。
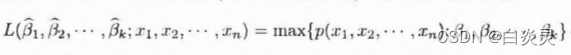
在时序分析中,序列总体的分布通常是未知的,为了便于分析和计算,通常假设序列服从多元正态分布。


求解方程组的就可得到未知参数的极大似然估计值,通常需要经过复杂的迭代算法才能求出未知参数的极大似然估计值。
极大似然估计的估计精度高,同时还具有估计的一致性、渐近正态性和渐进有效性等许多优良的统计性质,是一种非常优良的参数估计方法。
最小二乘估计



R语言中,参数估计可以通过调用arima函数完成。
模型检验
拟合模型的口径之后,还要对该拟合模型进行必要的检验。
模型的显著性检验
一个模型是否显著有效主要看它提取的信息是否充分,一个好的拟合模型应该能够提取观察值序列中几乎所有的样本相关信息。换言之,拟合残差项中将不再蕴涵任何相关信息,即残差序列应该为白噪声序列。这样的模型称为显著有效模型。
反之,如果残差序列为非自噪声序列,那就意味着残差序列中还残留着相关信息未被提取,这就说明拟合模型不够有效,通常需要选择其他模型,重新拟合。
所以模型的显著性检验即为残差序列的白噪声检验。原假设和备择假设分别为:

检验统计量为LB检验统计量:
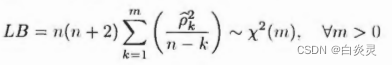
如何拒绝原假设,就说明残差序列中还残留相关信息,拟合模型不显著。
参数的显著性检验
参数的显著性检验就是要检验每一个位置参数是否显著非零,这个检验的目的是使模型最精简。如果某个参数不显著,即表示该参数所对应的那个自变量对因变量的影响不明显,该自变量可以从拟合模型中剔除。
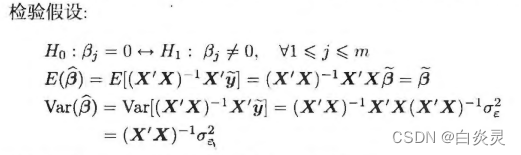


或者该检验统计量的p值小于
α
\alpha
α时,拒绝原假设,认为该参数显著,否则,认为该参数不显著。此时,应该剔除不显著参数所对应的自变量重新拟合模型,构造出新的、结构更精练的拟合模型。
R中可调用pt函数获得该统计量的p值。
模型优化
同一个序列可以构造多个拟合模型,且都显著有效。可引入AIC和BIC信息准则进行模型优化。


序列预测
前面这些工作的最终目的就是要利用拟合模型来对随机序列的未来发展进行预测。目前对平稳序列最常用的预测方法是线性最小方差预测。线性是指预测值为观察值序列的线性函数,最小方差是指预测方差达到最小。
对于未来任意
l
l
l时刻的序列值
x
t
+
l
x_{t+l}
xt+l,最终都可以表示成已知历史信息
x
t
,
x
t
−
1
,
.
.
.
x_t,x_{t-1},...
xt,xt−1,...的线性函数,并用该函数形式估计
x
t
+
l
x_{t+l}
xt+l的值:


参考文献:
[1]王燕. 时间序列分析:基于R[M]. 中国人民大学出版社, 2015.














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









