






 本文档详细记录了一位开发者在尝试从安全客网站搜索漏洞信息时遇到的问题及解决过程。最初通过requests库请求www.anquanke.com/vul?s=搜索参数无法获取数据,后经BurpSuite抓包发现实际数据来源于api.anquanke.com。通过更改请求地址,成功获取到JSON格式的搜索结果,并实现了将数据写入Excel文档的功能。整个过程中涉及网络请求、数据解析及文件操作等技术。
本文档详细记录了一位开发者在尝试从安全客网站搜索漏洞信息时遇到的问题及解决过程。最初通过requests库请求www.anquanke.com/vul?s=搜索参数无法获取数据,后经BurpSuite抓包发现实际数据来源于api.anquanke.com。通过更改请求地址,成功获取到JSON格式的搜索结果,并实现了将数据写入Excel文档的功能。整个过程中涉及网络请求、数据解析及文件操作等技术。
1.页面分析
url = r"https://www.anquanke.com/”
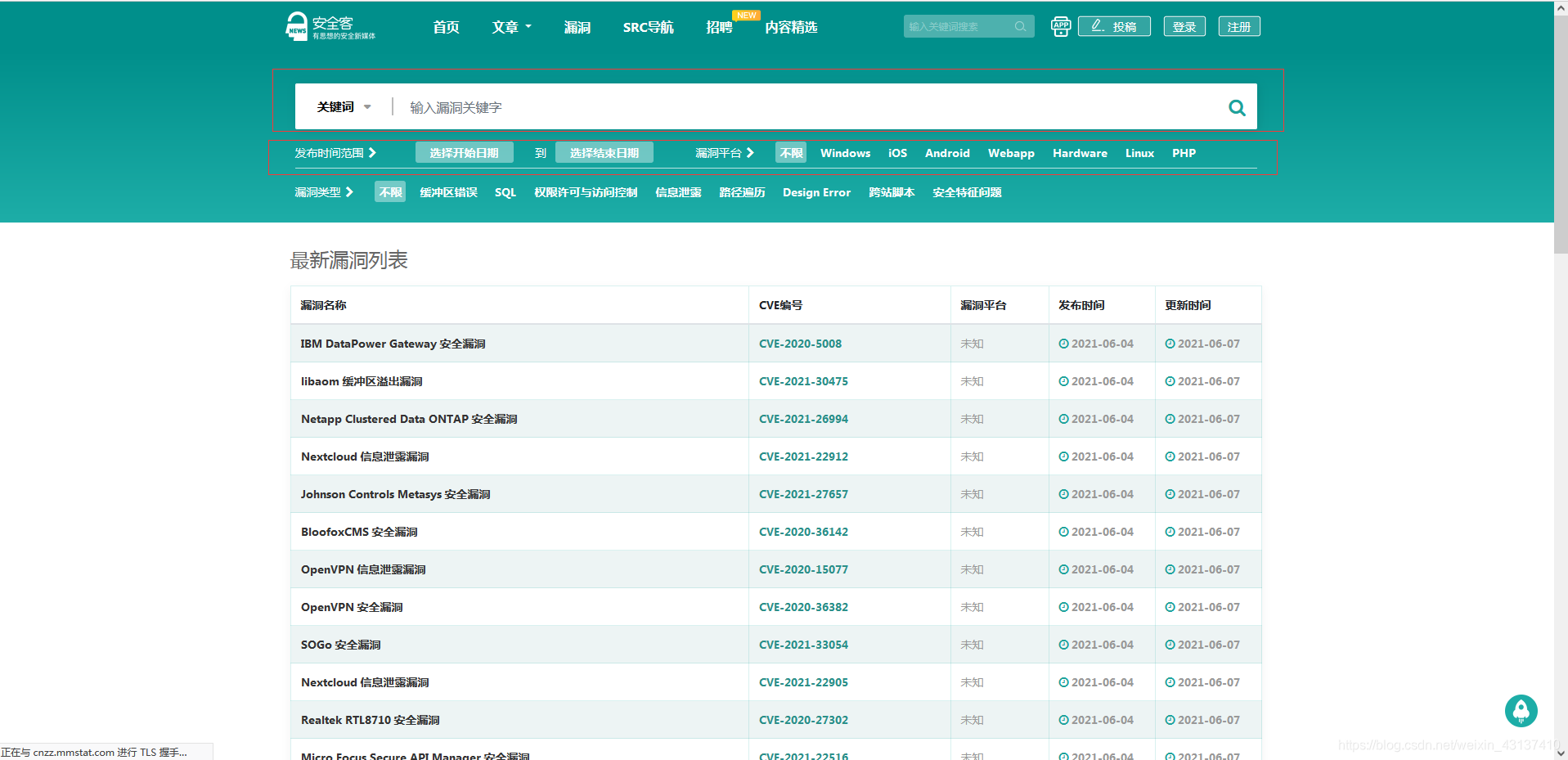 安全客漏洞搜索采用GET方式提交参数,在后续的实现过程中发生了一些意外,出现了一个我没有找到原因的问题,在本篇文章中我也会复现我当时出错的思路和想法,各位看官大人如果知道原因烦请指出,先谢过各位了。
安全客漏洞搜索采用GET方式提交参数,在后续的实现过程中发生了一些意外,出现了一个我没有找到原因的问题,在本篇文章中我也会复现我当时出错的思路和想法,各位看官大人如果知道原因烦请指出,先谢过各位了。
2.使用requests进行请求
在初步做页面分析时候,使用了https://www.anquanke.com/vul?s=的地址发起请求。
import requests
url = r"https://www.anquanke.com/vul?s=SaltStack"
response = requests.get(url)
但是在分析返回的数据时,却出现了问题。
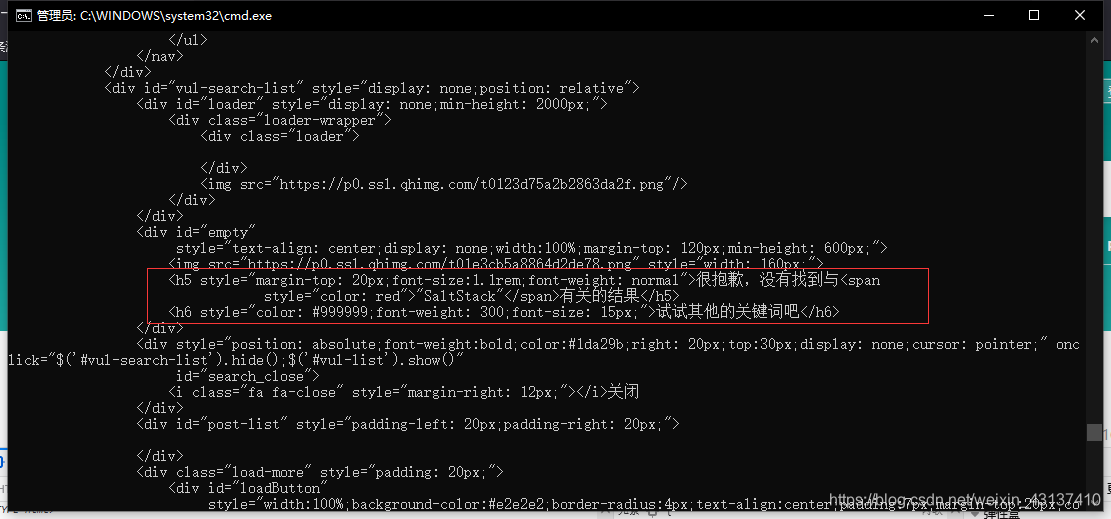 返回的HTML提示未搜索到SaltStack相关的结果。
返回的HTML提示未搜索到SaltStack相关的结果。
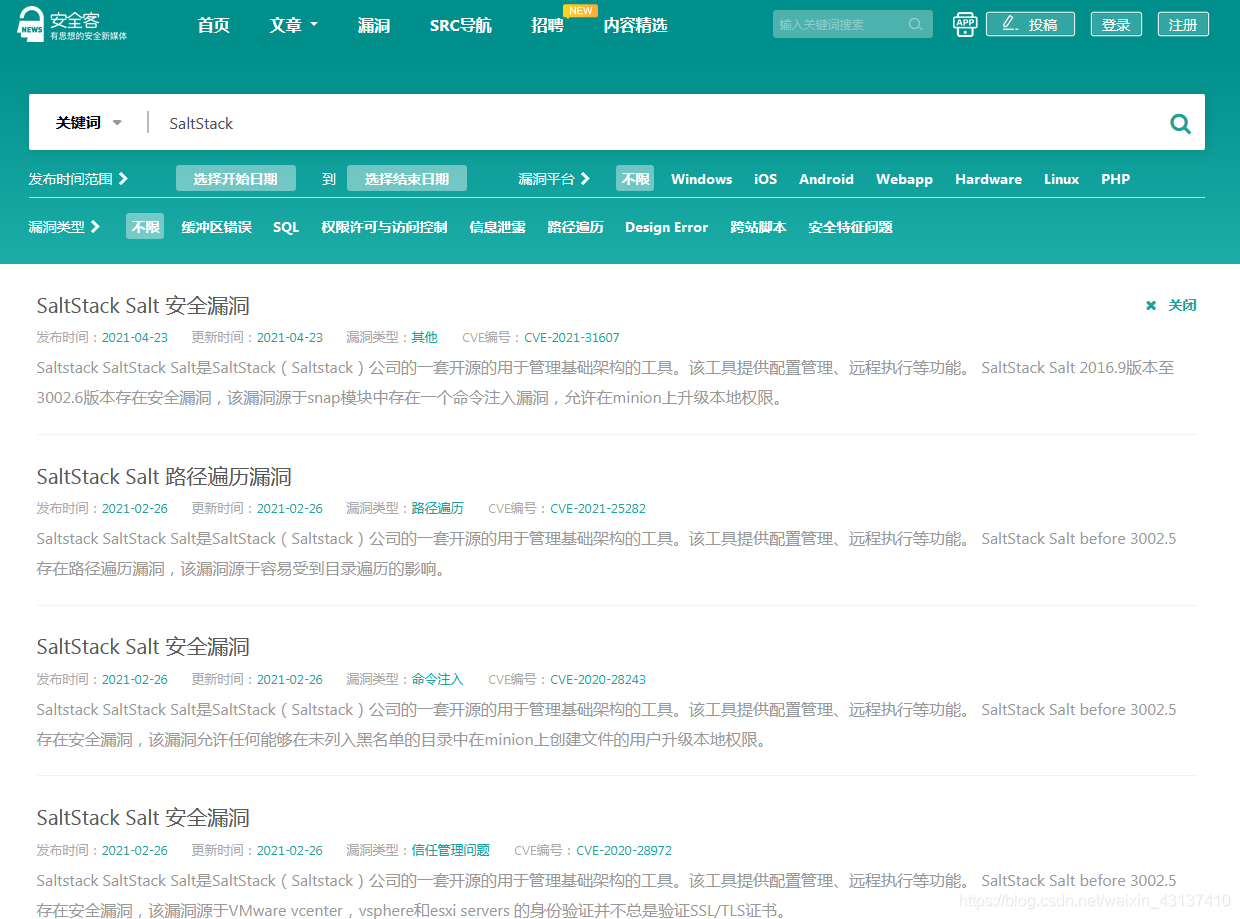 在正常页面搜索是存在搜索的结果,之后又尝试请求搜索了apache等,均提示未搜索到相关的结果。
在正常页面搜索是存在搜索的结果,之后又尝试请求搜索了apache等,均提示未搜索到相关的结果。
3.使用BurpSuite抓包进行分析
在使用BurpSuite抓包之后,截取到的请求除了正常向www.anquanke.com/vul?s=SaltStack发送的请求之外,还有一个请求引起了我的注意,也是最终完成爬虫的关键。
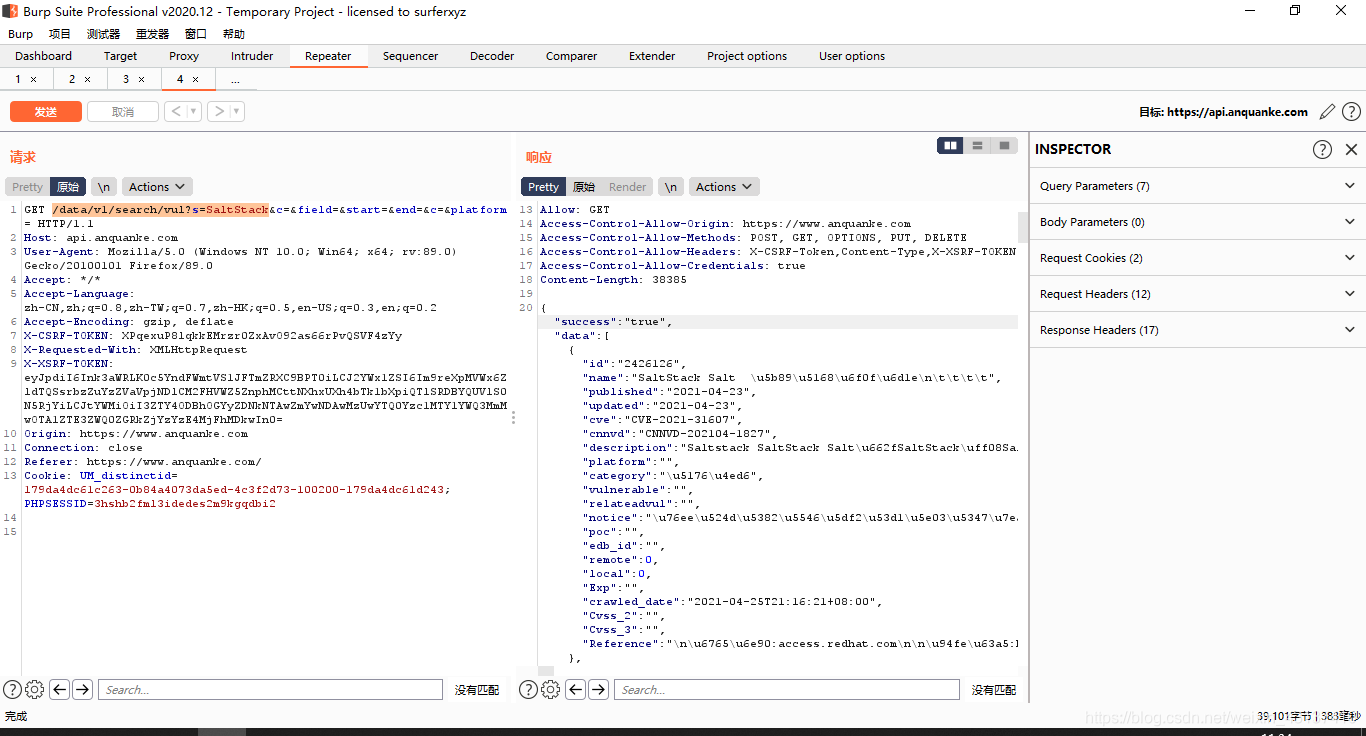 BurpSuite还截取到一个发送到api.anquanke.com的请求,在BurpSuite上测试后返回一个json数据的响应,在分析之后得出结论,返回的json数据就是搜索结果。
BurpSuite还截取到一个发送到api.anquanke.com的请求,在BurpSuite上测试后返回一个json数据的响应,在分析之后得出结论,返回的json数据就是搜索结果。
4.改变请求地址继续尝试
import requests
url = r"https://api.anquanke.com//data/v1/search/vul?s=SaltStack"
response = requests.get(url)
print(response.json())
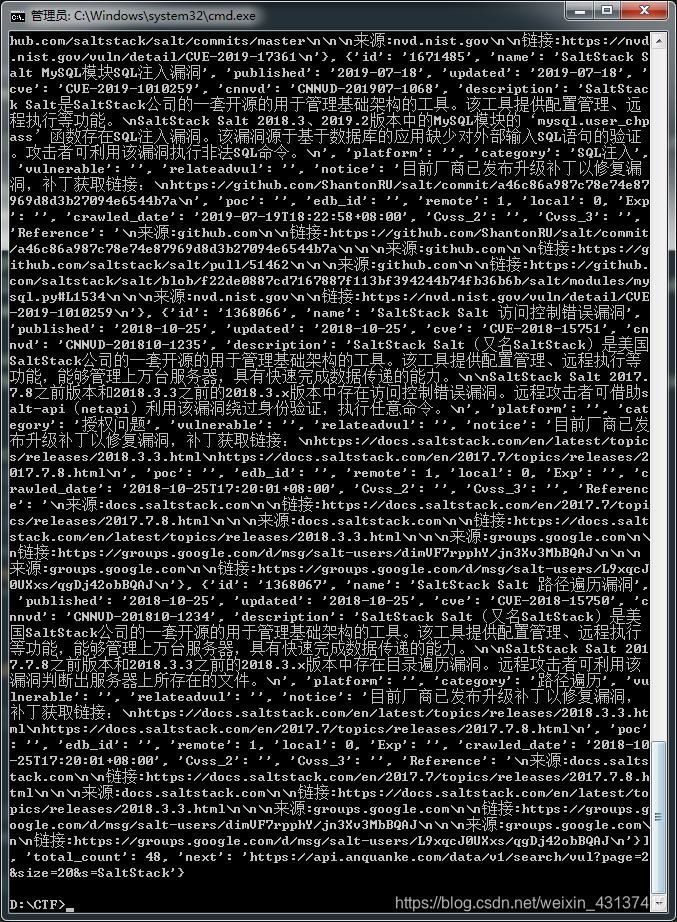 此时已经能正确获取到数据,剩下就是完善代码提取和写入数据即可。
此时已经能正确获取到数据,剩下就是完善代码提取和写入数据即可。
5.完善代码
import xlrd
import xlwt
import requests
url = r'https://api.anquanke.com//data/v1/search/vul?s='#api请求地址
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate",
"X-Requested-With": "XMLHttpRequest",
"Origin": "https://www.anquanke.com",
"Connection": "close",
"Referer": "https://www.anquanke.com/",
}
data = xlrd.open_workbook('search.xls')#读取excel文档
table = data.sheet_by_index(0)#读取文档第一个sheet页
nrows = table.nrows#获取sheet页行数
ncols = table.ncols#获取sheet页列数
count = 1#标识,方便后面写入excel
workbook = xlwt.Workbook(encoding = 'utf-8')#创建新的excel文档
worksheet = workbook.add_sheet('1')#创建新文档的新sheet页,用于写入数据。
for i in range(nrows):#遍历漏洞文档行
vul = table.cell(i,0).value#获取漏洞文档第i行第一列的数据
# print(vul)
vul_url = url + vul#拼接请求地址
print(vul_url)#打印请求地址
response = requests.get(vul_url)
# print(response.text)
data = response.json()['data']#将返回的json数据转换并获取data的value,返回的数据是一个多维字典形式,漏洞数据是data的值,变量data是一个存了很多字典的数组。
for j in data:#遍历value,j为一个漏洞的数据,是一个字典类型。
# print(j)
#下面的都是数据写入,参数含义:write(行,列,数值)
keys = j.keys()
# print(keys)
cols = 0
for key in keys:
# print(key)
worksheet.write(count,cols,label = j[key])
cols = cols + 1
count = count + 1#标识自增
print("{}已写入".format(j["name"]),count)
workbook.save('vul.xls')#保存新建的excel文档
6.后记
这个小项目,最终实现是读取当前文件夹下的search.xls文档,遍历第一例的漏洞列表后,爬取安全客相关数据信息并最终写入excel文档并保存到vul.xls,至于为什么请求www.anquanke.com/vul?s=无法获取正确的响应,我也没弄明白,希望知道的大佬能为我答疑解惑,感激不尽!

















 1522
1522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









