






前面一直做人脸检测相关内容,然后对比了下dib以及MTCNN的人脸检测效果主要是速度,以及FDDB准确率。最后给出生成FDDB测试文件的C++代码。
FDDB 测试结果
注本文的MTCNN效果检测准确率不是最优的,最优的在FDDB上可达95%,测试效果如下:
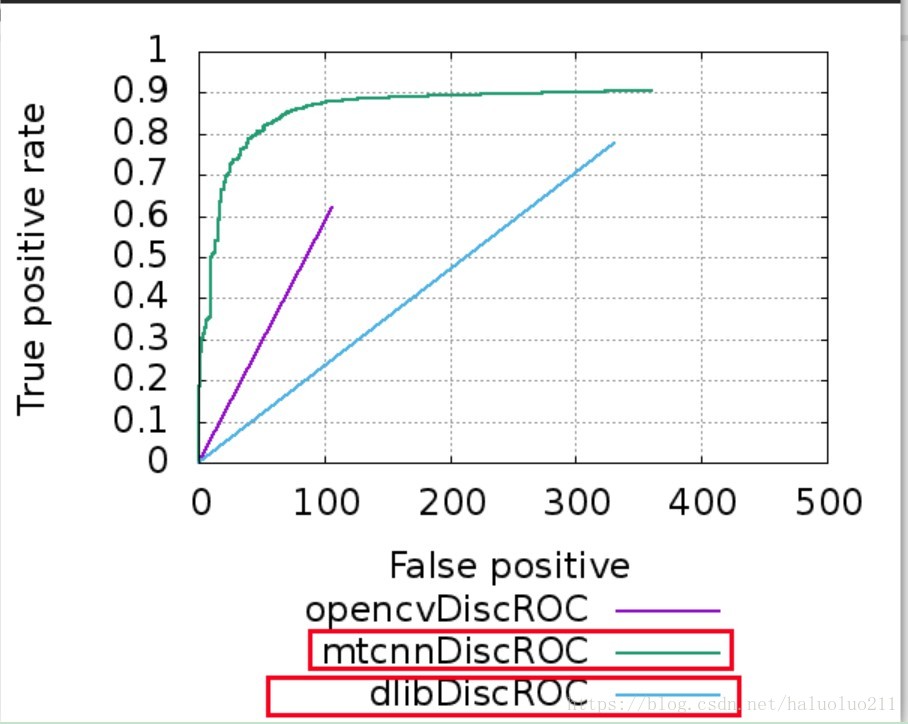
可以看到三种方法:
MTCNN 大概90%
dlib 大概 77%
opencv 大概 62%
dlib的作者非要说我的测试有问题,如果谁感兴趣可以使用dlib测试下FDDB的结果。
速度
在CPU和GPU模式下,对于三种不同尺寸的图片,运行一千次测试平均的时效:
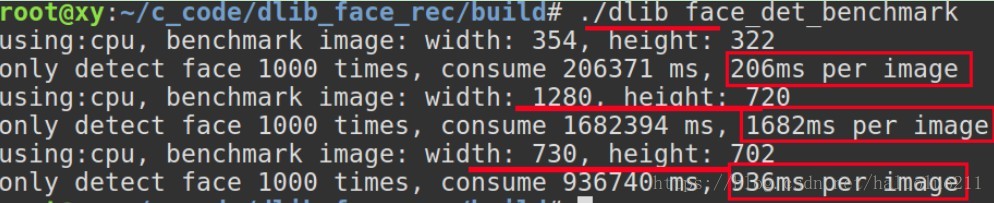
CPU模式
MTCNN(既检测人脸又做landmark):

dlib (仅仅检测人脸):
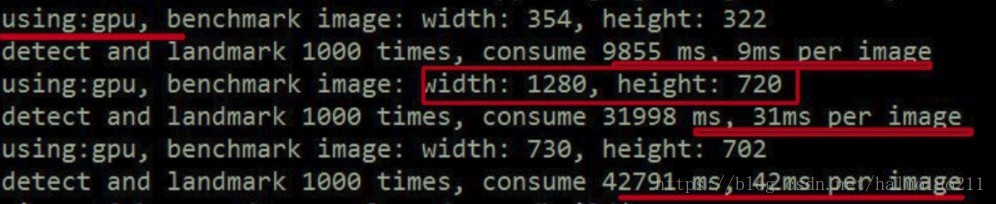
GPU模式
MTCNN(既检测人脸又做landmark):
dlib (仅仅检测人脸):
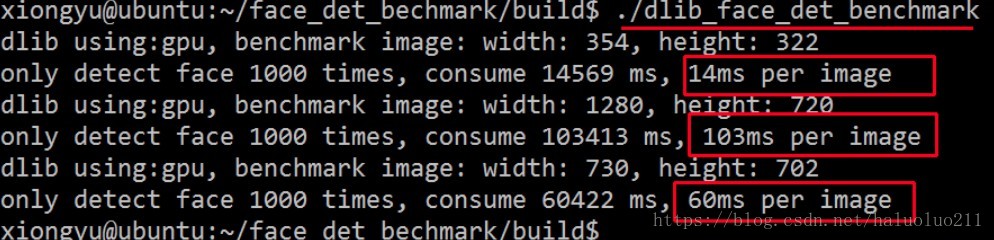
可以看到:
在检测精度上MTCNN显然好于dlib
无论是CPU还是GPU模型下MTCNN的检测数度都好于dlib,而且dlib还做了人脸的landmark
dlib c++生成FDDB结果代码如下(至于怎么使用FDDB测试可见前面blog,有py实现)或者我的stackoverflow回答:
#include <iostream>
#include <dlib/dnn.h>
#include <dlib/data_io.h>
#include <dlib/image_processing.h>
#include <dlib/gui_widgets.h>
using namespace std;
using namespace dlib;
// ----------------------------------------------------------------------------------------
template <long num_filters, typename SUBNET> using con5d = con<num_filters,5,5,2,2,SUBNET>;
template <long num_filters, typename SUBNET> using con5 = con<num_filters,5,5,1,1,SUBNET>;
template <typename SUBNET> using downsampler = relu<affine<con5d<32, relu<affine<con5d<32, relu<affine<con5d<16,SUBNET>>>>>>>>>;
template <typename SUBNET> using rcon5 = relu<affine<con5<45,SUBNET>>>;
using net_type = loss_mmod<con<1,9,9,1,1,rcon5<rcon5<rcon5<downsampler<input_rgb_image_pyramid<pyramid_down<6>>>>>>>>;
// ----------------------------------------------------------------------------------------
void getAllImgPaths(const std::string& file, std::vector<std::string>& vecPaths){
std::fstream fStream(file);
std::string sLine;
while (std::getline(fStream, sLine)){
if (sLine.size() > 0){
vecPaths.emplace_back(sLine);
}
}
fStream.close();
}
void writeStrVecToFile(const std::string& file, const std::vector<std::string>& vecStr){
std::ofstream fout(file);
for (auto const& x:vecStr){
fout<<x<<'\n';
}
fout.close();
}
注释:[关于FDDB人脸检测算法评价标准](https://yinguobing.com/fddb/)
FDDB[1]是Face Detection Data Set and Benchmark的缩写,这是一款专门针对人脸识别算法的评测方法与标准。
FDDB一共包含了2845张图片,包含彩色以及灰度图,其中的人脸总数达到5171个。这些人脸所呈现的状态多样,包括遮挡、罕见姿态、低分辨率以及失焦的情况。
**面部区域标记方法**
目前常用的标记方法包括矩形标记法与椭圆标记法两种。
**矩形标记法**
传统方法都采用矩形标记法,用一个矩形框将画面中的人脸区域包含在内,如下图所示。这种标记方法存在的问题在于很难给出一个恰好包含面部的矩形框,并且获得各种不同算法的一致的认可。因此采用矩形框的方法无法很好的对不同算法的结果做出准确且有效的评价。
**椭圆标记法**
由于人脸天然呈现为椭圆形,所以用椭圆形来表征是一种较为准确的方法,如下图所示。这种方法可以对侧脸与转动后的面部进行描述。
这样人脸就可以用5个变量来表征:
ra:椭圆长轴半径
rb:椭圆短轴半径
theta:椭圆长轴偏转角度
cx:椭圆圆心x坐标
cy:椭圆圆心y坐标
**量化评价指标**
评估前提
检测应当在连续的图片区域内进行。
所有涉及到融合交叠区域或者相似区域的后处理行为应当已经完成。
单次检测应当检测且只检测一张完整面部,即一次检测输出多张面部或者需要多次检测才能输出一个面部区域是无效的。
评分方式
若一次检测输出区域为di,对应的标准区域为li,则检测结果S可以用下方公式评价:
fddb-eval-equ
方式1 - Discrete score (DS)
eval-equ-01
方式2: - Continuous score (CS):
eval-equ-02
获得具体yi值之后,可以通过Receiver Operating Characteristic (ROC) 曲线来对不同的算法进行比较。
roc-ds
roc-cs
其它
FDDB官网提供了原始图像的下载[2]。各种算法的公开检测结果可以参考官方测试[3]














 4752
4752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









