






本文来源https://blog.csdn.net/jiongnima/article/details/80113976,感谢博主的分享
训练数据集1:斑马与马
下载链接:https://pan.baidu.com/s/1Zf6hvoDMsMi51WIPEOoqzg 密码:gua5
训练数据集2:橘子与苹果
下载链接:https://pan.baidu.com/s/1R0s2eaBxMCozbCCs7_1Juw 密码:z9y1
训练数据集3:填充轮廓->建筑照片
下载链接:https://pan.baidu.com/s/1xUg8AC7NEXyKebSUNtRvdg 密码:2kw1
在笔者看来,CycleGAN是2017年度最有趣的深度学习成果之一,因为实现了两个域的图像的互相转换(风格迁移),比如下面两个论文中所举的例子(截图来自论文):
(1) 将一副印象派画家莫奈的画作转化为相片(同时可将相片转化成印象派画作)

(2) 将拍摄的冬日景象转化成夏日景象(同时可将夏日景象转化成冬日景象)

在本篇博文中,笔者就教大家使用简单的代码搭建CycleGAN,亲自动手实践两个域的图片的相互转换。
在开始搭建CycleGAN与代码解析之前,笔者想说的是:要亲自搭建CycleGAN框架,还需各位读者朋友明白CycleGAN的原理。鉴于CycleGAN的原理网上已经有很多资料进行解析,笔者在下面提供一些笔者认为比较好的途径:
(1) 直接进行论文阅读:https://arxiv.org/abs/1703.10593
(2) 推荐看这篇之乎专栏解析的CycleGAN:可能是近期最好玩的深度学习模型:CycleGAN的原理与实验详解,里面不仅介绍了CycleGAN的原理,还介绍了其他应用,比如如何把女人变成男人,男人变成女人,猫狗之间的互相转换,如何去除图片中的马赛克(额,车速较快请握紧扶手。)
(3) 笔者也在本篇博客中简单介绍一下CycleGAN的原理(截图来自论文):
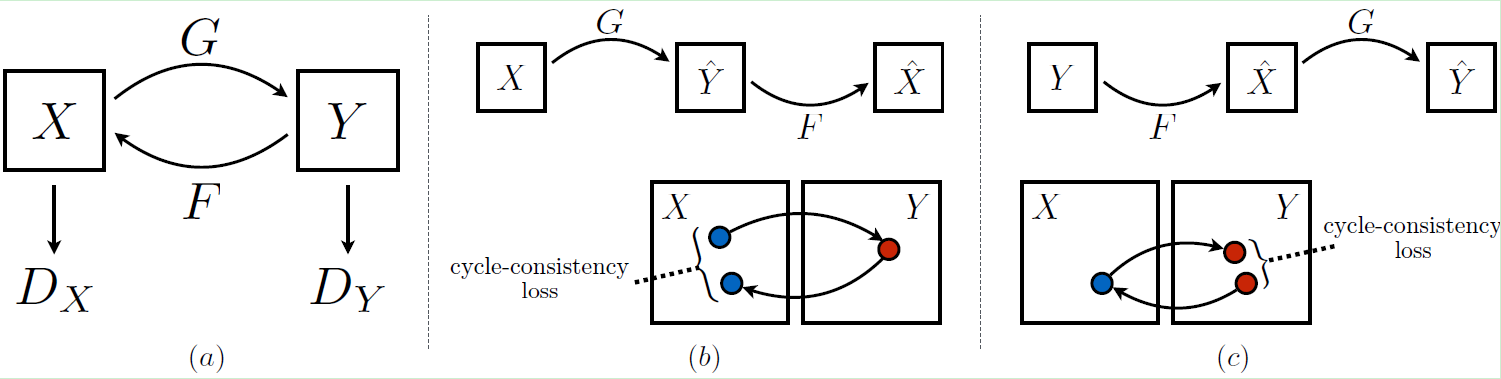
CycleGAN是一个环形的结构,主要由两个生成器及两个判别器组成,如上图所示。X表示X域的图像,Y表示Y域的图像。X域的图像通过生成器G生成Y域的图像,再通过生成器F重构回X域输入的原图像;Y域的图像通过生成器F生成X域图像,再通过生成器G重构回Y域输入的原图像。判别器Dx和Dy起到判别作用,确保图像的风格迁移。
CycleGAN的训练的损失函数如下所示(截图来自论文):
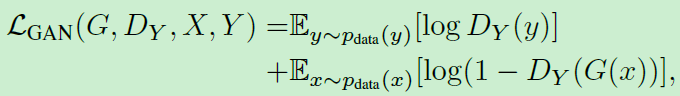
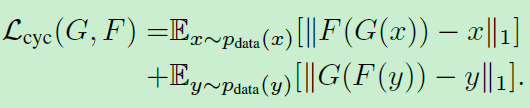
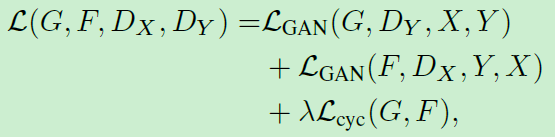
可以看到,CycleGAN的loss函数分成两大部分,一共四块。其中两块GAN loss,两块L1 loss。整个CycleGAN框架采用end-to-end方式训练。
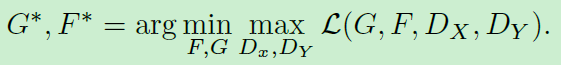
总而言之,CycleGAN想要达到的目的是,完成两个域之间的风格转换,在风格转换的同时,又要确保图中物体的几何形状和空间关系不发生变化。
下面,笔者就放出搭建CycleGAN的源码,首先列举一下笔者主要使用的工具和库:
(1) Python 3.5.2
(2) numpy
(3) Tensorflow 1.2
(4) argparse 用来解析命令行参数
(5) random 用来打乱输入顺序
(6) os 用来读取图片路径和文件名
(7) glob 用来读取图片路径和文件名
(8) cv2 用来读取图片
笔者搭建的CycleGAN代码分成5大部分,分别是:
(1) train.py 训练的主控程序
(2) train_image_reader.py 训练数据读取接口
(3) net.py 定义网络结构
(4) evaluate.py 测试的主控程序
(5) test_image_reader.py 训练数据读取接口
其中,训练时使用到的文件是(1),(2),(3)项,测试时使用到的文件时(3),(4),(5)。
下面,笔者放出代码与注释:
首先是train.py文件的代码:
-
from __future__
import print_function
-
-
import argparse
-
from datetime
import datetime
-
from random
import shuffle
-
import random
-
import os
-
import sys
-
import time
-
import math
-
import tensorflow
as tf
-
import numpy
as np
-
import glob
-
import cv2
-
-
from train_image_reader
import *
-
from net
import *
-
-
parser = argparse.ArgumentParser(description=
'')
-
-
parser.add_argument(
"--snapshot_dir", default=
'./snapshots', help=
"path of snapshots")
#保存模型的路径
-
parser.add_argument(
"--out_dir", default=
'./train_out', help=
"path of train outputs")
#训练时保存可视化输出的路径
-
parser.add_argument(
"--image_size", type=int, default=
256, help=
"load image size")
#网络输入的尺度
-
parser.add_argument(
"--random_seed", type=int, default=
1234, help=
"random seed")
#随机数种子
-
parser.add_argument(
'--base_lr', type=float, default=
0.0002, help=
'initial learning rate for adam')
#基础学习率
-
parser.add_argument(
'--epoch', dest=
'epoch', type=int, default=
200, help=
'# of epoch')
#训练的epoch数量
-
parser.add_argument(
'--epoch_step', dest=
'epoch_step', type=int, default=
100, help=
'# of epoch to decay lr')
#训练中保持学习率不变的epoch数量
-
parser.add_argument(
"--lamda", type=float, default=
10.0, help=
"L1 lamda")
#训练中L1_Loss前的乘数
-
parser.add_argument(
'--beta1', dest=
'beta1', type=float, default=
0.5, help=
'momentum term of adam')
#adam优化器的beta1参数
-
parser.add_argument(
"--summary_pred_every", type=int, default=
200, help=
"times to summary.")
#训练中每过多少step保存训练日志(记录一下loss值)
-
parser.add_argument(
"--write_pred_every", type=int, default=
100, help=
"times to write.")
#训练中每过多少step保存可视化结果
-
parser.add_argument(
"--save_pred_every", type=int, default=
10000, help=
"times to save.")
#训练中每过多少step保存模型(可训练参数)
-
parser.add_argument(
"--x_train_data_path", default=
'./dataset/horse2zebra/trainA/', help=
"path of x training datas.")
#x域的训练图片路径
-
parser.add_argument(
"--y_train_data_path", default=
'./dataset/horse2zebra/trainB/', help=
"path of y training datas.")
#y域的训练图片路径
-
-
args = parser.parse_args()
-
-
def save(saver, sess, logdir, step):
#保存模型的save函数
-
model_name =
'model'
#保存的模型名前缀
-
checkpoint_path = os.path.join(logdir, model_name)
#模型的保存路径与名称
-
if
not os.path.exists(logdir):
#如果路径不存在即创建
-
os.makedirs(logdir)
-
saver.save(sess, checkpoint_path, global_step=step)
#保存模型
-
print(
'The checkpoint has been created.')
-
-
def cv_inv_proc(img):
#cv_inv_proc函数将读取图片时归一化的图片还原成原图
-
img_rgb = (img +
1.) *
127.5
-
return img_rgb.astype(np.float32)
#返回bgr格式的图像,方便cv2写图像
-
-
def get_write_picture(x_image, y_image, fake_y, fake_x_, fake_x, fake_y_):
#get_write_picture函数得到训练过程中的可视化结果
-
x_image = cv_inv_proc(x_image)
#还原x域的图像
-
y_image = cv_inv_proc(y_image)
#还原y域的图像
-
fake_y = cv_inv_proc(fake_y[
0])
#还原生成的y域的图像
-
fake_x_ = cv_inv_proc(fake_x_[
0])
#还原重建的x域的图像
-
fake_x = cv_inv_proc(fake_x[
0])
#还原生成的x域的图像
-
fake_y_ = cv_inv_proc(fake_y_[
0])
#还原重建的y域的图像
-
row1 = np.concatenate((x_image, fake_y, fake_x_), axis=
1)
#得到训练中可视化结果的第一行
-
row2 = np.concatenate((y_image, fake_x, fake_y_), axis=
1)
#得到训练中可视化结果的第二行
-
output = np.concatenate((row1, row2), axis=
0)
#得到训练中可视化结果
-
return output
-
-
def make_train_data_list(x_data_path, y_data_path):
#make_train_data_list函数得到训练中的x域和y域的图像路径名称列表
-
x_input_images_raw = glob.glob(os.path.join(x_data_path,
"*"))
#读取全部的x域图像路径名称列表
-
y_input_images_raw = glob.glob(os.path.join(y_data_path,
"*"))
#读取全部的y域图像路径名称列表
-
x_input_images, y_input_images = add_train_list(x_input_images_raw, y_input_images_raw)
#将x域图像数量与y域图像数量对齐
-
return x_input_images, y_input_images
-
-
def add_train_list(x_input_images_raw, y_input_images_raw):
#add_train_list函数将x域和y域的图像数量变成一致
-
if len(x_input_images_raw) == len(y_input_images_raw):
#如果x域和y域图像数量本来就一致,直接返回
-
return shuffle(x_input_images_raw), shuffle(y_input_images_raw)
-
elif len(x_input_images_raw) > len(y_input_images_raw):
#如果x域的训练图像数量大于y域的训练图像数量,则随机选择y域的图像补充y域
-
mul_num = int(len(x_input_images_raw)/len(y_input_images_raw))
#计算两域图像数量相差的倍数
-
y_append_num = len(x_input_images_raw) - len(y_input_images_raw)*mul_num
#计算需要随机出的y域图像数量
-
append_list = [random.randint(
0,len(y_input_images_raw)
-1)
for i
in range(y_append_num)]
#得到需要补充的y域图像下标
-
y_append_images = []
#初始化需要被补充的y域图像路径名称列表
-
for a
in append_list:
-
y_append_images.append(y_input_images_raw[a])
-
y_input_images = y_input_images_raw * mul_num + y_append_images
#得到数量与x域一致的y域图像
-
shuffle(x_input_images_raw)
#随机打乱x域图像顺序
-
shuffle(y_input_images)
#随机打乱y域图像顺序
-
return x_input_images_raw, y_input_images
#返回数量一致的x域和y域图像路径名称列表
-
else:
#与elif中的逻辑一致,只是x与y互换,不再赘述
-
mul_num = int(len(y_input_images_raw)/len(x_input_images_raw))
-
x_append_num = len(y_input_images_raw) - len(x_input_images_raw)*mul_num
-
append_list = [random.randint(
0,len(x_input_images_raw)
-1)
for i
in range(x_append_num)]
-
x_append_images = []
-
for a
in append_list:
-
x_append_images.append(x_input_images_raw[a])
-
x_input_images = x_input_images_raw * mul_num + x_append_images
-
shuffle(y_input_images_raw)
-
shuffle(x_input_images)
-
return x_input_images, y_input_images_raw
-
-
def l1_loss(src, dst):
#定义l1_loss
-
return tf.reduce_mean(tf.abs(src - dst))
-
-
def gan_loss(src, dst):
#定义gan_loss,在这里用了二范数
-
return tf.reduce_mean((src-dst)**
2)
-
-
def main():
-
if
not os.path.exists(args.snapshot_dir):
#如果保存模型参数的文件夹不存在则创建
-
os.makedirs(args.snapshot_dir)
-
if
not os.path.exists(args.out_dir):
#如果保存训练中可视化输出的文件夹不存在则创建
-
os.makedirs(args.out_dir)
-
x_datalists, y_datalists = make_train_data_list(args.x_train_data_path, args.y_train_data_path)
#得到数量相同的x域和y域图像路径名称列表
-
tf.set_random_seed(args.random_seed)
#初始一下随机数
-
x_img = tf.placeholder(tf.float32,shape=[
1, args.image_size, args.image_size,
3],name=
'x_img')
#输入的x域图像
-
y_img = tf.placeholder(tf.float32,shape=[
1, args.image_size, args.image_size,
3],name=
'y_img')
#输入的y域图像
-
-
fake_y = generator(image=x_img, reuse=
False, name=
'generator_x2y')
#生成的y域图像
-
fake_x_ = generator(image=fake_y, reuse=
False, name=
'generator_y2x')
#重建的x域图像
-
fake_x = generator(image=y_img, reuse=
True, name=
'generator_y2x')
#生成的x域图像
-
fake_y_ = generator(image=fake_x, reuse=
True, name=
'generator_x2y')
#重建的y域图像
-
-
dy_fake = discriminator(image=fake_y, reuse=
False, name=
'discriminator_y')
#判别器返回的对生成的y域图像的判别结果
-
dx_fake = discriminator(image=fake_x, reuse=
False, name=
'discriminator_x')
#判别器返回的对生成的x域图像的判别结果
-
dy_real = discriminator(image=y_img, reuse=
True, name=
'discriminator_y')
#判别器返回的对真实的y域图像的判别结果
-
dx_real = discriminator(image=x_img, reuse=
True, name=
'discriminator_x')
#判别器返回的对真实的x域图像的判别结果
-
-
gen_loss = gan_loss(dy_fake, tf.ones_like(dy_fake)) + gan_loss(dx_fake, tf.ones_like(dx_fake)) + args.lamda*l1_loss(x_img, fake_x_) + args.lamda*l1_loss(y_img, fake_y_)
#计算生成器的loss
-
-
dy_loss_real = gan_loss(dy_real, tf.ones_like(dy_real))
#计算判别器判别的真实的y域图像的loss
-
dy_loss_fake = gan_loss(dy_fake, tf.zeros_like(dy_fake))
#计算判别器判别的生成的y域图像的loss
-
dy_loss = (dy_loss_real + dy_loss_fake) /
2
#计算判别器判别的y域图像的loss
-
-
dx_loss_real = gan_loss(dx_real, tf.ones_like(dx_real))
#计算判别器判别的真实的x域图像的loss
-
dx_loss_fake = gan_loss(dx_fake, tf.zeros_like(dx_fake))
#计算判别器判别的生成的x域图像的loss
-
dx_loss = (dx_loss_real + dx_loss_fake) /
2
#计算判别器判别的x域图像的loss
-
-
dis_loss = dy_loss + dx_loss
#计算判别器的loss
-
-
gen_loss_sum = tf.summary.scalar(
"final_objective", gen_loss)
#记录生成器loss的日志
-
-
dx_loss_sum = tf.summary.scalar(
"dx_loss", dx_loss)
#记录判别器判别的x域图像的loss的日志
-
dy_loss_sum = tf.summary.scalar(
"dy_loss", dy_loss)
#记录判别器判别的y域图像的loss的日志
-
dis_loss_sum = tf.summary.scalar(
"dis_loss", dis_loss)
#记录判别器的loss的日志
-
discriminator_sum = tf.summary.merge([dx_loss_sum, dy_loss_sum, dis_loss_sum])
-
-
summary_writer = tf.summary.FileWriter(args.snapshot_dir, graph=tf.get_default_graph())
#日志记录器
-
-
g_vars = [v
for v
in tf.trainable_variables()
if
'generator'
in v.name]
#所有生成器的可训练参数
-
d_vars = [v
for v
in tf.trainable_variables()
if
'discriminator'
in v.name]
#所有判别器的可训练参数
-
-
lr = tf.placeholder(tf.float32,
None, name=
'learning_rate')
#训练中的学习率
-
d_optim = tf.train.AdamOptimizer(lr, beta1=args.beta1)
#判别器训练器
-
g_optim = tf.train.AdamOptimizer(lr, beta1=args.beta1)
#生成器训练器
-
-
d_grads_and_vars = d_optim.compute_gradients(dis_loss, var_list=d_vars)
#计算判别器参数梯度
-
d_train = d_optim.apply_gradients(d_grads_and_vars)
#更新判别器参数
-
g_grads_and_vars = g_optim.compute_gradients(gen_loss, var_list=g_vars)
#计算生成器参数梯度
-
g_train = g_optim.apply_gradients(g_grads_and_vars)
#更新生成器参数
-
-
train_op = tf.group(d_train, g_train)
#train_op表示了参数更新操作
-
config = tf.ConfigProto()
-
config.gpu_options.allow_growth =
True
#设定显存不超量使用
-
sess = tf.Session(config=config)
#新建会话层
-
init = tf.global_variables_initializer()
#参数初始化器
-
-
sess.run(init)
#初始化所有可训练参数
-
-
saver = tf.train.Saver(var_list=tf.global_variables(), max_to_keep=
50)
#模型保存器
-
-
counter =
0
#counter记录训练步数
-
-
for epoch
in range(args.epoch):
#训练epoch数
-
shuffle(x_datalists)
#每训练一个epoch,就打乱一下x域图像顺序
-
shuffle(y_datalists)
#每训练一个epoch,就打乱一下y域图像顺序
-
lrate = args.base_lr
if epoch < args.epoch_step
else args.base_lr*(args.epoch-epoch)/(args.epoch-args.epoch_step)
#得到该训练epoch的学习率
-
for step
in range(len(x_datalists)):
#每个训练epoch中的训练step数
-
counter +=
1
-
x_image_resize, y_image_resize = TrainImageReader(x_datalists, y_datalists, step, args.image_size)
#读取x域图像和y域图像
-
batch_x_image = np.expand_dims(np.array(x_image_resize).astype(np.float32), axis =
0)
#填充维度
-
batch_y_image = np.expand_dims(np.array(y_image_resize).astype(np.float32), axis =
0)
#填充维度
-
feed_dict = { lr : lrate, x_img : batch_x_image, y_img : batch_y_image}
#得到feed_dict
-
gen_loss_value, dis_loss_value, _ = sess.run([gen_loss, dis_loss, train_op], feed_dict=feed_dict)
#得到每个step中的生成器和判别器loss
-
if counter % args.save_pred_every ==
0:
#每过save_pred_every次保存模型
-
save(saver, sess, args.snapshot_dir, counter)
-
if counter % args.summary_pred_every ==
0:
#每过summary_pred_every次保存训练日志
-
gen_loss_sum_value, discriminator_sum_value = sess.run([gen_loss_sum, discriminator_sum], feed_dict=feed_dict)
-
summary_writer.add_summary(gen_loss_sum_value, counter)
-
summary_writer.add_summary(discriminator_sum_value, counter)
-
if counter % args.write_pred_every ==
0:
#每过write_pred_every次写一下训练的可视化结果
-
fake_y_value, fake_x__value, fake_x_value, fake_y__value = sess.run([fake_y, fake_x_, fake_x, fake_y_], feed_dict=feed_dict)
#run出网络输出
-
write_image = get_write_picture(x_image_resize, y_image_resize, fake_y_value, fake_x__value, fake_x_value, fake_y__value)
#得到训练的可视化结果
-
write_image_name = args.out_dir +
"/out"+ str(counter) +
".png"
#待保存的训练可视化结果路径与名称
-
cv2.imwrite(write_image_name, write_image)
#保存训练的可视化结果
-
print(
'epoch {:d} step {:d} \t gen_loss = {:.3f}, dis_loss = {:.3f}'.format(epoch, step, gen_loss_value, dis_loss_value))
-
-
if __name__ ==
'__main__':
-
main()
然后是train_image_reader.py文件:
-
import os
-
-
import numpy
as np
-
import tensorflow
as tf
-
import cv2
-
-
def TrainImageReader(x_file_list, y_file_list, step, size):
#训练数据读取接口
-
file_length = len(x_file_list)
#获取图片列表总长度
-
line_idx = step % file_length
#获取一张待读取图片的下标
-
x_line_content = x_file_list[line_idx]
#获取一张x域图片路径与名称
-
y_line_content = y_file_list[line_idx]
#获取一张y域图片路径与名称
-
x_image = cv2.imread(x_line_content,
1)
#读取一张x域的图片
-
y_image = cv2.imread(y_line_content,
1)
#读取一张y域的图片
-
x_image_resize_t = cv2.resize(x_image, (size, size))
#改变读取的x域图片的大小
-
x_image_resize = x_image_resize_t/
127.5
-1.
#归一化x域的图片
-
y_image_resize_t = cv2.resize(y_image, (size, size))
#改变读取的y域图片的大小
-
y_image_resize = y_image_resize_t/
127.5
-1.
#归一化y域的图片
-
return x_image_resize, y_image_resize
#返回读取并处理的一张x域图片和y域图片
接着是net.py文件:
-
import numpy
as np
-
import tensorflow
as tf
-
import math
-
-
#构造可训练参数
-
def make_var(name, shape, trainable = True):
-
return tf.get_variable(name, shape, trainable = trainable)
-
-
#定义卷积层
-
def conv2d(input_, output_dim, kernel_size, stride, padding = "SAME", name = "conv2d", biased = False):
-
input_dim = input_.get_shape()[
-1]
-
with tf.variable_scope(name):
-
kernel = make_var(name =
'weights', shape=[kernel_size, kernel_size, input_dim, output_dim])
-
output = tf.nn.conv2d(input_, kernel, [
1, stride, stride,
1], padding = padding)
-
if biased:
-
biases = make_var(name =
'biases', shape = [output_dim])
-
output = tf.nn.bias_add(output, biases)
-
return output
-
-
#定义空洞卷积层
-
def atrous_conv2d(input_, output_dim, kernel_size, dilation, padding = "SAME", name = "atrous_conv2d", biased = False):
-
input_dim = input_.get_shape()[
-1]
-
with tf.variable_scope(name):
-
kernel = make_var(name =
'weights', shape = [kernel_size, kernel_size, input_dim, output_dim])
-
output = tf.nn.atrous_conv2d(input_, kernel, dilation, padding = padding)
-
if biased:
-
biases = make_var(name =
'biases', shape = [output_dim])
-
output = tf.nn.bias_add(output, biases)
-
return output
-
-
#定义反卷积层
-
def deconv2d(input_, output_dim, kernel_size, stride, padding = "SAME", name = "deconv2d"):
-
input_dim = input_.get_shape()[
-1]
-
input_height = int(input_.get_shape()[
1])
-
input_width = int(input_.get_shape()[
2])
-
with tf.variable_scope(name):
-
kernel = make_var(name =
'weights', shape = [kernel_size, kernel_size, output_dim, input_dim])
-
output = tf.nn.conv2d_transpose(input_, kernel, [
1, input_height *
2, input_width *
2, output_dim], [
1,
2,
2,
1], padding =
"SAME")
-
return output
-
-
#定义batchnorm(批次归一化)层
-
def batch_norm(input_, name="batch_norm"):
-
with tf.variable_scope(name):
-
input_dim = input_.get_shape()[
-1]
-
scale = tf.get_variable(
"scale", [input_dim], initializer=tf.random_normal_initializer(
1.0,
0.02, dtype=tf.float32))
-
offset = tf.get_variable(
"offset", [input_dim], initializer=tf.constant_initializer(
0.0))
-
mean, variance = tf.nn.moments(input_, axes=[
1,
2], keep_dims=
True)
-
epsilon =
1e-5
-
inv = tf.rsqrt(variance + epsilon)
-
normalized = (input_-mean)*inv
-
output = scale*normalized + offset
-
return output
-
-
#定义最大池化层
-
def max_pooling(input_, kernel_size, stride, name, padding = "SAME"):
-
return tf.nn.max_pool(input_, ksize=[
1, kernel_size, kernel_size,
1], strides=[
1, stride, stride,
1], padding=padding, name=name)
-
-
#定义平均池化层
-
def avg_pooling(input_, kernel_size, stride, name, padding = "SAME"):
-
return tf.nn.avg_pool(input_, ksize=[
1, kernel_size, kernel_size,
1], strides=[
1, stride, stride,
1], padding=padding, name=name)
-
-
#定义lrelu激活层
-
def lrelu(x, leak=0.2, name = "lrelu"):
-
return tf.maximum(x, leak*x)
-
-
#定义relu激活层
-
def relu(input_, name = "relu"):
-
return tf.nn.relu(input_, name = name)
-
-
#定义残差块
-
def residule_block_33(input_, output_dim, kernel_size = 3, stride = 1, dilation = 2, atrous = False, name = "res"):
-
if atrous:
-
conv2dc0 = atrous_conv2d(input_ = input_, output_dim = output_dim, kernel_size = kernel_size, dilation = dilation, name = (name +
'_c0'))
-
conv2dc0_norm = batch_norm(input_ = conv2dc0, name = (name +
'_bn0'))
-
conv2dc0_relu = relu(input_ = conv2dc0_norm)
-
conv2dc1 = atrous_conv2d(input_ = conv2dc0_relu, output_dim = output_dim, kernel_size = kernel_size, dilation = dilation, name = (name +
'_c1'))
-
conv2dc1_norm = batch_norm(input_ = conv2dc1, name = (name +
'_bn1'))
-
else:
-
conv2dc0 = conv2d(input_ = input_, output_dim = output_dim, kernel_size = kernel_size, stride = stride, name = (name +
'_c0'))
-
conv2dc0_norm = batch_norm(input_ = conv2dc0, name = (name +
'_bn0'))
-
conv2dc0_relu = relu(input_ = conv2dc0_norm)
-
conv2dc1 = conv2d(input_ = conv2dc0_relu, output_dim = output_dim, kernel_size = kernel_size, stride = stride, name = (name +
'_c1'))
-
conv2dc1_norm = batch_norm(input_ = conv2dc1, name = (name +
'_bn1'))
-
add_raw = input_ + conv2dc1_norm
-
output = relu(input_ = add_raw)
-
return output
-
-
#定义生成器
-
def generator(image, gf_dim=64, reuse=False, name="generator"):
-
#生成器输入尺度: 1*256*256*3
-
input_dim = image.get_shape()[
-1]
-
with tf.variable_scope(name):
-
if reuse:
-
tf.get_variable_scope().reuse_variables()
-
else:
-
assert tf.get_variable_scope().reuse
is
False
-
#第1个卷积模块,输出尺度: 1*256*256*64
-
c0 = relu(batch_norm(conv2d(input_ = image, output_dim = gf_dim, kernel_size =
7, stride =
1, name =
'g_e0_c'), name =
'g_e0_bn'))
-
#第2个卷积模块,输出尺度: 1*128*128*128
-
c1 = relu(batch_norm(conv2d(input_ = c0, output_dim = gf_dim *
2, kernel_size =
3, stride =
2, name =
'g_e1_c'), name =
'g_e1_bn'))
-
#第3个卷积模块,输出尺度: 1*64*64*256
-
c2 = relu(batch_norm(conv2d(input_ = c1, output_dim = gf_dim *
4, kernel_size =
3, stride =
2, name =
'g_e2_c'), name =
'g_e2_bn'))
-
-
#9个残差块:
-
r1 = residule_block_33(input_ = c2, output_dim = gf_dim*
4, atrous =
False, name=
'g_r1')
-
r2 = residule_block_33(input_ = r1, output_dim = gf_dim*
4, atrous =
False, name=
'g_r2')
-
r3 = residule_block_33(input_ = r2, output_dim = gf_dim*
4, atrous =
False, name=
'g_r3')
-
r4 = residule_block_33(input_ = r3, output_dim = gf_dim*
4, atrous =
False, name=
'g_r4')
-
r5 = residule_block_33(input_ = r4, output_dim = gf_dim*
4, atrous =
False, name=
'g_r5')
-
r6 = residule_block_33(input_ = r5, output_dim = gf_dim*
4, atrous =
False, name=
'g_r6')
-
r7 = residule_block_33(input_ = r6, output_dim = gf_dim*
4, atrous =
False, name=
'g_r7')
-
r8 = residule_block_33(input_ = r7, output_dim = gf_dim*
4, atrous =
False, name=
'g_r8')
-
r9 = residule_block_33(input_ = r8, output_dim = gf_dim*
4, atrous =
False, name=
'g_r9')
-
#第9个残差块的输出尺度: 1*64*64*256
-
-
#第1个反卷积模块,输出尺度: 1*128*128*128
-
d1 = relu(batch_norm(deconv2d(input_ = r9, output_dim = gf_dim *
2, kernel_size =
3, stride =
2, name =
'g_d1_dc'),name =
'g_d1_bn'))
-
#第2个反卷积模块,输出尺度: 1*256*256*64
-
d2 = relu(batch_norm(deconv2d(input_ = d1, output_dim = gf_dim, kernel_size =
3, stride =
2, name =
'g_d2_dc'),name =
'g_d2_bn'))
-
#最后一个卷积模块,输出尺度: 1*256*256*3
-
d3 = conv2d(input_=d2, output_dim = input_dim, kernel_size =
7, stride =
1, name =
'g_d3_c')
-
#经过tanh函数激活得到生成的输出
-
output = tf.nn.tanh(d3)
-
return output
-
-
#定义判别器
-
def discriminator(image, df_dim=64, reuse=False, name="discriminator"):
-
with tf.variable_scope(name):
-
if reuse:
-
tf.get_variable_scope().reuse_variables()
-
else:
-
assert tf.get_variable_scope().reuse
is
False
-
#第1个卷积模块,输出尺度: 1*128*128*64
-
h0 = lrelu(conv2d(input_ = image, output_dim = df_dim, kernel_size =
4, stride =
2, name=
'd_h0_conv'))
-
#第2个卷积模块,输出尺度: 1*64*64*128
-
h1 = lrelu(batch_norm(conv2d(input_ = h0, output_dim = df_dim*
2, kernel_size =
4, stride =
2, name=
'd_h1_conv'),
'd_bn1'))
-
#第3个卷积模块,输出尺度: 1*32*32*256
-
h2 = lrelu(batch_norm(conv2d(input_ = h1, output_dim = df_dim*
4, kernel_size =
4, stride =
2, name=
'd_h2_conv'),
'd_bn2'))
-
#第4个卷积模块,输出尺度: 1*32*32*512
-
h3 = lrelu(batch_norm(conv2d(input_ = h2, output_dim = df_dim*
8, kernel_size =
4, stride =
1, name=
'd_h3_conv'),
'd_bn3'))
-
#最后一个卷积模块,输出尺度: 1*32*32*1
-
output = conv2d(input_ = h3, output_dim =
1, kernel_size =
4, stride =
1, name=
'd_h4_conv')
-
return output
上面的三个文件就是训练时所需的全部代码,如果要启动训练,只需改动两个参数即可,即train.py中参数中的最后两个(即x_train_data_path和Y_train_data_path,指X域和Y域的训练输入图像路径)。
下面是evaluate.py文件:
-
from __future__
import print_function
-
-
import argparse
-
from datetime
import datetime
-
from random
import shuffle
-
import os
-
import sys
-
import time
-
import math
-
import tensorflow
as tf
-
import numpy
as np
-
import glob
-
import cv2
-
-
from test_image_reader
import *
-
from net
import *
-
-
parser = argparse.ArgumentParser(description=
'')
-
-
parser.add_argument(
"--x_test_data_path", default=
'./dataset/horse2zebra/testA/', help=
"path of x test datas.")
#x域的测试图片路径
-
parser.add_argument(
"--y_test_data_path", default=
'./dataset/horse2zebra/testB/', help=
"path of y test datas.")
#y域的测试图片路径
-
parser.add_argument(
"--image_size", type=int, default=
256, help=
"load image size")
#网络输入的尺度
-
parser.add_argument(
"--snapshots", default=
'./snapshots/',help=
"Path of Snapshots")
#读取训练好的模型参数的路径
-
parser.add_argument(
"--out_dir_x", default=
'./test_output_x/',help=
"Output Folder")
#保存x域的输入图片与生成的y域图片的路径
-
parser.add_argument(
"--out_dir_y", default=
'./test_output_y/',help=
"Output Folder")
#保存y域的输入图片与生成的x域图片的路径
-
-
args = parser.parse_args()
-
-
def make_test_data_list(x_data_path, y_data_path):
#make_test_data_list函数得到测试中的x域和y域的图像路径名称列表
-
x_input_images = glob.glob(os.path.join(x_data_path,
"*"))
#读取全部的x域图像路径名称列表
-
y_input_images = glob.glob(os.path.join(y_data_path,
"*"))
#读取全部的y域图像路径名称列表
-
return x_input_images, y_input_images
-
-
def cv_inv_proc(img):
#cv_inv_proc函数将读取图片时归一化的图片还原成原图
-
img_rgb = (img +
1.) *
127.5
-
return img_rgb.astype(np.float32)
#bgr
-
-
def get_write_picture(x_image, y_image, fake_y, fake_x):
#get_write_picture函数得到网络测试结果
-
x_image = cv_inv_proc(x_image)
#还原x域的图像
-
y_image = cv_inv_proc(y_image)
#还原y域的图像
-
fake_y = cv_inv_proc(fake_y[
0])
#还原生成的y域的图像
-
fake_x = cv_inv_proc(fake_x[
0])
#还原生成的x域的图像
-
x_output = np.concatenate((x_image, fake_y), axis=
1)
#得到x域的输入图像以及对应的生成的y域图像
-
y_output = np.concatenate((y_image, fake_x), axis=
1)
#得到y域的输入图像以及对应的生成的x域图像
-
return x_output, y_output
-
-
def main():
-
if
not os.path.exists(args.out_dir_x):
#如果保存x域测试结果的文件夹不存在则创建
-
os.makedirs(args.out_dir_x)
-
if
not os.path.exists(args.out_dir_y):
#如果保存y域测试结果的文件夹不存在则创建
-
os.makedirs(args.out_dir_y)
-
-
x_datalists, y_datalists = make_test_data_list(args.x_test_data_path, args.y_test_data_path)
#得到待测试的x域和y域图像路径名称列表
-
test_x_image = tf.placeholder(tf.float32,shape=[
1,
256,
256,
3], name =
'test_x_image')
#输入的x域图像
-
test_y_image = tf.placeholder(tf.float32,shape=[
1,
256,
256,
3], name =
'test_y_image')
#输入的y域图像
-
-
fake_y = generator(image=test_x_image, reuse=
False, name=
'generator_x2y')
#得到生成的y域图像
-
fake_x = generator(image=test_y_image, reuse=
False, name=
'generator_y2x')
#得到生成的x域图像
-
-
restore_var = [v
for v
in tf.global_variables()
if
'generator'
in v.name]
#需要载入的已训练的模型参数
-
-
config = tf.ConfigProto()
-
config.gpu_options.allow_growth =
True
#设定显存不超量使用
-
sess = tf.Session(config=config)
#建立会话层
-
-
saver = tf.train.Saver(var_list=restore_var,max_to_keep=
1)
#导入模型参数时使用
-
checkpoint = tf.train.latest_checkpoint(args.snapshots)
#读取模型参数
-
saver.restore(sess, checkpoint)
#导入模型参数
-
-
total_step = len(x_datalists)
if len(x_datalists) > len(y_datalists)
else len(y_datalists)
#测试的总步数
-
for step
in range(total_step):
-
test_ximage_name, test_ximage = TestImageReader(x_datalists, step, args.image_size)
#得到x域的输入及名称
-
test_yimage_name, test_yimage = TestImageReader(y_datalists, step, args.image_size)
#得到y域的输入及名称
-
batch_x_image = np.expand_dims(np.array(test_ximage).astype(np.float32), axis =
0)
#填充维度
-
batch_y_image = np.expand_dims(np.array(test_yimage).astype(np.float32), axis =
0)
#填充维度
-
feed_dict = { test_x_image : batch_x_image, test_y_image : batch_y_image}
#建立feed_dict
-
fake_y_value, fake_x_value = sess.run([fake_y, fake_x], feed_dict=feed_dict)
#得到生成的y域图像与x域图像
-
x_write_image, y_write_image = get_write_picture(test_ximage, test_yimage, fake_y_value, fake_x_value)
#得到最终的图片结果
-
x_write_image_name = args.out_dir_x +
"/"+ test_ximage_name +
".png"
#待保存的x域图像与其对应的y域生成结果名字
-
y_write_image_name = args.out_dir_y +
"/"+ test_yimage_name +
".png"
#待保存的y域图像与其对应的x域生成结果名字
-
cv2.imwrite(x_write_image_name, x_write_image)
#保存图像
-
cv2.imwrite(y_write_image_name, y_write_image)
#保存图像
-
print(
'step {:d}'.format(step))
-
-
if __name__ ==
'__main__':
-
main()
最后是test_image_reader.py文件的代码:
-
import os
-
-
import numpy
as np
-
import tensorflow
as tf
-
import cv2
-
-
def TestImageReader(file_list, step, size):
#训练数据读取接口
-
file_length = len(file_list)
#获取图片列表总长度
-
line_idx = step % file_length
#获取一张待读取图片的下标
-
test_line_content = file_list[line_idx]
#获取一张测试图片路径与名称
-
test_image_name, _ = os.path.splitext(os.path.basename(test_line_content))
#获取该张测试图片名
-
test_image = cv2.imread(test_line_content,
1)
#读取一张测试图片
-
test_image_resize_t = cv2.resize(test_image, (size, size))
#改变读取的测试图片的大小
-
test_image_resize = test_image_resize_t/
127.5
-1
#归一化测试图片
-
return test_image_name, test_image_resize
#返回读取并处理的一张测试图片与它的名称
如果需要测试训练好的模型,在evaluate.py文件中设置三个参数即可。分别是第1个(x_test_data_path,指定X域测试输入图片的路径),第2个(y_test_data_path,指定Y域测试输入图片的路径)和第四个(snapshots,设置为训练的模型保存路径)。
下面,笔者就以训练的马和斑马相互转换为例,展示一下CycleGAN的实际效果:
首先是训练时的可视化输出图像,第一行从左往右三张依次是X域输入图像(马),生成的Y域图像(斑马),重建回的X域输入图像;第二行从左往右三张依次是Y域输入图像(斑马),生成的X域图像(马),重建回的Y域输入图像。
训练200次时的效果:

训练16500次的效果:

训练35000次的效果:

训练86200次的效果:

训练160800次的效果:

训练209300次的效果:

训练265500次的效果:

下面展示一下训练过程中的loss变化:
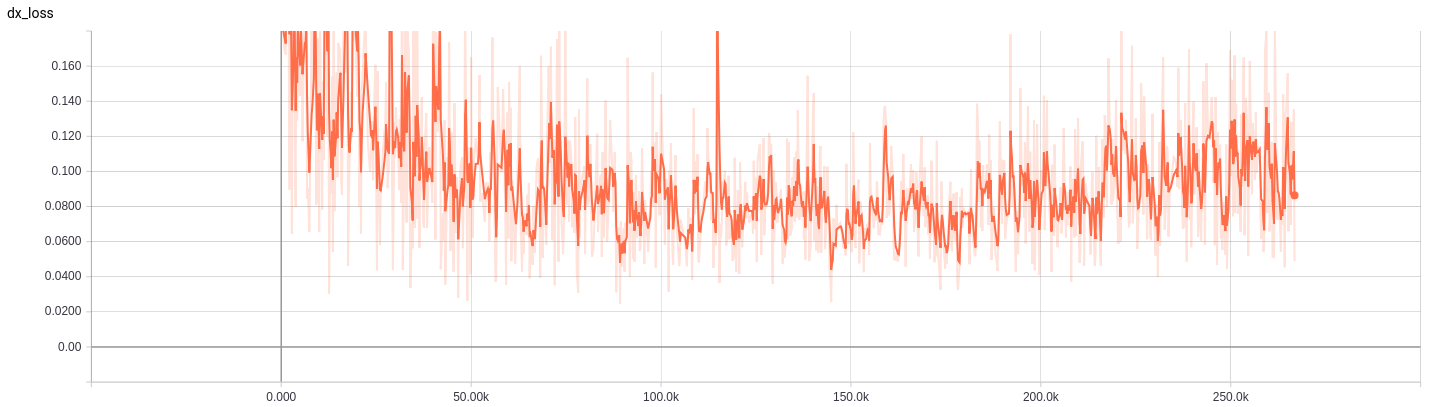
首先是判别器Dx的loss曲线:
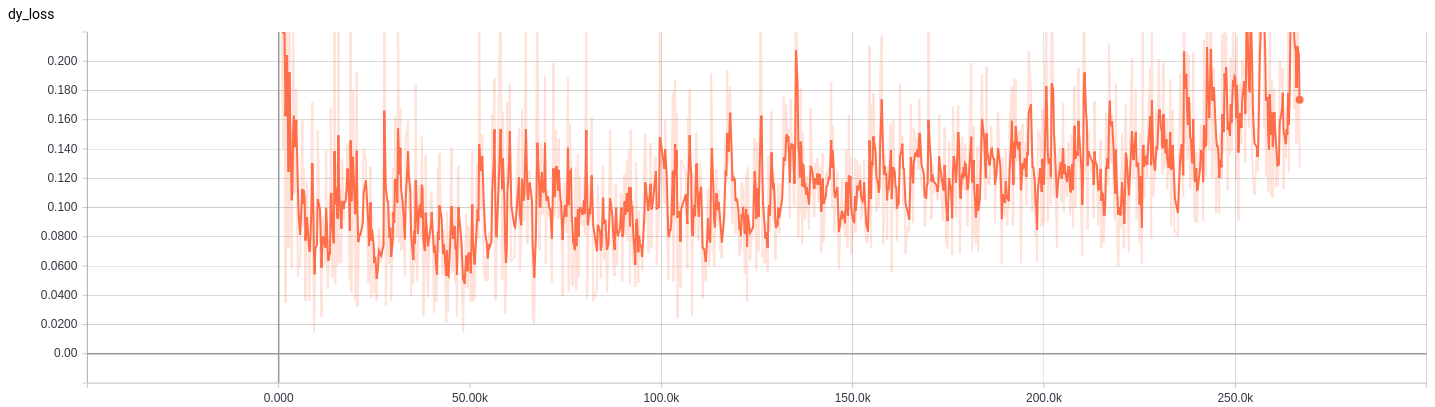
然后是判别器Dy的loss曲线:
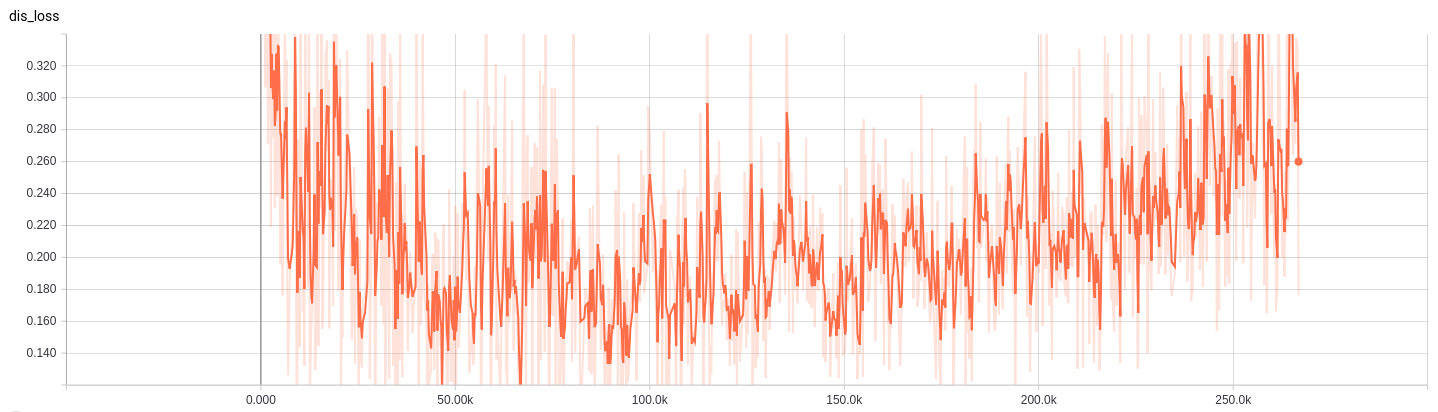
接着是判别loss曲线:
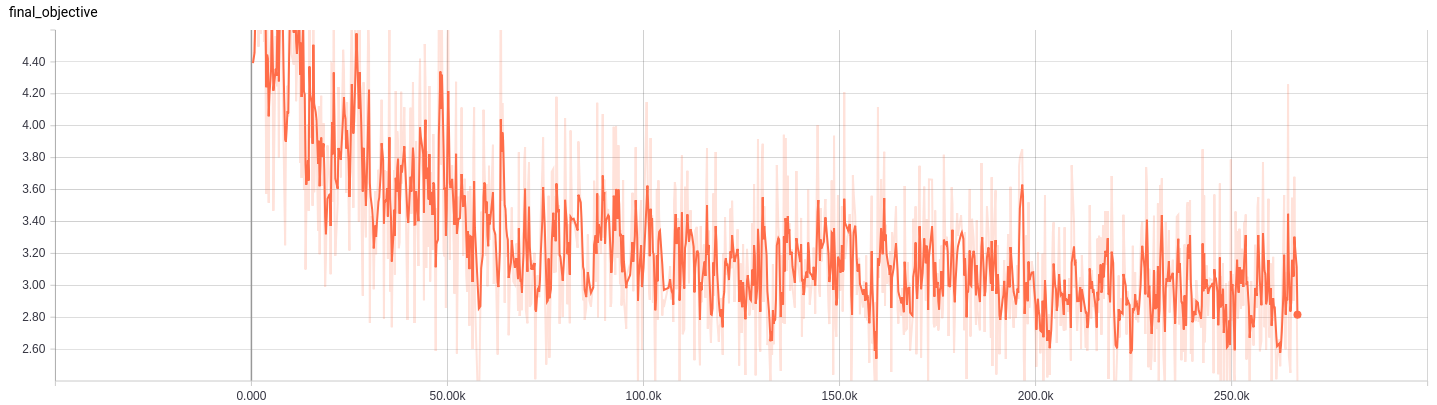
最后是CycleGAN总的目标函数loss曲线:
下面展示一些模型测试时斑马与马互相转换的效果:
每张图片中,左边的是输入图像,右边的是生成结果。
先展示一些成功的转换:
马->斑马






斑马->马






再展示一些失败的转换案例:
马->斑马




斑马->马




笔者还跑了一下苹果和橘子的互相转换,也展示一下效果:
先展示一些成功的转换:
苹果->橘子
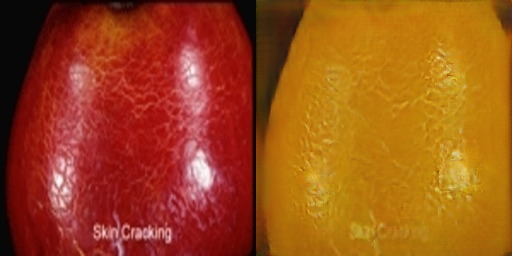





橘子->苹果






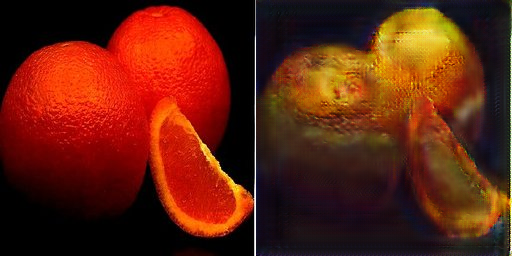
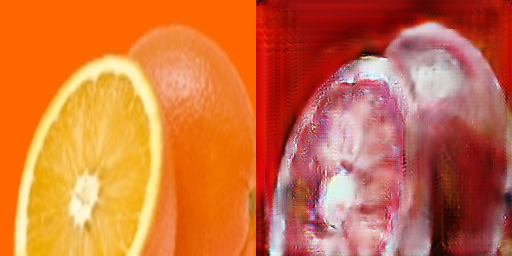
最后展示一些失败的转换案例:
苹果->橘子




橘子->苹果


上面详细地展示了CycleGAN在两个数据集上的结果。
很敬佩CycleGAN的作者,Berkeley AI Research laboratory的Jun-Yan Zhu,同时也感谢他为大家带来如此有意义的研究成果。笔者也衷心希望,此篇博客对大家的学习研究有帮助。
欢迎阅读笔者后续博客,各位读者朋友的支持与鼓励是我最大的动力!
written by jiong
岂不罹凝寒,松柏有本性















 5733
5733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









