







线程是CPU调度的最小单位,Python由于GIL锁的存在,CPython解释器并不能真正实现多线程,他不适合CPU密集型,但是适合IO密集型,本文主要讲述 python 多线程的使用。
文章目录
多线程
以下文字出自 菜鸟教程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
- 使用线程可以把占据长时间的程序中的任务放到后台去处理。
- 用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
- 程序的运行速度可能加快。
- 在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。【这里的应用程序也可以说是一个进程,进程是操作系统资源分配的最小单位,线程是CPU执行的最小单位】
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。【这段话比较重要,因为线程切换需要随之切换上下文】
- 线程可以被抢占(中断)。
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) – 这就是线程的退让。
线程可以分为:
- 内核线程:由操作系统内核创建和撤销。
- 用户线程:不需要内核支持而在用户程序中实现的线程。
Python3 线程中常用的两个模块为:
- _thread
- threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 “_thread”。
后面讲述的多线程,都是用 threading 模块。
Thread
python中一切皆对象,所以线程也是一个对象。定义在threading库中:
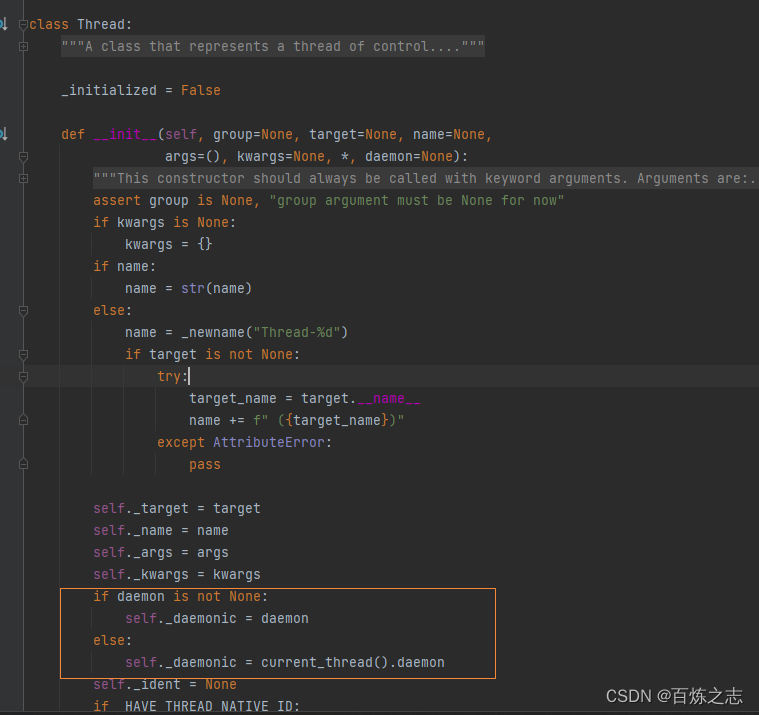
截图是 Thread 的初始化方法的部分,下面说一下各个参数的含义
- group: 所属线程组,这个用的少
- target:一个可执行的对象,一般是一个函数,但是所有定义了
__call__的类生成的对象都是可执行的对象,里面是我们要用多线程跑的代码 - name:线程名字,为None时,默认为Thread-N
- args:线程函数的参数,必须按照顺序传递
- kwrags:目标函数的关键字参数,传递的是
age=12这种 - daemon:线程的模式,其实只有两种值
- True:当前线程为守护线程,主线程结束了他就结束了,无论执行到哪里了
- False:主线程结束了,他依然会执行
- None:从主进程继承
下面用代码来演示 daemon 参数
daemo = True
import threading
import time
def function():
print('+' * 10, '子线程开始', '+' * 10)
time.sleep(3)
print('-' * 10, '子线程结束', '-' * 10)
t = threading.Thread(target=function, daemon=True)
t.start() # 子线程启动,不调用 start,子线程是不会启动和生效的
time.sleep(1) # 主线程休眠一秒,可以让子线程被调度执行
print('主线程结束')
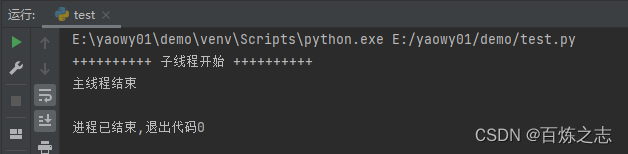
子线程结束并没有打印出来,主线程结束,子线程就结束了。
daemo = False
将 daemo 设置为 False,再执行

子线程结束打印出来了。
但是这里,很多博客都没讲清楚,如果在主线程里面再添加一行 t.join(),哪怕是子线程被设置为 True,主线程依然会等待子线程执行完。

join 的作用
join 的作用是让父线程等待子线程执行完,一不留神,可能多线程变成了单线程在使用。这里也是很多博客没有说清楚
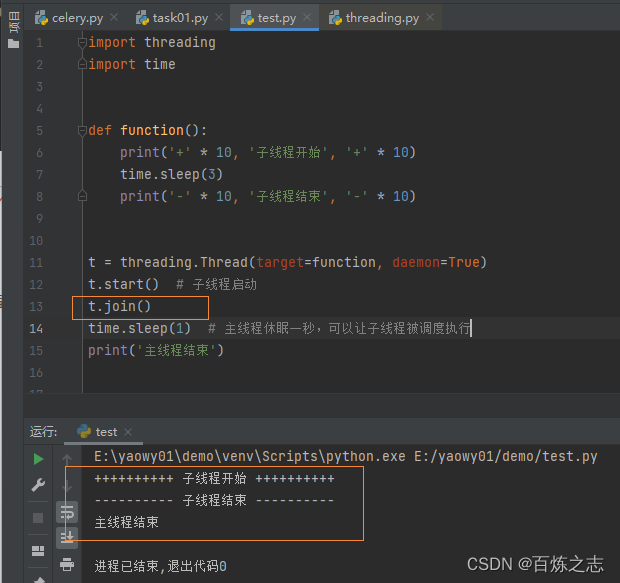
注意观察 join 方法的调用时机,他会让主线程在 join 调用之后就一直处于等待,直到子线程执行完,才会继续向下执行。所以用不好是会变成单线程的。
比如下面这段代码,完全就是单线程的效果
import threading
import time
def func():
print('*' * 10, f'当前线程 {threading.current_thread().name}')
time.sleep(5)
for i in range(0, 3):
t = threading.Thread(target=func, daemon=True)
t.start()
t.join()
在循环体内,每次调用了 join(), 必须等到刚刚创建的线程执行完了,主线程才能创建下一个线程
继承使用
上面讲述的方法是直接生成线程对象的方式使用,还可以通过继承 Thread 类实现。
使用threading模块实现一个新的线程,需要下面3步:
- 继承于Thread 类
- 重写
__init__方法,可以添加额外的参数 - 最后,需要重写 run() 方法来实现线程要做的事情
run()方法默认就是创建线程threading时,传递的target function。start方法会自动调用run()。

start 方法已经篇底层了,没必要继续深入研究下去,我们只需要知道,start() 会调用 run(),而 run() 又会调用我们之前传递的 target,所以如果我们直接重写 run 方法,就需要传递 target 了。
使用示例:
import threading
import time
class PrintThread(threading.Thread):
def __init__(self, xstr, daemon):
super().__init__(daemon=daemon)
self.xstr = xstr
def run(self):
print(self.xstr)
pt = PrintThread('yaowy', daemon=False)
pt.start()
time.sleep(1)
模块方法和类方法
模块方法
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
import threading
import time
def func():
print('*' * 10, f'当前线程 {threading.current_thread().name}')
time.sleep(5)
for i in range(5):
threading.Thread(target=func, daemon=False).start()
time.sleep(1)
print(threading.enumerate())
print(f'主线程名{threading.current_thread().name}')
print(threading.activeCount())
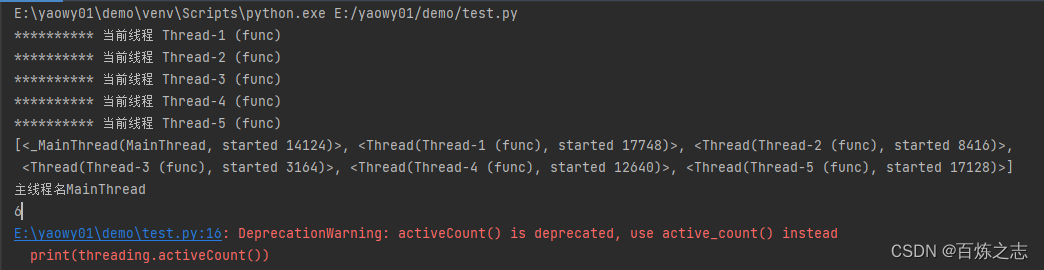
- 当前活跃的线程是 6,包括主线程
- activeCount 将要取消,请使用 active_count
类方法
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
上面的方法前面都有涉及,这里就不演示了。
多线程多进程经常会问到互斥与同步,但是很多人一直搞不清楚这两个概念。
互斥和同步是两个不一样的概念:
- 互斥只需要保证同时只有一个线程在处理临界资源。
- 而所谓同步就是有顺序的执行,拿最经典的生产者-消费者为例,必须要先生产出产品,才能消费。存在先后顺序!
首先要提一个概念:原子操作。无论是lock上锁,还是信号量加减,都必须是原子操作。即该操作要么不执行,一执行就不可中断,直到运行结束。
很好理解,比如 lock 上锁,如果该过程执行到一半,cpu 切换了线程,进而会导致异常。
解决办法:
- 要么你对lock继续上锁,可这样无穷递归无法解决问题 ×
- 干脆操作系统规定有些操作不可以中断,就有了原子操作的概念 √
互斥
这里说一下为什么需要互斥。
现在有一个卖票场景,票总数是 100张,线程 AB 都在卖。线程 A 读取到一共有 100 张票,B 也读取到了,A 卖掉了 1 张,将原值改为 99 张, B 也以为有 100 张,卖掉了 一张,也改为 99 张,但其实应该还剩 98张才对。
很遗憾,因为 Python GIL 解释器锁以及当前计算机的超高运算速度的缘故,我试了好久也没办法做出最贴切的案例,这里我做一个类似的案例出来。
# 共享全局变量
import threading
import time
# 资源竞争(未添加锁)示例
global_value = 0
def func():
global global_value
b = global_value + 1
time.sleep(1) # 这里模拟我们的业务操作
global_value = b
if __name__ == '__main__':
threading.Thread(target=func, daemon=False).start()
threading.Thread(target=func, daemon=False).start()
time.sleep(3)
print(global_value)

假定我们的业务操作比较繁琐耗时,先取全局变量的值,经过一番计算之后,修改全局变量的值,经过两次加 1,他应该等于 2才对,但实际上他等于 1,。这就是资源竞争。
一份资源同一时刻只允许一个线程使用。
Lock
这里就要引入锁机制了,将会读取公共资源,并且可能会修改的代码锁住,某一段时间内只有拿到锁的线程才能执行这段代码。这样就可以避免产生资源竞争。
注意,逻辑上是锁住了公共资源,实际上是锁住了某段代码,使得某一段时间之内,只有一个线程可以执行这段代码。
import threading
import time
global_value = 0 # 公共资源
lock = threading.Lock() # 锁
def func():
global global_value
'''
这里是各个线程的计算代码,没有读取和操作公共资源
'''
lock.acquire() # 从这里开始,代码被锁住
b = global_value + 1 # 读取公共资源
time.sleep(1) # 这里模拟我们的业务操作
global_value = b # 操作公共资源
lock.release() # 从这里结束,代码解锁
if __name__ == '__main__':
threading.Thread(target=func, daemon=False).start()
threading.Thread(target=func, daemon=False).start()
time.sleep(5)
print(global_value)
这个流程就是:
执行到 lock.acquire 的时候,锁会被当前线程拿到,当另一个线程也执行到这里,尝试拿到锁,结果发现锁未释放,该线程也就不执行了,卡在这里,直到拿到锁的线程执行了 lock.release 释放了锁,该线程抢到了锁,才能执行这段代码。
这里需要注意的是,由于被锁住的代码同一时间段只允许一个线程执行,所以这段代码实际上串行的,但是这段代码之外是并行的,所以锁代码的时候需要尽可能的少锁住,避免串行代码太多,影响了程序的执行效率。线程开的太多,大家都在上锁的代码这里竞争锁资源,也会增加拥堵,影响程序的执行效率。
上锁方法 acquire 和 释放锁方法 release 可以直接用 with 代替
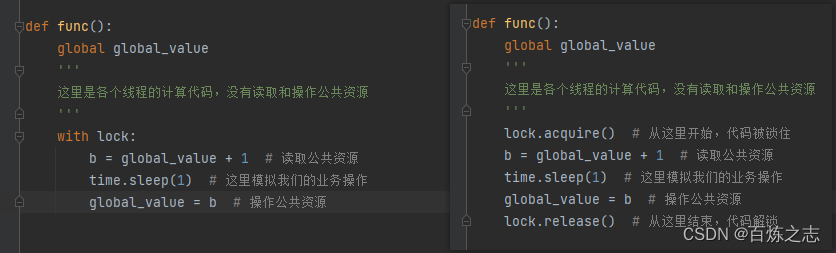
这两种写法等价。
另外一个 Lock 锁对象只能上一次,不能重复上锁,其他的线程也可以释放该锁。
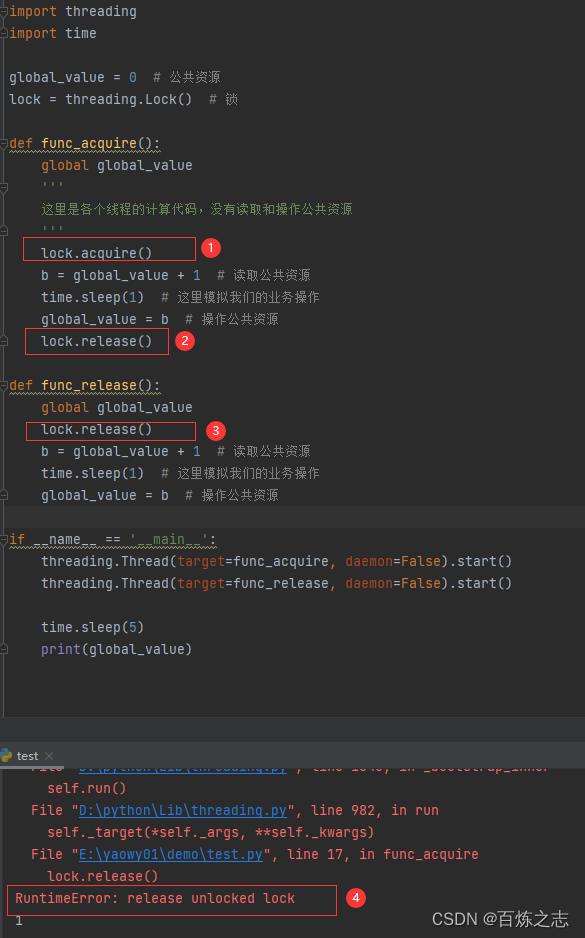
【1】加锁,【3】释放了锁,【2】尝试释放锁,结果已经被释放了,因此打印了【4】.释放了的锁不能再次释放。
RLock
递归锁,又名可重入锁。
- 跟之前 Lock 不同的是,Lock对一个线程只能加一次锁,RLock可以对一个线程加多次锁。
- 谁拿到谁释放。如果线程A拿到锁,线程B无法释放这个锁,只有A可以释放;
- acquire多少次就必须release多少次,只有最后一次release才能改变RLock的状态为unlocked
如果一个东西,我们光知道怎么用,而不知道应用场景的话,是很难接受和记住的。因此,我先描述一种场景。
class Num(object):
def __init__(self):
self.num = 0
def op1(self):
self.num += 1
def op2(self):
self.num -= 1
self.op1()
类 Num 对外提供功能,op1 可以单独给外部使用,op2 也能单独给外部使用,同时 op2 也需要调用 op1,并且资源 num,每次都只能给一个线程使用。这样的应用场景确实存在,但是没办法具现化在博客里。
我们看到了 op1 和 op2 都有操作 num,因此他们操作 num 的时候必须上锁,因为 num 同一时间只允许一个线程使用。
假如说 op1 和 op2 分别使用不同的锁,如果在 op2 获取到了一个锁,想要调用 op2,结果另一个线程,他没有调用 op2, 直接调用 op1,这个时候 op1 中使用的锁还空闲着,被另一个线程拿到了,这个时候就是两个线程都在操作 num,就会发生资源竞争了,不安全。
但是可重入锁完美解决了这个问题。
import threading
class Num(object):
def __init__(self):
self.num = 0
self.rlock = threading.RLock()
def op1(self):
with self.rlock:
self.num += 1
def op2(self):
with self.rlock:
self.num -= 1
self.op1()
可重入锁的用法和 Lock 一样。
好处: 减少了锁使用数量,定义多个锁增加了维护难度。 保证了代码的扩展性。
RLock 源码
可重入锁的实现非常巧妙,阅读其源码对我们有很大的提升。
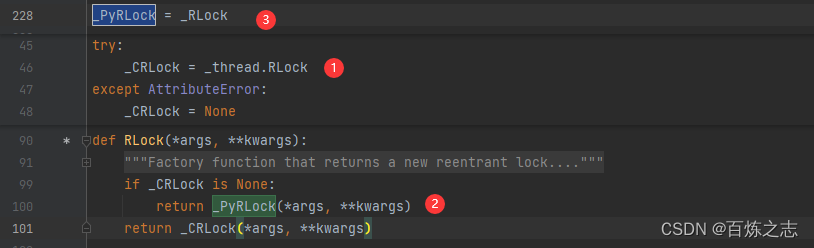
这段代码是我截图拼凑而成,注意看行号
如果_threading中定义了 RLock,则最终会使用 _threading.RLock,否则就是使用 _PyRLock,而 _PyRLock 就是 _RLock。这里使用的是 _RLock,我们就看这个类。
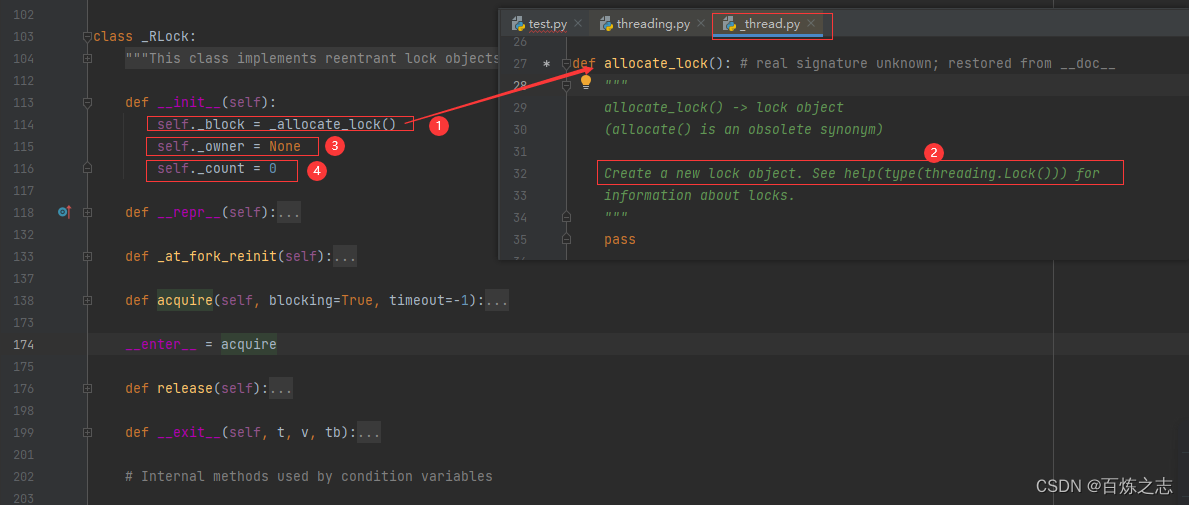
【1】调用 _allocate_lock 方法创建一个锁,
【2】这里已经是底层了,我们看注释即可。返回一个锁对象
【3】保存锁的拥有者,实例化的时候,他还没有拥有者,为 None
【4】保存一个次数
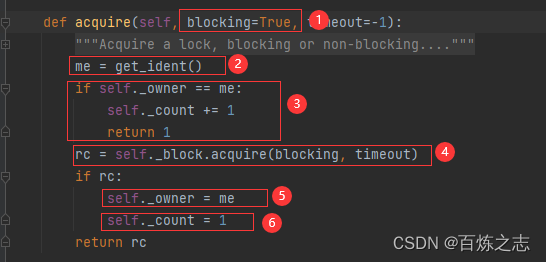
某个线程初次上锁
【1】是否阻塞,默认是阻塞的,如果该值为False,表示是非阻塞的,也就是如果获取不到锁,我就立马返回,如果blocking为False,则timeout 参数将会失效,因为既然非阻塞,也就没有必要等待锁释放了。
【2】获取当前线程的ID
【3】第一执行 acquire 方法的时候,_owner 为空,所以这里不会执行
【4】调用保存的所对象的 acquire 方法,如果获取成功,在这里已经开始锁住了,他的返回值是 bool
【5】如果锁住了,就将当前锁对象的拥有者标记为当前线程
【6】如果锁住了,就将上锁次数设置为 1
某个线程多次上锁
【3】此时3必定执行,并且上锁次数增加 1,然后直接返回了。所以多次上锁,底层只上锁了一次。
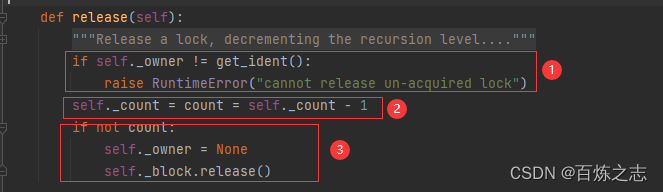
【1】如果当前线程不是该锁的拥有者,则弹出运行时错误,保证了只有上锁的线程才能释放锁
【2】释放一次,上锁记录就减1
【3】当上锁次数减到了0,这里就会执行,先将拥有者置为空,再真正的释放锁。
讲同步的时候需要用到信号量,讲信号量又要用到条件,所以下面按照,条件,信号量,同步来讲。其实讲完了条件和信号量之后,同步不讲都没关系。
Condition
Condition 翻译为条件。
所谓 condition 条件变量,即这种机制是在满足了特定的条件后,线程才可以访问相关的数据。 这种同步机制就是一个线程等待特定的条件,另一个线程通知它条件已经发生。一旦条件发生,该线程就会获取锁,从而独占共享资源的访问。
Condition包含以下部分:
- c.acquire(*args):获取底层锁。此方法将调用底层锁上对应的acquire(*args)方法。
- c.release():释放底层锁。此方法将调用底层锁上对应的release()方法
- c.wait(timeout):等待直到获取通知或出现超时为止。此方法在调用线程已经获取锁之后调用。
调用时,将释放底层锁,而且线程将进入睡眠状态,直到另一个线程在条件变量上执行notify()或notify_all()方法将其唤醒为止。在线程被唤醒后,线程讲重新获取锁,方法也会返回。timeout是浮点数,单位为秒。如果超时,线程将被唤醒,重新获取锁,而控制将被返回。 - c.notify(n):唤醒一个或多个等待此条件变量的线程。此方法只会在调用线程已经获取锁之后调用,
而且如果没有正在等待的线程,它就什么也不做。
n指定要唤醒的线程数量,默认为1.被唤醒的线程在它们重新获取锁之前不会从wait()调用返回。 - c.notify_all():唤醒所有等待此条件的线程。
一个经典的模型,生产者消费者模型
现在有一个商品队列,只要队列没有满,生产者就应该不断生产商品。只要商品队列还有商品就应该不断消费。如果商品队列空了,消费者就应该休息,如果商品队列满了,生产者就应该休息。
这才是真正的应用场景,然后我翻了不少博客,返现很多案例把多线程写成了单线程,让我疑惑了好久,然后我自己写了一个。
案例
from threading import Thread, Condition
import time
items = []
condition = Condition()
class Consumer(Thread):
def __init__(self):
Thread.__init__(self)
def consume(self):
global condition
global items
if len(items) == 0: # 不加锁先判断一下,不能随便加锁,否则会影响多线程执行的效率
with condition:
if len(items) == 0: # 二次判断,防止资源竞争判断不对
print("Consumer wait : no item to consume")
condition.notify() # 先唤醒其他的线程,其实就是通知生产者准备生产了
condition.wait() # 然后把自己挂起来,就是休息,如果他被唤醒的话,代码将会从这儿继续执行。
items.pop()
print("Consumer notify : consumed 1 item items to consume are " + str(len(items)))
def run(self):
for i in range(0, 20):
time.sleep(2)
self.consume()
class Producer(Thread):
def __init__(self):
Thread.__init__(self)
def produce(self):
global condition
global items
if len(items) == 10:
with condition:
if len(items) == 10:
print("Producer wait : stop the production!!")
condition.notify()
condition.wait()
items.append(1)
print("Producer notify : total items producted " + str(len(items)))
def run(self):
for i in range(0, 20):
time.sleep(1)
self.produce()
if __name__ == "__main__":
producer = Producer()
consumer = Consumer()
producer.start()
consumer.start()
producer.join()
consumer.join()

只要队列为空,就应该先唤醒生产者,然后自己挂起来,等待被唤醒。其他情况下就应该不断的消费。

只要商品队列满了,就应该唤醒消费者,自己沉睡。其他情况应该源源不断的生产。
但是上面这个案例有一点点不太好的地方。我们假设生产者生产过快,先填满了队列,然后挂起来了,只有等消费者将队列消费空了,才会将之唤醒,自己挂起来。消费者将之唤醒的时候,自己反而空了,等待生产者填满队列才会继续执行。也就是说,他会渐渐变成了单线程的模式。
改进:
- 生产者在生产的时候,假定每生产5次,尝试获取一次锁,从而唤醒消费者。在整个程序生产结束的时候再尝试一次,防止漏消费。
- 消费者在消费的时候,假定每消费5次,尝试获取一次锁,从而唤醒生产者。当消费线程被唤醒的时候,需要判断一次是否为空,如果为空,说明生产者已经不继续消费了。
源码
初始化函数
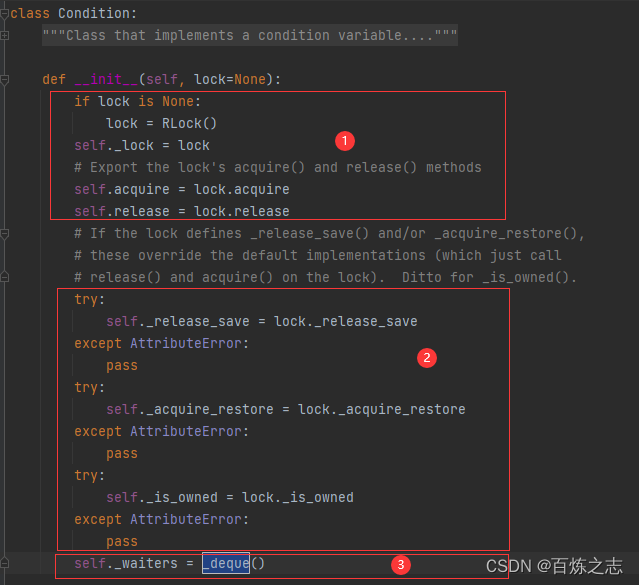
这个初始化函数可坑死我了,刚开始没看清楚,wait 方法怎么都读不懂
【1】填充内部锁对象,如果不传递的话,默认是可重入锁;将底层的上锁,释放锁方法绑定到 Condition 上。
【2】覆盖三个方法,如果底层锁对象有这三个方法,则 Condition 的这三个方法与底层的锁对象的同名方法绑定,否则他们指向的就是 Condition 自己的这三个方法,下面 Condition 也是定义了这三个方法的。也不知道作者是怎么考虑的。
【3】保存了休眠的线程,默认是个队列,也就是说先休眠的先被唤醒
wait
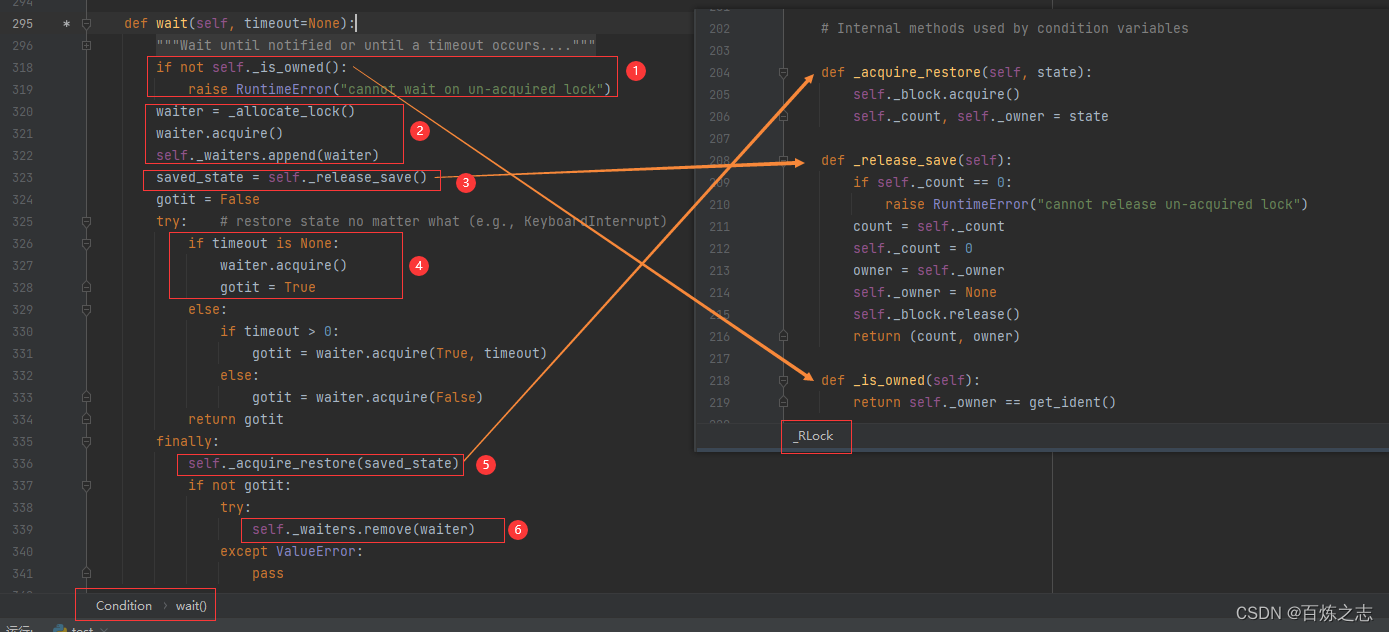
【1】线程判断这个锁是否已经被占用,其实调用的是底层的可重入锁的同名方法,如果不是当前线程拥有该锁,那么就会报错,也就是说,只有使用 Condition 加锁的线程才能执行 await 方法
【2】生成一个锁对象,使用它上锁,并且将他放入等待池中
【3】在这一步,释放了 Condition ,如果是可重入锁,不管重入多少层,统统修改为没有被线程抢占的状态,并且返回了当时重入状态,方便该线程到时候抢占到锁的时候可以恢复到之前的状态。
【4】我们所有的案例都是无 timeout 的,这里使用之前刚刚创建的锁 waiter,再次尝试加锁,注意,这个 waiter 可是普通的锁,而非可重入锁,也就是说在这里,这个线程把自己卡住了。就是在这里完成了休眠,除非其他的线程拿到这个 waiter,释放了他,这个线程才有可能继续走下去。
【5】我们假设当前线程又拿到了 Condition,就是在这里恢复可重入锁的上锁数据的。
【6】将之前创建的 waiter 移除。
notify
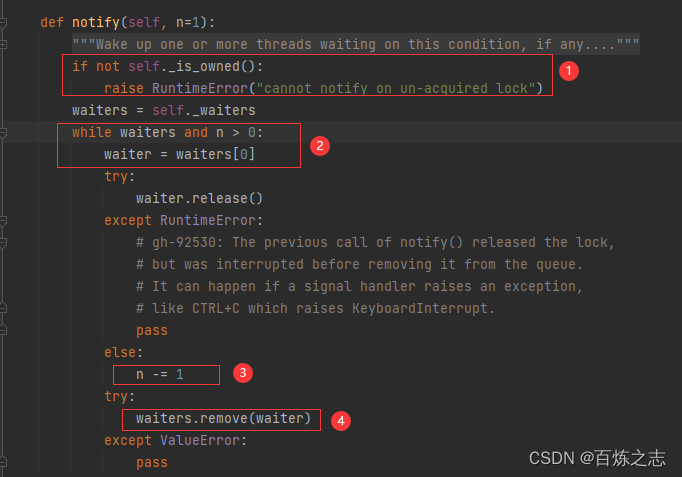
【1】判断先前线程是否为 Condition 的拥有者
【2】循环取出队列中用来阻塞的 waiter
【3】将 waiter 释放,释放之后,之前用 waiter 卡住自己的线程就可以继续执行下去了,这就是所谓的唤醒。
【4】这里尝试移除这个 waiter。
总结
Condition 通过创建一个临时的 waiter,然后两次上锁,卡主自己,实现线程休眠。一直到别的线程释放了这个锁,这个线程才能继续走下去,这就是所谓的唤醒。
Semaphore
信号量
Lock 锁保证了同时只有一个人可以访问特定的资源,但是 Semaphore 信号量保证了同一时间最多有多少个线程访问特定的资源。
他是怎么实现的?看源码
acquire
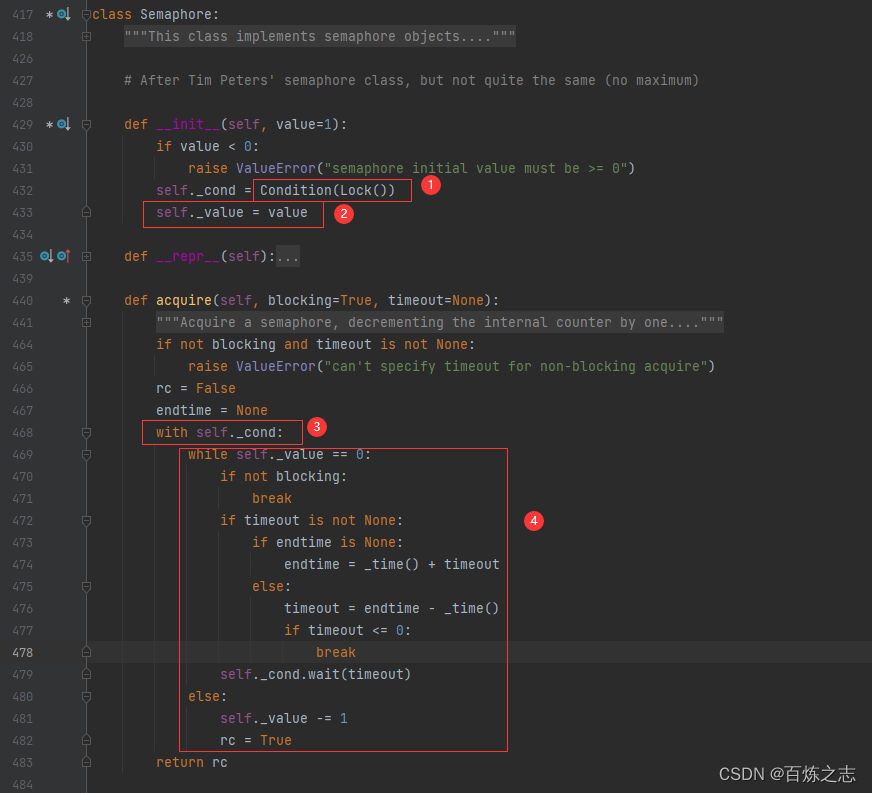
【1】注意,这里传递的是 Lock,也就是说,信号量是不支持可重入锁,使用的是原生的 Lock
【2】保存了传递一个数值
【3】这里是尝试获取一个锁,假如获取不到锁就会卡住,如果是非阻塞的,获取不到就直接返回了 False。
【4】假如说当前线程获取到了锁,就会进入这个循环。如果说 value 等于 0,当前线程就会进入循环等待,为什么使用循环等待呢?这里是怕别的线程不小心激活了当前线程,但是因为 value 依然为 0,也就是说允许访问的线程数量已经满了,还是需要等待。假如说 value 大于 0 ,那么就将 value 减小 1,同时返回 True,这个时候表示允许访问的线程数量增加了一个,剩余的数量减小了一个。
release

尝试唤醒当前沉睡的线程。
总结
Semaphore 信号量只是对 Condition 条件的一种运用而已。
总结
Lock,RLock,Condition,Semaphore 估计小伙伴们都已经有点蒙蔽了,实际上,这四个东西有点费脑子,需要多次使用,仔细感悟代码的精妙,这里对他们之间的关系做个总结和梳理。大家带着这些梳理,可以更高的吃透上面的源码,以及他们的用法。
锁是为了解决资源竞争。
- Lock,原生锁,最底层的锁,他可以卡住代码,被他卡住的代码,同一时间只有一个线程可以执行。
- RLock,可重入锁,对 Lock 进行了封装,实现了可重入,本质还是 Lock。
- Condition,条件,可以当锁来用,但他远不是锁这么简单,他利用锁实现了线程的休眠和唤醒。 线程在哪里卡住的,在 wait 方法内部卡住的。
- Semaphore,信号量,他不是锁,不能当锁用,他利用 Condition 实现了资源的竞争程度,同一时刻限定操作资源的线程数。底层是用的是 原生锁,而非可重入锁。他用原生锁锁的是自己的代码,从而控制并发量。















 131
131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









