







multiprocessing
multiprocessing 是一个支持使用与 threading 模块类似的 API 来产生进程的包。 multiprocessing 包同时提供了本地和远程并发操作,通过使用子进程而非线程有效地绕过了 全局解释器锁。 因此,multiprocessing 模块允许程序员充分利用给定机器上的多个处理器。 它在 Unix 和 Windows 上均可运行。
multiprocessing 模块还引入了在 threading 模块中没有的API。一个主要的例子就是 Pool 对象,它提供了一种快捷的方法,赋予函数并行化处理一系列输入值的能力,可以将输入数据分配给不同进程处理(数据并行)。下面的例子演示了在模块中定义此类函数的常见做法,以便子进程可以成功导入该模块。这个数据并行的基本例子使用了 Pool ,
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))
将在标准输出中打印
[1, 4, 9]
三种启动方式
下面是python多进程官网文档的翻译

fork 启动
原文的意思可能比较难以理解,我翻译一下。fork方式启动一个子进程,子进程里面的所有资源都是从主进程拷贝了一份,然后子进程执行具体的函数的时候,就会直接使用原主进程有的资源,比如说一些变量。

【1】子进程可以使用在子进程启动之前已经加载进内存的变量
【2】子进程无法使用子进程启动之后加载的变量
【3】子进程的父进程ID和主进程的ID一样
【4】子进程和父进程的模块名一样,都是__main__, 因为这个是子进程继承自父进程的变量数据
【5】父进程的父进程ID是 python解释器的进程ID
一般说来,fork 启动方式是最快的,因为他所需的所有数据都是内存拷贝,但是很明显,某些情况下,他是最消耗内存的,比如有个项目已经运行了很久了,有很多对象,但是他们不是 子进程计算中的必须对象,会造成一定的内存占用。另外就是 fork 模式下是不安全的,比如子进程会用到某个父进程中定义的变量或者对象,后来在真正使用的时候可能已经被修改了。
spawn 启动
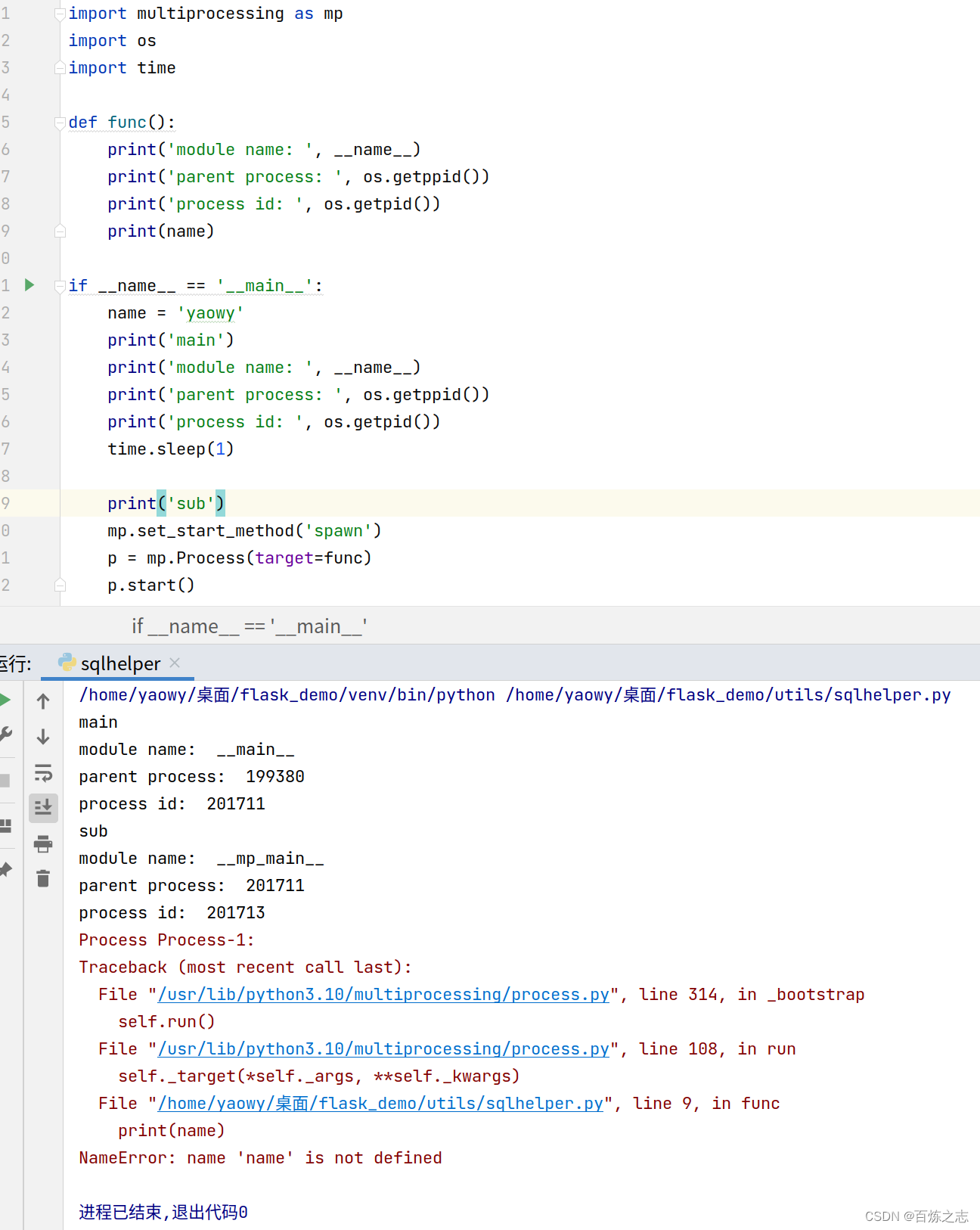
【1】子进程的父进程ID就是主进程的ID
【2】子进程的模块名和主进程的模块名不一样
【3】子进程无法使用父进程的变量
这个启动方式最大的缺点就是慢,他要用到的一些包,在进程启动之时都要再加载一遍,这是IO操作,非常耗时。
forkserver 启动
forkserver 模式是 fork 模式和 spawn 模式的结合体,主进程会先新启一个服务器进程,这个服务器进程再去以 fork 的方式启动一个新的进程,主进程负责与服务器进程打交道,服务器进程完成进程管理。

【1】主进程并不是子进程的父进程
【2】两个子进程的父进程是同一个
【3】子进程并不能使用主进程的变量
【4】子进程的模块名已经发生了变化
所以 forkserver 启动方式是一种中和的。假如说该方式只启动了一个进程,那他和 spawn 是没有区别的,他也需要重新加载包,但是后续进程多了之后,他每次都直接从 进程服务器中拷贝就完事了,速度就跟上来了。主进程启动进程服务器的时候不能传递主进程的变量,也就保证了进程安全。
下面对三种的优劣做个比较,在使用过程中如何选择,都是个人的一些浅见
【1】如果多进程需要处理的任务比较简单,使用 fork 模式最好,因为代码简单,进程启动也快,其余两种模式都需要在执行代码里特意导包等
【2】如果多进程需要执行的代码耗时比较久,需要开启的进程比较多,使用 forkserver 模式最佳,省内存
Process
下面是一个 多进程的简单案例。
from multiprocessing import Process
def f(name):
print('hello', name)
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()
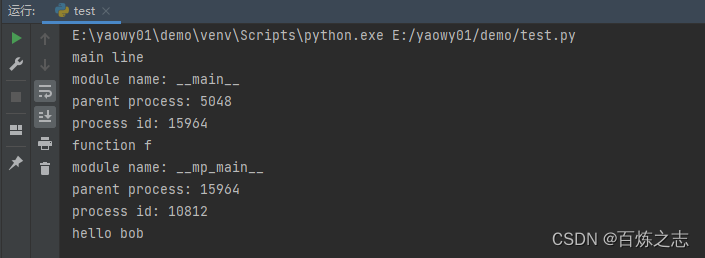
要显示所涉及的各个进程ID,这是一个扩展示例:
from multiprocessing import Process
import os
def info(title):
print(title)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
def f(name):
info('function f')
print('hello', name)
if __name__ == '__main__':
info('main line')
p = Process(target=f, args=('bob',))
p.start()
p.join()
进程通信
队列
Queue 类是一个近似 queue.Queue 的克隆。 例如:
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()
队列是线程和进程安全的。
管道
Pipe() 函数返回一个由管道连接的连接对象,默认情况下是双工(双向)。例如:
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()
返回的两个连接对象 Pipe() 表示管道的两端。每个连接对象都有 send() 和 recv() 方法(相互之间的)。请注意,如果两个进程(或线程)同时尝试读取或写入管道的 同一 端,则管道中的数据可能会损坏。当然,在不同进程中同时使用管道的不同端的情况下不存在损坏的风险。
同步
multiprocessing 包含来自 threading 的所有同步原语的等价物。例如,可以使用锁来确保一次只有一个进程打印到标准输出:
from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()
不使用锁的情况下,来自于多进程的输出很容易产生混淆。[这个应该很有体会吧]
共享
如上所述,在进行并发编程时,通常最好尽量避免使用共享状态。使用多个进程时尤其如此。
但是,如果你真的需要使用一些共享数据,那么 multiprocessing 提供了两种方法。
内存共享
可以使用 Value 或 Array 将数据存储在共享内存映射中。例如,以下代码:
from multiprocessing import Process, Value, Array
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target=f, args=(num, arr))
p.start()
p.join()
print(num.value)
print(arr[:])

创建 num 和 arr 时使用的 ‘d’ 和 ‘i’ 参数是 array 模块使用的类型的 typecode : ‘d’ 表示双精度浮点数, ‘i’ 表示有符号整数。这些共享对象将是进程和线程安全的。
因为这里的共享内存使用 C 语言实现的,C语言是强类型的语言,尤其是数组,每一个元素必须是同一种类型,因此这列创建的时候必须指定数据类型。
为了更灵活地使用共享内存,可以使用 multiprocessing.sharedctypes 模块,该模块支持创建从共享内存分配的任意ctypes对象。
服务进程共享
由 Manager() 返回的管理器对象控制一个服务进程,该进程保存Python对象并允许其他进程使用代理操作它们。
Manager() 返回的管理器支持类型: list 、 dict 、 Namespace 、 Lock 、 RLock 、 Semaphore 、 BoundedSemaphore 、 Condition 、 Event 、 Barrier 、 Queue 、 Value 和 Array 。例如:
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)

使用服务进程的管理器比使用共享内存对象更灵活,因为它们可以支持任意对象类型。此外,单个管理器可以通过网络由不同计算机上的进程共享。但是,它们比使用共享内存慢。
进程池

- processes 是要使用的工作进程数目。如果 processes 为 None,则使用 os.cpu_count() 返回的值。

- 如果 initializer 不为 None,则每个工作进程将会在启动时调用 initializer(*initargs)。这个偏底层了,找不到源码,只能用代码验证。
from multiprocessing import Pool
class Data(object):
def __init__(self, a):
self.a = a
print(a)
def print_func(x):
print(x)
if __name__ == '__main__':
with Pool(processes=4, initializer=Data, initargs=('a',)) as pool:
pool.map(print_func, [1, 2, 3, 4])

整个进程池生命周期内,initializer 就用到了一次,也不知道干啥用的,我调试的时候看了下,初始化调用的地方太深太底层了,不好描述。跳过!
- context 可被用于指定启动的工作进程的上下文,没用过。
from multiprocessing import Pool
import time
def f(x):
return x*x
if __name__ == '__main__':
with Pool(processes=4) as pool: # start 4 worker processes
result = pool.apply_async(f, (10,)) # evaluate "f(10)" asynchronously in a single process
print(result.get(timeout=1)) # prints "100" unless your computer is *very* slow
print(pool.map(f, range(10))) # prints "[0, 1, 4,..., 81]"
it = pool.imap(f, range(10))
print(next(it)) # prints "0"
print(next(it)) # prints "1"
print(it.next(timeout=1)) # prints "4" unless your computer is *very* slow
result = pool.apply_async(time.sleep, (10,))
print(result.get(timeout=1)) # raises multiprocessing.TimeoutError

一定要自己跑一遍代码。
Python多进程的使用就到这里。















 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









