






任务
判别网络数据包中是否存在攻击以及验证模型的准确性。
简介
采用支持向量机(SVM)算法创建和设计入侵检测系统:
- 能够区分是攻击报文还是正常报文
- 应用不同核函数(Gassuian, RBF, Linear, polynomial)训练SVM模型,并对比不同核函数下模型的表现
- 应用Grid-search VS Random技术选择参数并比较两种结果
导入常用的机器学习和数据处理库
import numpy as np # 用于科学计算的高效数组操作库
import pandas as pd # 用于数据处理和分析的库,提供数据框结构
import matplotlib.pyplot as plt # 用于数据可视化的基本绘图库
import seaborn as sns # 基于matplotlib的高级数据可视化库
import warnings # 用于处理警告的库
import statsmodels.api as sm # 提供统计模型和经济计量学工具的库
from sklearn.preprocessing import LabelEncoder # 用于将类别型标签转换为数值的编码器
from sklearn.preprocessing import RobustScaler # 用于数据标准化的鲁棒缩放器
from sklearn.model_selection import train_test_split, GridSearchCV # 用于数据集划分和参数网格搜索的工具
from sklearn.decomposition import PCA # 用于主成分分析的库
from sklearn.linear_model import LogisticRegression # 逻辑回归模型
from sklearn.neighbors import KNeighborsClassifier # k近邻分类器
from sklearn.tree import DecisionTreeClassifier # 决策树分类器
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn import tree # 用于绘制决策树的库
from sklearn import svm # 支持向量机库
from sklearn.svm import SVC # 支持向量机分类器
from sklearn.naive_bayes import GaussianNB # 朴素贝叶斯分类器
from sklearn import metrics # 用于模型评估的库
from sklearn.metrics import confusion_matrix # 用于计算混淆矩阵的工具
from sklearn.metrics import plot_roc_curve # 用于绘制ROC曲线的工具
from mlxtend.plotting import plot_confusion_matrix # 用于绘制混淆矩阵的工具
# 设置警告信息忽略
warnings.filterwarnings(action='ignore')
# 设置matplotlib inline,使得在Jupyter Notebook中直接显示图像
%matplotlib inline
读取数据
Columns = (['duration','protocol_type','service','flag','src_bytes','dst_bytes','land','wrong_fragment','urgent','hot',
'num_failed_logins','logged_in','num_compromised','root_shell','su_attempted','num_root','num_file_creations',
'num_shells','num_access_files','num_outbound_cmds','is_host_login','is_guest_login','count','srv_count',
'serror_rate','srv_serror_rate','rerror_rate','srv_rerror_rate','same_srv_rate','diff_srv_rate','srv_diff_host_rate',
'dst_host_count','dst_host_srv_count','dst_host_same_srv_rate','dst_host_diff_srv_rate','dst_host_same_src_port_rate',
'dst_host_srv_diff_host_rate','dst_host_serror_rate','dst_host_srv_serror_rate','dst_host_rerror_rate',
'dst_host_srv_rerror_rate','attack','level'])
定义一个元组Columns,包含了一系列的字段名称,这些字段主要用于描述网络活动的数据特征。
# 读取训练集数据
Trained_Data = pd.read_csv("../input/nslkdd/KDDTrain+.txt" , sep = ",", names=Columns, encoding = 'utf-8')
# 读取测试集数据
Tested_Data = pd.read_csv("../input/nslkdd/KDDTest+.txt" , sep = ",",names=Columns , encoding = 'utf-8')
数据展示
训练集
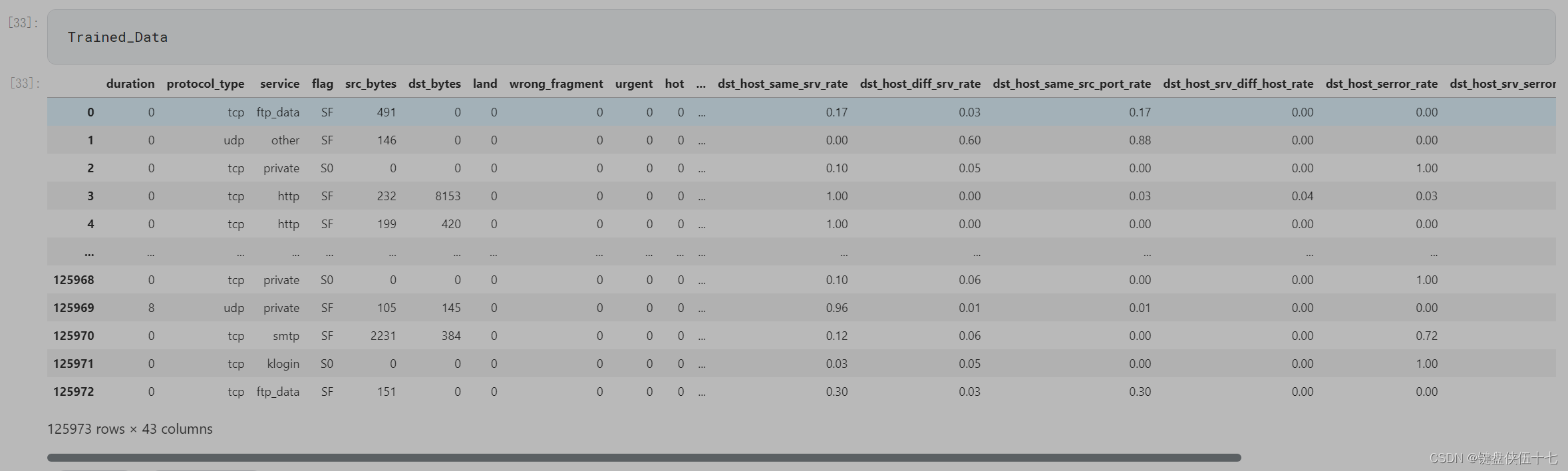

测试集
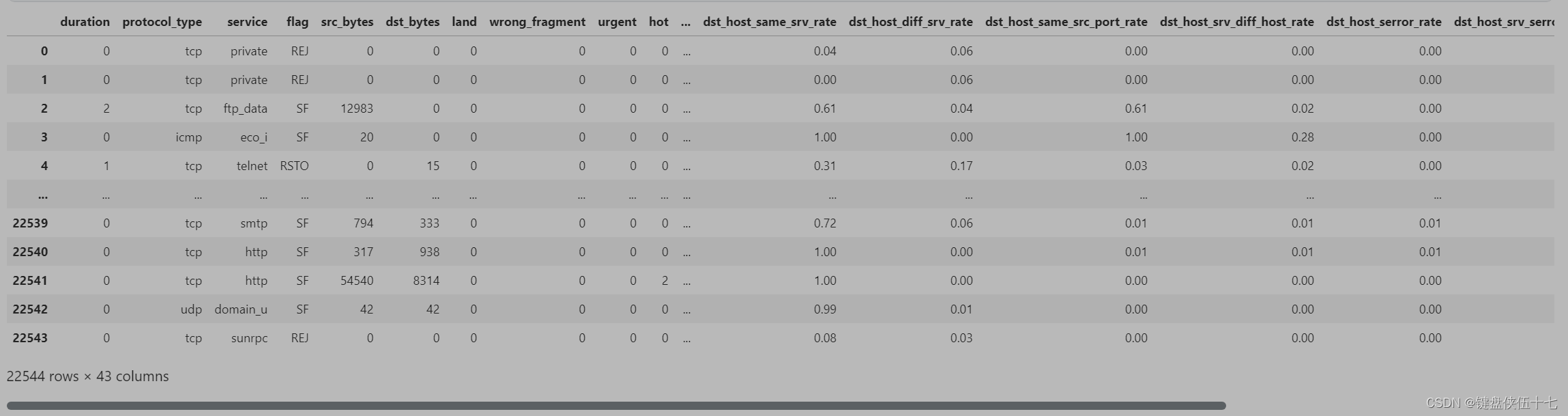

探索响应
# 从训练数据中提取攻击类型的值并去重
Results = set(Trained_Data['attack'].values)
# 打印结果,不换行
print(Results,end=" ")

攻击结果分类并标记
将训练数据和测试数据中的攻击状态转换为二进制形式
具体来说,将正常的攻击标记为0,非正常的攻击标记为1
参数:
- Trained_Data: 训练数据集,包含攻击信息的DataFrame
- Tested_Data: 测试数据集,包含攻击信息的DataFrame
返回值:无
Trained_attack = Trained_Data.attack.map(lambda a: 0 if a == 'normal' else 1)
Tested_attack = Tested_Data.attack.map(lambda a: 0 if a == 'normal' else 1)
# 将处理后的攻击状态添加到相应的数据集中
Trained_Data['attack_state'] = Trained_attack
Tested_Data['attack_state'] = Tested_attack
对数据进行标签编码
Trained_Data = pd.get_dummies(Trained_Data,columns=[‘protocol_type’,‘service’,‘flag’],prefix=“”,prefix_sep=“”)
使用pandas的get_dummies函数对数据进行one-hot编码
参数:
- Trained_Data: 需要进行one-hot编码的数据集,必须是pandas的DataFrame类型
- columns: 指定需要进行one-hot编码的列名列表
- prefix: 为生成的虚拟变量添加的前缀
- prefix_sep: 当使用连接多个前缀时,用作分隔符
返回值:
- 经过one-hot编码处理后的数据集
Tested_Data = pd.get_dummies(Tested_Data,columns=['protocol_type','service','flag'],prefix="",prefix_sep="")
# 初始化标签编码器
LE = LabelEncoder()
attack_LE = LabelEncoder()
# 对训练数据集中的攻击类型进行标签编码
Trained_Data['attack'] = attack_LE.fit_transform(Trained_Data["attack"])
# 对测试数据集中的攻击类型进行相同的标签编码,确保编码的一致性
Tested_Data['attack'] = attack_LE.fit_transform(Tested_Data["attack"])
标签编码器的使用是为了将分类变量转化为数值变量,以便于机模型的处理。
分割数据
# 准备训练数据和测试数据
# 从训练数据中移除不需要的列:'attack', 'level', 'attack_state'
# 从测试数据中移除不需要的列:'attack', 'level', 'attack_state'
X_train = Trained_Data.drop('attack', axis = 1)
X_train = Trained_Data.drop('level', axis = 1)
X_train = Trained_Data.drop('attack_state', axis = 1)
X_test = Tested_Data.drop('attack', axis = 1)
X_test = Tested_Data.drop('level', axis = 1)
X_test = Tested_Data.drop('attack_state', axis = 1)
# 提取标签数据
# 从训练数据中提取标签列 'attack_state'
Y_train = Trained_Data['attack_state']
# 从测试数据中提取标签列 'attack_state'
Y_test = Tested_Data['attack_state']
X_train_train,X_test_train ,Y_train_train,Y_test_train = train_test_split(X_train, Y_train, test_size= 0.25 , random_state=42)
# 对测试集进行内部验证集的划分,以用于最终模型性能的评估
# 此步骤与上述训练集的划分相似,不过是针对测试集进行的
# 参数及返回值说明同上
X_train_test,X_test_test,Y_train_test,Y_test_test = train_test_split(X_test, Y_test, test_size= 0.25 , random_state=42)
对训练集和测试集进行进一步的划分,以用于验证和测试模型
train_test_split函数用于将原始训练集X_train和标签Y_train分为训练子集和验证子集
参数:
- X_train: 原始训练集的特征部分
- Y_train: 原始训练集的标签部分
- test_size: 验证子集所占比例,此处为0.25,即验证集占总数据集的25%
- random_state: 随机种子,用于确保结果的可复现性
返回值:
- X_train_train: 训练集的特征部分
- X_test_train: 验证集的特征部分
- Y_train_train: 训练集的标签部分
- Y_test_train: 验证集的标签部分
数据缩放
# 初始化RobustScaler对象,用于数据的鲁棒性标准化处理
Ro_scaler = RobustScaler()
# 对训练集的训练部分进行鲁棒性标准化处理
X_train_train = Ro_scaler.fit_transform(X_train_train)
# 对测试集的训练部分进行相同的鲁棒性标准化处理
X_test_train= Ro_scaler.transform(X_test_train)
# 对训练集的测试部分进行鲁棒性标准化处理
X_train_test = Ro_scaler.fit_transform(X_train_test)
# 对测试集的测试部分进行相同的鲁棒性标准化处理
X_test_test= Ro_scaler.transform(X_test_test)
这段代码的主要目的是使用RobustScaler对象对数据集的不同部分进行鲁棒性标准化处理。
该处理旨在减少数据中异常值的影响,使数据更加稳健。
首先,初始化一个RobustScaler对象。
接着,分别对训练集的训练部分、测试集的训练部分、训练集的测试部分以及测试集的测试部分应用这个标准化处理。
通过这种方式,确保了处理的一致性和数据集之间的可比性。
处理训练数据
VIF
VIF,全称为Variance Inflation Factor(方差膨胀因子),是统计学中衡量多重共线性问题严重程度的一个指标。在回归分析中,当模型中的自变量之间存在高度相关性时,即出现多重共线性问题,这可能会导致模型参数的估计不准确和预测能力下降。
VIF值计算公式通常基于回归模型中某个自变量与其余所有自变量之间的相关系数。VIF值越大,说明该自变量与其他自变量的相关性越强,共线性问题越严重。一般认为:
VIF值<10:表示各变量间不存在严重的多重共线性。
10≤VIF值<100:表示存在一定程度的多重共线性,需要关注。
VIF值≥100:则强烈提示存在多重共线性问题,此时应考虑对模型进行修正,比如剔除部分变量或者通过其他方式降低共线性。
因此,在构建回归模型时,我们通常会计算各个自变量的VIF值,并根据其大小来评估和处理多重共线性问题。
# 向特征矩阵中添加常数项,以便于模型中包含截距项
A = sm.add_constant(X_train)
# 创建GLM模型,将标签变量和包含常数项的特征变量作为输入
Est1 = sm.GLM(Y_train, A)
# 拟合模型
Est2 = Est1.fit()
# 输出模型的统计摘要
Est2.summary()
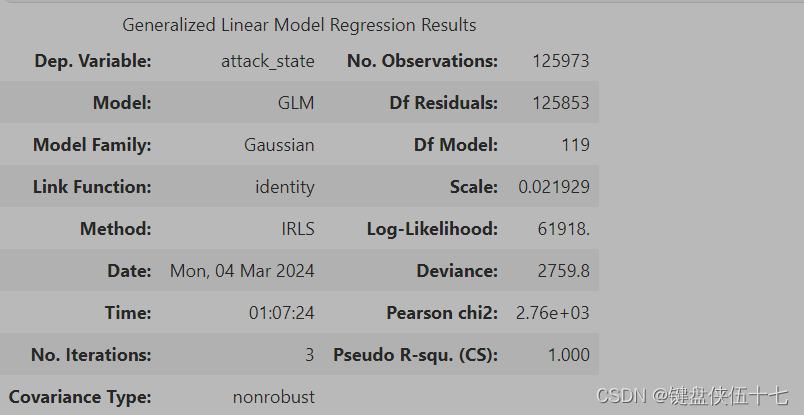
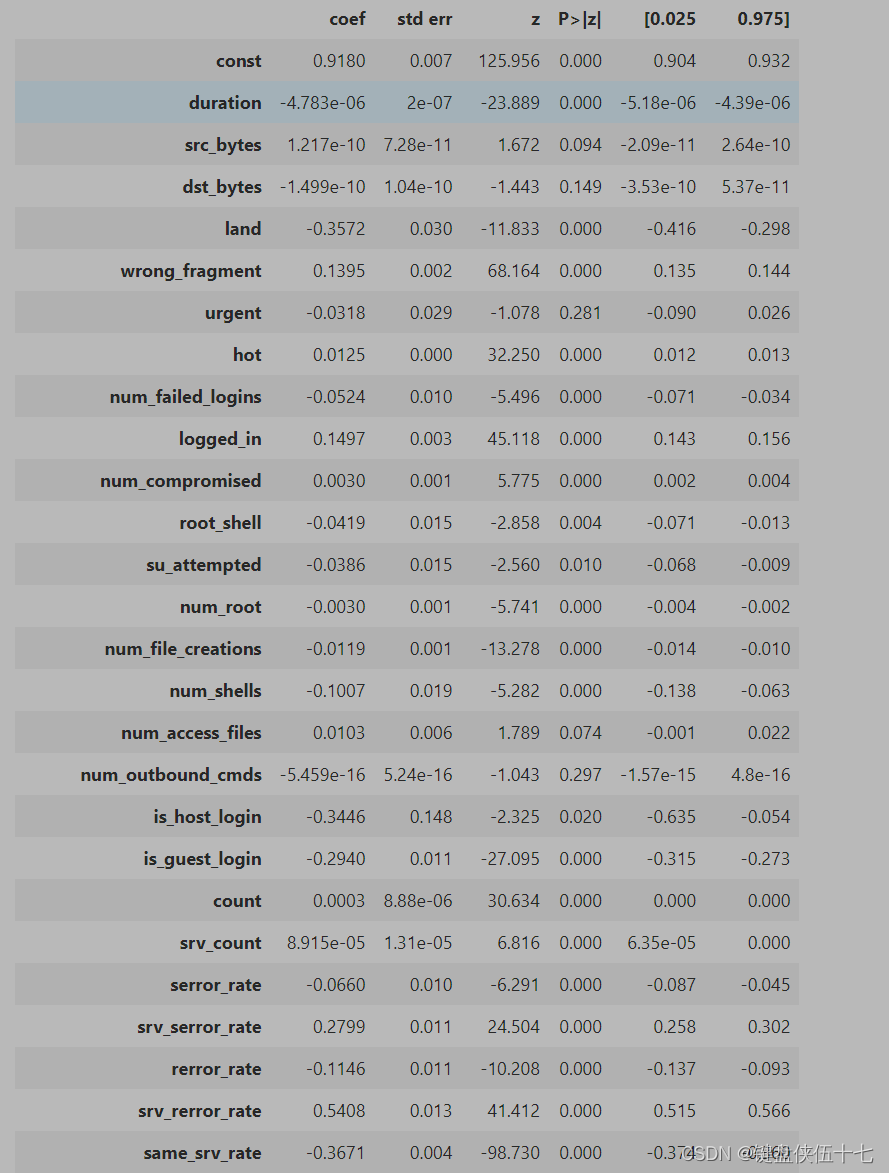
该代码块实现了使用广义线性模型(GLM)对训练数据进行拟合并生成拟合结果的概述。
参数:
- Y_train: 标签数据集,训练集中的目标变量。
- X_train: 特征数据集,训练集中的特征变量。
返回值:
- 无。该代码块不直接返回任何值,但输出拟合模型的详细统计摘要。
数据建模
评估函数
def Evaluate(Model_Name, Model_Abb, X_test, Y_test):
# 使用模型对测试集进行预测
Pred_Value= Model_Abb.predict(X_test)
# 计算模型的性能指标
Accuracy = metrics.accuracy_score(Y_test,Pred_Value)
Sensitivity = metrics.recall_score(Y_test,Pred_Value)
Precision = metrics.precision_score(Y_test,Pred_Value)
F1_score = metrics.f1_score(Y_test,Pred_Value)
Recall = metrics.recall_score(Y_test,Pred_Value)
# 打印模型的性能报告
print('--------------------------------------------------\n')
print('The {} Model Accuracy = {}\n'.format(Model_Name, np.round(Accuracy,3)))
print('The {} Model Sensitvity = {}\n'.format(Model_Name, np.round(Sensitivity,3)))
print('The {} Model Precision = {}\n'.format(Model_Name, np.round(Precision,3)))
print('The {} Model F1 Score = {}\n'.format(Model_Name, np.round(F1_score,3)))
print('The {} Model Recall = {}\n'.format(Model_Name, np.round(Recall,3)))
print('--------------------------------------------------\n')
# 计算并绘制混淆矩阵
Confusion_Matrix = metrics.confusion_matrix(Y_test, Pred_Value)
plot_confusion_matrix(Confusion_Matrix,class_names=['Normal', 'Attack'],figsize=(5.55,5), colorbar= "blue")
# 绘制ROC曲线
plot_roc_curve(Model_Abb, X_test, Y_test)
评估给定模型的性能。
参数:
- Model_Name: 模型的名称,用于标识和打印报告。
- Model_Abb: 预测模型的实例,用于进行预测。
- X_test: 测试集的特征数据,用于模型的预测。
- Y_test: 测试集的真实标签,用于评估模型的性能。
无返回值,但会打印模型的准确性、敏感性、精确度、F1分数和召回率,以及混淆矩阵和ROC曲线。
网格搜索
def GridSearch(Model_Abb, Parameters, X_train, Y_train):
# 初始化网格搜索对象
Grid = GridSearchCV(estimator=Model_Abb, param_grid= Parameters, cv = 3, n_jobs=-1)
# 对训练数据进行拟合,寻找最佳超参数组合
Grid_Result = Grid.fit(X_train, Y_train)
# 获取具有最佳性能的模型实例
Model_Name = Grid_Result.best_estimator_
return (Model_Name)
使用网格搜索方法对模型参数进行优化选择。
参数:
- Model_Abb: 模型的别名或实例,用于进行网格搜索的模型。
- Parameters: 参数字典,包含需要搜索的超参数及其取值范围。
- X_train: 训练数据集的特征部分。
- Y_train: 训练数据集的目标变量。
返回:
- Model_Name: 优化后的模型实例,具有最佳的超参数组合。
逻辑回归
# 创建Logistic回归模型对象
LR= LogisticRegression()
# 使用训练集进行模型训练
LR.fit(X_train_train , Y_train_train)
LR.score(X_train_train, Y_train_train), LR.score(X_test_train, Y_test_train)
计算并返回训练集和测试集的评分
LR.score函数用于评估模型的性能,返回值为模型在指定数据集上的评分
参数:
X_train_train: 训练集的特征矩阵
Y_train_train: 训练集的目标值矩阵
X_test_train: 测试集的特征矩阵
Y_test_train: 测试集的目标值矩阵
返回值:
一个元组,包含训练集和测试集的评分

Evaluate('Logistic Regression', LR, X_test_train, Y_test_train)
评估给定模型在测试集上的表现。
参数:
- model_name: 字符串,表示模型的名称。
- model: 模型对象,待评估的模型。
- X_test_train: 数组,测试集的特征矩阵。
- Y_test_train: 数组,测试集的目标变量。
返回值:
- 无,直接打印模型的评估结果。
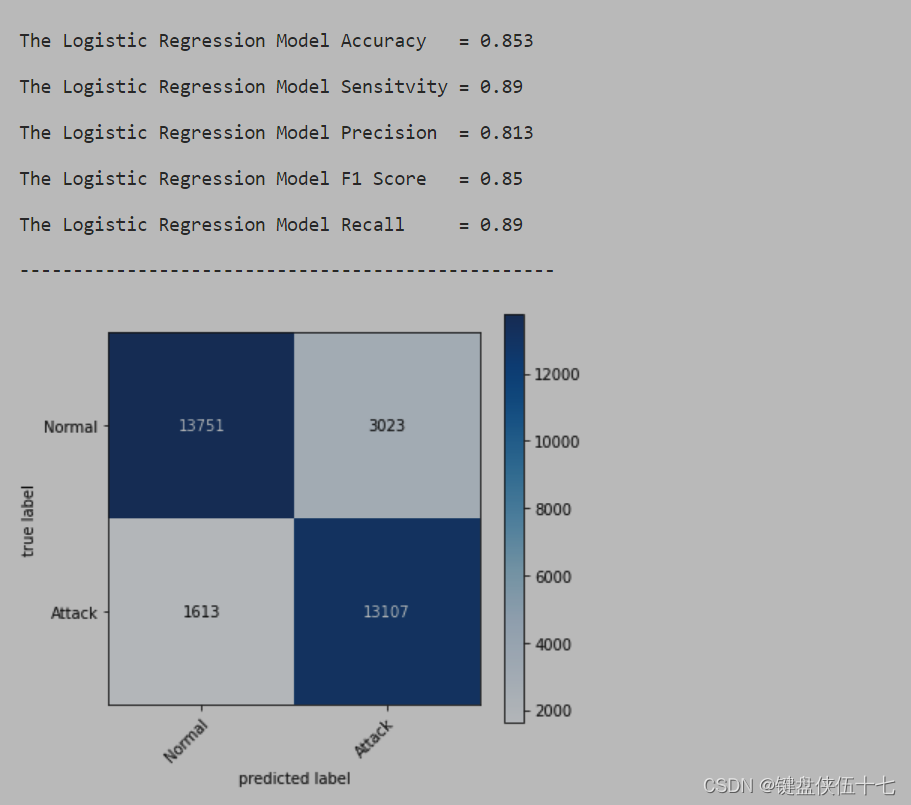
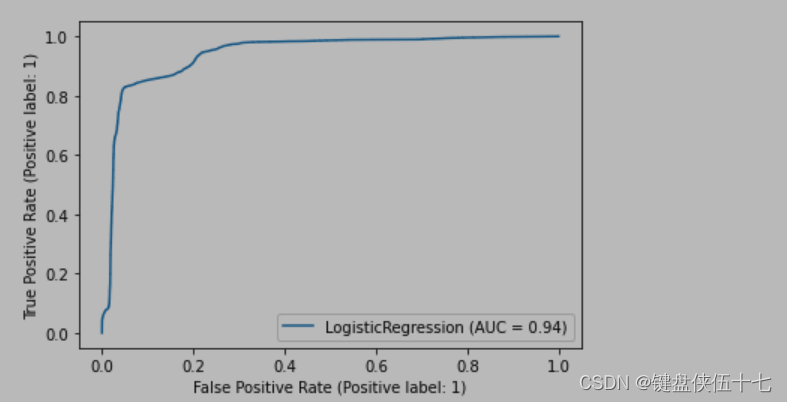
决策树分类器
# 创建决策树分类器对象
# max_features 设置在构建分割时考虑的最大特征数;max_depth 设置决策树的最大深度
DT = DecisionTreeClassifier(max_features=6, max_depth=4)
# 训练决策树模型
# X_train_train 是训练集的特征矩阵;Y_train_train 是训练集的目标变量
DT.fit(X_train_train, Y_train_train)
DT.score(X_train_train, Y_train_train), DT.score(X_test_train, Y_test_train)
计算决策树模型在训练集和测试集上的得分
参数说明:
- DT: 训练好的决策树模型
- X_train_train: 训练集的特征数据
- Y_train_train: 训练集的目标数据
- X_test_train: 测试集的特征数据
- Y_test_train: 测试集的目标数据
返回值说明:
- 返回一个元组,包含决策树模型在训练集和测试集上的得分

Evaluate('Decision Tree Classifier', DT, X_test_train, Y_test_train)
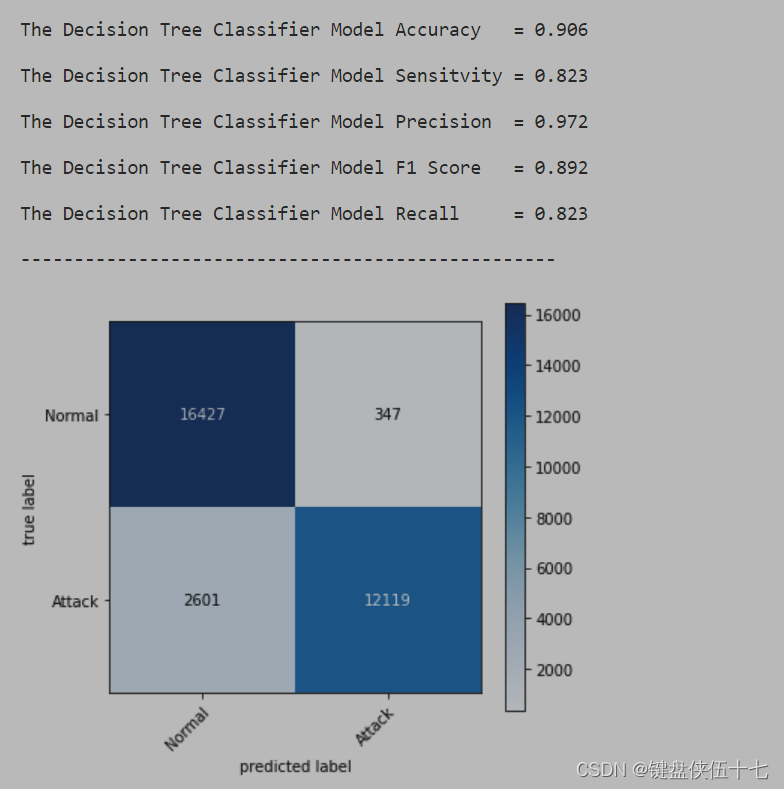

fig = plt.figure(figsize=(15,12))
tree.plot_tree(DT, filled=True)
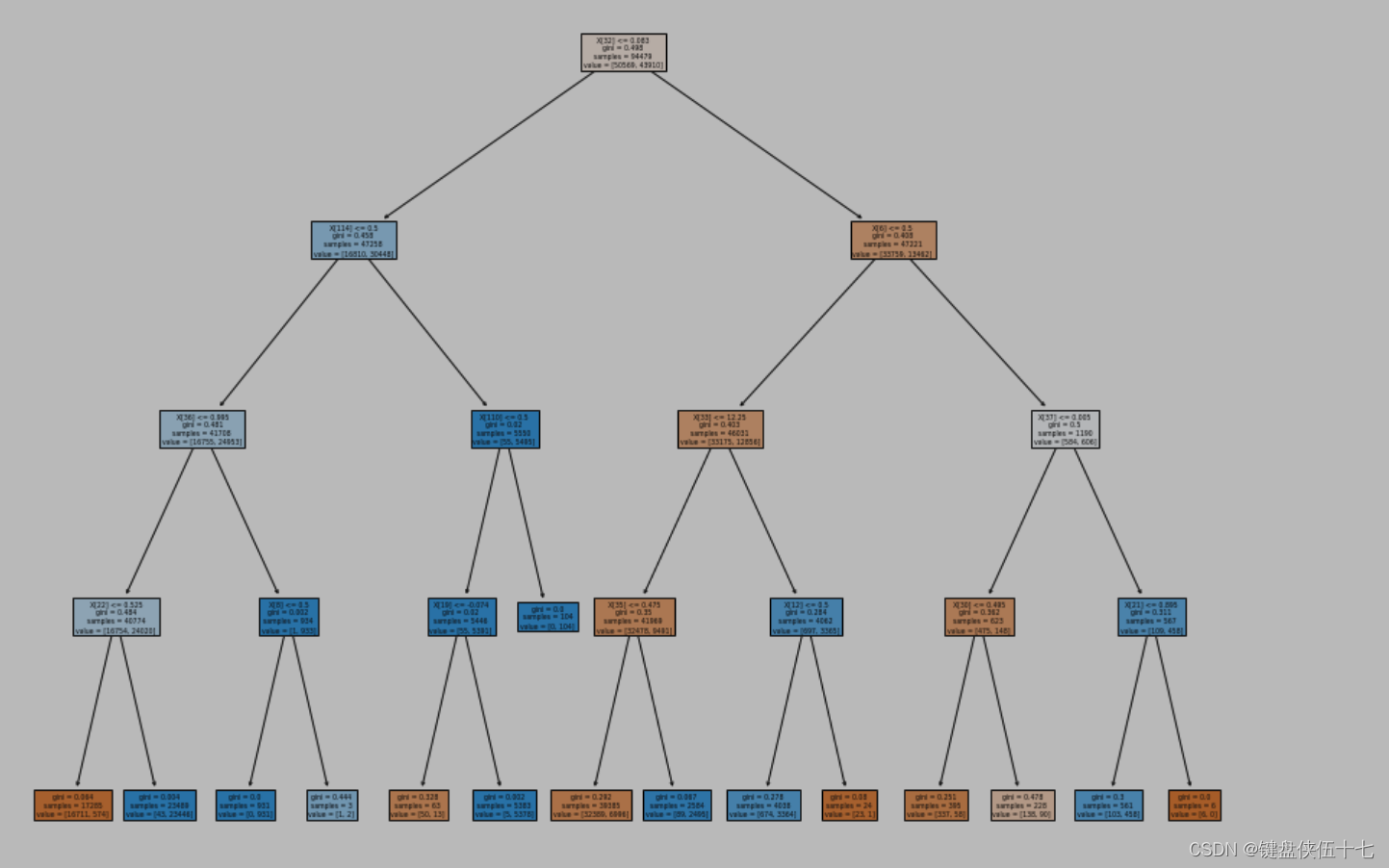
随机森林分类器
max_depth= [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
Parameters={ 'max_depth': max_depth}
# 初始化随机森林分类器
RF= RandomForestClassifier()
GridSearch(RF, Parameters, X_train_train, Y_train_train)
使用网格搜索优化随机森林分类器的参数
- GridSearch函数的参数说明:
- RF:已经初始化的随机森林分类器对象;
- Parameters:需要优化的参数集合,以字典形式提供;
- X_train_train:训练数据集的特征部分;
- Y_train_train:训练数据集的目标标签部分。
RF.fit(X_train_train, Y_train_train)
训练随机森林模型
参数:
- RF: 随机森林模型对象,已经初始化但尚未训练
- X_train_train: 训练集的特征矩阵,用于训练模型
- Y_train_train: 训练集的目标变量矩阵,对应于X_train_train的标签
返回值:
- 无,该方法会修改RF对象,将其训练成一个可以用于预测的模型
RF.score(X_train_train, Y_train_train), RF.score(X_test_train, Y_test_train)
计算并返回训练集和测试集的评分
- RF是已经训练好的随机森林模型
- X_train_train 是训练集的特征数据
- Y_train_train 是训练集的目标数据
- X_test_train 是测试集的特征数据
- Y_test_train 是测试集的目标数据
返回值
- 训练集和测试集的评分,分别为两个浮点数

Evaluate(‘Random Forest Classifier’, RF, X_test_train, Y_test_train)
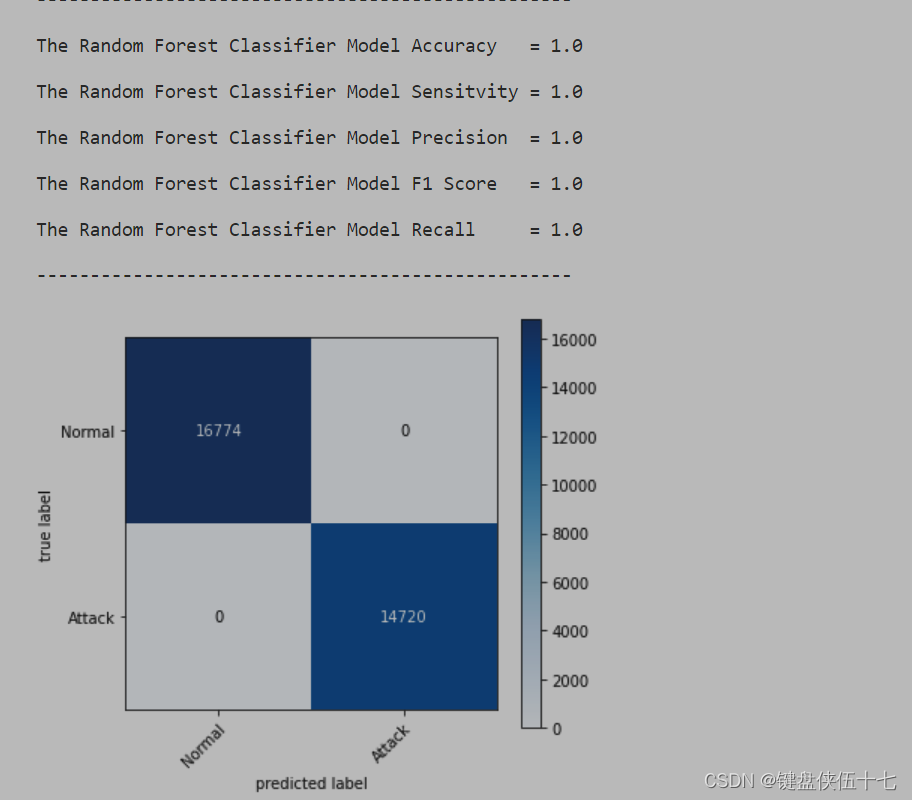

KNN-模型
# 初始化K近邻分类器
KNN= KNeighborsClassifier(n_neighbors=6)
# 这里设置了邻居的数量为6,即将用来投票决定分类的邻居数目。
# 训练K近邻分类器
KNN.fit(X_train_train, Y_train_train)
# 使用提供的训练集(X_train_train和Y_train_train)来拟合K近邻模型。
# 这一步会根据训练数据计算每个样本的邻居,以便之后进行预测。
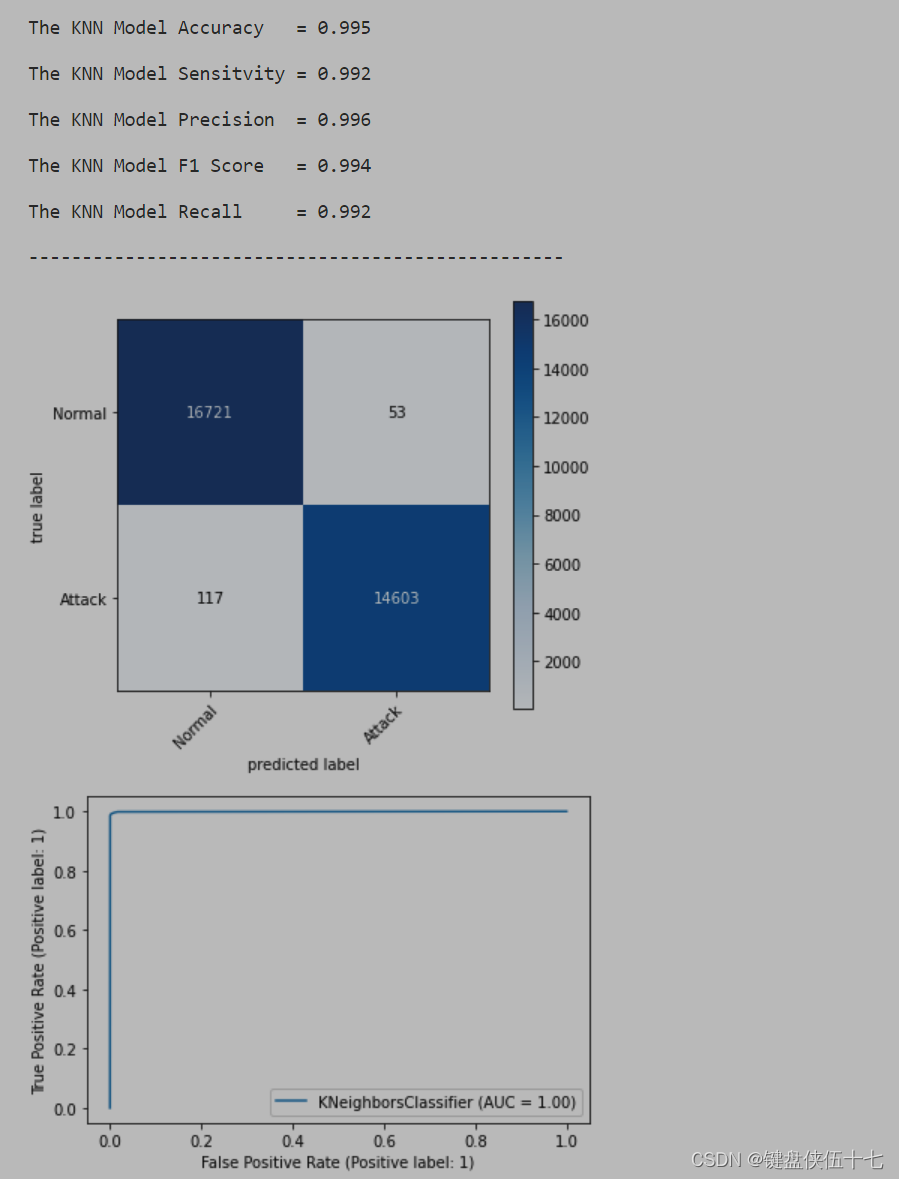
KNN.score(X_train_train, Y_train_train), KNN.score(X_test_train, Y_test_train)
计算并返回KNN模型在训练集和测试集上的得分
参数:
- X_train_train: 训练集的特征矩阵
- Y_train_train: 训练集的目标值矩阵
- X_test_train: 测试集的特征矩阵
- Y_test_train: 测试集的目标值矩阵
返回值:
- 一个元组,包含两个得分:第一个为训练集上的得分,第二个为测试集上的得分

Evaluate('KNN', KNN, X_test_train, Y_test_train)
支持向量机(SVM)分类器
1st Kernel
# 创建线性支持向量机分类器
# 参数C为正则化参数,用于控制误差项和边界的平衡,较小的C值将极度关注边界,较大的C值将极度关注误差项。
# 此处设定C=1为默认值,适用于大多数情况。
Linear_SVC = svm.LinearSVC(C=1)
# 训练分类器
# 使用X_train_train作为特征训练集,Y_train_train作为标签训练集来拟合Linear_SVC分类器。
# 这一步将根据训练数据调整分类器的参数,使其能够根据特征有效地预测标签。
Linear_SVC.fit(X_train_train, Y_train_train)
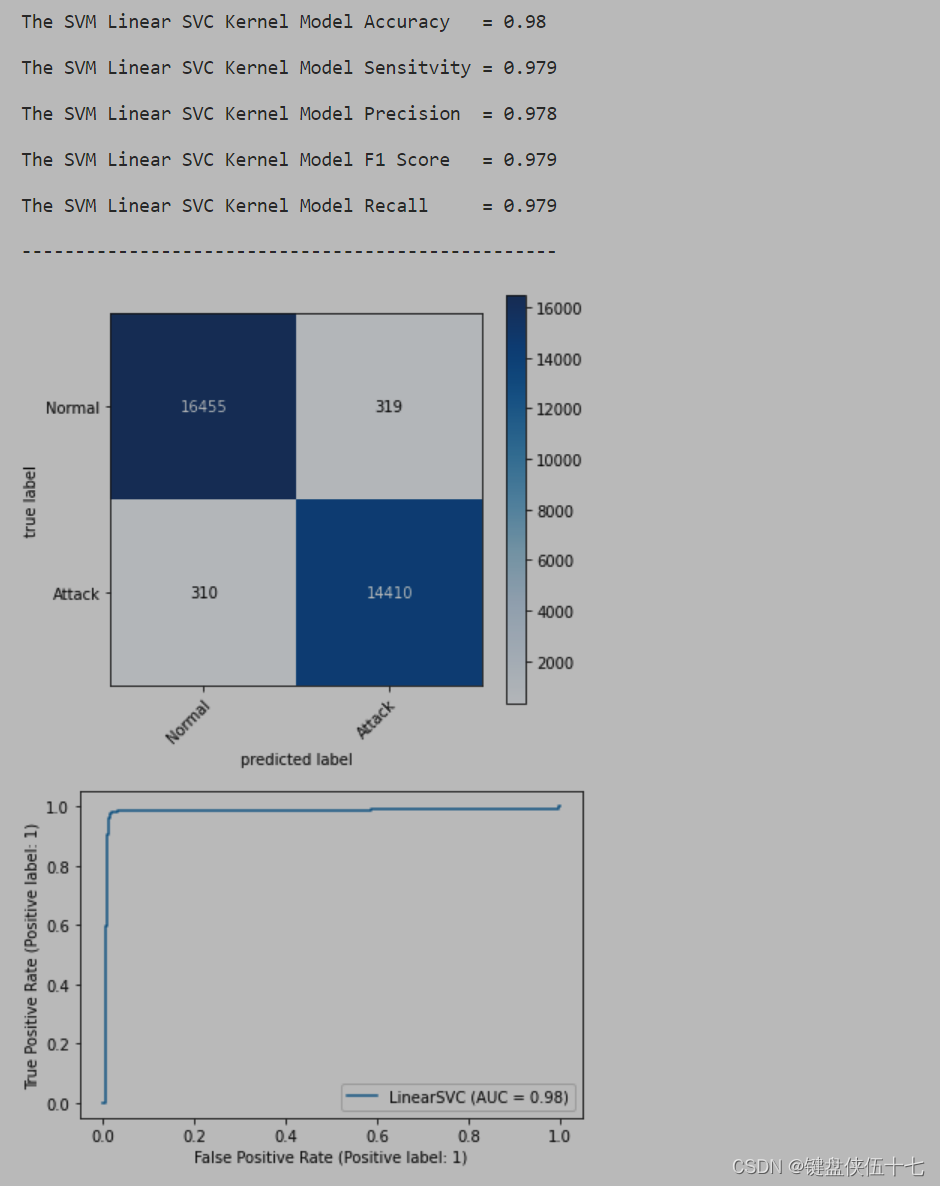
计算并返回线性支持向量机(Linear_SVC)在训练集和测试集上的得分
参数:
- X_train_train: 训练集的特征矩阵
- Y_train_train: 训练集的目标值矩阵
- X_test_train: 测试集的特征矩阵
- Y_test_train: 测试集的目标值矩阵
返回值:
- 一个元组,包含训练集和测试集的得分。得分是模型正确预测的比例。
Linear_SVC.score(X_train_train, Y_train_train), Linear_SVC.score(X_test_train, Y_test_train)


















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











