






P-GCN
之前一直在看G-TAD的论文和代码,突然发现实验结果的地方,加了P-GCN。P-GCN结果真的强。
代码地址:https://github.com/Alvin-Zeng/PGCN
论文下载链接:https://arxiv.org/pdf/1911.11462.pdf
参考:https://blog.csdn.net/qq_41590635/article/details/105053656
https://zhuanlan.zhihu.com/p/93530440
摘要部分
大多数最先进的动作本地化系统都单独处理每个动作建议,而在学习过程中没有明确利用它们之间的关系。但是,提案之间的关系实际上在动作本地化中起着重要作用,因为有意义的动作始终在视频中包含多个提案。在本文中,我们建议使用图卷积网络(GCN)开发提案-提案关系。首先,我们构造一个行动建议图,其中每个建议都表示为一个节点,而两个建议之间的关系则作为一个边。在这里,我们使用两种类型的关系,一种用于捕获每个建议的上下文信息,另一种用于表征不同动作之间的相关性。然后,我们在图形上应用GCN,以对不同建议之间的关系进行建模,并为动作分类和本地化学习强大的表示形式。实验结果表明,我们的方法明显优于THUMOS14上的最新技术(49.1%对42.8%)。此外,ActivityNet上的扩充实验还验证了对行动建议关系进行建模的有效性。可以在https://github.com/Alvin-Zeng/PGCN上找到代码。
数据输入
从给的github里下载了经过I3D特征提取后得到的RGB特征和Flow特征。对于我们这种机子跑不起来I3D代码的,简直福报。dataset.py做特征数据的输入和处理。
分成两个部分:
1)视频处理
2)proposals提取
在PGCNDataSet类中的方法,
def _prepare_iou_dict(self):
pbar = tqdm(total=len(self.video_list))
for cnt, video in enumerate(self.video_list):
pbar.update(1)
fg = video.get_fg(self.fg_iou_thresh, self.gt_as_fg)
incomp, bg = video.get_negatives(self.incomplete_iou_thresh, self.bg_iou_thresh,
self.bg_coverage_thresh, self.incomplete_overlap_thresh)
self.prop_dict[video.id] = [fg, incomp, bg]
video_pool = fg + incomp + bg
# calculate act iou matrix
prop_array = np.array([[prop.start_frame, prop.end_frame] for prop in video_pool])
iou_array, overlap_array = segment_tiou(prop_array, prop_array)
self.act_iou_dict[video.id] = iou_array
# calculate act distance matrix
prop_array = np.array([[prop.start_frame, prop.end_frame] for prop in video_pool])
distance_array = segment_distance(prop_array, prop_array)
self.act_dis_dict[video.id] = distance_array
pbar.close()
def _prepare_test_iou_dict(self):
pbar = tqdm(total=len(self.video_list))
for cnt, video in enumerate(self.video_list):
pbar.update(1)
video_pool = video.proposals
# calculate act iou matrix
prop_array = np.array([[prop.start_frame, prop.end_frame] for prop in video_pool])
iou_array, overlap_array = segment_tiou(prop_array, prop_array)
self.act_iou_dict[video.id] = iou_array
# calculate act distance matrix
prop_array = np.array([[prop.start_frame, prop.end_frame] for prop in video_pool])
distance_array = segment_distance(prop_array, prop_array)
self.act_dis_dict[video.id] = distance_array
pbar.close()
实验模型

图1:我们的P-GCN模型的示意图。给定来自输入的未修剪视频的一组建议,我们通过每个建议实例化图中的节点。然后,在节点之间建立边以建模建议之间的关系。我们在具有不同输入特征(即原始特征和扩展特征)的同一构造图上使用两个单独的GCN。最后,P-GCN模型同时输出所有提案的预测动作类别,完整性和边界回归结果。
1.原始特征:通过I3D提取得到的1024维双流特征
扩展特征:作者在相关工作中“上述方法忽略了提案的上下文信息,因此已经进行了一些尝试以合并上下文以增强提案特征。通过在提案的扩展接受域(即边界)中提取特征,它们显示出令人鼓舞的改进。尽管取得了成功,但他们都分别处理每个提案。相比之下,我们的方法考虑了提案与提案之间的互动,并利用了提案之间的关系。”

图2 扩展的特征提取的建模
original proposal:我们首先在建议中获取一组段级特征,然后在各个段之间应用最大池化,以获得一个1024维特征向量.
extended proposal:原始proposal的边界在左侧和右侧都扩展了其长度的12,因此扩展了提案。因此,扩展提案包含三个部分:开始,居中和结束(如图2右)。对于每个部分,我们都遵循与原始建议相同的特征提取过程。最后,扩展proposal特征是通过将三个部分的特征串联而获得的。
3.图卷积网络得到所有提案的预测动作类别,完整性和边界回归结果
网络大致模型如下:
DataParallel(
(module): PGCN(
(activity_fc): Linear(in_features=2048, out_features=21, bias=True)
(completeness_fc): Linear(in_features=6144, out_features=20, bias=True)
(regressor_fc): Linear(in_features=6144, out_features=40, bias=True)
(Act_GCN): GCN(
(gc1): GraphConvolution (1024 -> 512)
(gc2): GraphConvolution (512 -> 1024)
)
(Comp_GCN): GCN(
(gc1): GraphConvolution (3072 -> 512)
(gc2): GraphConvolution (512 -> 3072)
)
(dropout_layer): Dropout(p=0.8, inplace=False)
)
)

图3:P-GCN模型的网络架构
一个带有N类别数×2的输出用于边界回归,另外两个带有N类别数的输出则分别用于动作分类和完整性分类。
第一个GCN公式为:
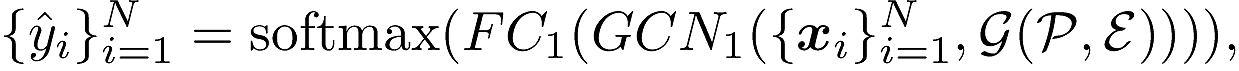
(在原始的论文代码中好像没有找到使用softmax的代码)
第二个GCN可以表示为:
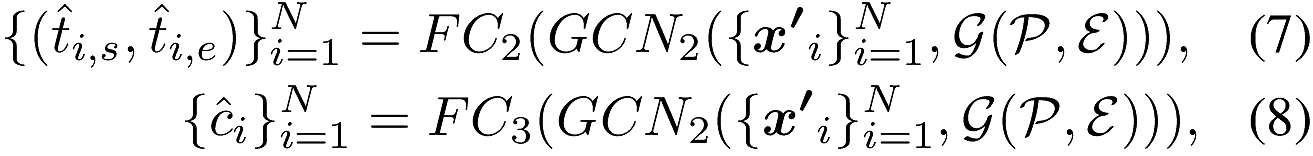
图卷积构建,文中公式为:
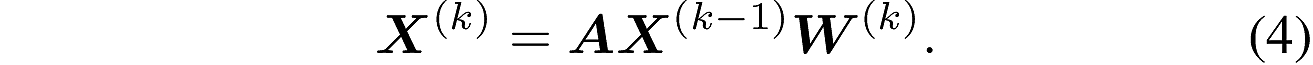
#其中adj是邻接矩阵,input是输入,weight是权重
support = torch.mm(input, self.weight)
output = torch.mm(adj, support)
PGCN中训练和测试的前向分类:
def forward(self, input, target, reg_target, prop_type):
if not self.test_mode:
return self.train_forward(input, target, reg_target, prop_type)
else:
return self.test_forward(input)
proposal采样
该采样在
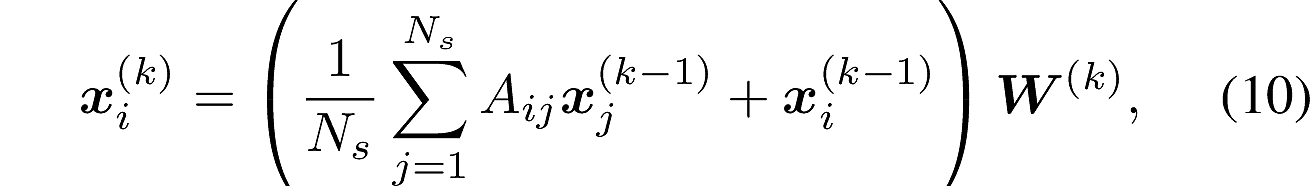
训练前向传播
def train_forward(self, input, target, reg_target, prop_type):
activity_fts = input[0]
completeness_fts = input[1]
batch_size = activity_fts.size()[0]
# construct feature matrix
act_ft_mat = activity_fts.view(-1, self.act_feat_dim).contiguous()
comp_ft_mat = completeness_fts.view(-1, self.comp_feat_dim).contiguous()
# act cosine similarity 余弦相似度来分配权重
#“在这里,我们通过为边缘分配特定的权重来设计邻接矩阵。例如,我们可以应用余弦相似度来估计边缘的权重”
dot_product_mat = torch.mm(act_ft_mat, torch.transpose(act_ft_mat, 0, 1))
len_vec = torch.unsqueeze(torch.sqrt(torch.sum(act_ft_mat * act_ft_mat, dim=1)), dim=0)
len_mat = torch.mm(torch.transpose(len_vec, 0, 1), len_vec)
act_cos_sim_mat = dot_product_mat / len_mat
# comp cosine similarity 余弦相似度来分配权重
dot_product_mat = torch.mm(comp_ft_mat, torch.transpose(comp_ft_mat, 0, 1))
len_vec = torch.unsqueeze(torch.sqrt(torch.sum(comp_ft_mat * comp_ft_mat, dim=1)), dim=0)
len_mat = torch.mm(torch.transpose(len_vec, 0, 1), len_vec)
comp_cos_sim_mat = dot_product_mat / len_mat
#
mask = act_ft_mat.new_zeros(self.adj_num, self.adj_num)
for stage_cnt in range(self.child_num + 1):
ind_list = list(range(1 + stage_cnt * self.child_num, 1 + (stage_cnt + 1) * self.child_num))
for i, ind in enumerate(ind_list):
mask[stage_cnt, ind] = 1 / self.child_num
mask[stage_cnt, stage_cnt] = 1
mask_mat_var = act_ft_mat.new_zeros(act_ft_mat.size()[0], act_ft_mat.size()[0])
for row in range(int(act_ft_mat.size(0)/ self.adj_num)):
mask_mat_var[row * self.adj_num : (row + 1) * self.adj_num, row * self.adj_num : (row + 1) * self.adj_num] \
= mask
act_adj_mat = mask_mat_var * act_cos_sim_mat
comp_adj_mat = mask_mat_var * comp_cos_sim_mat
# normalized by the number of nodes
act_adj_mat = F.relu(act_adj_mat)
comp_adj_mat = F.relu(comp_adj_mat)
#
act_gcn_ft = self.Act_GCN(act_ft_mat, act_adj_mat)
comp_gcn_ft = self.Comp_GCN(comp_ft_mat, comp_adj_mat)
#
out_act_fts = torch.cat((act_gcn_ft, act_ft_mat), dim=-1)
act_fts = out_act_fts[:-1: self.adj_num, :]
act_fts = self.dropout_layer(act_fts)
out_comp_fts = torch.cat((comp_gcn_ft, comp_ft_mat), dim=-1)
comp_fts = out_comp_fts[:-1: self.adj_num, :]
raw_act_fc = self.activity_fc(act_fts)
raw_comp_fc = self.completeness_fc(comp_fts)
# 保留7份提案以计算完整性
raw_comp_fc = raw_comp_fc.view(batch_size, -1, raw_comp_fc.size()[-1])[:, :-1, :].contiguous()
raw_comp_fc = raw_comp_fc.view(-1, raw_comp_fc.size()[-1])
comp_target = target.view(batch_size, -1, self.adj_num)[:, :-1, :].contiguous().view(-1).data
comp_target = comp_target[0: -1: self.adj_num].contiguous()
# keep the target proposal
type_data = prop_type.view(-1).data
type_data = type_data[0: -1: self.adj_num]
target = target.view(-1)
target = target[0: -1: self.adj_num]
act_indexer = ((type_data == 0) + (type_data == 2)).nonzero().squeeze()
#回归目标
reg_target = reg_target.view(-1, 2)
reg_target = reg_target[0: -1: self.adj_num]
reg_indexer = (type_data == 0).nonzero().squeeze()
raw_regress_fc = self.regressor_fc(comp_fts).view(-1, self.completeness_fc.out_features, 2).contiguous()
return raw_act_fc[act_indexer, :], target[act_indexer], type_data[act_indexer], \
raw_comp_fc, comp_target, \
raw_regress_fc[reg_indexer, :, :], target[reg_indexer], reg_target[reg_indexer, :]
测试
我们将分类分数与完整性分数相乘,作为计算mAP的最终分数。
测试,后面添加的是最优的模型:
sh test.sh /PGCN-master/outputPGCN_thumos14_model_best.pth.tar
代码:
def test_forward(self, input):
activity_fts = input[0]
completeness_fts = input[1]
batch_size = activity_fts.size()[0]
# construct feature matrix
act_ft_mat = activity_fts.view(-1, self.act_feat_dim).contiguous()
comp_ft_mat = completeness_fts.view(-1, self.comp_feat_dim).contiguous()
# act cosine similarity
dot_product_mat = torch.mm(act_ft_mat, torch.transpose(act_ft_mat, 0, 1))
len_vec = torch.unsqueeze(torch.sqrt(torch.sum(act_ft_mat * act_ft_mat, dim=1)), dim=0)
len_mat = torch.mm(torch.transpose(len_vec, 0, 1), len_vec)
act_cos_sim_mat = dot_product_mat / len_mat
# comp cosine similarity
dot_product_mat = torch.mm(comp_ft_mat, torch.transpose(comp_ft_mat, 0, 1))
len_vec = torch.unsqueeze(torch.sqrt(torch.sum(comp_ft_mat * comp_ft_mat, dim=1)), dim=0)
len_mat = torch.mm(torch.transpose(len_vec, 0, 1), len_vec)
comp_cos_sim_mat = dot_product_mat / len_mat
mask = act_ft_mat.new_zeros(self.adj_num, self.adj_num)
for stage_cnt in range(self.child_num + 1):
ind_list = list(range(1 + stage_cnt * self.child_num, 1 + (stage_cnt + 1) * self.child_num))
for i, ind in enumerate(ind_list):
mask[stage_cnt, ind] = 1 / self.child_num
mask[stage_cnt, stage_cnt] = 1
mask_mat_var = act_ft_mat.new_zeros(act_ft_mat.size()[0], act_ft_mat.size()[0])
for row in range(int(act_ft_mat.size(0)/ self.adj_num)):
mask_mat_var[row * self.adj_num: (row + 1) * self.adj_num, row * self.adj_num: (row + 1) * self.adj_num] \
= mask
act_adj_mat = mask_mat_var * act_cos_sim_mat
comp_adj_mat = mask_mat_var * comp_cos_sim_mat
# normalized by the number of nodes
act_adj_mat = F.relu(act_adj_mat)
comp_adj_mat = F.relu(comp_adj_mat)
act_gcn_ft = self.Act_GCN(act_ft_mat, act_adj_mat)
comp_gcn_ft = self.Comp_GCN(comp_ft_mat, comp_adj_mat)
out_act_fts = torch.cat((act_gcn_ft, act_ft_mat), dim=-1)
act_fts = out_act_fts[:-1: self.adj_num, :]
out_comp_fts = torch.cat((comp_gcn_ft, comp_ft_mat), dim=-1)
comp_fts = out_comp_fts[:-1: self.adj_num, :]
raw_act_fc = self.activity_fc(act_fts)
raw_comp_fc = self.completeness_fc(comp_fts)
raw_regress_fc = self.regressor_fc(comp_fts).view(-1, self.completeness_fc.out_features * 2).contiguous()
return raw_act_fc, raw_comp_fc, raw_regress_fc
双流融合
融合运行代码:
sh test_two_stream.sh
Loss方法
"""loss and optimizer"""
activity_criterion = torch.nn.CrossEntropyLoss().cuda()
completeness_criterion = CompletenessLoss().cuda()
regression_criterion = ClassWiseRegressionLoss().cuda()
一共分为三个部分,动作loss,完整性loss,位置回归loss
act_loss = act_criterion(activity_out, activity_target)
comp_loss = comp_criterion(completeness_out, completeness_target, ohem_num, comp_group_size)
reg_loss = regression_criterion(regression_out, regression_labels, regression_target)
loss = act_loss + comp_loss * args.comp_loss_weight + reg_loss * args.reg_loss_weight
losses.update(loss.item(), batch_size)
act_losses.update(act_loss.item(), batch_size)
comp_losses.update(comp_loss.item(), batch_size)
reg_losses.update(reg_loss.item(), batch_size)
位置回归loss
class ClassWiseRegressionLoss(torch.nn.Module):
"""
This class implements the location regression loss for each class
"""
def __init__(self):
super(ClassWiseRegressionLoss, self).__init__()
self.smooth_l1_loss = nn.SmoothL1Loss() #平滑L1损失
def forward(self, pred, labels, targets):
indexer = labels.data - 1
prep = pred[:, indexer, :]
class_pred = torch.cat((torch.diag(prep[:, :, 0]).view(-1, 1),
torch.diag(prep[:, :, 1]).view(-1, 1)),
dim=1)
loss = self.smooth_l1_loss(class_pred.view(-1), targets.view(-1)) * 2
return loss
完整性loss
class CompletenessLoss(torch.nn.Module):
def __init__(self, ohem_ratio=0.17):
super(CompletenessLoss, self).__init__()
self.ohem_ratio = ohem_ratio
self.sigmoid = nn.Sigmoid()
def forward(self, pred, labels, sample_split, sample_group_size):
pred_dim = pred.size()[1]
print("pred",pred.size())
pred = pred.view(-1, sample_group_size, pred_dim)
labels = labels.view(-1, sample_group_size)
pos_group_size = sample_split
neg_group_size = sample_group_size - sample_split
pos_prob = pred[:, :sample_split, :].contiguous().view(-1, pred_dim)
neg_prob = pred[:, sample_split:, :].contiguous().view(-1, pred_dim)
pos_ls = OHEMHingeLoss.apply(pos_prob, labels[:, :sample_split].contiguous().view(-1), 1,
1.0, pos_group_size)
neg_ls = OHEMHingeLoss.apply(neg_prob, labels[:, sample_split:].contiguous().view(-1), -1,
self.ohem_ratio, neg_group_size)
pos_cnt = pos_prob.size(0)
neg_cnt = max(int(neg_prob.size()[0] * self.ohem_ratio), 1)
return pos_ls / float(pos_cnt + neg_cnt) + neg_ls / float(pos_cnt + neg_cnt)
行为loss:
采用了交叉熵损失














 1007
1007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









