






论文链接:https://arxiv.org/abs/2203.14104
Br-prompt在融合经过clip后的image embedding和经过clip后的位置文本描述 order prompt embedding的对应。
x将image embedding 重复 K 个,每一个image embedding用来和order prompt embedding中的具体位置进行对应。
image_embedding = image_embedding.unsqueeze(1).repeat(1, config.data.max_act, 1, 1)
cnt_emb, image_embedding = fusion_model(image_embedding, text_pos_embedding)原论文翻译:
帧级特征(代码中为x)与序数提示嵌入一同经过融合编码器,提取第i个动作的clip级特征代码中的x[:, :, -self.clip_length:]。融合模块的设计对于理解x中的动作内部信息和动作间信息至关重要。提出了一种基于Transformer的融合结构。序数提示ord_emb的信息被融合到融合编码器中,提供指导性信息。还在融合模块内嵌入了一个计数标记,以收集与统计提示相匹配的定量信息。clip级特征在对比的视觉-文本学习模式下,与语义提示嵌入和整合提示嵌入一起进行联合学习。
融合目的:融合模块。融合编码器从连续的帧级特征中提取核心信息。换句话说,它试图抽象出输入视频剪辑中发生的一系列动作。采用了一种序数注意机制来实现融合模块,即每次融合模块只关注特定位置的动作(第i个动作)。序数注意机制通过将第i个序数提示嵌入添加到融合输入中来实现,这是一种早期融合策略。为融合模块采用Transformer-Encoder结构。融合编码器的输入标记包括:一个可学习的计数标记(代码中的self.cnt_token),第i个序数提示嵌入,一个分隔标记(代码中的sep_token),以及表示有L帧的帧序列级特征的视觉标记。第i个序数表示融合编码器关注的哪一个动作。对Lc帧级特征的编码表示进行均值池化,以表示片段级特征。此外,我们添加了一个可学习的计数标记(代码中的self.cnt_token),以学习额外的动作定量信息。标记self.cnt_token的编码表示将通过与统计提示嵌入一起的对比视觉-文本学习框架。
class BPromptFusing(nn.Module):
def __init__(self, clip_length=None, embed_dim=2048, n_layers=6, heads=8):
super(BPromptFusing, self).__init__()
self.clip_length = clip_length
drop_rate = 0.
enc_layer = nn.TransformerEncoderLayer(d_model=embed_dim, nhead=heads)
self.transformer_enc = nn.TransformerEncoder(enc_layer, num_layers=n_layers, norm=nn.LayerNorm(
embed_dim))
self.cnt_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.sep_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, clip_length + 3, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
with torch.no_grad():
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cnt_token, std=.02)
trunc_normal_(self.sep_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
with torch.no_grad():
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x, ord_emb):
b, n, f, c = x.shape
x = x.view(-1, f, c)
ord_emb = ord_emb.view(-1, ord_emb.shape[-1])
ord_emb = torch.unsqueeze(ord_emb, dim=1)
nvids = x.shape[0]
cnt_token = self.cnt_token.expand(nvids, -1, -1)
sep_token = self.sep_token.expand(nvids, -1, -1)
x = torch.cat((cnt_token, ord_emb, sep_token, x), dim=1)
x = x + self.pos_embed
x.transpose_(1, 0)
x = self.transformer_enc(x)
x.transpose_(1, 0)
x = x.view(b, n, -1, c)
return x[:, :, 0], x[:, :, -self.clip_length:]基于提示的推理: 在自然语言处理领域中,“预训练、提示和预测”范式表明,基于提示的设计具有将下游任务的目标与预训练过程相结合的优势。br-prompt框架具有通过解决基于提示的完形填空测试来识别一系列动作的能力,例如“此视频片段总共包含_个动作”或“ ,此人正在执行__动作”。实际操作中,首先通过预训练的文本编码器生成所有相关序数提示、统计提示和语义提示的文本特征。对于每个测试视频,使用预训练的图像编码器和融合编码器提取由不同序数提示嵌入的剪辑特征以及平均统计表示。首先,找到与融合模块输出的x[:, :, 0](即connt信息)最匹配的统计提示嵌入,以确定动作的总数。然后,找到与每个序数提示嵌入的剪辑特征最匹配的语义提示嵌入,逐个确定每个序数动作。对于提示的变体,我们在推理阶段从所有变体格式中进行投票,以获取最匹配的提示。(因为在作者定义prompt的时候,有很多种描述方式,所以通过这种方式提高效果)
论文中的实验分析:
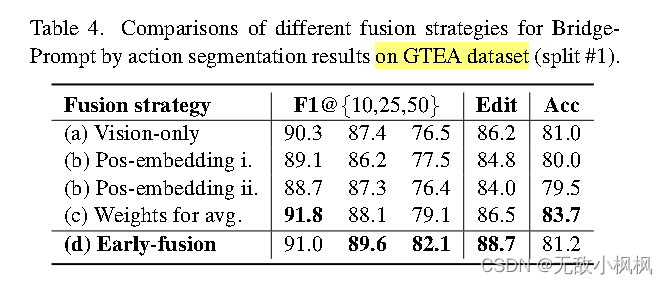
这里d是作者用的早期融合的方式。包含可学习计数标记的早期融合序数提示。这是框架中采用的融合策略。对于 Bridge-Prompt 的不同融合策略的动作分割性能在 GTEA(split #1)上进行了评估。表 4 显示了定量结果,表明融合模块对于提高 Bridge-Prompt 的学习效果具有显著意义。通过将序数信息合并到融合模块中,学到的表示具有每个序数动作的关注信息。融合策略 (b) 和 (c) 是更直接地整合序数提示的方式,然而,序数提示嵌入与视觉特征没有进行交叉注意力。具体来说,策略 (b) 和 (c) 学习的信息类似于“在任何 16 帧视频剪辑中,第一个动作可能在哪里?”而 (d) 关注的是“在此视频中的所有动作中,第一个动作在哪里?”每个序数动作的位置还取决于其他相邻的动作,这使得早期融合的方式更加可信。(因为在此模块中,用到了序数注意力。可学习的split_token 可以提供不同视频的动作位置)















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









