







卷积神经网络(LeNet)
引用翻译:《动手学深度学习》
我们现在准备把所有的工具放在一起,部署你的第一个全功能卷积神经网络。在我们第一次接触图像数据时,我们将多层感知器应用于Fashion-MNIST数据集中的服装图片。Fashion-MNIST中的每张图片都由一个28×28的二维矩阵组成。为了使这些数据适用于多层感知器,即把输入作为一维固定长度的向量来接收,我们首先把每张图片扁平化,产生长度为784的向量,然后用一系列全连接的层来处理它们。
现在我们已经引入了卷积层,我们可以将图像保持在原来的空间组织网格中,用一系列连续的卷积层来处理它。此外,由于我们使用的是卷积层,我们可以在所需的参数数量上享有相当大的节省。
在这一节中,我们将介绍最早发表的卷积神经网络之一,它的好处首先由Yann Lecun(当时是AT&T贝尔实验室的研究员)证明,目的是识别图像中的手写数字-LeNet5。 在90年代,他们对LeNet的实验给出了第一个令人信服的证据,证明通过反向传播训练卷积神经网络是可能的。他们的模型在当时取得了杰出的成果(当时只有支持向量机可以与之媲美),并被采用来识别ATM机上的存款数字。一些自动取款机仍在运行扬和他的同事Leon Bottou在20世纪90年代编写的代码。
一、LeNet
粗略的说,我们可以认为LeNet是由两部分组成的。(i) 一块卷积层;和(ii) 一块全连接层。在深入了解之前,让我们先简单回顾一下LeNet的模型。
from IPython.display import Image
Image(filename='../img/lenet.png')
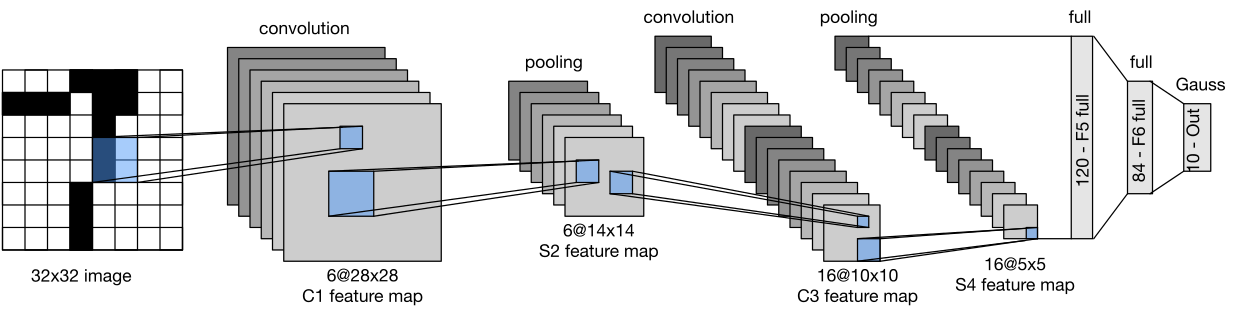
LeNet 5中的数据流。输入是一个手写的数字,输出是10个可能结果的概率。
LeNet 5中的数据流。输入是一个手写的数字,输出是10个可能结果的概率。
卷积块中的基本单元是一个卷积层和一个后续的平均池层(注意,最大池层效果更好,但它在90年代还没有被发明出来)。卷积层用于识别图像中的空间模式,如线条和物体的部分,随后的平均池化层则用于降低维度。卷积层块由这两个基本单元的重复堆叠组成。每个卷积层使用一个5×5的核,并用一个sigmoid激活函数来处理每个输出(再次注意,现在已知ReLU工作更可靠,但当时还没有被发明)。第一个卷积层有6个输出通道,第二个卷积层将通道深度进一步增加到16。
然而,与这种通道数量的增加相吻合的是,高度和宽度都大大缩水。因此,增加输出通道的数量使得两个卷积层的参数大小相似。两个平均池化层的大小为2×2,取跨度为2(注意,这意味着它们是不重叠的)。换句话说,池化层对表示进行降采样,使其正好是池化前大小的四分之一。
卷积块发出一个输出,其大小由(批次大小、通道、高度、宽度)给出。在我们将卷积块的输出传递给全连接块之前,我们必须对迷你批中的每个例子进行平整处理。换句话说,我们将这个4D输入进行tansform,变成全连接层所期望的2D输入:作为提醒,第一个维度索引迷你批中的例子,第二个维度给出每个例子的平面向量表示。LeNet的全连接层块有三个全连接层,分别有120、84和10个输出。因为我们仍然在进行分类,所以10维的输出层对应着可能的输出类别的数量。
虽然达到真正理解LeNet内部的情况可能需要一些工作,但你可以在下面看到,在现代深度学习库中实现它是非常简单的。同样,我们将依靠顺序类。
import sys
sys.path.insert(0, '..')
import d2l
import torch
import torch.nn as nn
import torch.optim as optim
import time
class Flatten(torch.nn.Module):
def forward(self, x):
return x.view(x.shape[0], -1)
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1,1,28,28)
net = torch.nn.Sequential(
Reshape(),
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
Flatten(),
nn.Linear(in_features=16*5*5, out_features=120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
与原始网络相比,我们擅自将最后一层的高斯激活替换为普通的线性层,这在训练时往往会更加方便。除此之外,这个网络符合LeNet5的历史定义。 接下来,我们将一个大小为28×28的单通道例子送入网络,并逐层进行正向计算,打印每层的输出形状,以确保我们理解这里发生的事情。
X = torch.randn(size=(1,1,28,28), dtype = torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
Reshape output shape: torch.Size([1, 1, 28, 28])
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])
Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])
Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])
请注意,在整个卷积块中,每一层的表示的高度和宽度都减少了(与前一层相比)。卷积层使用一个高度和宽度为5的内核,在第一个卷积层中只有2个像素的填充,在第二个卷积层中没有填充,这导致高度和宽度都分别减少了2和4个像素。此外,每个池化层将高度和宽度减半。然而,当我们往上走的时候,通道的数量逐层增加,从输入的1个增加到第一个卷积层后的6个和第二个层后的16个。然后,全连接层逐层降低维度,直到发出一个与图像类别数量相匹配的输出。
Image(filename="../img/lenet-vert.png")

二、数据采集和训练
既然我们已经实现了这个模型,我们不妨做一些实验,看看我们能用LeNet模型完成什么。虽然在原始的MNIST OCR数据集上训练LeNet可能会起到怀旧的作用,但这个数据集已经变得太容易了,MLP的准确率超过98%,所以很难看到卷积网络的好处。因此,我们将坚持使用Fashion-MNIST作为我们的数据集,因为虽然它有相同的形状(28×28张图片),但这个数据集明显更具挑战性。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
虽然卷积网络的参数可能很少,但它们的计算成本仍然比类似的深度多层感知器要高得多,所以如果你可以使用GPU,这可能是一个很好的时机,可以将其投入使用,以加快训练速度。
这里有一个简单的函数,我们可以用它来检测我们是否有GPU。在这个函数中,如果gpu0可用,我们会尝试使用torch.cuda.is_available()方法来分配。否则,我们坚持使用CPU。
def try_gpu():
"""如果GPU可用,返回torch.device为cuda:0;否则返回torch.device为cpu。"""
if torch.cuda.is_available():
device = torch.device('cuda:0')
else:
device = torch.device('cpu')
return device
device = try_gpu()
device
device(type='cpu')
对于评估,我们需要对我们在从头开始实现softmax(chapter_softmax_scratch)时描述的evaluate_accuracy函数做一点修改。由于完整的数据集存在于CPU上,我们需要在计算我们的模型之前将其复制到GPU上。这是通过chapter_use_gpu中描述的.to(device)完成的。请注意,我们在数据最终所在的设备上积累错误(在acc)。这就避免了可能损害性能的中间复制操作。
# 这个函数已经被保存在d2l包中,供将来使用。该函数将被逐步改进。它的完整实现将在 "图像扩增 "部分讨论
def evaluate_accuracy(data_iter, net,device=torch.device('cpu')):
"""Evaluate accuracy of a model on the given data set."""
acc_sum,n = torch.tensor([0],dtype=torch.float32,device=device),0
for X,y in data_iter:
X,y = X.to(device),y.to(device)
net.eval()
with torch.no_grad():
y = y.long()
acc_sum += torch.sum((torch.argmax(net(X), dim=1) == y))
n += y.shape[0]
return acc_sum.item()/n
我们还需要更新我们的训练函数以处理GPU。与chapter_softmax_scratch中定义的train_ch3不同,我们现在需要在进行前向和后向处理之前,将每批数据转移到我们指定的设备(希望是GPU)。
# This function has been saved in the d2l package for future use
def train_ch5(net, train_iter, test_iter,criterion, num_epochs, batch_size, device,lr=None):
"""Train and evaluate a model with CPU or GPU."""
print('training on', device)
net.to(device)
optimizer = optim.SGD(net.parameters(), lr=lr)
for epoch in range(num_epochs):
train_l_sum = torch.tensor([0.0],dtype=torch.float32,device=device)
train_acc_sum = torch.tensor([0.0],dtype=torch.float32,device=device)
n, start = 0, time.time()
for X, y in train_iter:
net.train()
optimizer.zero_grad()
X,y = X.to(device),y.to(device)
y_hat = net(X)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
with torch.no_grad():
y = y.long()
train_l_sum += loss.float()
train_acc_sum += (torch.sum((torch.argmax(y_hat, dim=1) == y))).float()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net,device)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, '
'time %.1f sec'
% (epoch + 1, train_l_sum/n, train_acc_sum/n, test_acc,
time.time() - start))
我们在设备指示的设备上初始化模型参数,这次使用Xavier初始化器。损失函数和训练算法仍然使用交叉熵损失函数和小批量随机梯度下降法。
lr, num_epochs = 0.9, 5
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
torch.nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net = net.to(device)
criterion = nn.CrossEntropyLoss()
train_ch5(net, train_iter, test_iter, criterion,num_epochs, batch_size,device, lr)
training on cpu
epoch 1, loss 0.0091, train acc 0.103, test acc 0.100, time 60.6 sec
epoch 2, loss 0.0055, train acc 0.446, test acc 0.637, time 59.9 sec
epoch 3, loss 0.0032, train acc 0.677, test acc 0.714, time 56.4 sec
epoch 4, loss 0.0026, train acc 0.734, test acc 0.756, time 57.6 sec
三、摘要
- 卷积神经网络(简称ConvNet)是一个使用卷积层的网络。
- 在一个卷积网络中,我们在卷积、非线性以及通常的池化操作之间交替进行。
- 最终,在通过一个(或多个)密集层发出输出之前,分辨率被降低。
- LeNet是这种网络的首次成功部署。
四、练习
1、用最大集合法代替平均集合法。会发生什么?
2、尝试在LeNet的基础上构建一个更复杂的网络以提高其准确性。
- 调整卷积窗口大小。
- 调整输出通道的数量。
- 调整激活函数(ReLU?)。
- 调整卷积层的数量。
- 调整完全连接层的数量。
- 调整学习率和其他训练细节(初始化、 epochs等)。
3、在原始MNIST数据集上尝试改进后的网络。
4、显示LeNet第一层和第二层对不同输入(如毛衣、大衣)的激活情况。















 1709
1709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









