






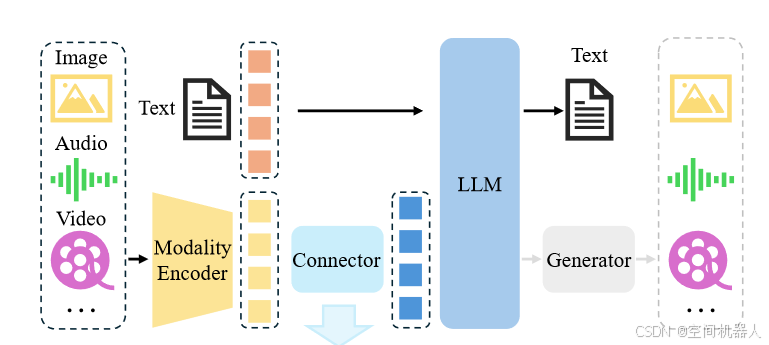
想象一下,人类是如何感知世界的呢?我们看到🌄、听到音乐🎵、触摸到🖐️、甚至还能闻到👃。但如果只能靠单一感官,比如只能看但听不到声音,那体验肯定大打折扣!
AI 也是一样的! 现实世界的信息是多模态的(Multi-Modal),比如:
- 视频 = 图像+声音+文本字幕
- 自动驾驶 = 摄像头+激光雷达+毫米波雷达+GPS
- 医疗AI = X光片+病历文本+基因数据
🚀 多模态融合(Multi-Modal Fusion) 就是让 AI 像人一样,综合不同类型的信息,从而提升认知和决策能力!今天,我们就来深入拆解多模态融合的奥秘!🔍
一、多模态到底是什么?
💡 “模态” 就是信息的不同形式,比如:
| 模态类型 | 举例 |
|---|---|
| 视觉(Vision) | 图片、视频 |
| 语音(Audio) | 说话声、音乐 |
| 语言(Text) | 文字、对话 |
| 触觉(Touch) | 震动、压力 |
| 传感器(Sensor) | 激光雷达、毫米波雷达 |
举个例子📷🎙️:
- 你在看一部电影🎬,如果只看画面没声音,体验是不是很割裂?
- 听歌🎵,如果只有歌词但没旋律,就没啥感觉了。
🌟 所以,多模态融合就是让AI像人一样,把各种信息整合在一起,提高理解能力!
二、多模态融合有哪些方式?
多模态融合一般分三大类👇:
1️⃣ 早期融合(Early Fusion)—— 数据级融合
💡 特点:在模型输入阶段,先把所有模态的数据合并成一个大“拼盘”,然后喂给模型。
📌 举例:
- 自动驾驶🚗:把摄像头、雷达、激光雷达的原始数据融合,然后送给神经网络做感知。
- 语音识别🗣️:同时输入声音波形+嘴部的视觉动图,提高准确率(比如听不清时靠读唇术!)
🟢 优点:保留了最完整的信息,理论上能学到更丰富的特征。
🔴 缺点:不同模态的数据格式差异大,直接融合可能会增加噪声和计算复杂度。
2️⃣ 中期融合(Mid Fusion)—— 特征级融合
💡 特点:各个模态单独通过不同的神经网络提取特征,然后再合并进行决策。
📌 举例:
- 视频情感分析:
- 视觉CNN 负责提取人脸表情特征🤨😊
- 语音RNN 负责分析说话语调📢
- 文本BERT 负责分析字幕文本💬
- 最后融合所有信息,判断人物情绪!
🟢 优点:既能保留各模态特征,又能降低数据噪声,比较均衡。
🔴 缺点:需要多个独立的模型,训练成本较高。
3️⃣ 晚期融合(Late Fusion)—— 决策级融合
💡 特点:不同模态的数据分别训练独立的模型,最后在决策阶段融合预测结果。
📌 举例:
- 医疗AI🩺(判断病人是否有某种疾病):
- 模型1:分析 CT/X光 影像结果📸
- 模型2:分析电子病历📄
- 模型3:分析基因检测数据🧬
- 最终投票决策,给出综合诊断!
🟢 优点:每个模态的模型可以独立优化,不受其他模态干扰。
🔴 缺点:信息融合较浅,无法挖掘模态间的深层关联。
🌟 总结:
| 融合方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 早期融合 | 保留最丰富信息 | 计算量大,数据格式差异大 | 自动驾驶、感知任务 |
| 中期融合 | 平衡特征提取和计算量 | 训练复杂度较高 | 视频情感分析、安防 |
| 晚期融合 | 各模态独立优化,抗干扰 | 深层关联不足 | 医疗、金融决策 |
三、多模态融合的经典应用
💡 **多模态融合已经被广泛应用在各个领域!**🚀
📸 1. 视觉+文本:AI 画画(Stable Diffusion, DALL·E)
- 你输入**“一只骑着自行车的宇航员”🚴♂️🚀**,AI 直接给你画出来!
- 文本→视觉,需要将语言模态和图像模态融合才能做到。
🎤 2. 语音+视觉:Lip Reading 读唇术
- 伦敦大学的研究用 CNN+RNN 结合视频+音频,让 AI 通过看嘴型识别讲话内容,准确率比人类更高!
🚗 3. 自动驾驶:摄像头+激光雷达+雷达+GPS
- 只靠摄像头可能会被大雾影响,但激光雷达不受影响!
- 多传感器融合,让自动驾驶在不同环境下都能安全运行。
🏥 4. 医疗诊断:医学影像+病历+基因数据
- X光片 + CT + 病人病史 结合,能提高 AI 诊断准确率。
- AI 还能分析基因数据,预测癌症风险!
四、未来发展趋势
1️⃣ 大模型+多模态融合
- OpenAI 的 GPT-4,能同时处理文本、图片、语音!
- 未来可能直接用一套大模型搞定所有模态!
2️⃣ 跨模态学习(Cross-Modal Learning)
- 让 AI 在一个模态学到的知识,迁移到另一个模态,比如:
- 看着一张图片,就能自动生成配音! 🎙️🎞️
3️⃣ 更强的鲁棒性
- 让 AI 学会在某个模态缺失时,仍然能正确判断!
- 比如自动驾驶,摄像头坏了,仍然能靠激光雷达和 GPS 行驶。
五、总结
✅ 多模态融合让 AI 像人一样感知世界! 🌍
✅ 三种融合方式(早期/中期/晚期),适用于不同场景! 🔥
✅ 应用广泛:AI 画画、自动驾驶、医疗诊断等! 🏥🚗🎨
✅ 未来 AI 将更加智能,跨模态学习能力更强! 🚀
🔥 **搞懂多模态,你就站在 AI 发展的最前沿!**🔥



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











