







1. Python对象拷贝
在Python中,赋值语句总是建立对象的引用,看下面的一段代码
>>> a = [1,2,3]
>>> b = a
>>> print(id(a), id(b))
(4420030688, 4420030688) # 变量地址一致,证明b只是a的引用
>>> b.append(3)
>>> a # 对b的修改,实际是对a的修改 [1, 2, 3, 3]
会发现b = a操作后,a和b指向了同一块地址。
上面例子中,a和b都是可变对象(list)的,对b的修改,同样可会影响到a
Python中copy模块通过copy()和deepcopy()函数来分别提供浅拷贝和深拷贝功能,可以通过在对象中定义__copy__()和__deepcopy()__方法来修改模块默认的实现。
copy模块中的deepcopy函数可以实现深拷贝:
>>> import copy
>>> l1 = [2, 3, 4, [3, 5]]
>>> l2 = copy.deepcopy(l1)
>>> l1, l2
([2, 3, 4, [3, 5]], [2, 3, 4, [3, 5]])
>>> l2[3].append(6)
>>> l2.append(7)
>>> l1, l2
([2, 3, 4, [3, 5]], [2, 3, 4, [3, 5, 6], 7])
2.format 格式化函数
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % ,format 函数可以接受不限个参数,位置可以不按顺序。
示例:
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
设置参数:
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com")) # 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site)) # 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
向 str.format() 传入对象:
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 为: {0.value}'.format(my_value)) # "0" 是可选的
数字格式化
>>> print("{:.2f}".format(3.1415926))
3.14
格式化字符串f-string
f-string,亦称为格式化字符串常量(formatted string literals),是Python3.6新引入的一种字符串格式化方法。
f-string在形式上是以 f 或 F 修饰符引领的字符串(f’xxx’ 或 F’xxx’),以大括号 {} 标明被替换的字段;f-string在本质上并不是字符串常量,而是一个在运行时运算求值的表达式。
f-string采用 {content:format} 设置字符串格式,其中 content 是替换并填入字符串的内容,可以是变量、表达式或函数等,format 是格式描述符。采用默认格式时不必指定 {:format},如上面例子所示只写 {content} 即可。
>>> f'A total number of {24 * 8 + 4}'
'A total number of 196'
>>> f'Complex number {(2 + 2j) / (2 - 3j)}'
'Complex number (-0.15384615384615388+0.7692307692307692j)'
>>> name = 'ERIC'
>>> f'My name is {name.lower()}'
'My name is eric'
>>> import math
>>> f'The answer is {math.log(math.pi)}'
'The answer is 1.1447298858494002'
3.super()函数用法
super()在多重继承时候可以避免重复调用。
在多重继承时会涉及继承顺序,mro()用来获得类的继承顺序。super()相当于返回继承顺序的下一个类,而不是父类,类似于这样的功能:
def super(class_name, self):
mro = self.__class__.mro()
return mro[mro.index(class_name) + 1]
如果childA继承Base, childB继承childA和Base,如果childB需要调用Base的__init__()方法时,就会导致__init__()被执行两次:
class Base(object):
def __init__(self):
print 'Base create'
class childA(Base):
def __init__(self):
print 'enter A '
Base.__init__(self)
print 'leave A'
class childB(childA, Base):
def __init__(self):
childA.__init__(self)
Base.__init__(self)
b = childB()
Base的__init__()方法被执行了两次,输出如下:
enter A
Base create
leave A
Base create
使用super()是可避免重复调用:
class Base(object):
def __init__(self):
print 'Base create'
class childA(Base):
def __init__(self):
print 'enter A '
super(childA, self).__init__()
print 'leave A'
class childB(childA, Base):
def __init__(self):
super(childB, self).__init__()
b = childB()
print b.__class__.mro()
输出如下:
enter A
Base create
leave A
[<class '__main__.childB'>, <class '__main__.childA'>, <class '__main__.Base'>, <type 'object'>]
4.Python的内存管理
1.变量与对象
1、变量,通过变量指针引用对象。变量指针指向具体对象的内存空间,取对象的值。
2、对象,类型已知,每个对象都包含一个头部信息(头部信息:类型标识符和引用计数器)
注意:变量名没有类型,类型属于对象(因为变量引用对象,所以类型随对象),变量引用什么类型的对象,变量就是什么类型的。
id()是python的内置函数,用于返回对象的身份,即对象的内存地址。
示例:
In [32]: var1=object
In [33]: var2=var1
In [34]: id(var1)
Out[34]: 139697863383968
In [35]: id(var2)
Out[35]: 139697863383968
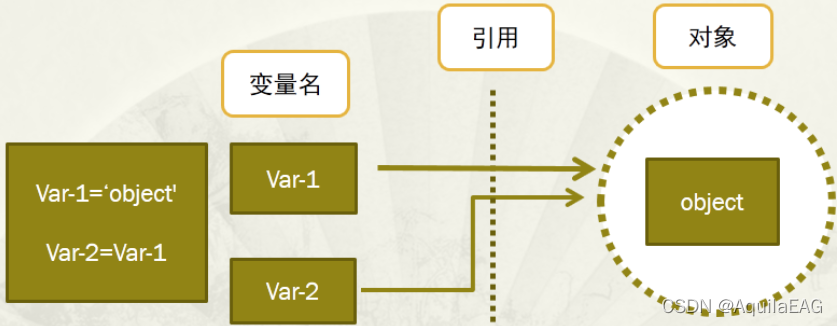
3、引用判断:通过is进行引用所指判断,is是用来判断两个引用所指的对象是否相同。

由运行结果可知:
1、Python缓存了整数和短字符串,因此每个对象在内存中只存有一份,引用所指对象就是相同的,即使使用赋值语句,也只是创造新的引用,而不是对象本身;
2、Python没有缓存长字符串、列表及其他对象,可以由多个相同的对象,可以使用赋值语句创建出新的对象。
2.引用计数
在Python中,每个对象都有指向该对象的引用总数—引用计数,查看对象的引用计数:sys.getrefcount()
1、普通引用
In [2]: import sys
In [3]: a=[1,2,3]
In [4]: getrefcount(a)
Out[4]: 2
In [5]: b=a
In [6]: getrefcount(a)
Out[6]: 3
In [7]: getrefcount(b)
Out[7]: 3
当使用某个引用作为参数,传递给getrefcount()时,参数实际上创建了一个临时的引用。因此,getrefcount()所得到的结果,会比期望的多1。
2、容器对象
Python的一个容器对象(比如:列表、词典等),可以包含多个对象。

由上可见,实际上,容器对象中包含的并不是元素对象本身,是指向各个元素对象的引用。
3、引用计数增加
(1)对象被创建
In [39]: getrefcount(123)
Out[39]: 6
In [40]: n=123
In [41]: getrefcount(123)
Out[41]: 7
(2)另外的别人被创建
In [42]: m=n
In [43]: getrefcount(123)
Out[43]: 8
(3)作为容器对象的一个元素
In [44]: a=[1,12,123]
In [45]: getrefcount(123)
Out[45]: 9
(4)被作为参数传递给函数:foo(x)
4、引用计数减少
1、对象的别名被显式的销毁
In [46]: del m
In [47]: getrefcount(123)
Out[47]: 8
2、对象的一个别名被赋值给其他对象
In [48]: n=456
In [49]: getrefcount(123)
Out[49]: 7
3、对象从一个窗口对象中移除,或,窗口对象本身被销毁
In [50]: a.remove(123)
In [51]: a
Out[51]: [1, 12]
In [52]: getrefcount(123)
Out[52]: 6
4、一个本地引用离开了它的作用域,比如上面的foo(x)函数结束时,x指向的对象引用减1。
3.垃圾回收
当Python中的对象越来越多,占据越来越大的内存,启动垃圾回收(garbage collection),将没用的对象清除。
1、原理
当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾。比如某个新建对象,被分配给某个引用,对象的引用计数变为1。如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。
2、解析del
In [74]: a=[321,123]
In [75]: del a
del a后,已经没有任何引用指向之前建立的[321,123],该表引用计数变为0,用户不可能通过任何方式接触或者动用这个对象,当垃圾回收启动时,Python扫描到这个引用计数为0的对象,就将它所占据的内存清空。
3、注意
1、垃圾回收时,Python不能进行其它的任务,频繁的垃圾回收将大大降低Python的工作效率;
2、Python只会在特定条件下,自动启动垃圾回收(垃圾对象少就没必要回收)
3、当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
In [93]: import gc
In [94]: gc.get_threshold() #gc模块中查看阈值的方法
Out[94]: (700, 10, 10)
阈值分析:
700即是垃圾回收启动的阈值;
每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收;
当然也是可以手动启动垃圾回收:
In [95]: gc.collect() #手动启动垃圾回收
Out[95]: 2
4、何为分代回收
Python将所有的对象分为0,1,2三代;
所有的新建对象都是0代对象;
当某一代对象经历过垃圾回收,依然存活,就被归入下一代对象。
4.内存池机制
Python中有分为大内存和小内存:(256K为界限分大小内存)
1、大内存使用malloc进行分配
2、小内存使用内存池进行分配
3、Python的内存池(金字塔)
第3层:最上层,用户对Python对象的直接操作
第1层和第2层:内存池,有Python的接口函数PyMem_Malloc实现-----若请求分配的内存在1~256字节之间就使用内存池管理系统进行分配,调用malloc函数分配内存,但是每次只会分配一块大小为256K的大块内存,不会调用free函数释放内存,将该内存块留在内存池中以便下次使用。
第0层:大内存-----若请求分配的内存大于256K,malloc函数分配内存,free函数释放内存。
第-1,-2层:操作系统进行操作
参考:https://www.cnblogs.com/geaozhang/p/7111961.html
5.python模块的内置属性__main__
if __name__ == "__main__":
pass
1、__name__是当前模块的一个属性,属性名称的前后各有两个_修饰,表明它是一个内置属性(也称内置变量)
2、"main"则是一个字符串对象
__name__属性的值什么时候等于"main"呢?
如果当前模块是程序的入口模块(也称顶级模块、脚本文件),则当前模块的__name__属性的值是"main"
对于任何一个python文件来说,当python解释器运行一个py文件,会自动将一些内容加载到内置的属性中;一个模块我们可以看做是一个比类更大的对象。(通过dir()方法我们可以获取到该模块的所有的显式或隐式的属性或方法)
__name__
该属性代表当前模块的名字,每个py文件默认的属性,如果当前模块是主程序,值为“main”,如果不是主程序,值为模块名。这个属性经常用来区分主程序和作为被导入模块的程序。
__builtins__
该属性代表内置模块builtins,即所有的内建函数、内置类型、内置异常等;在python执行一个py文件时,会将内置模块赋值给这个属性;如果不是主程序,那么这个属性是一个builtins模块所有方法的字典。
__doc__
模块的说明文档,py文件初始化时,将文件开始的说明字符串赋值给这个属性。
__file__
该属性代表文件的绝对路径,任何一个模块使用这个属性就可获得本模块的绝对路径。
__cached__
缓存文件,如果是主程序,那么该属性为None,其他模块的该属性指向该模块的pyc字节文件,这样在py文件不发生修改的情况下可以减少编译的时间,更快地加载上下文环境。
__annotations__
该属性对于模块文件来说,没有开放给用户使用;但对于函数来说,这个方法用来记录参数的类型和返回值。
函数的参数和返回值如果在定义的时候指定了类型,那么它们就会以键值对的形式记录到函数的__annotations__属性中,但对于匿名函数来说,这个属性是不存在的。
__loader__
该属性py3.3之前没有,引用了本模块的加载器对象,即该模块的上下文是由这个加载器加载到内存中的。
__package__
该属性是一个文件是否是包的标志,在主程序中该属性的值永远是None,不要使用它;当一个包被导入到主程序中,该包的__package__属性为包的名字。
__spec__
该属性记录一个模块的详细信息,是一个ModuleSpec对象。
__author__
该属性用来定义模块的作者信息,可以是字符串,也可以是列表、字典等数据结构。
__all__
该属性不是模块默认的,需要手动定义,它的功能有二:
记录一个模块有哪些重要的、对外开发的类、方法或变量等,或记录一个包哪些对外开放的模块;
限制导入,当使用“from xxx import *”形式导入时,实际导入的只有__all__属性中的同名的对象而不是所有,但对于“from xxx import xxx”指定了具体的名字则all属性被忽略。
__import__
该魔法方法是import触发,即import os 相当于os = import(‘os’),也可以直接使用,主要用于模块延迟加载,或重载模块。
参考:https://www.cnblogs.com/cwp-bg/p/9856339.html
6.Python2.x 与 3.x 版本区别
参考:https://www.runoob.com/python/python-2x-3x.html
7.自定义模块的导入
导入自定义模块的三种方法:
第一种,直接 import
这里有个大前提,就是py执行文件和模块同属于同个目录(父级目录)
第二种,通过sys模块导入自定义模块的path
先导入sys模块
然后通过sys.path.append(path) 函数来导入自定义模块所在的目录
导入自定义模块。
第三种,通过.pth文件找到自定义模块
这个方法原理就是利用了系统变量,python会扫描path变量的路径来导入模块,可以在系统path里面添加。
python导入模块的查找顺序:
(1)首先导入内建模块。首先判断这个module是不是built-in即内建模块,如果是内建模块则引入内建模块,如果不是则在一个称为sys.path的list中寻找;
(2)在sys.path返回的列表中寻找。sys.path在python脚本执行时动态生成,它返回的是一个列表,这个列表包含了以下几部分。包括以下5个部分:
下面的五个搜索路径是有先后顺序的:
1.程序的根目录(即当前运行python文件的目录)
2.PYTHONPATH环境变量设置的目录
3.标准库的目录
4.任何能够找到的.pth文件的内容
5.第三方扩展的site-package目录
8.python程序的执行顺序
1.按顺序扫描序执行
2.import模块在首次导入时会进去执行
示例:mt/mt.py,init.py
print("enter mt")
class fun():
def __init__(self):
print("enter fun")
print("leave mt")
main.py
from mt.mt import fun
class A:
print("A")
def __init__(self):
print("A create")
self.a = 1
def output(self):
print(self.a)
class B(A):
print("B")
def __init__(self):
print("B create")
super(B, self).__init__()
class C(A):
print("C")
global t
t = 888
def __init__(self):
print("C create")
super(C, self).__init__()
class D(B, C):
print("D")
def __init__(self):
print("D create")
super(D, self).__init__()
D = D()
print(D.__class__.__mro__)
#print(dir())
print(t)
F = fun()
if __name__ == "__main__":
print("enter main()")
输出:
enter mt
leave mt
A
B
C
D
D create
B create
C create
A create
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
888
enter fun
enter main()
9.python类的继承
通过继承创建的新类称为“子类”或“派生类”,被继承的类称为“基类”、“父类”或“超类”,继承的过程,就是从一般到特殊的过程。
继承概念的实现方式主要有2类:实现继承、接口继承。
实现继承是指使用基类的属性和方法而无需额外编码的能力。
接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力(子类重构爹类方法)。
构造函数的继承
继承类的构造方法:
1.经典类的写法: 父类名称.__init__(self,参数1,参数2,...)
2. 新式类的写法:super(子类,self).__init__(参数1,参数2,....),优势在于
处理多重继承时能够避免基类对象的重复构造
示例:
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
self.weight = 'weight'
def talk(self):
print("person is talking....")
class Chinese(Person):
def __init__(self, name, age, language): # 先继承,再重构
Person.__init__(self, name, age) #继承父类的构造方法,也可以写成:super(Chinese,self).__init__(name,age)
self.language = language # 定义类的本身属性
def walk(self):
print('is walking...')
class American(Person):
pass
c = Chinese('bigberg', 22, 'Chinese')
如果只是简单的在子类Chinese中定义一个构造函数,其实就是在重构,这样子类就不能继承父类的属性了。
所以在定义子类的构造函数时,要先继承再构造,这样我们也能获取父类的属性了。
子类构造函数基础父类构造函数过程如下:
实例化对象c ----> c 调用子类__init__() ---- > 子类__init__()继承父类__init__() ----- > 调用父类 __init__()
子类对父类方法的重写
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
self.weight = 'weight'
def talk(self):
print("person is talking....")
class Chinese(Person):
def __init__(self, name, age, language):
Person.__init__(self, name, age)
self.language = language
print(self.name, self.age, self.weight, self.language)
def talk(self): # 子类 重构方法
print('%s is speaking chinese' % self.name)
def walk(self):
print('is walking...')
c = Chinese('bigberg', 22, 'Chinese')
c.talk()
# 输出
bigberg 22 weight Chinese
bigberg is speaking chinese
10.python标识符
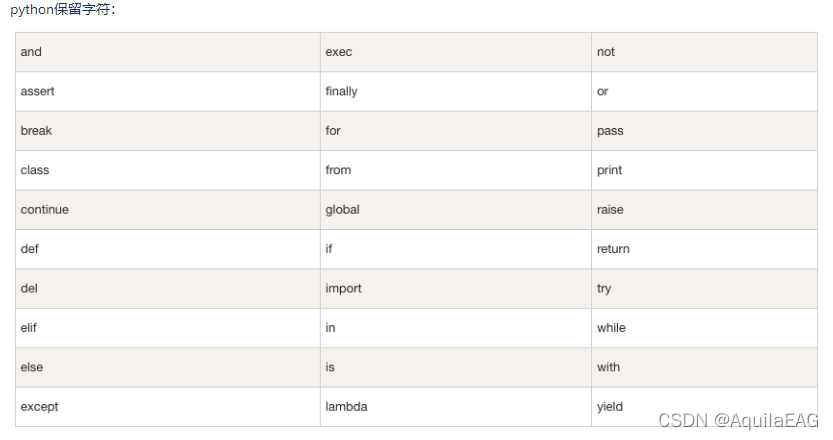
在 Python 里,标识符由字母、数字、下划线组成。
在 Python 中,所有标识符可以包括英文、数字以及下划线(_),但不能以数字开头。
Python 中的标识符是区分大小写的。
以下划线开头的标识符是有特殊意义的。
以单下划线开头 _foo 的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用 from xxx import * 而导入。
以双下划线开头的 __foo 代表类的私有成员,
以双下划线开头和结尾的 foo 代表 Python 里特殊方法专用的标识,如 init() 代表类的构造函数。
Python 可以同一行显示多条语句,方法是用分号 ; 分开。
说明:global关键字可以定义一个变量,被定义的变量可以在变量作用域之外被修改,即声明为全局变量(必须先声明global,再赋值定义)














 70
70











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









